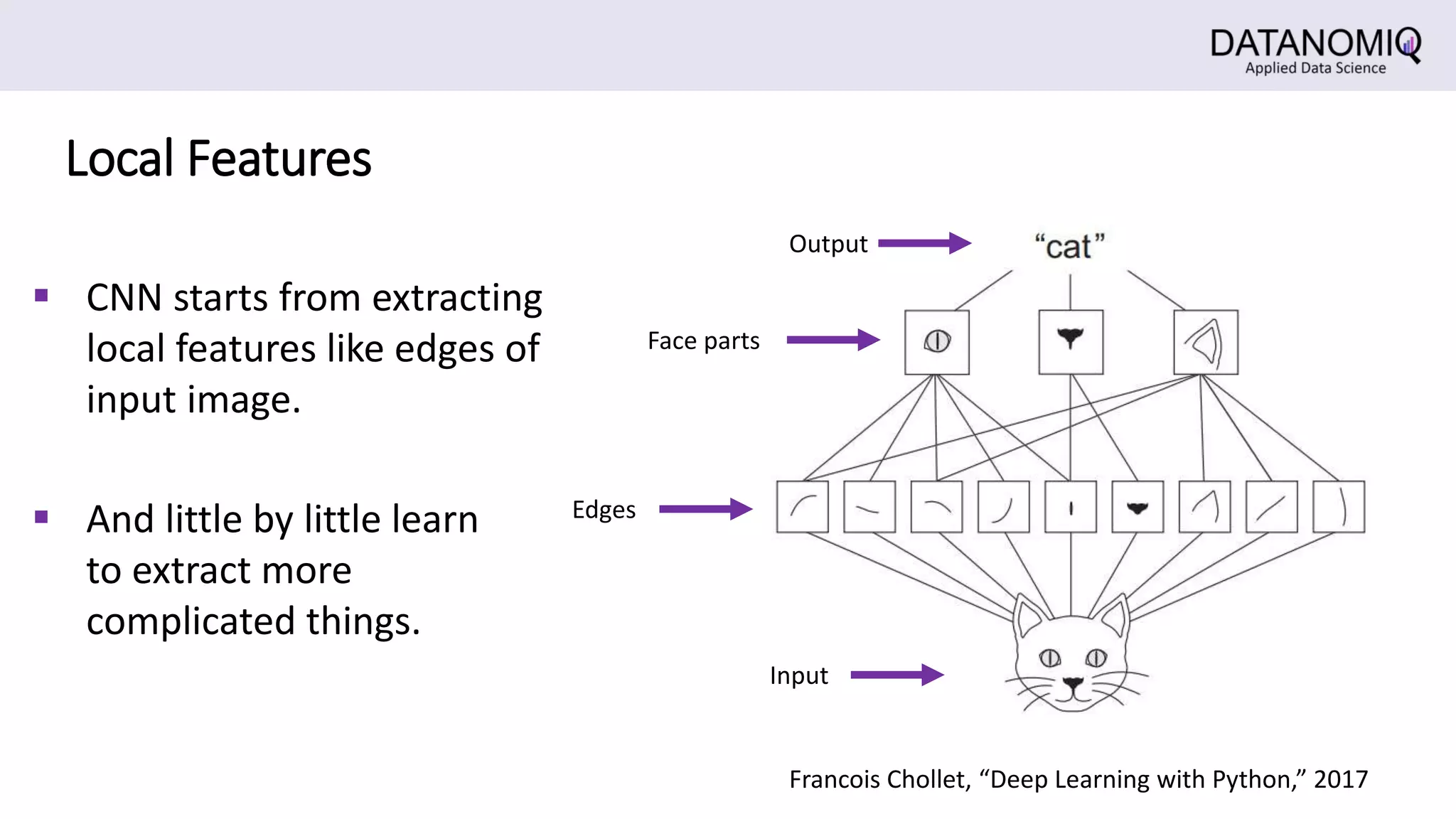
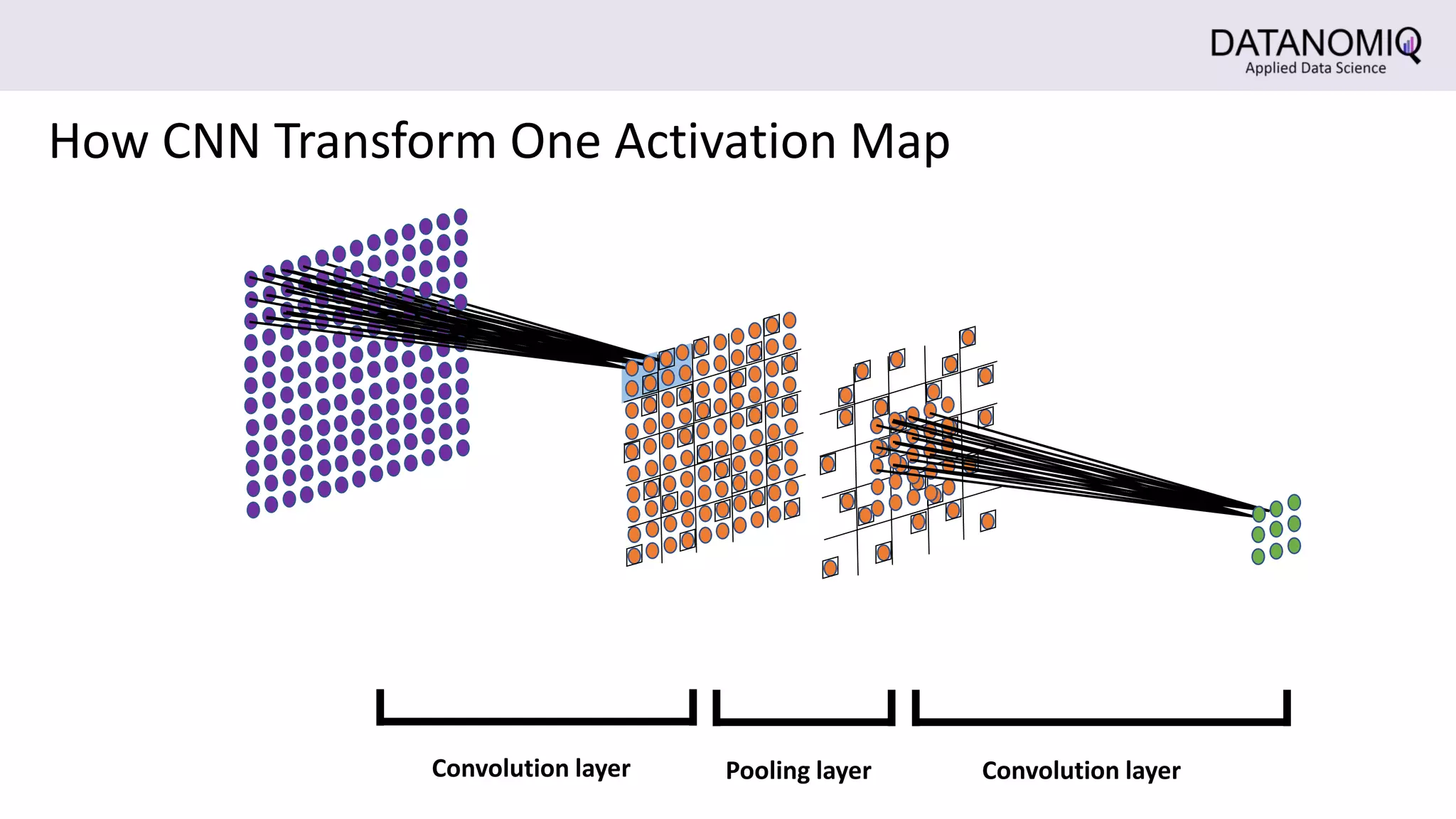
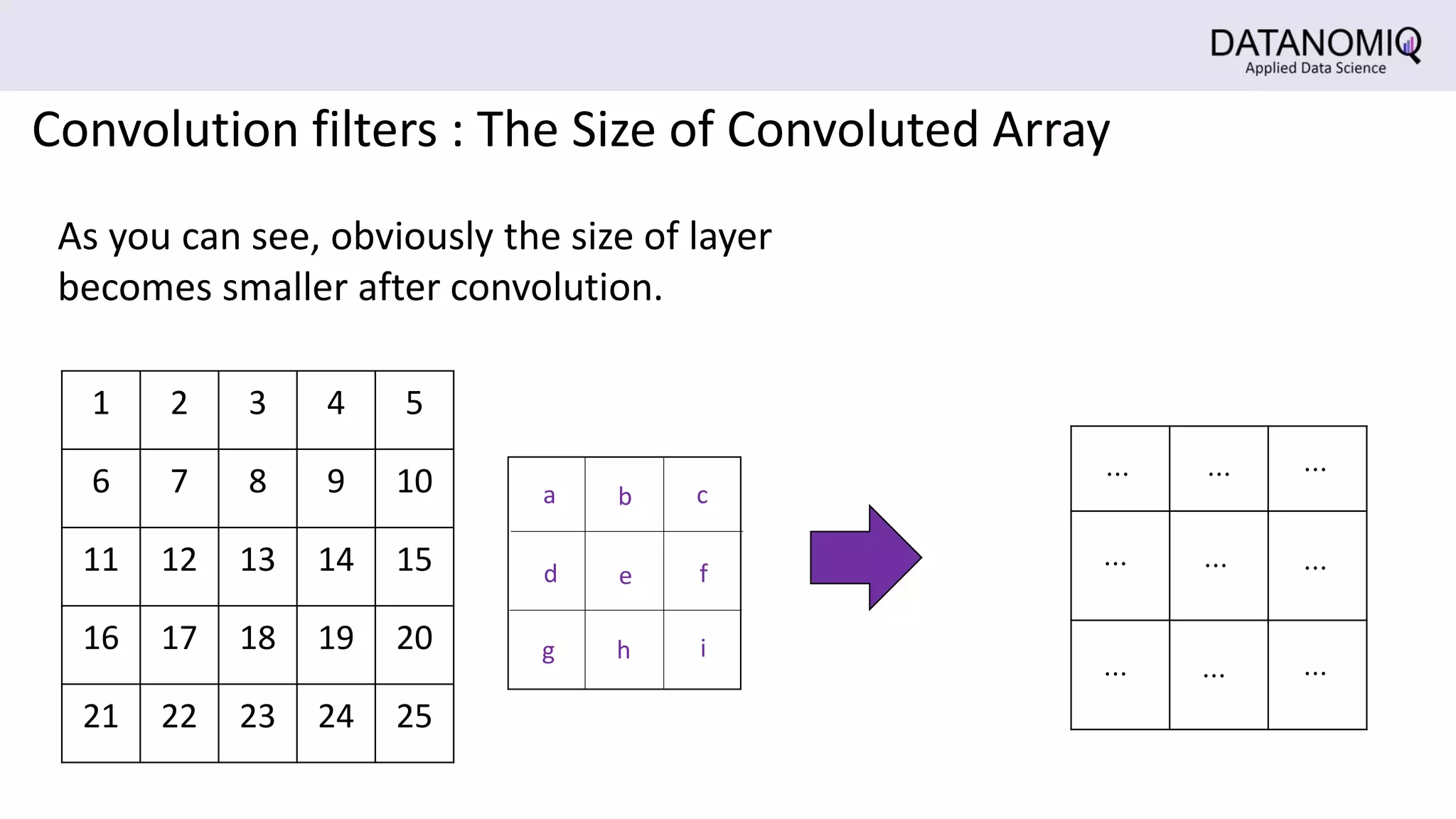
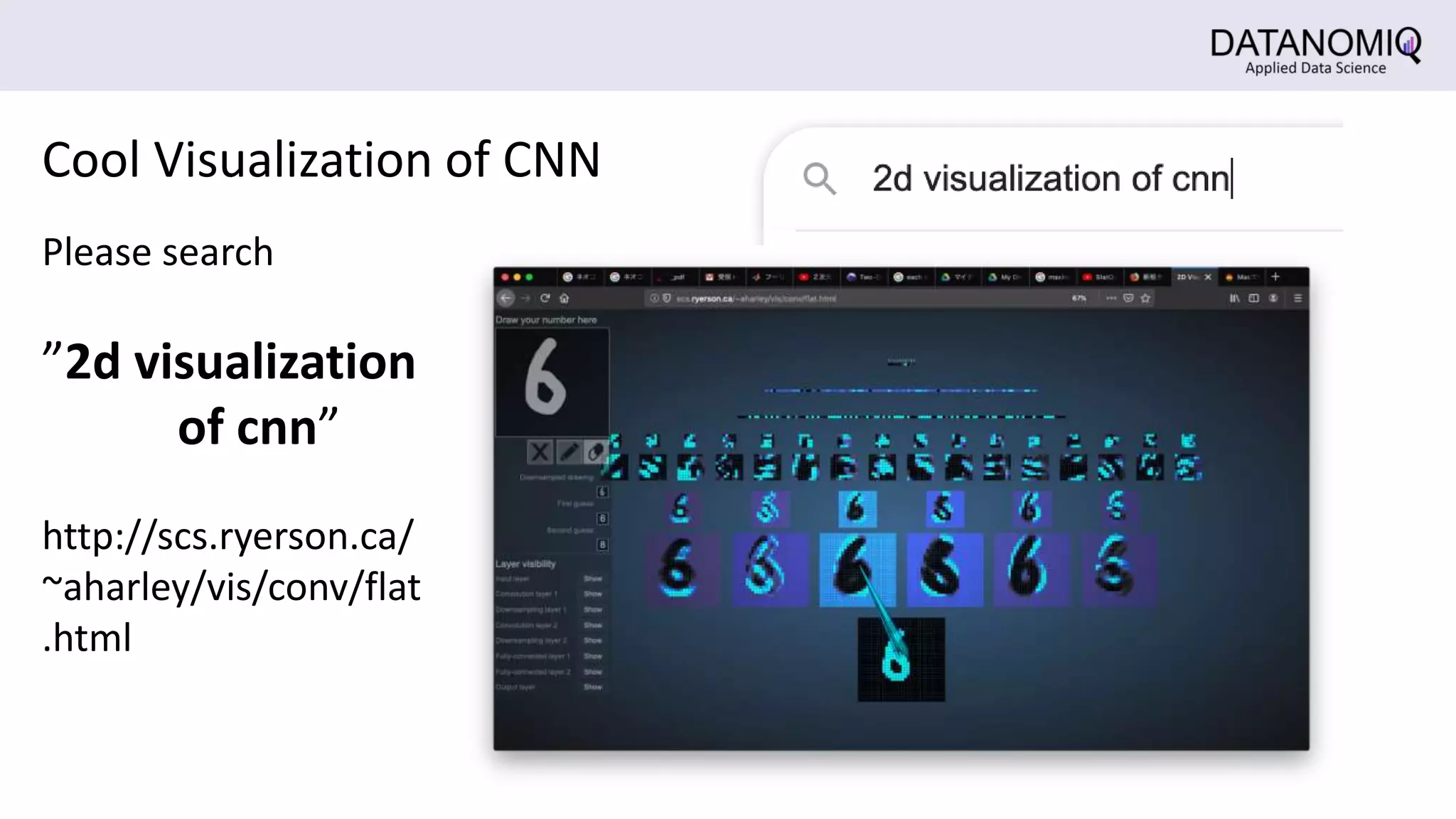
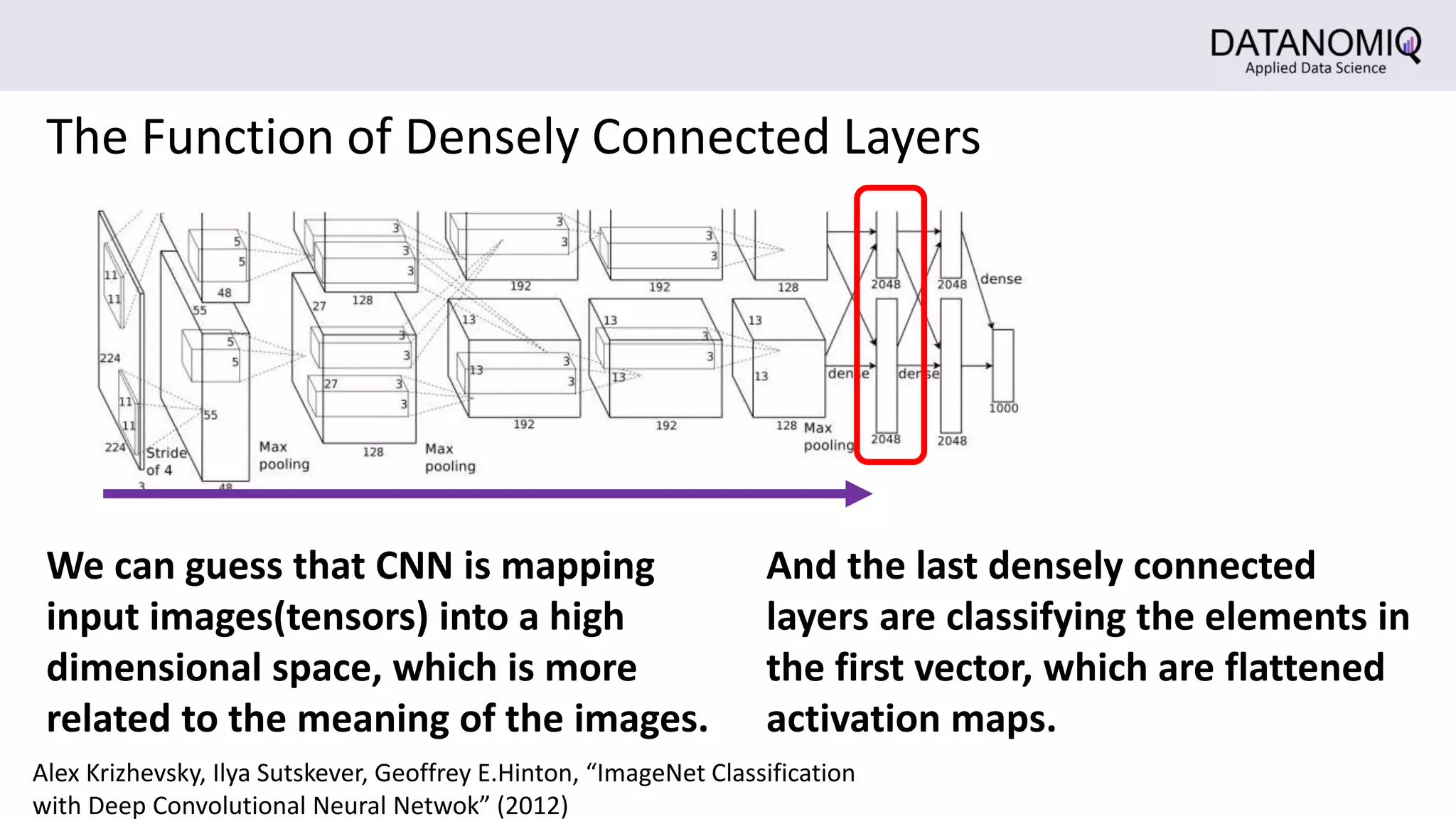
The document discusses Convolutional Neural Networks (CNNs) and their application in image processing, highlighting how CNNs are designed to learn features from images rather than relying on predefined descriptors. It explains the importance of local feature extraction, the role of convolution and pooling layers in reducing computational costs, and how CNNs can classify images efficiently. Additionally, it touches on the historical context of CNNs and visualization techniques for understanding image recognition processes within these networks.