Downloaded 15 times


![Introduction
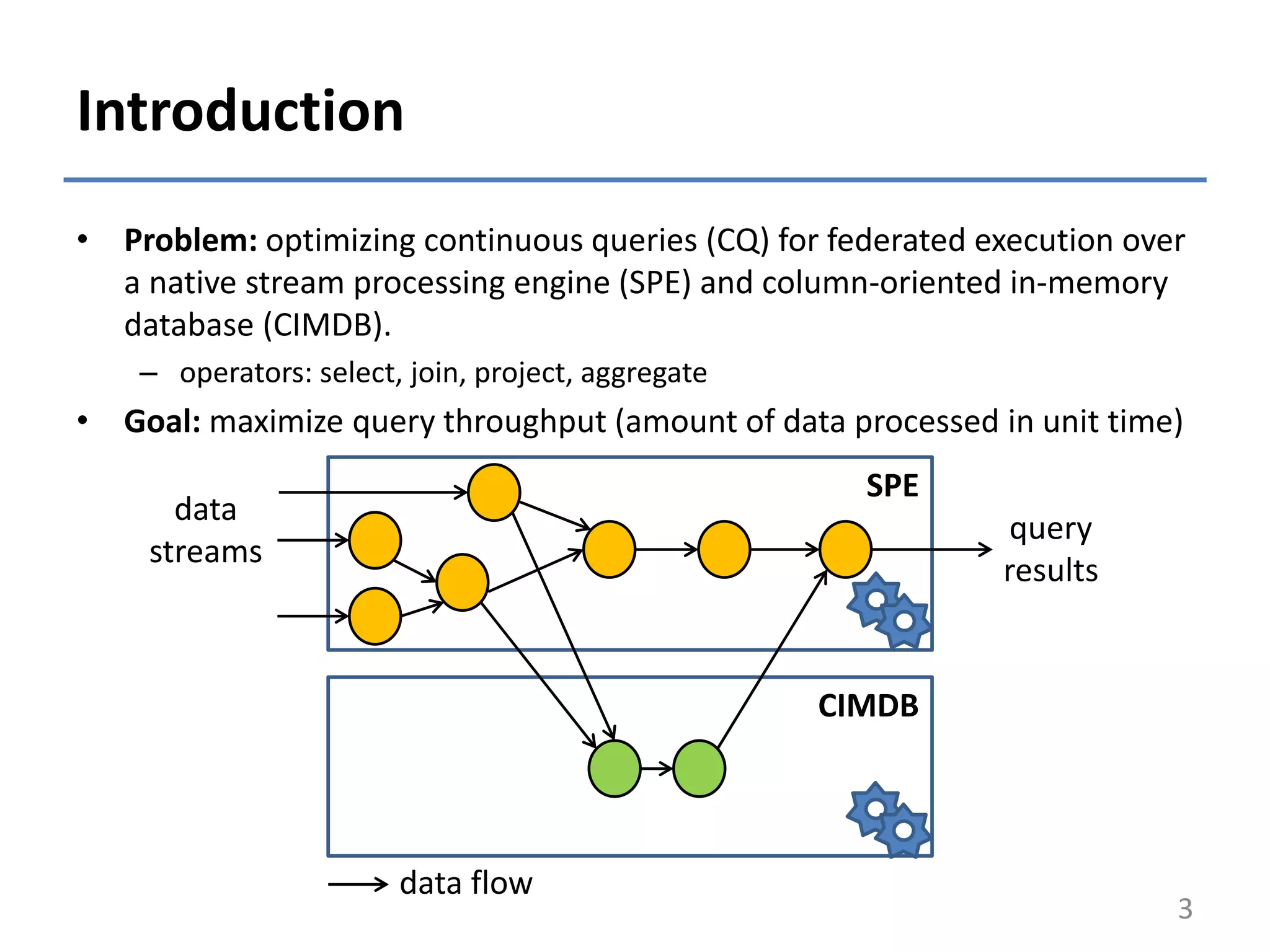
• Motivation:
– “No one size fits all” (Cyclops[LHB13], [JI13])
– obtain the best of both worlds (SPE, CIMDB)
• Application Scenario:
– analyzing energy consumption data collected from smart plugs
installed in households (DEBS 2014 Grand Challenge)
• Main contributions:
– a static cost-based optimizer for federated systems
• extends established optimization techniques
• considers the feasibility property of CQ
– showed the potential of federated CQ execution over a SPE and a CIMDB
• up to 8.5x as high as throughput of pure SPE based processing
• up to 1.8x as high as throughput of pure CIMDB based processing
4](https://image.slidesharecdn.com/2015-03-05btw-talkv2-150316111411-conversion-gate01/75/Optimization-of-Continuous-Queries-in-Federated-Database-and-Stream-Processing-Systems-4-2048.jpg)
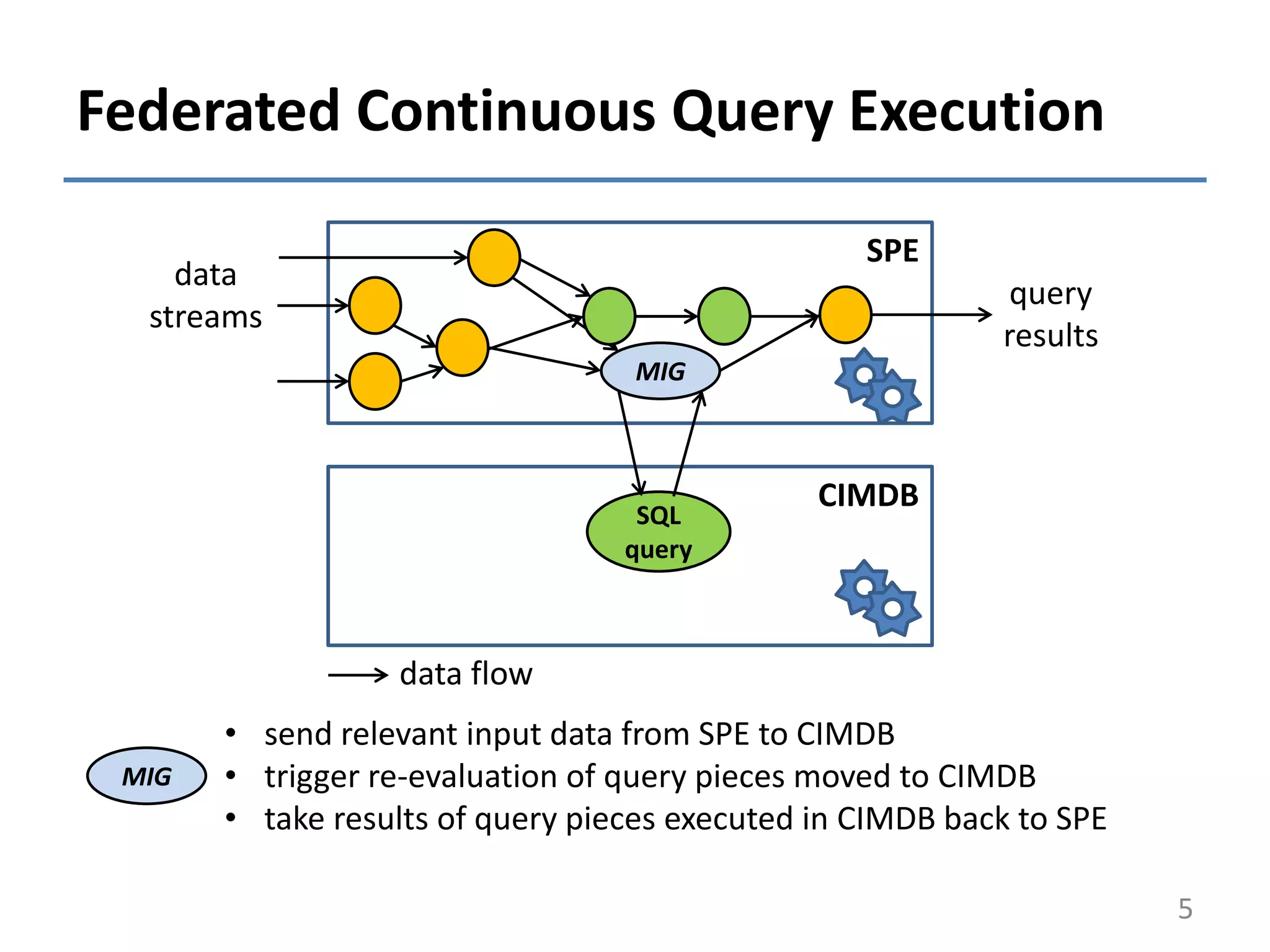
![Query Optimization Problem
• Problem: determine the optimal execution
plan for a given CQ
– currently at deployment time
• Feasibility of continuous queries [AN04]:
– feasible execution plan: can keep up
with data arrival rate
– feasible query: has at least one feasible plan
6
SPE CIMDB
• Feasibility-dependent optimization objective:
– feasible queries: find the feasible plan with least resource consumption
– infeasible queries: find the plan which with maximal throughput
• State of the art: either consider feasibility of CQ but not the federation
context, or the federation context but not the feasibility of CQ.](https://image.slidesharecdn.com/2015-03-05btw-talkv2-150316111411-conversion-gate01/75/Optimization-of-Continuous-Queries-in-Federated-Database-and-Stream-Processing-Systems-6-2048.jpg)

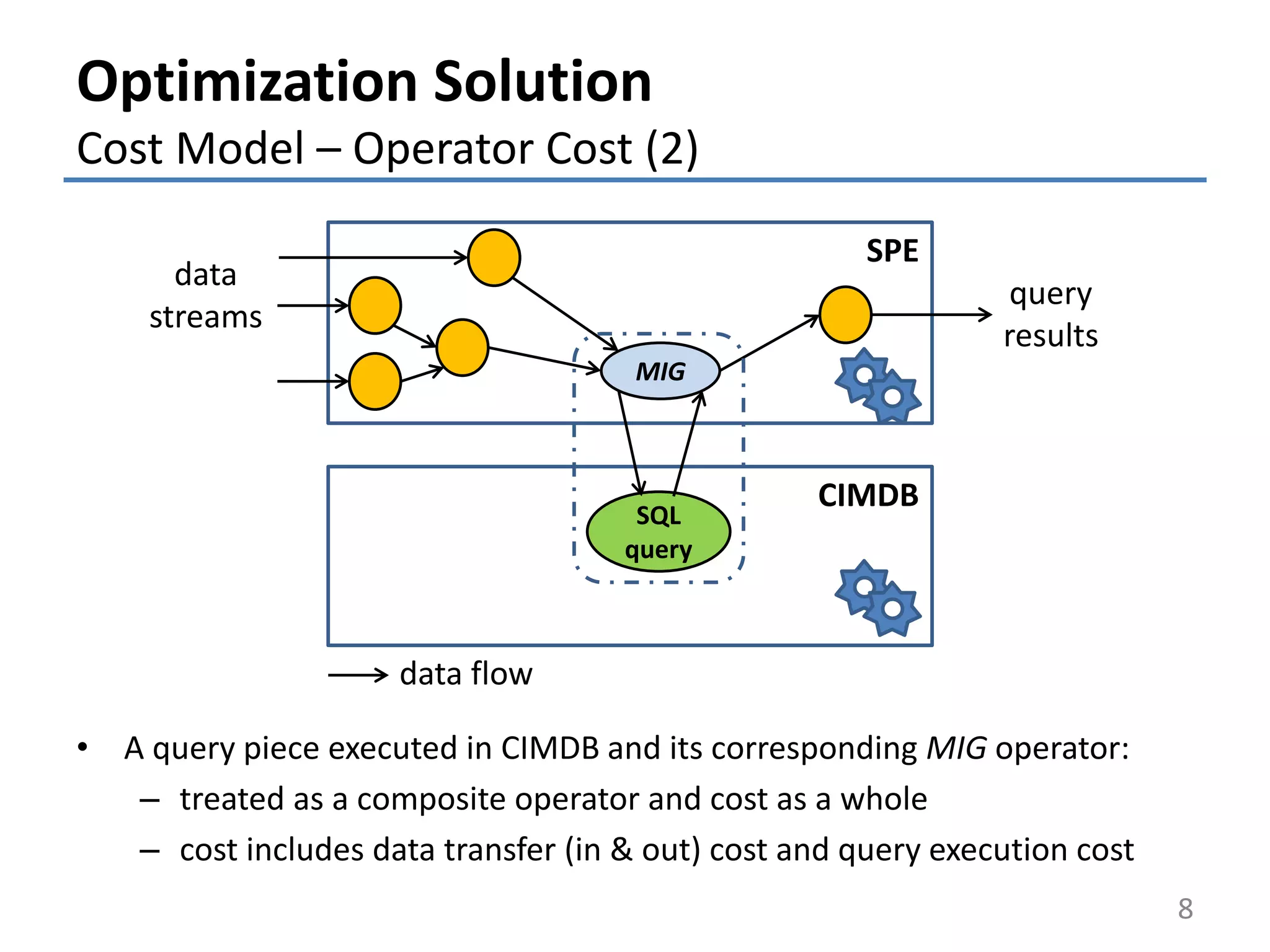
![• Execution plan cost: C(P) = <𝐶 𝑏 𝑃 , 𝐶 𝑢 𝑃 > (m operator)
– Two components: bottleneck cost: 𝐶 𝑏 𝑃 = max{𝑢(𝑂𝑗): 𝑗 ∈ [1, 𝑚]}
total utilization cost: 𝐶 𝑢 𝑃 = 𝑗=1
𝑚
𝑢(𝑂𝑗)
(m: # operators in P)
– 𝑃 is infeasible if 𝐶 𝑏 𝑃 >1
Optimization Solution
Cost Model – Execution Plan Cost
9
𝐶 𝑏 𝑃 = 1.1
𝐶 𝑢 𝑃 = 2.6
𝑢(𝑂1)=0.5
O3
O1
O2
O4
𝑢(𝑂2)=0.3
𝑢(𝑂3)=1.1 𝑢(𝑂4)=0.7](https://image.slidesharecdn.com/2015-03-05btw-talkv2-150316111411-conversion-gate01/75/Optimization-of-Continuous-Queries-in-Federated-Database-and-Stream-Processing-Systems-9-2048.jpg)


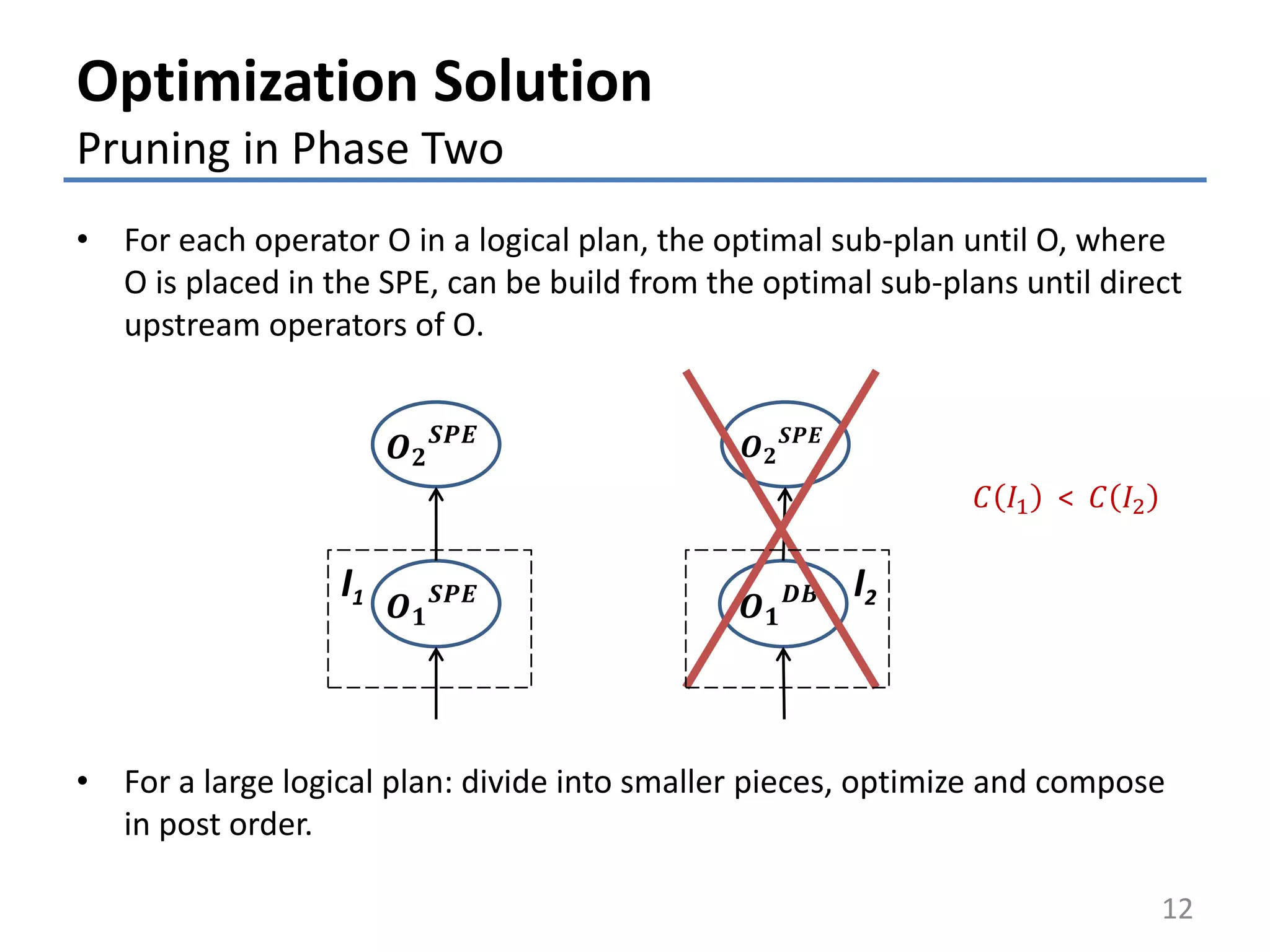
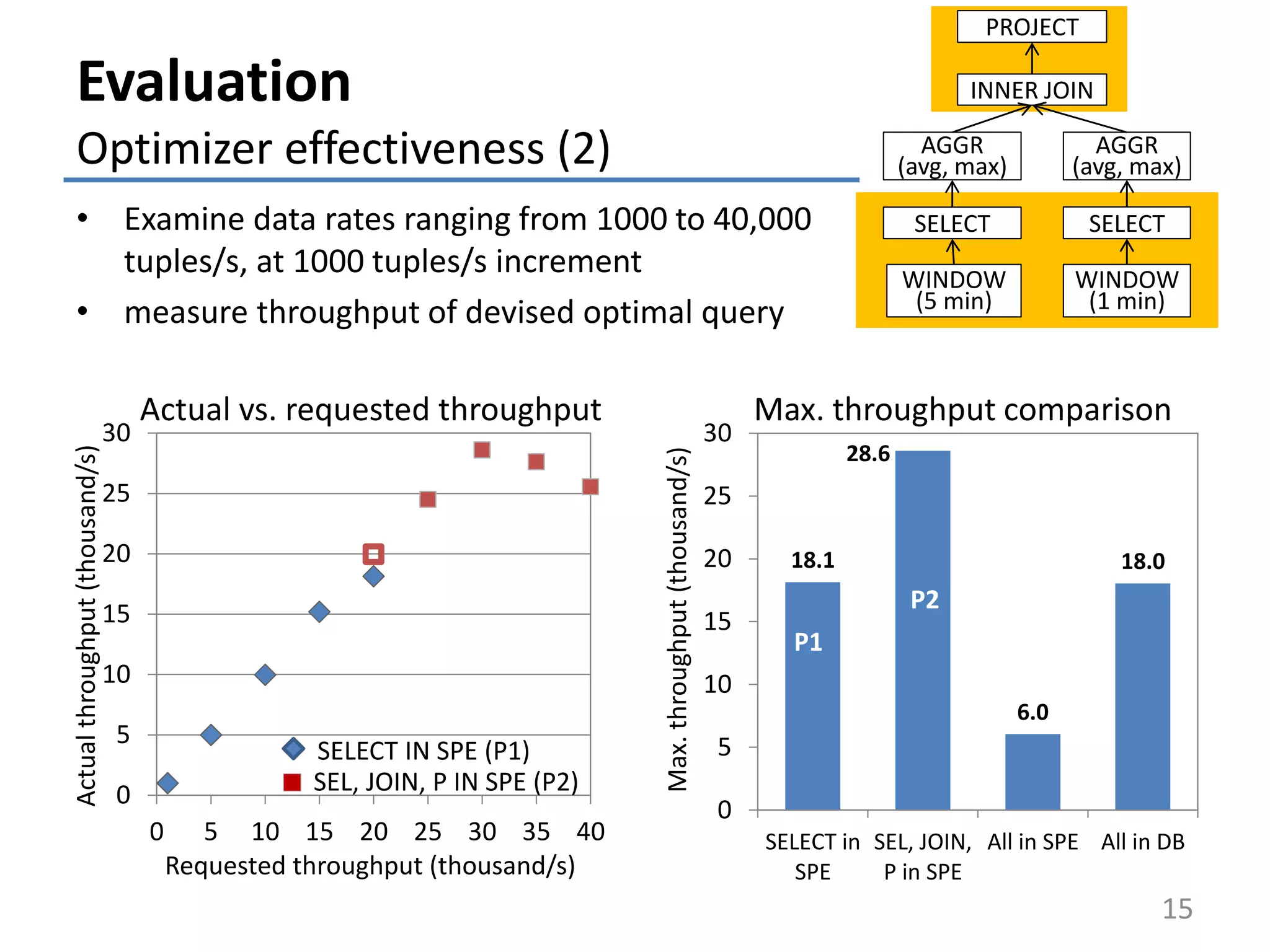
![26.1
3.1
18.7
0
5
10
15
20
25
30
SELECT in
SPE
All in SPE All in DB
Max.throughput(thousand/s)
0
5
10
15
20
25
30
0 5 10 15 20 25 30 35 40
Actualthroughput(thousand/s)
Requested throughput (thousand/s)
Evaluation
Optimizer effectiveness (1)
• Examine 10 source stream data rates picked from
range [1,000, 40,000] (tuples/s)
• measure throughput of devised optimal query
14
Max. throughput comparisonActual vs. requested throughput
PROJECT
INNER JOIN
AGGR (avg)
SELECT SELECT
WINDOW
(5 min)
WINDOW
(5 min)
AGGR (cnt)
SELECT IN SPE](https://image.slidesharecdn.com/2015-03-05btw-talkv2-150316111411-conversion-gate01/75/Optimization-of-Continuous-Queries-in-Federated-Database-and-Stream-Processing-Systems-14-2048.jpg)

![References
[AN04] Ayad, A. M. & Naughton, J. F., Static Optimization of Conjunctive Queries with Sliding Windows over
Infinite Streams, SIGMOD, 2004
[FKC+09] Franklin, M. J.; Krishnamurthy, S.; Conway, N.; Li, A., Russakovsky, A. & Thombre, N., Continuous
Analytics: Rethinking query processing in a network-effect world. CIDR, 2009
[KS09] Kraemer, J. & Seeger B., Semantics and implementation of continuous sliding window queries over data
streams, ACM TODS, 2009
[BCD+10] Botan, I.; Cho, Y.; Derakhshan, R.; Dindar, N.; Gupta, A.; Haas, L. M.; Kim, K.; Lee, C.; Mundada, G.;
Shan, M.-C.; Tatbul, N.; Yan, Y.; Yun, B. & Zhang, J. A demonstration of the MaxStream federated stream
processing system. ICDE, 2010
[LMB+10] Liu, M.; Mihaylov, S. R.; Bao, Z.; Jacob, M.; Ives, Z. G.; Loo, B. T. & Guha, S. SmartCIS: integrating
digital and physical environments. SIGMOD Record, 2010
[LIM+12] Liarou, E.; Idreos, S.; Manegold, S. & Kersten, M. MonetDB/DataCell: online analytics in a streaming
column-store, PVLDB, 2012
[LHB13] Lim, H.; Han, Y. & Babu, S. How to Fit when No One Size Fits, CIDR, 2013
[Ji13] Ji, Y., Database support for processing complex aggregate queries over data streams , EDBT Workshops,
2013
[CDK+14] Çetintemel, U.; Du, J.; Kraska, T.; Madden, S.; Maier, D.; Meehan, J.; Pavlo, A.; Stonebraker, M.;
Sutherland, E.; Tatbul, N.; Tufte, K.; Wang, H. & Zdonik, S. B., S-Store: A streaming NewSQL system for big
velocity applications, PVLDB, 2014
[DLB+11] Daum, M.; Lauterwald, F.; Baumgärtel, P.; Pollner, N. & Meyer-Wegener, K., Efficient and Cost-aware
Operator Placement in Heterogeneous Stream-processing Environments, DEBS, 2011
19](https://image.slidesharecdn.com/2015-03-05btw-talkv2-150316111411-conversion-gate01/75/Optimization-of-Continuous-Queries-in-Federated-Database-and-Stream-Processing-Systems-19-2048.jpg)

![Query Optimization Problem
State-of-the-Art
21
CQ
optimization
Federation
context
Optimization
Granularity
Feasibility-
dependent opt.
[VN02, AN04] √ operator √
Traditional distributed,
federated DBMS, e.g.,
[DH02, BCE+05]
√ operator
MaxStream [BCD+10] √
Cyclops [LHB13] √ √ query
ASPEN [LMB+10] √ √ operator
Operator placement,
e.g., [DLB+11]
√ √/X operator
query](https://image.slidesharecdn.com/2015-03-05btw-talkv2-150316111411-conversion-gate01/75/Optimization-of-Continuous-Queries-in-Federated-Database-and-Stream-Processing-Systems-21-2048.jpg)
![Semantics
• Adopt the abstract semantics defined in [ABW06], which is based on:
– Two data types:
• Stream (S): a possibly infinite bag of elements <s, t>, where s is a
tuple belonging to the schema of S and t is the timestamp of s.
• Time-varying Relation (R): a mapping from T to a finite but
unbounded bag of tuples belonging to the schema of R.
– Three classes of query operators:
• stream-to-relation (S2R) operators: produce one relation from one
stream (e.g., window operators)
• relation-to-relation (R2R) operators: produce one relation from
one or more relations.
• relation-to-stream (R2S) operators: produce one stream from one
relation.
22](https://image.slidesharecdn.com/2015-03-05btw-talkv2-150316111411-conversion-gate01/75/Optimization-of-Continuous-Queries-in-Federated-Database-and-Stream-Processing-Systems-22-2048.jpg)
![Introduction
Build SPE on Top of DBMS Kernel
• Exploit and merge technologies from both worlds in an integration way.
– Truviso Continuous Analytics [FKC+09], HP Lab work [CH10], DataCell
[LIM+12], S-Store [CDK+14]
25
SPE + DBMS
one-shot
queries query results
stored data
continuous query
streaming data query results
in-memory
table
buffers
in UDFs](https://image.slidesharecdn.com/2015-03-05btw-talkv2-150316111411-conversion-gate01/75/Optimization-of-Continuous-Queries-in-Federated-Database-and-Stream-Processing-Systems-25-2048.jpg)

The document discusses optimizing continuous queries (CQ) for federated execution using a stream processing engine (SPE) and a column-oriented in-memory database (CIMDB). It presents a static cost-based optimizer that enhances traditional techniques by incorporating the feasibility of CQs to maximize throughput, achieving performance improvements of up to 8.5 times over pure SPE processing and 1.8 times over pure CIMDB processing. The findings demonstrate that this optimization approach is effective for real-world applications, such as analyzing energy consumption data.

























![Resource Aware Scheduling for Hadoop [Final Presentation]](https://cdn.slidesharecdn.com/ss_thumbnails/fyppresentationfinal-120226092754-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








































































