Download as PDF, PPTX



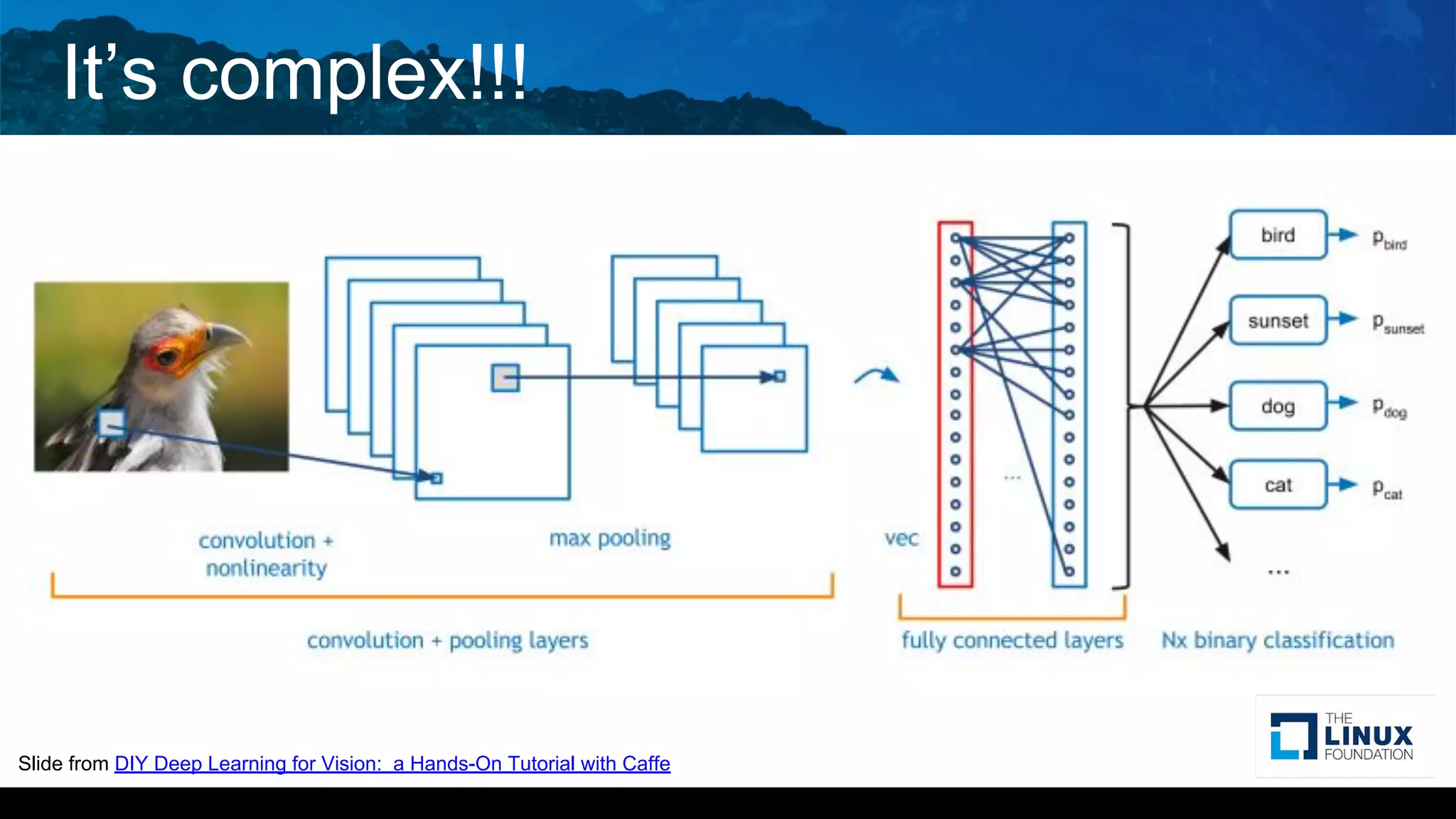


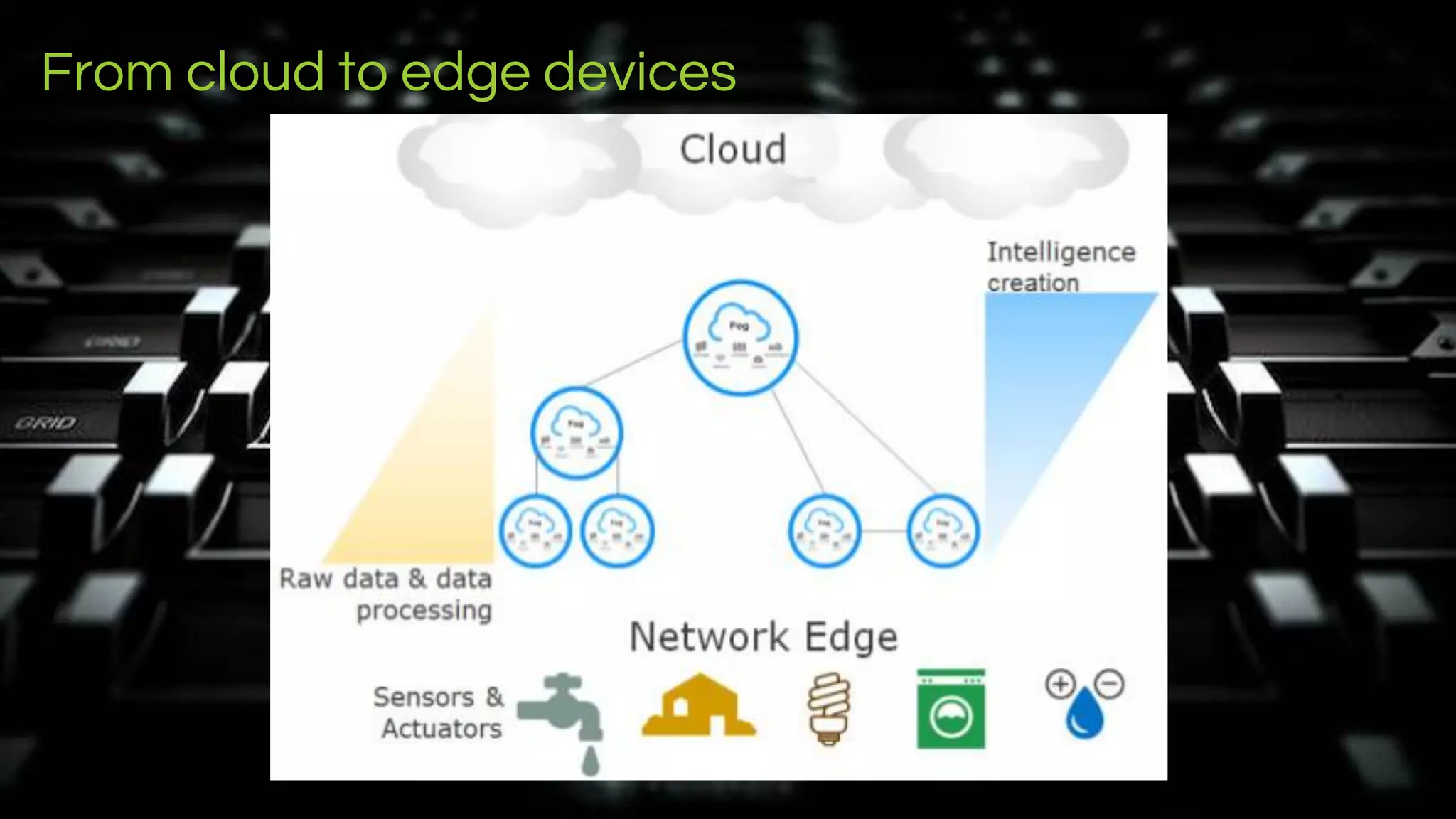







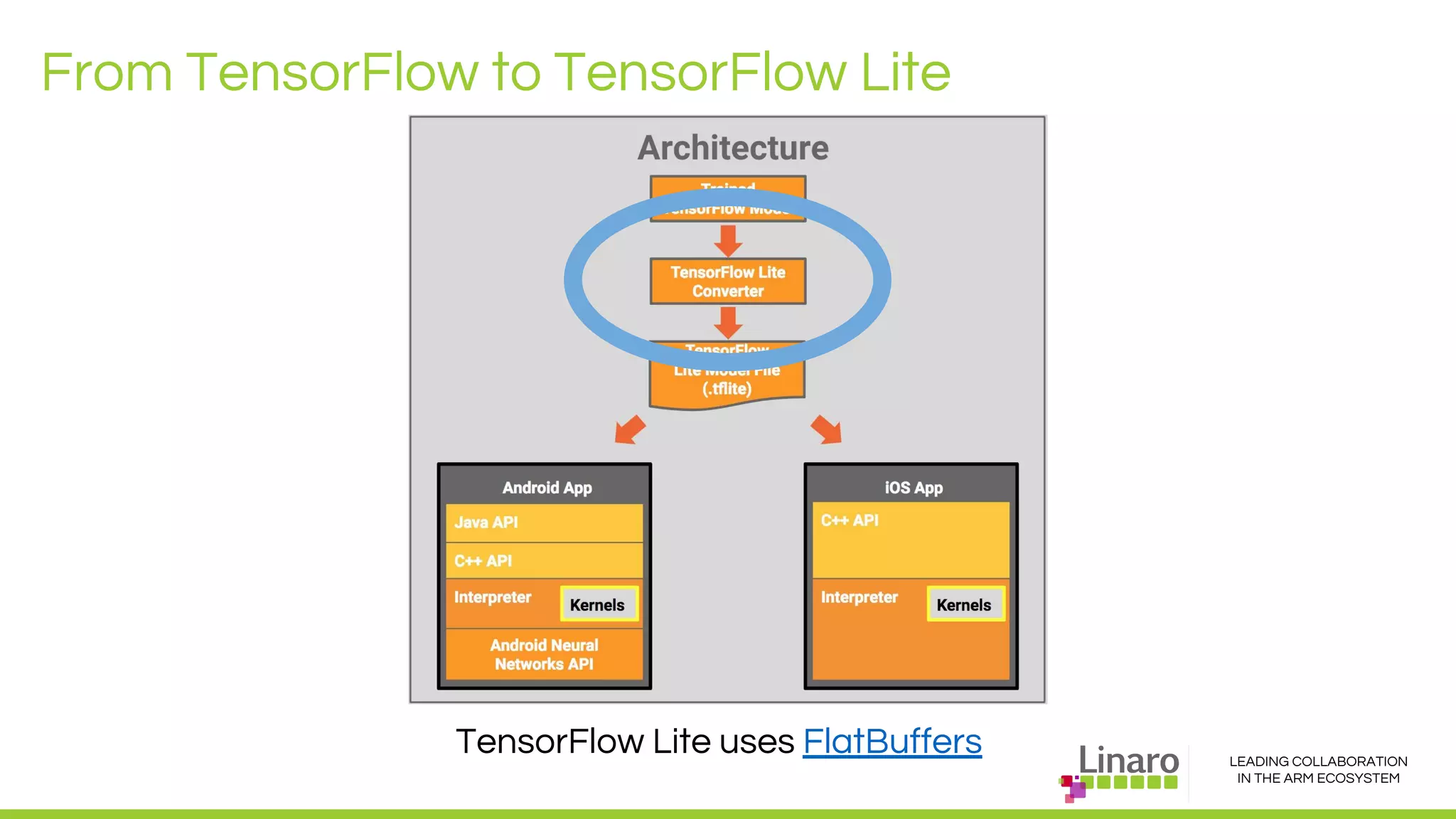
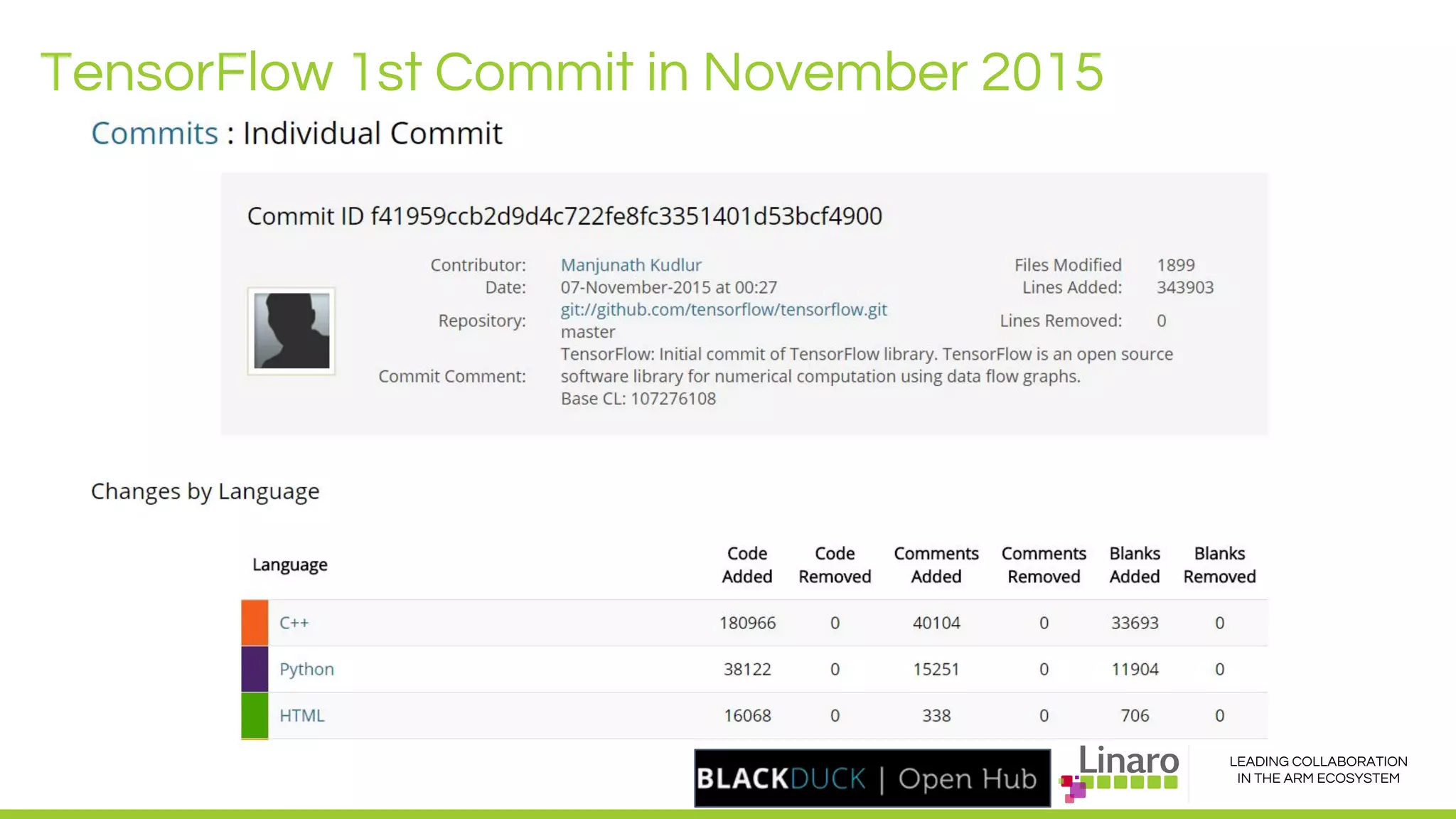




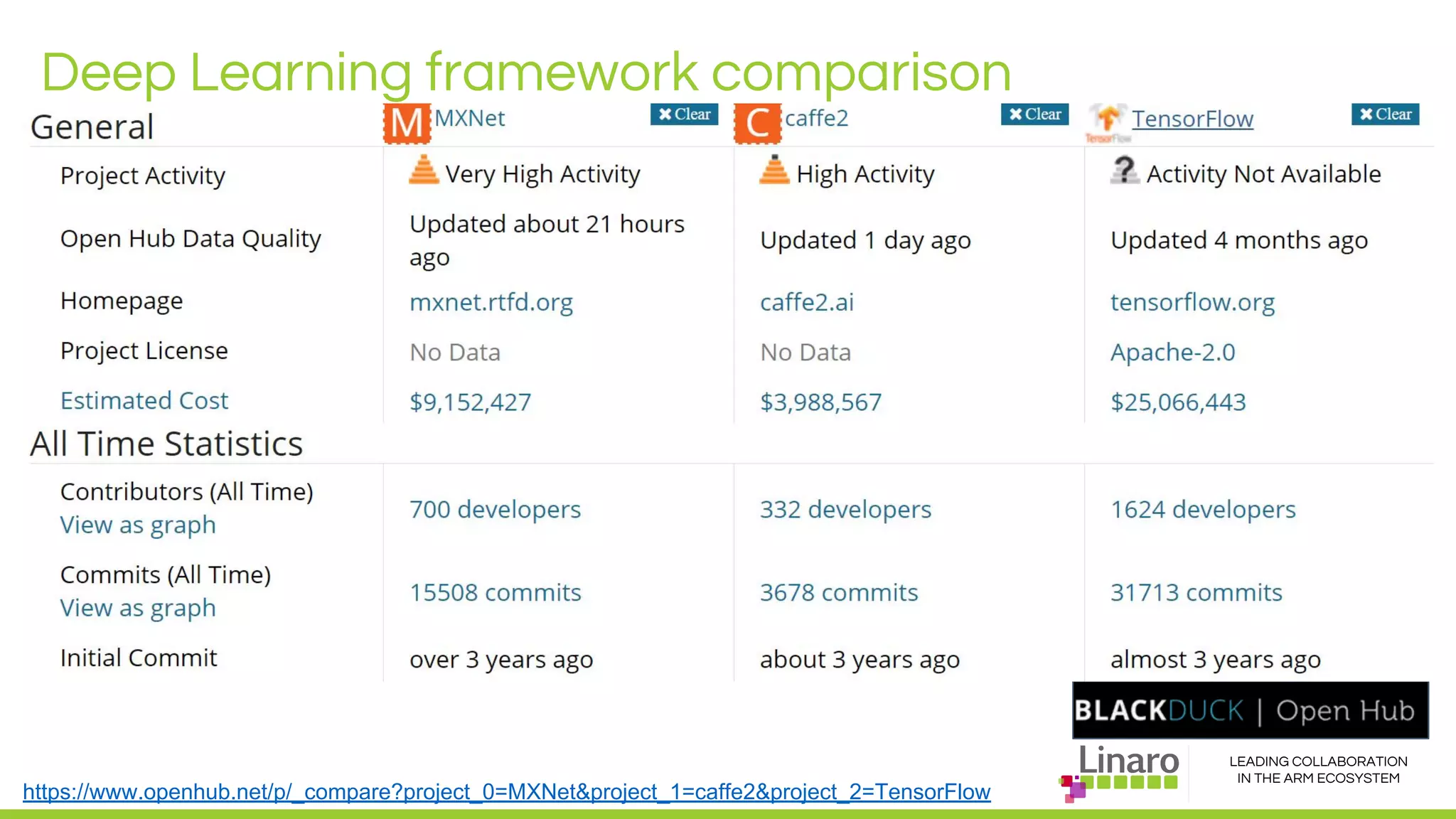
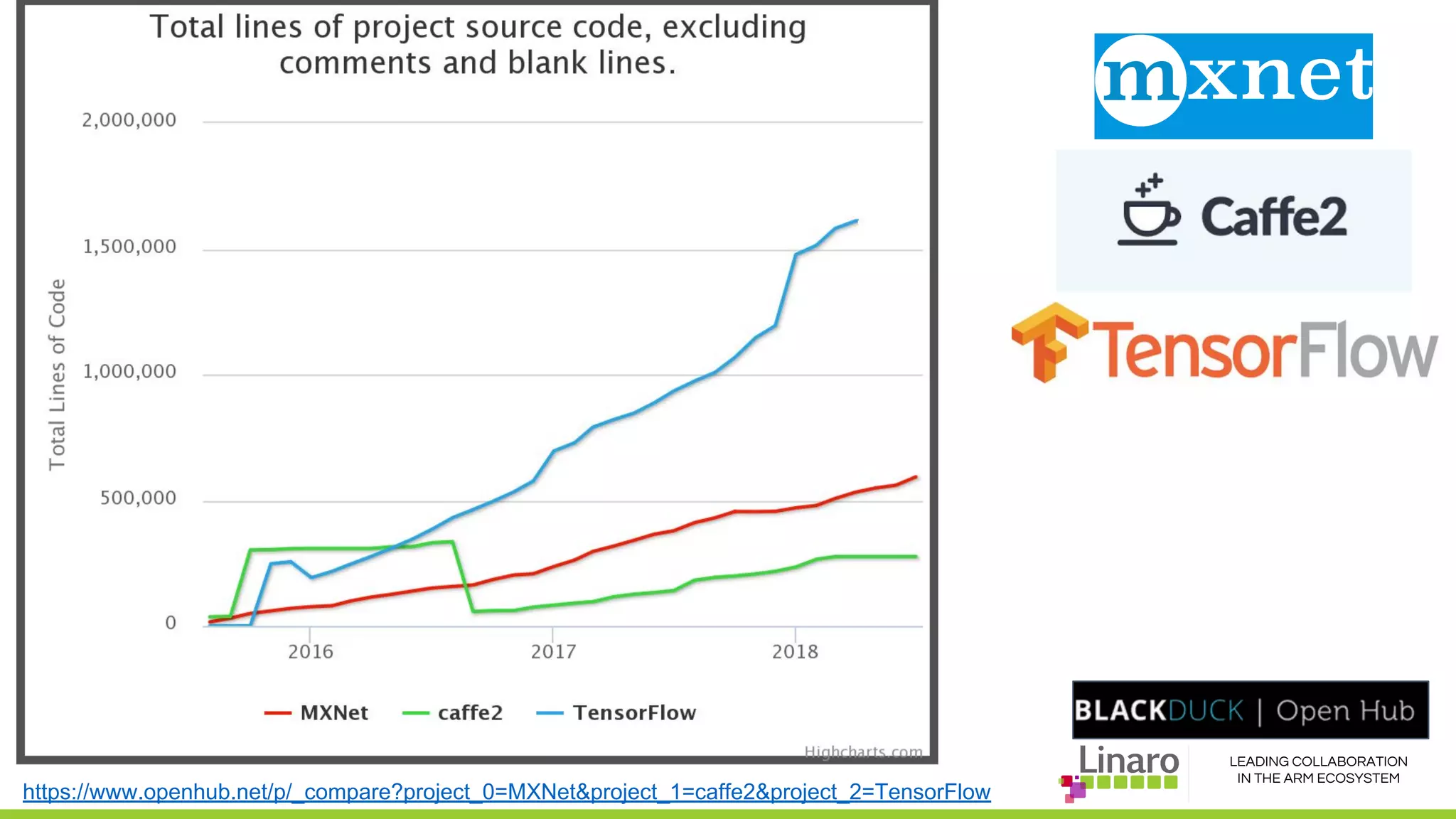
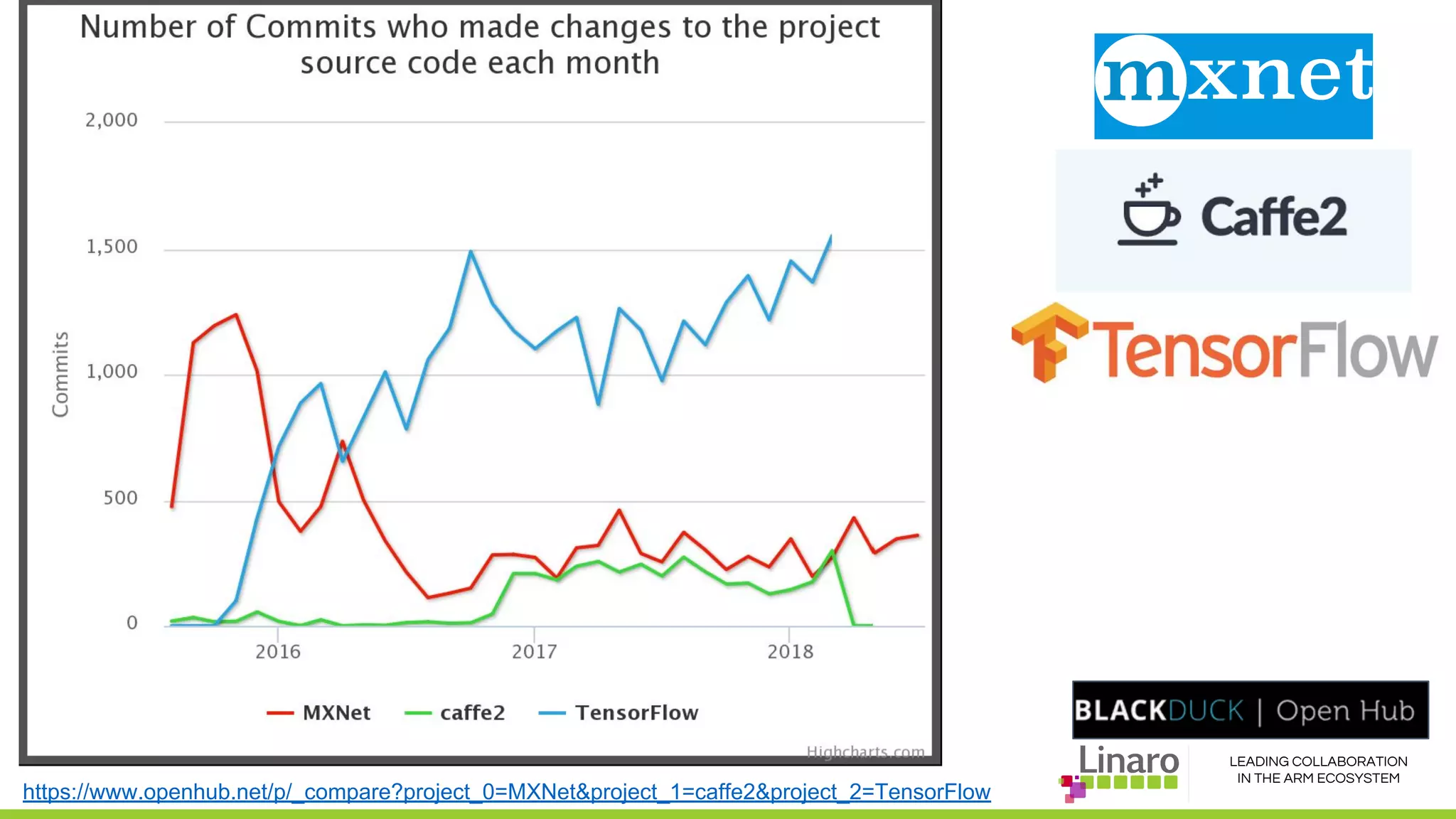








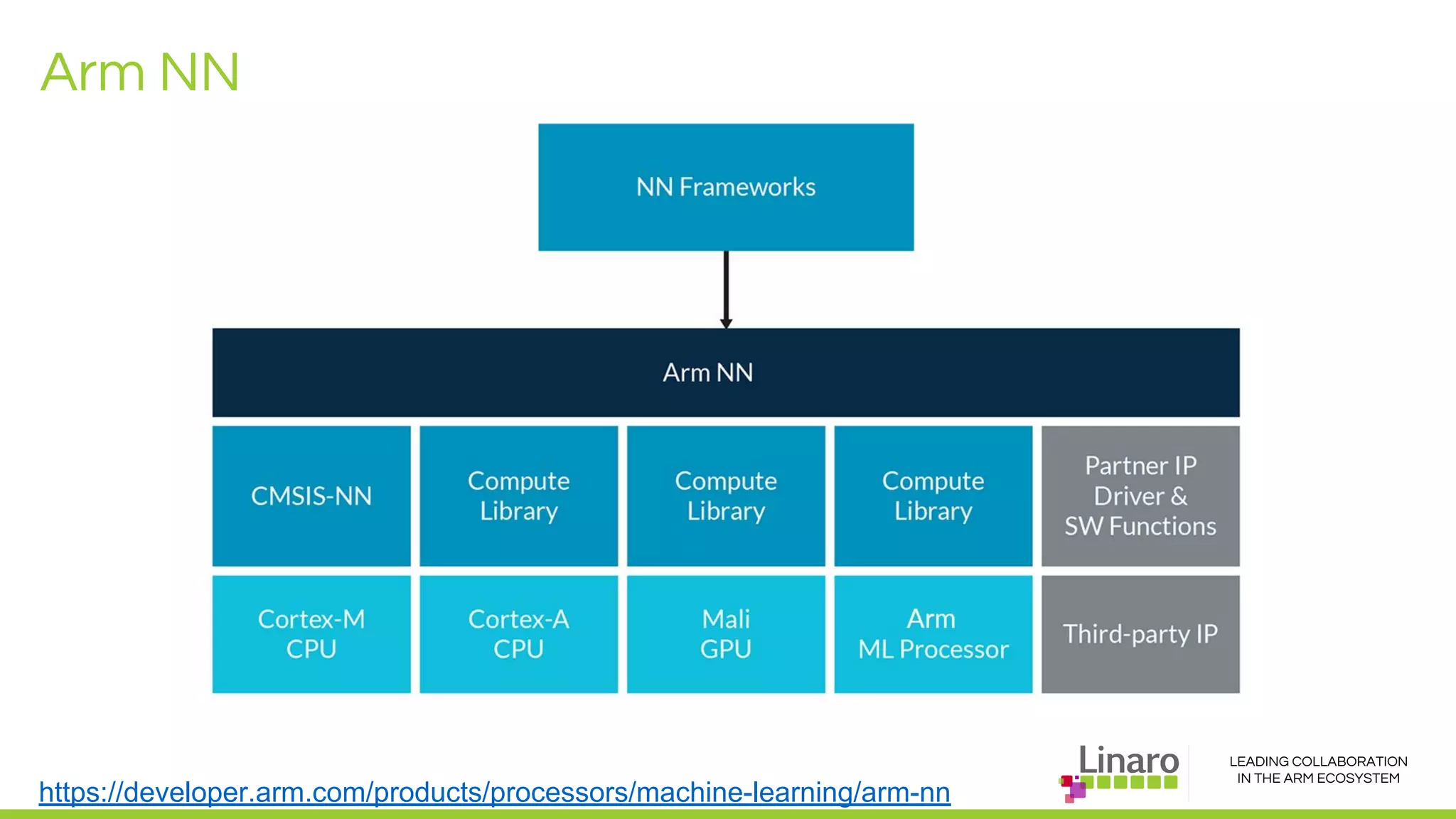
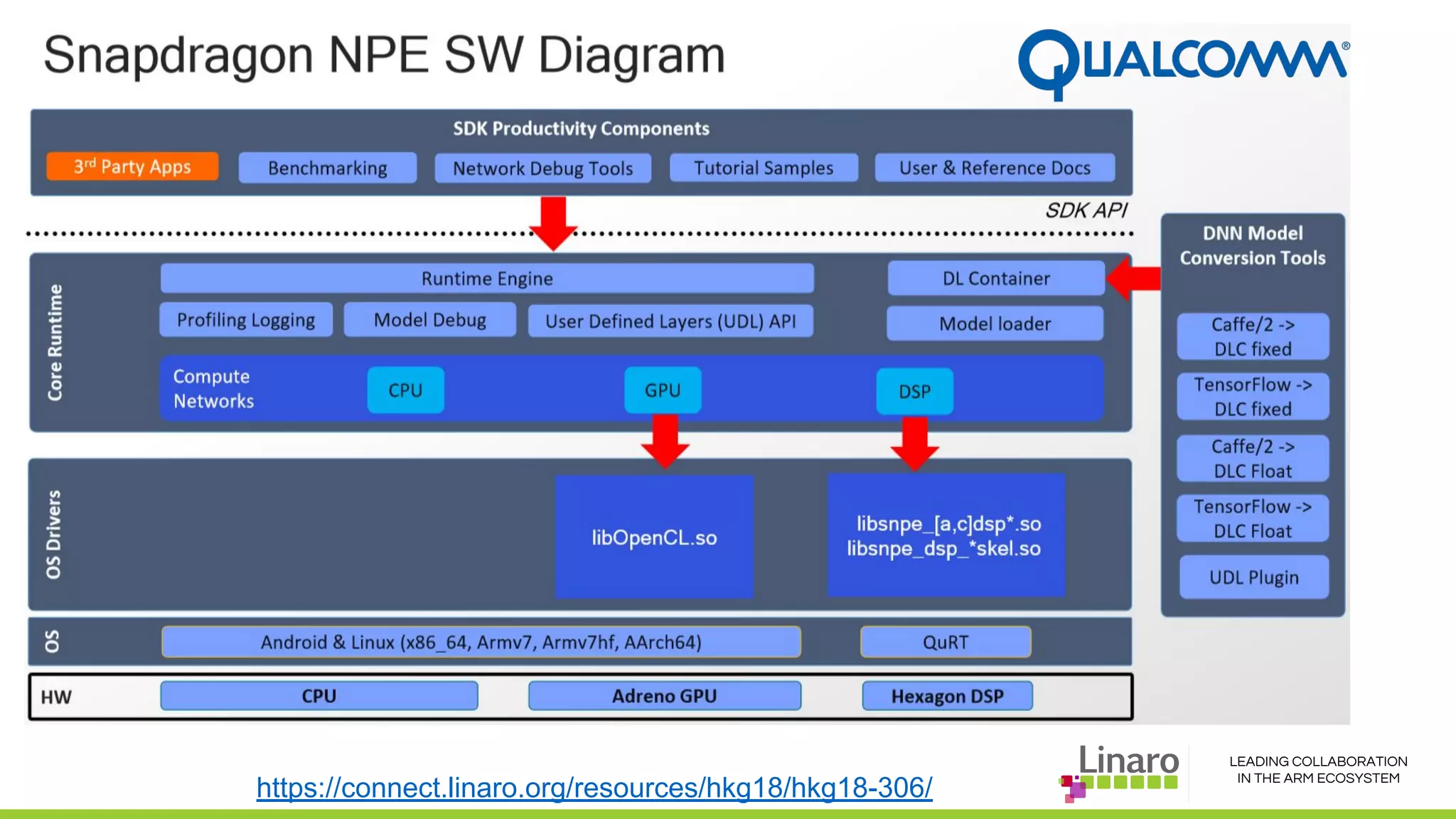
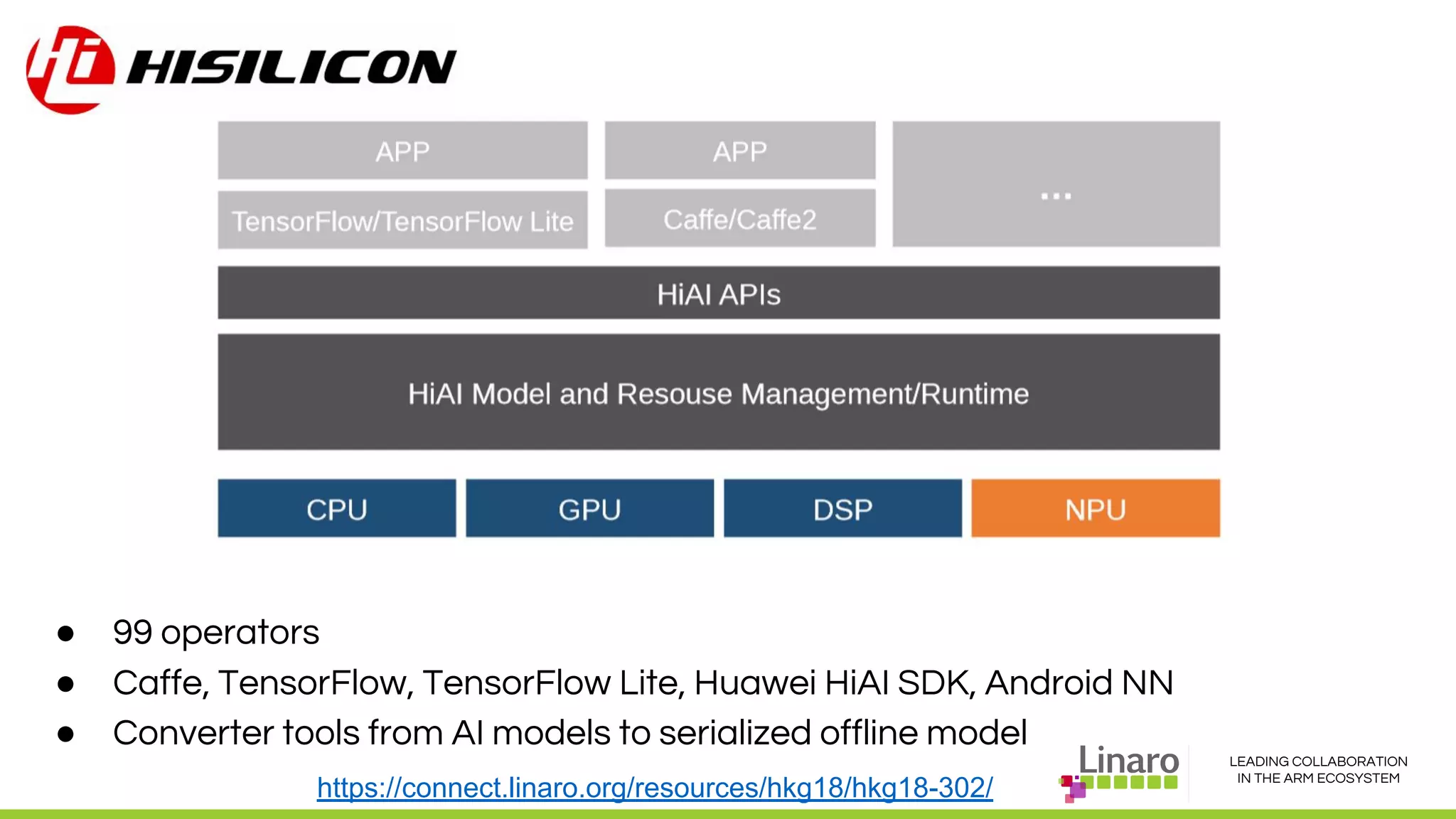
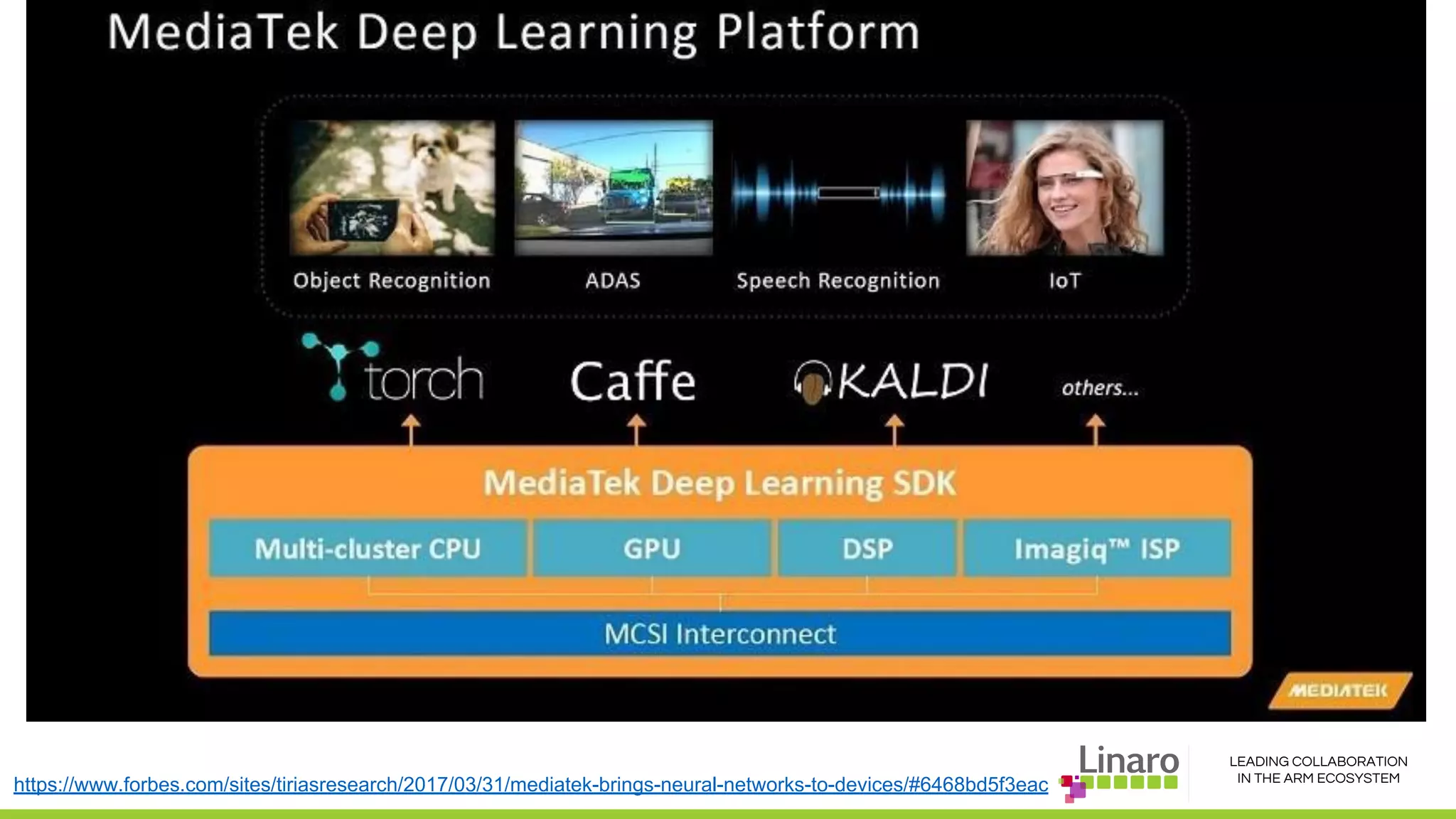

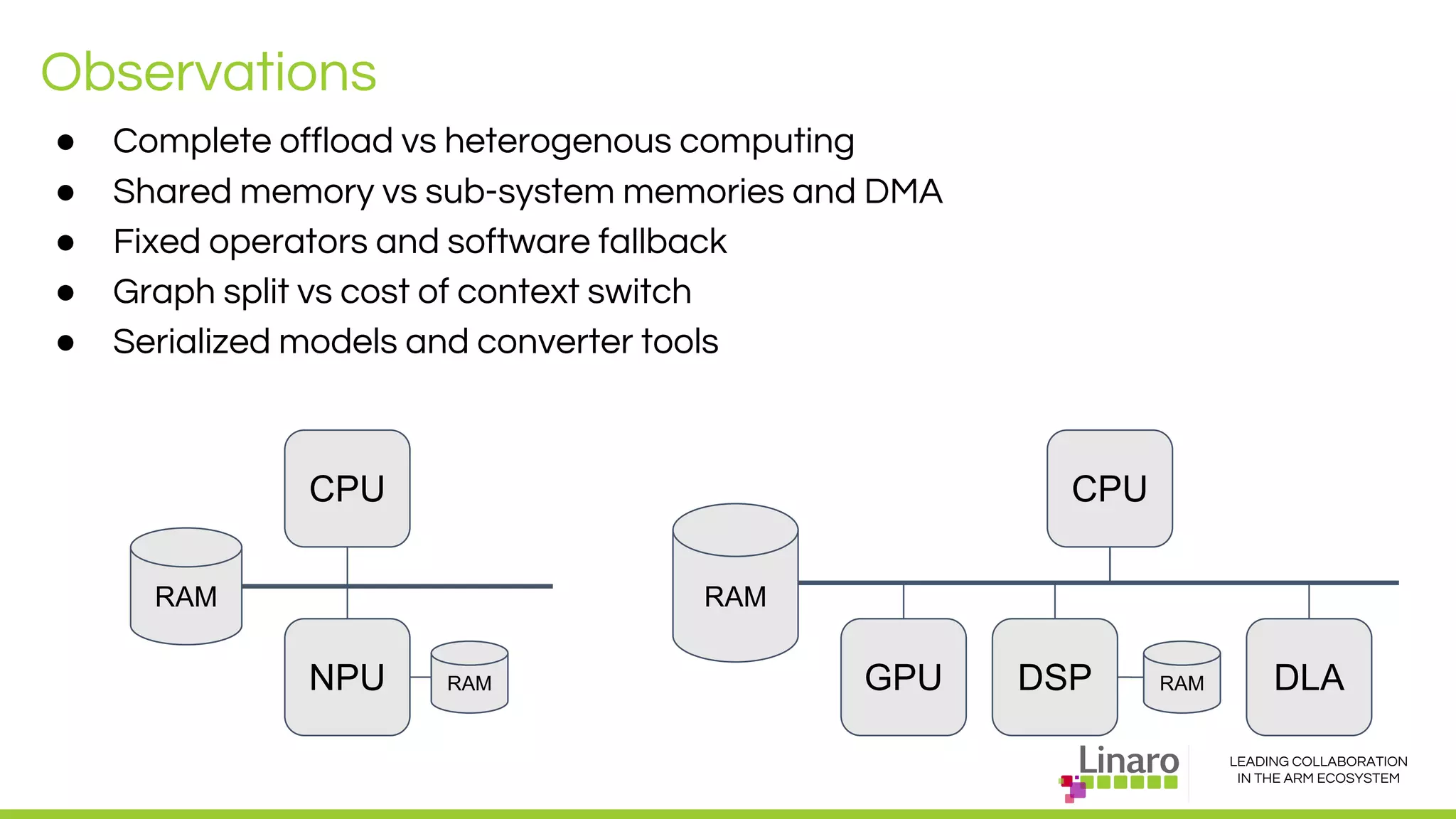






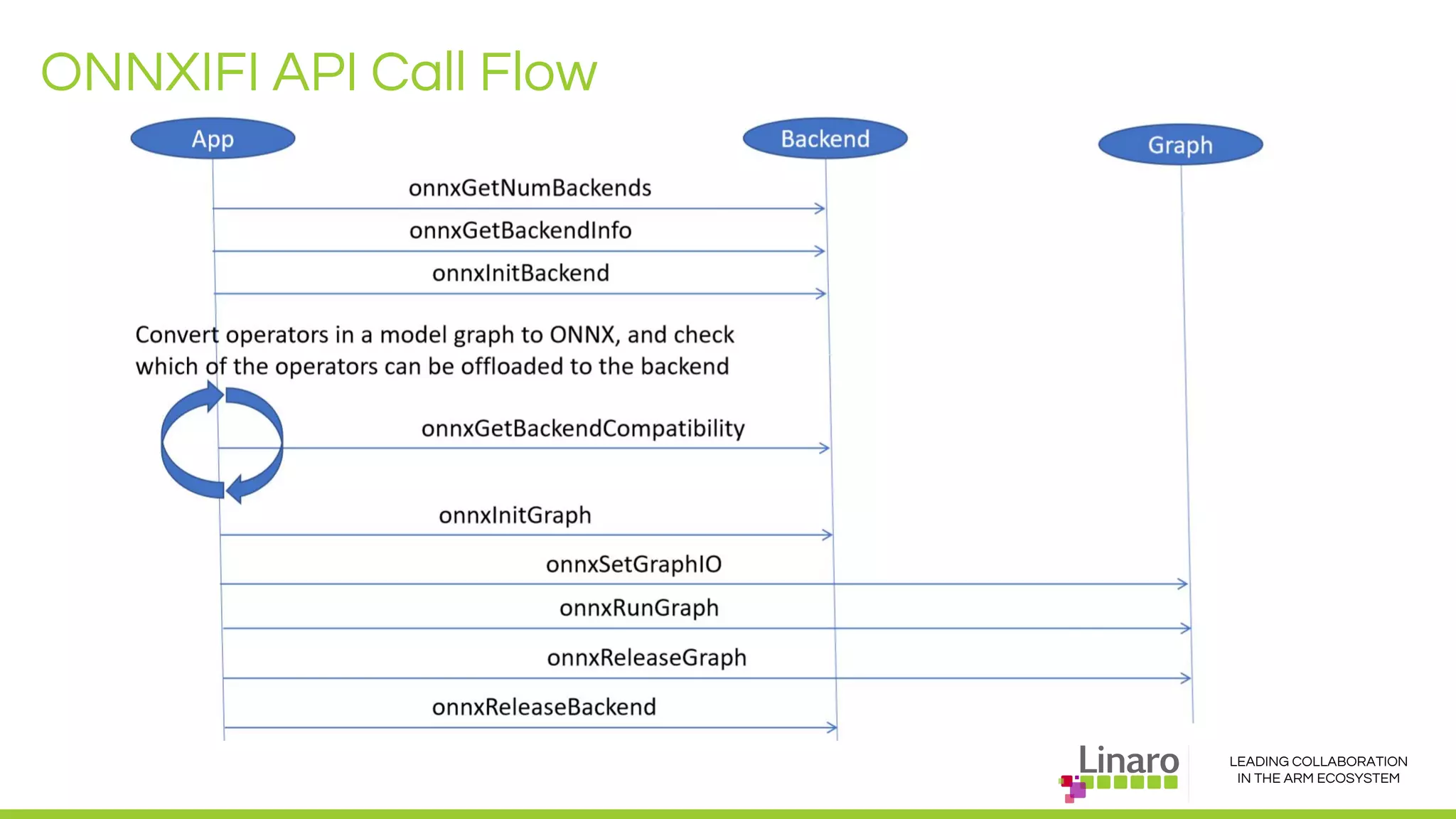
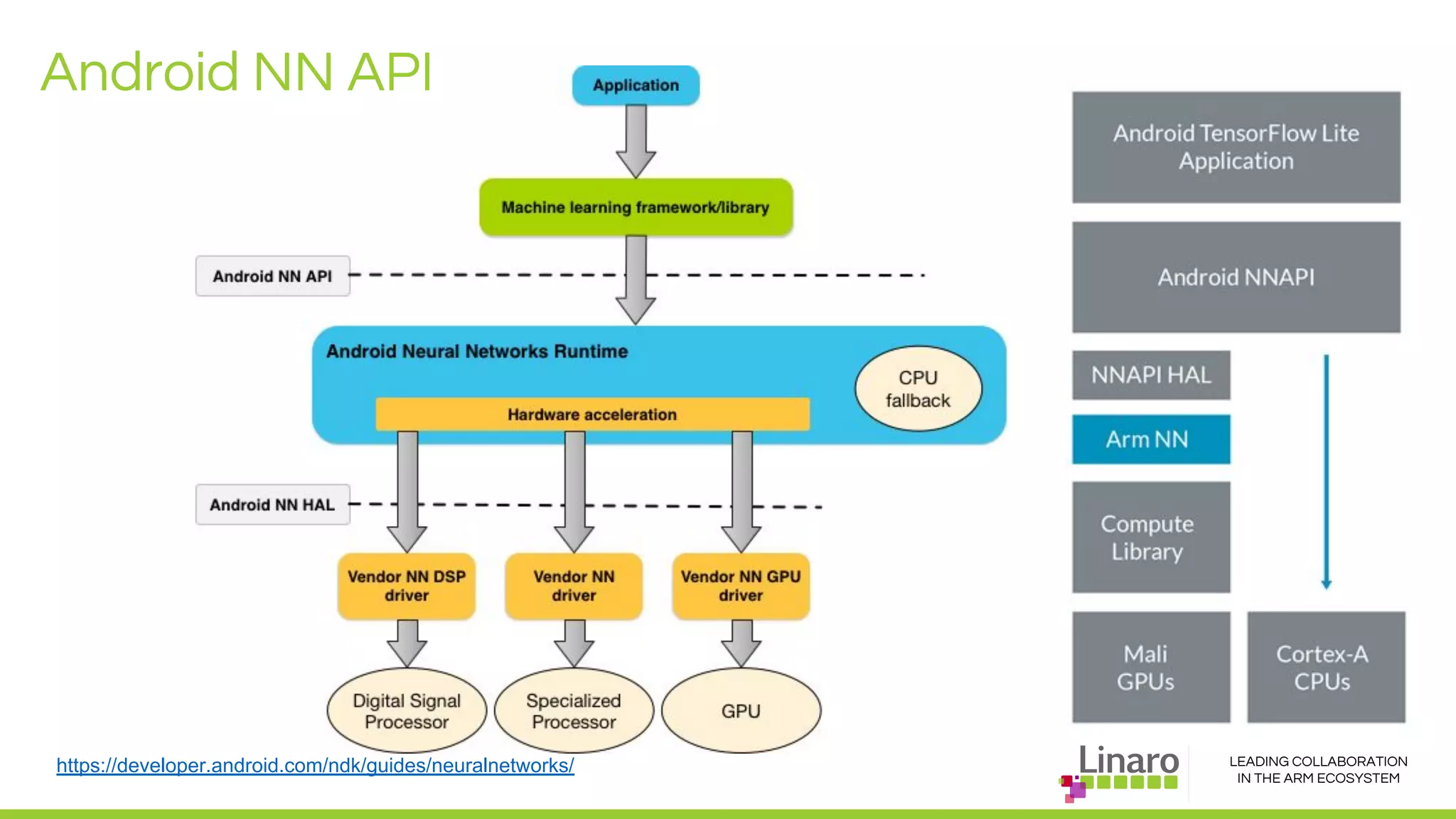





The document discusses deep learning neural network acceleration at the edge, emphasizing various AI and ML frameworks like TensorFlow, Caffe, and MXNet, and their evolution and capabilities. It highlights the importance of collaboration within the ARM ecosystem and addresses privacy, bandwidth, and latency issues when deploying deep learning at the edge. Additionally, it outlines different hardware solutions and architectures aimed at improving performance for AI tasks, encouraging Linaro members to collaborate on open-source projects to drive innovation.




































































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)


















