Download to read offline








![RETE network construction
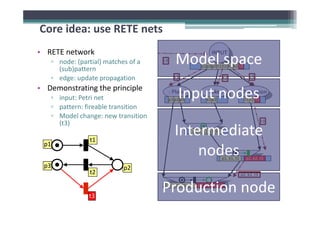
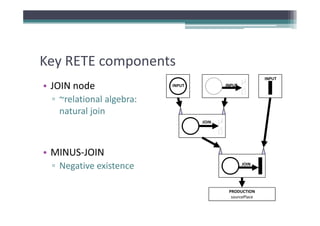
RETE network construction
• Key: pattern decomposition
y p p
▫ Pattern = set of constraints (defined over pattern variables)
▫ Types of constraints: type, topology (source/target),
hierarchy (containment), attribute value, generics
h h ( ) b l
(instanceOf/supertypeOf), injectivity, [negative] pattern
calls, …
calls, …
• Construction algorithm (roughly)
▫ 1. Decompose the pattern into elementary constraints (*)
▫ 2. Process the elementary constraints and connect them
with appropriate intermediate nodes (JOIN, MINUS‐JOIN,
UNION, …)
UNION )
▫ 3. Create terminator production node](https://image.slidesharecdn.com/gramot08-rath-120608102649-phpapp01/85/Incremental-pattern-matching-in-the-VIATRA2-model-transformation-system-11-320.jpg)







![Improving performance
Improving performance
• Strategies
▫ Improve the construction algorithm
Memory efficiency (node sharing)
Memory efficiency (node sharing)
Heuristics‐driven constraint enumeration (based on
p
pattern [and model space] content)
[ p ] )
▫ Parallelism
Update the RETE network in parallel with the
transformation
Parallel network construction
▫?](https://image.slidesharecdn.com/gramot08-rath-120608102649-phpapp01/85/Incremental-pattern-matching-in-the-VIATRA2-model-transformation-system-21-320.jpg)






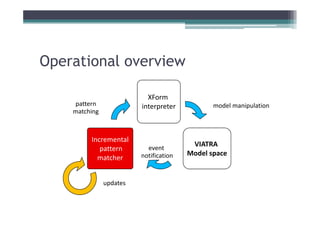
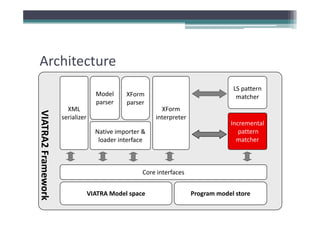
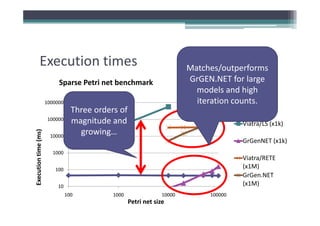
Incremental pattern matching allows model transformations to update target models incrementally based on changes to the source model. The VIATRA model transformation system implements incremental pattern matching using a RETE network to efficiently retrieve matching sets as models change. Benchmark results show near-linear performance for sparse models and constant execution time for certain patterns. Future work includes improving construction algorithms and enabling event-driven live transformations.