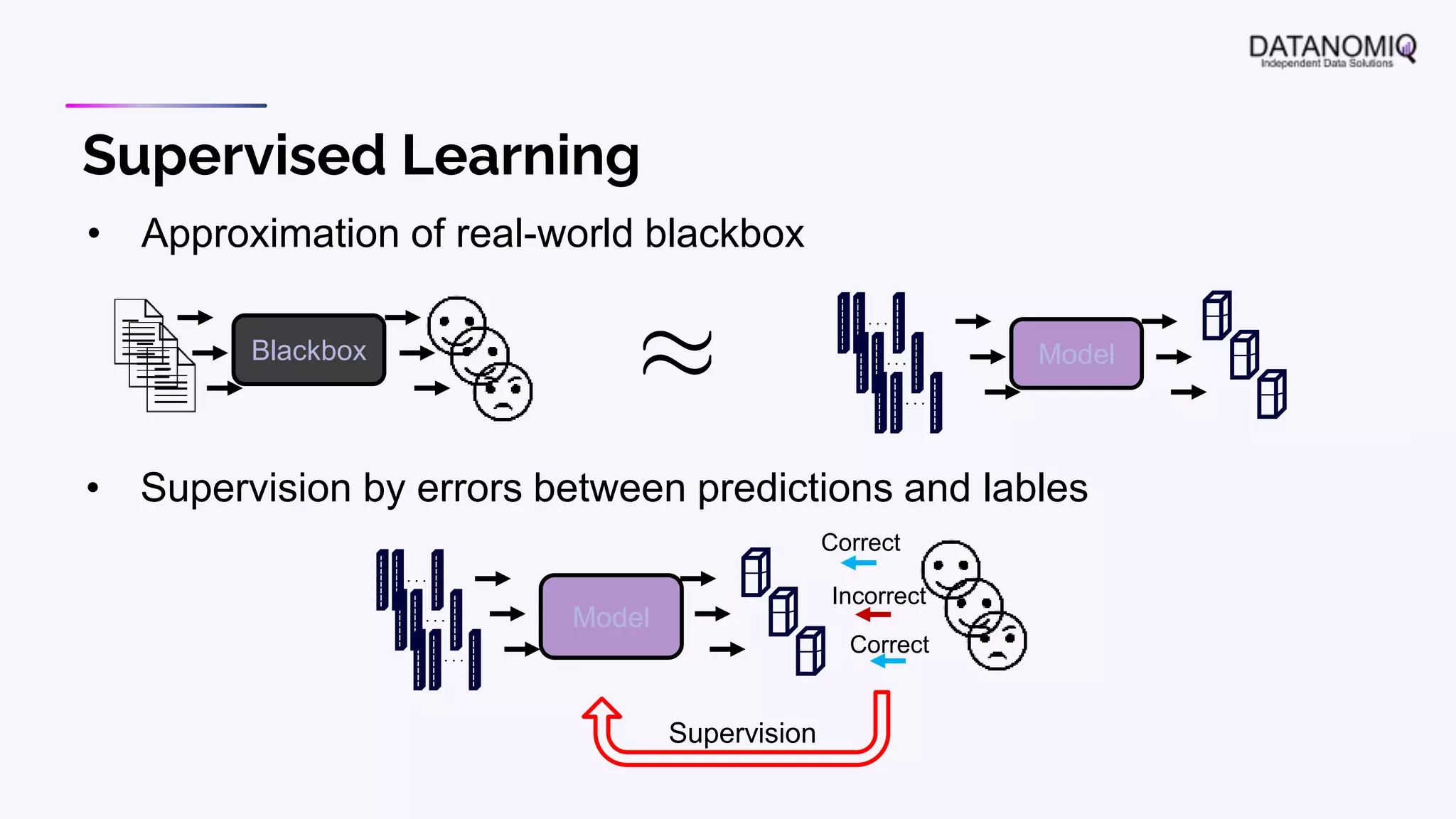
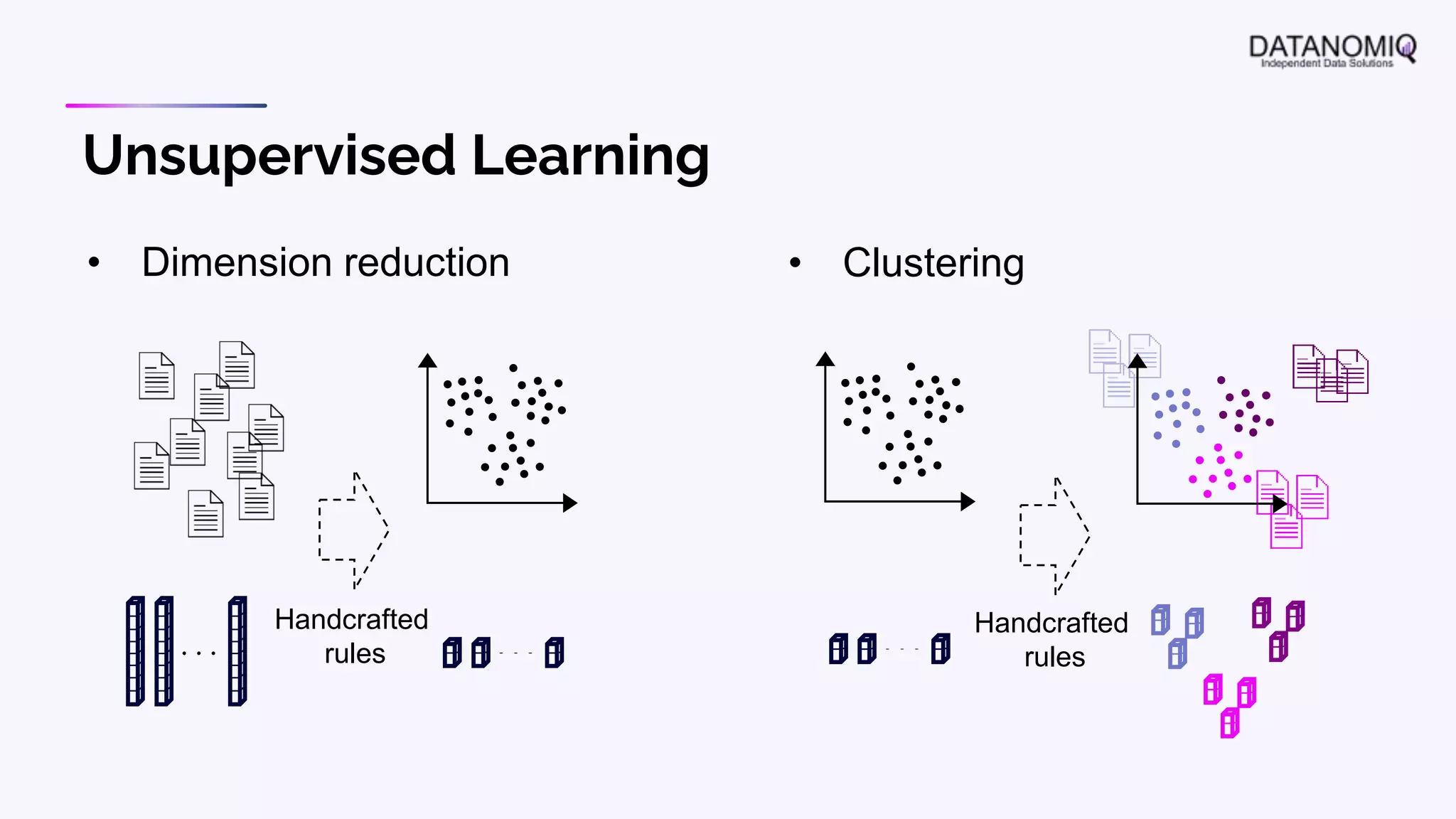
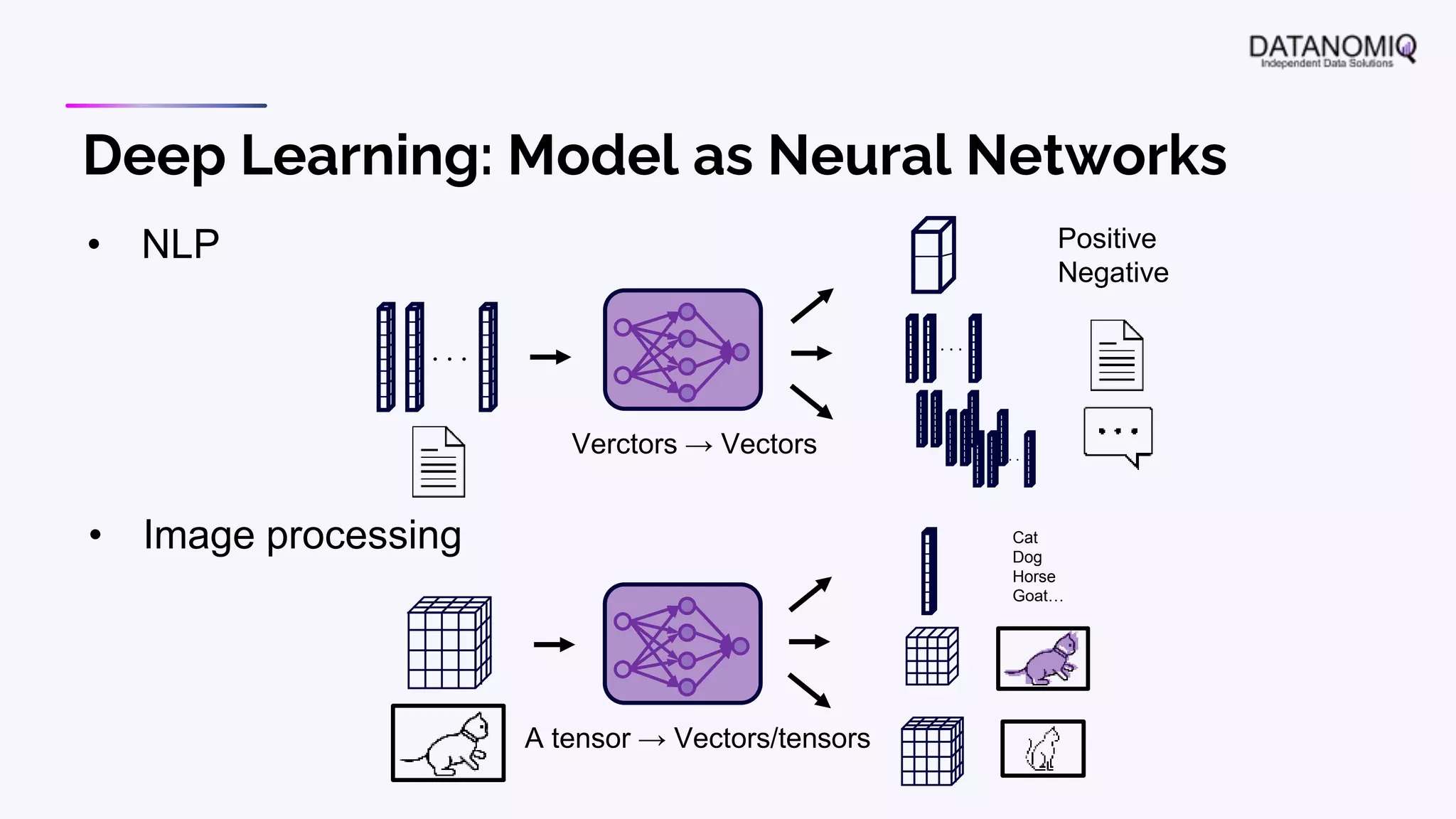
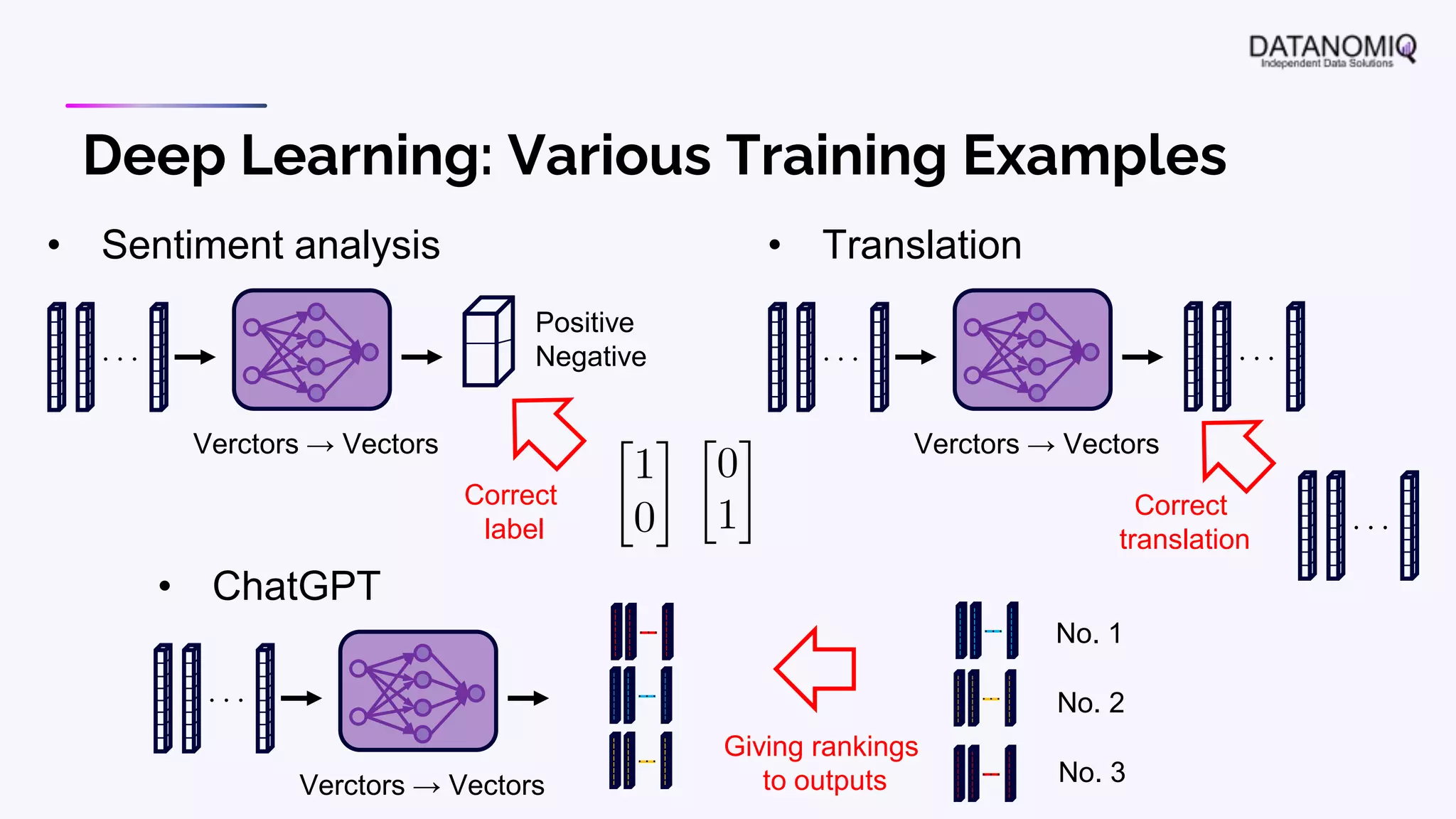
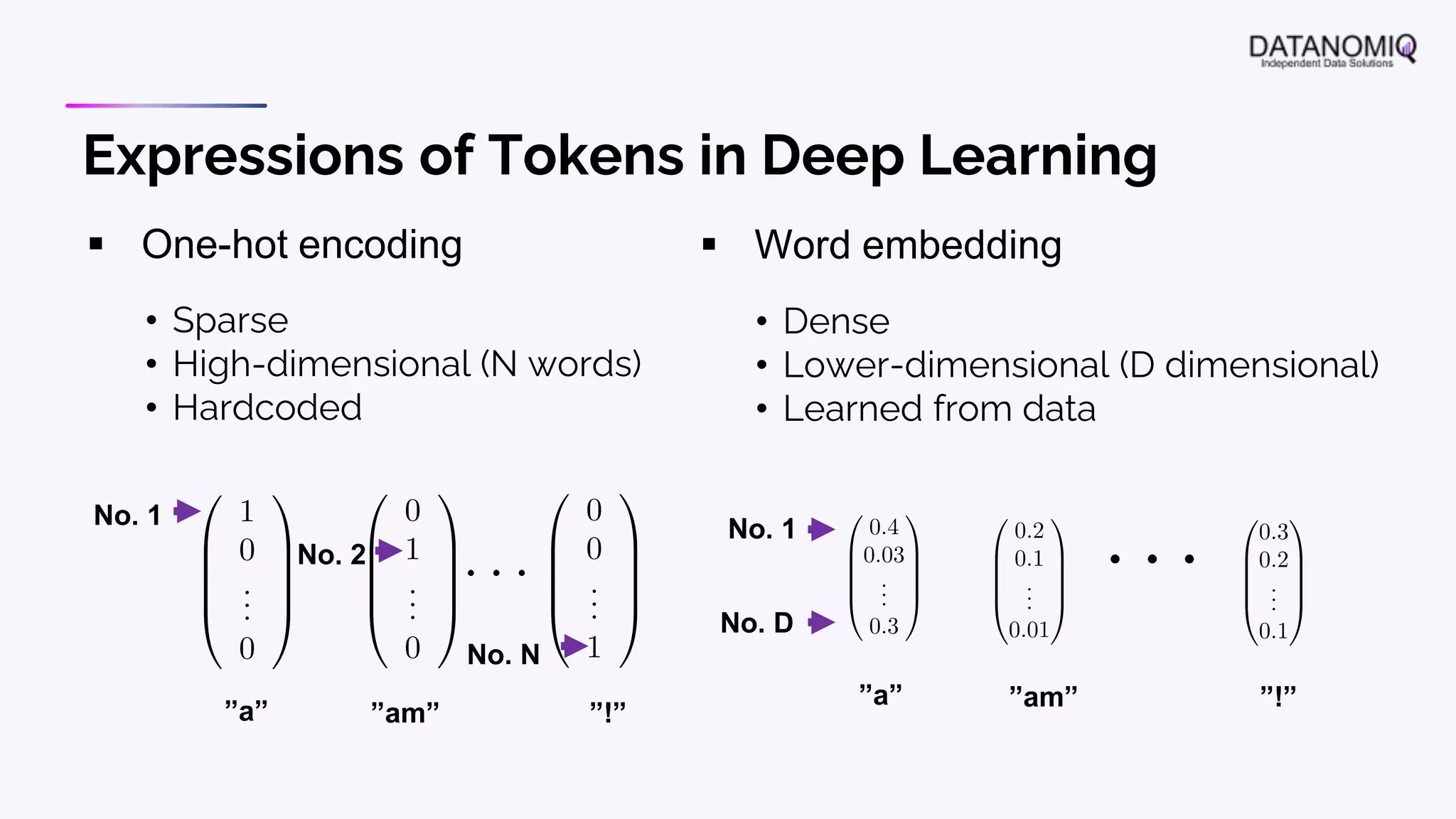
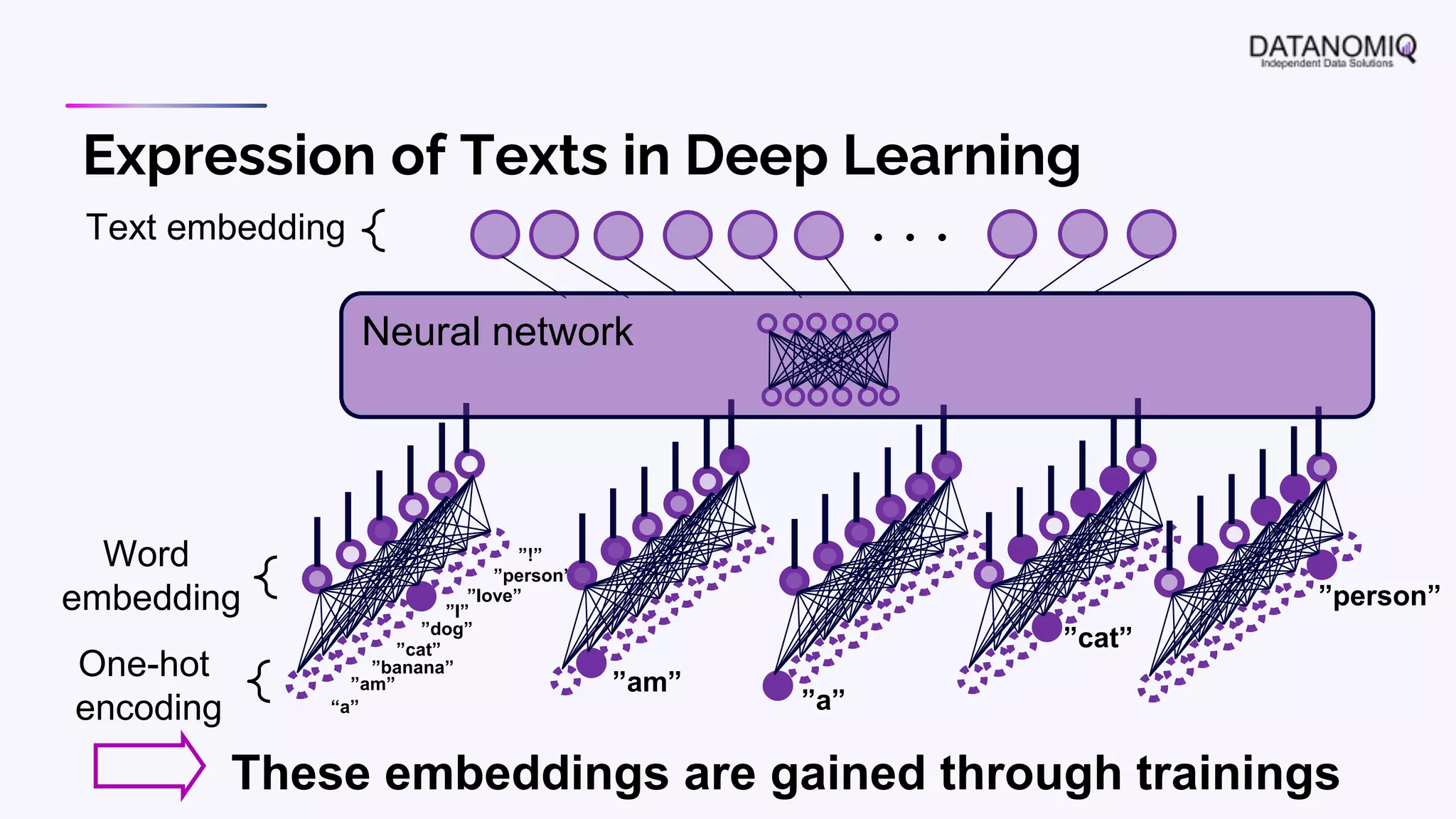
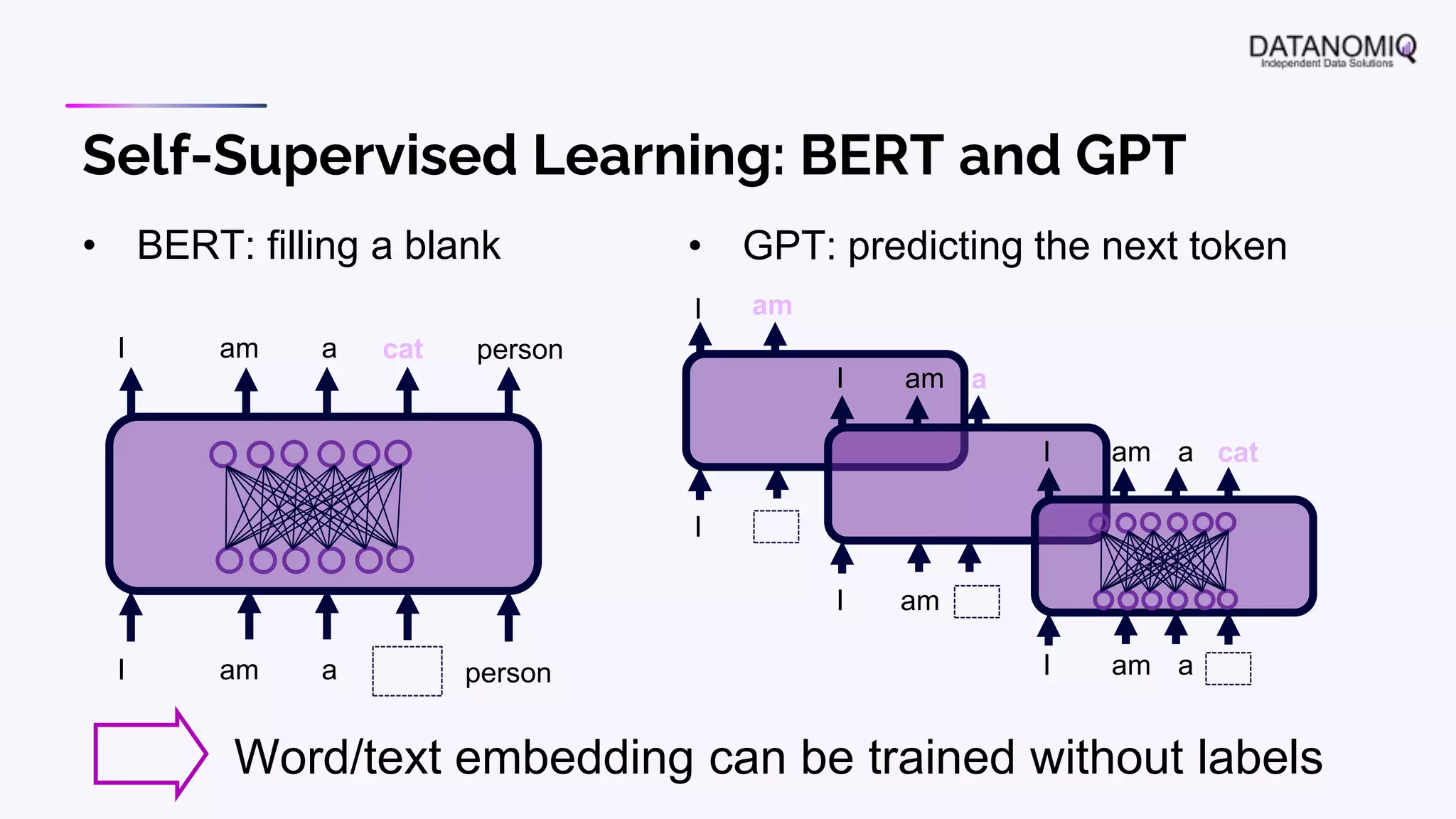
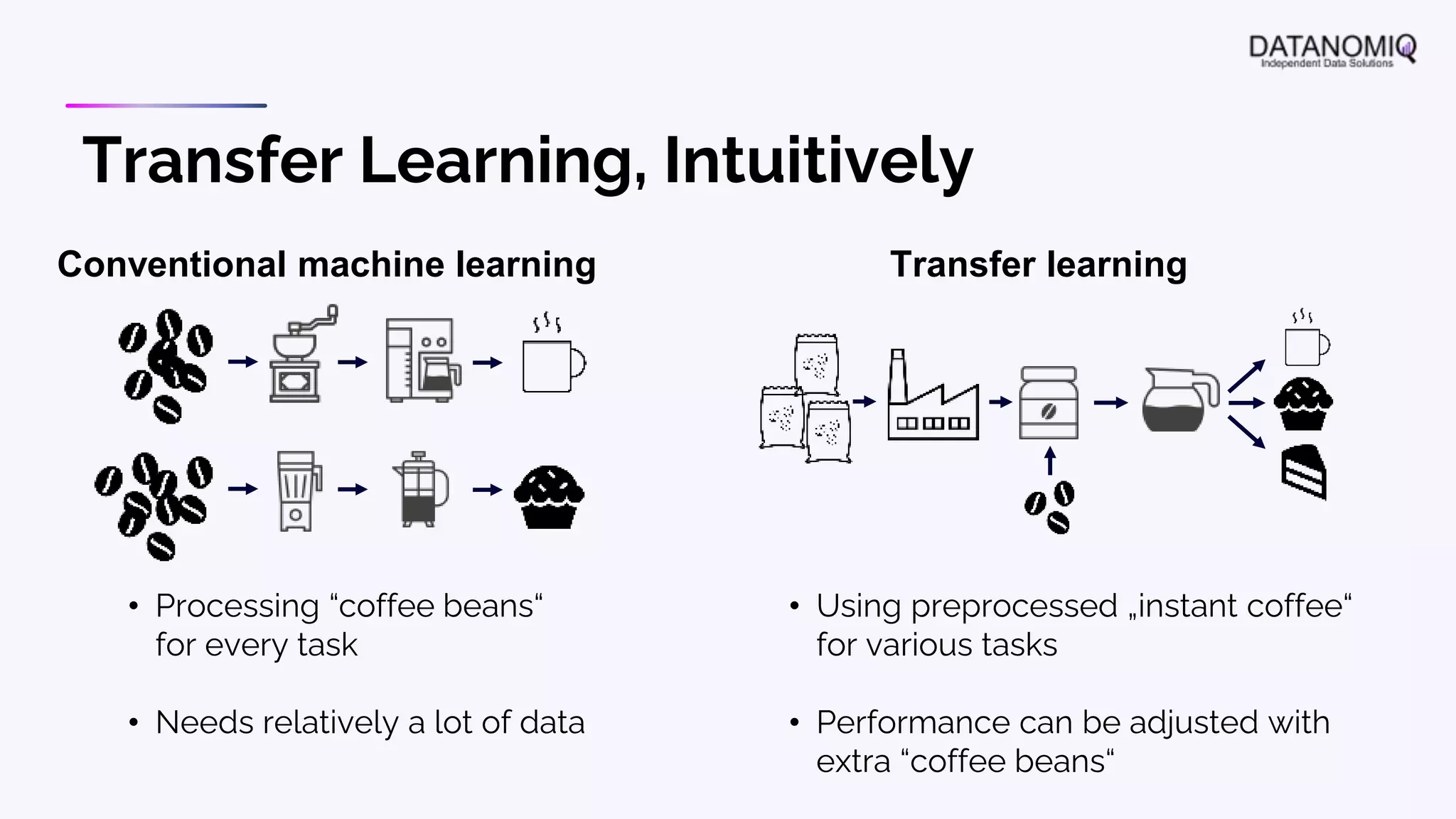
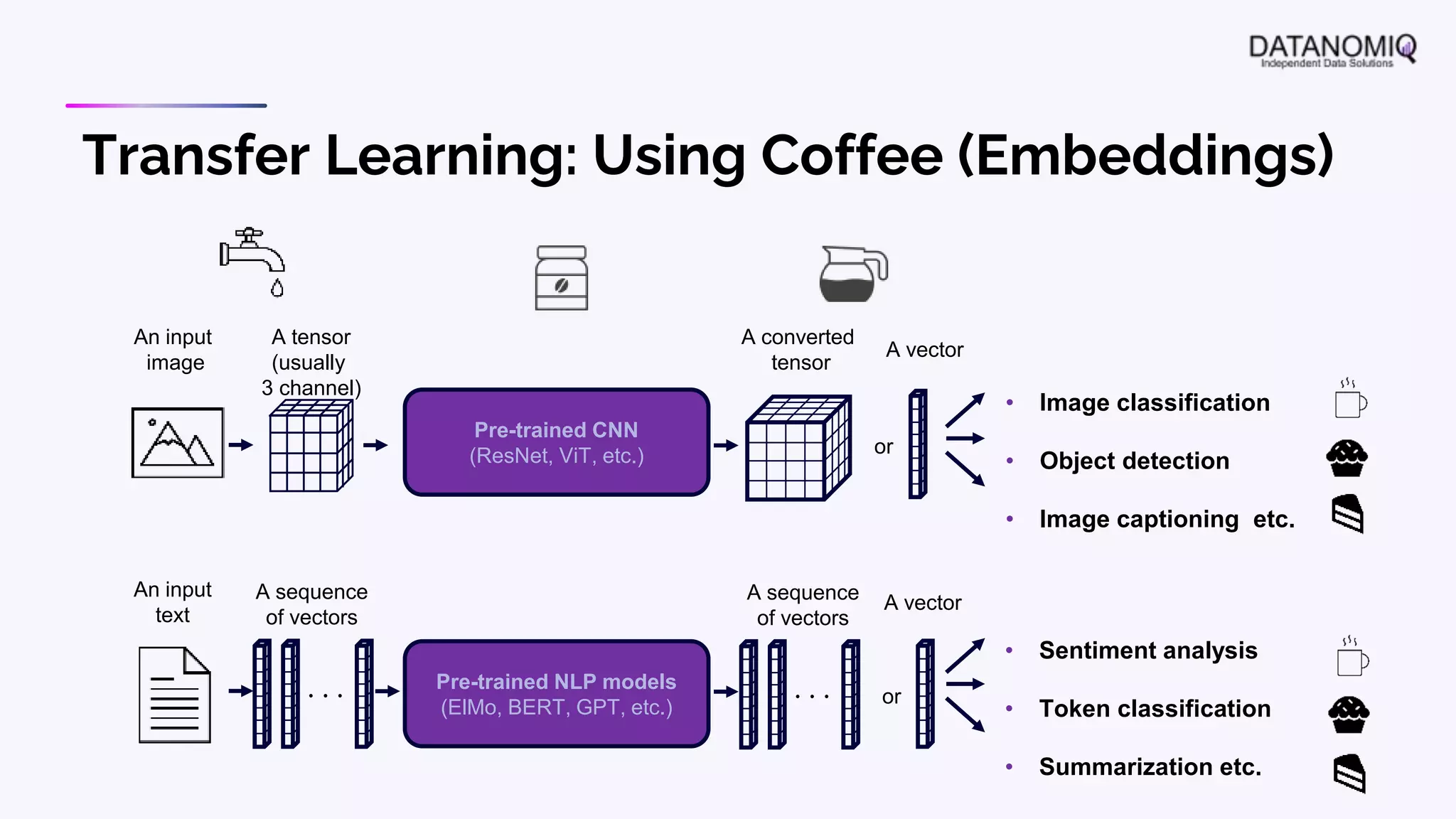
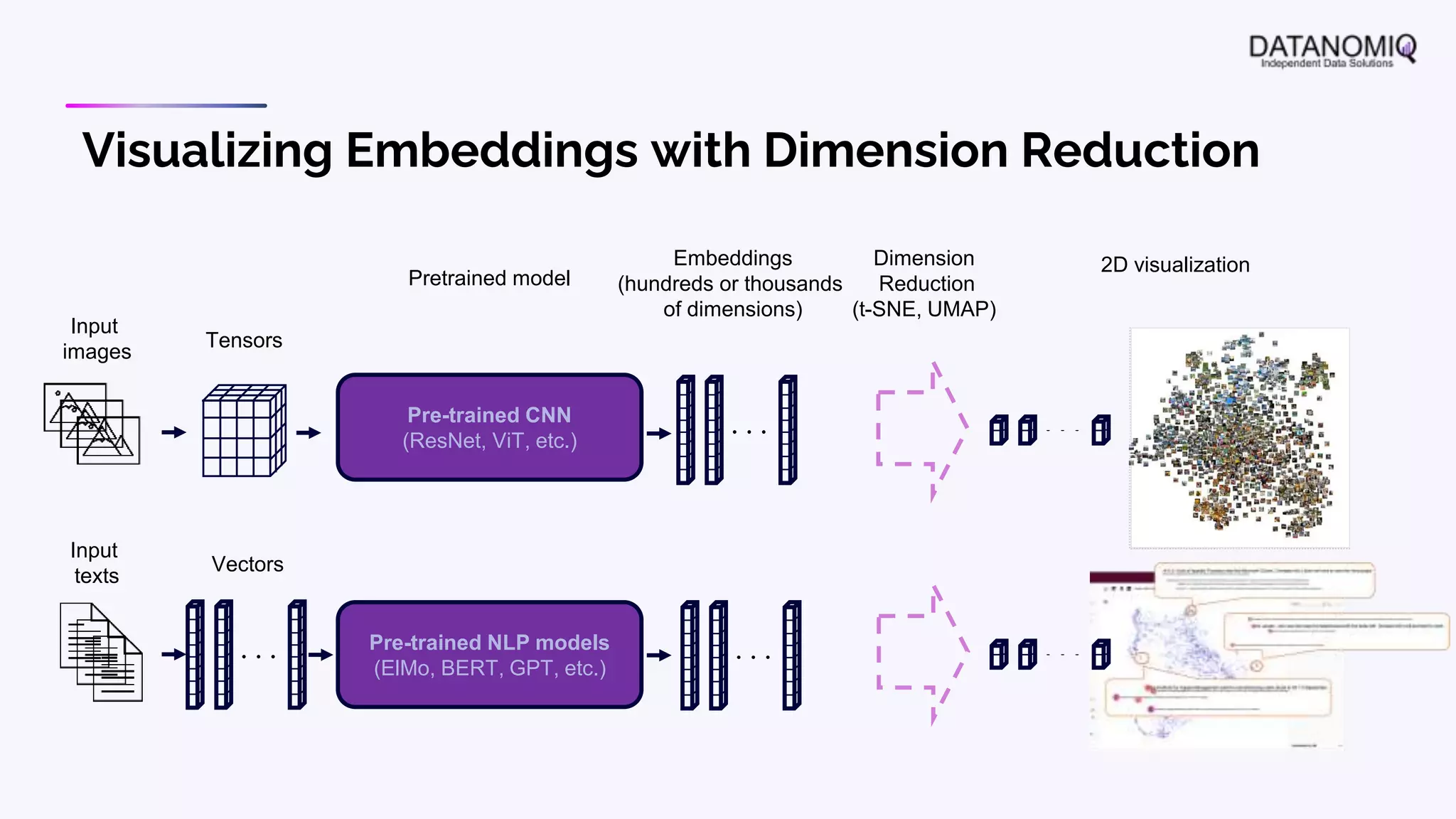
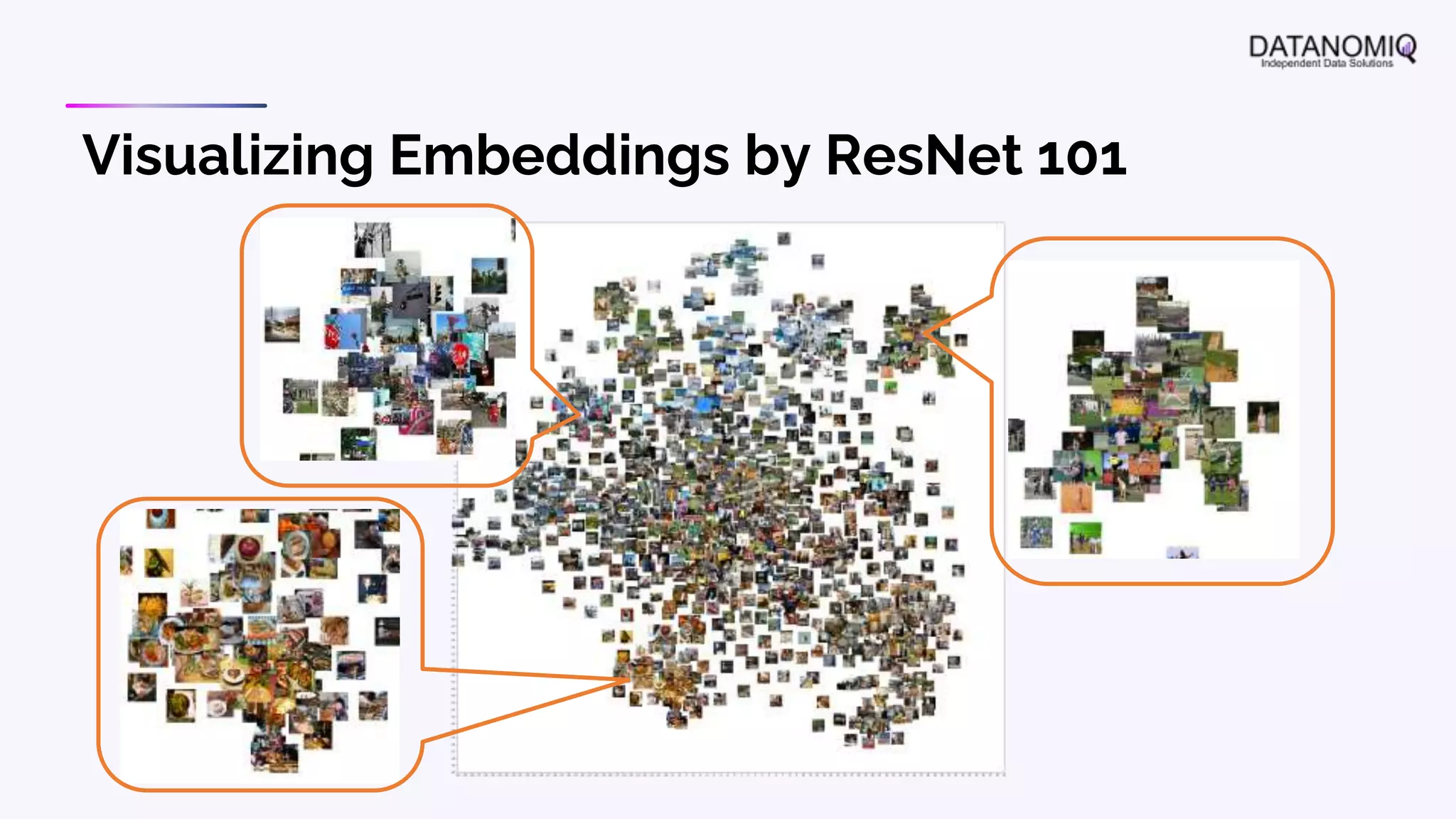
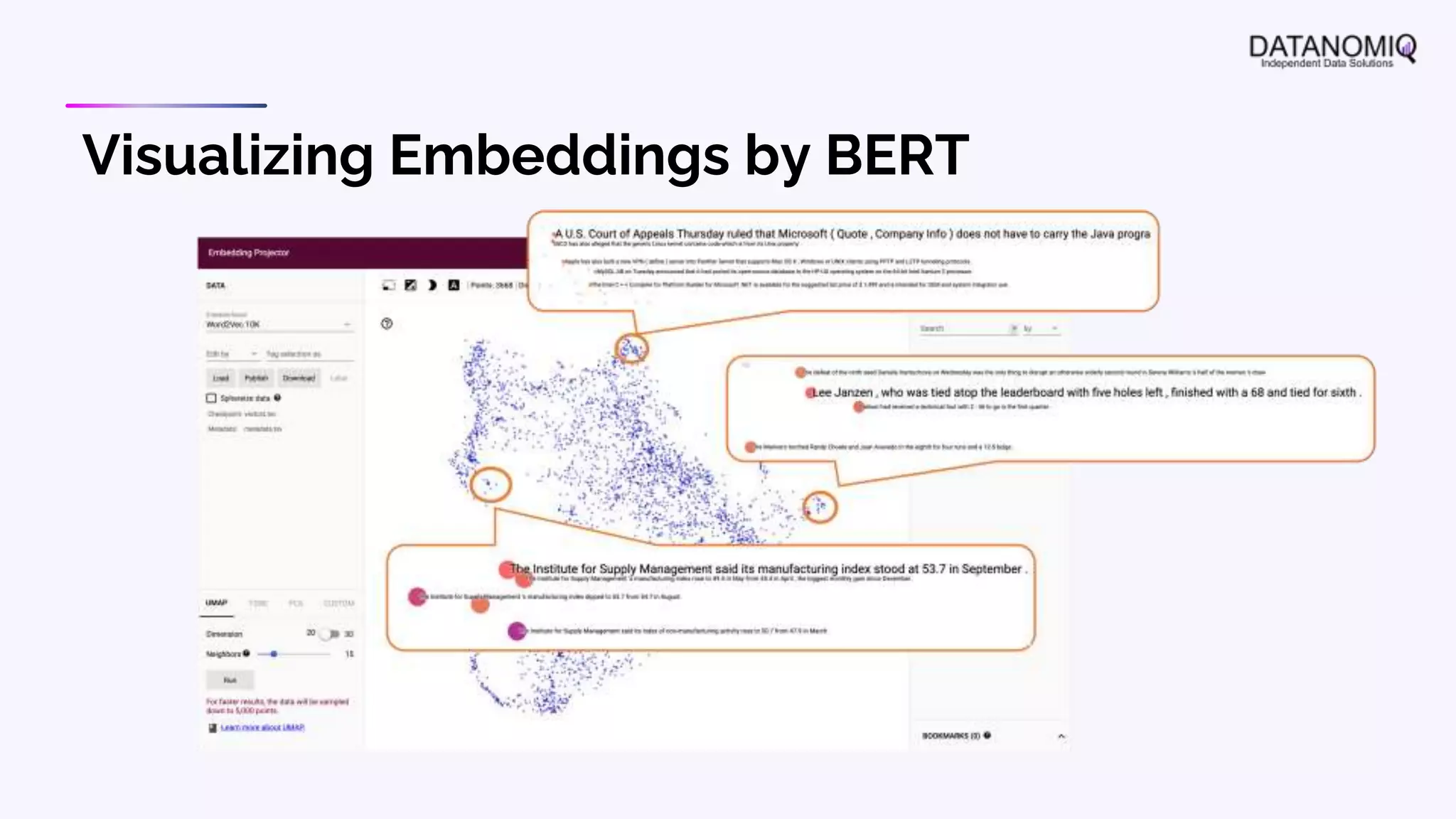
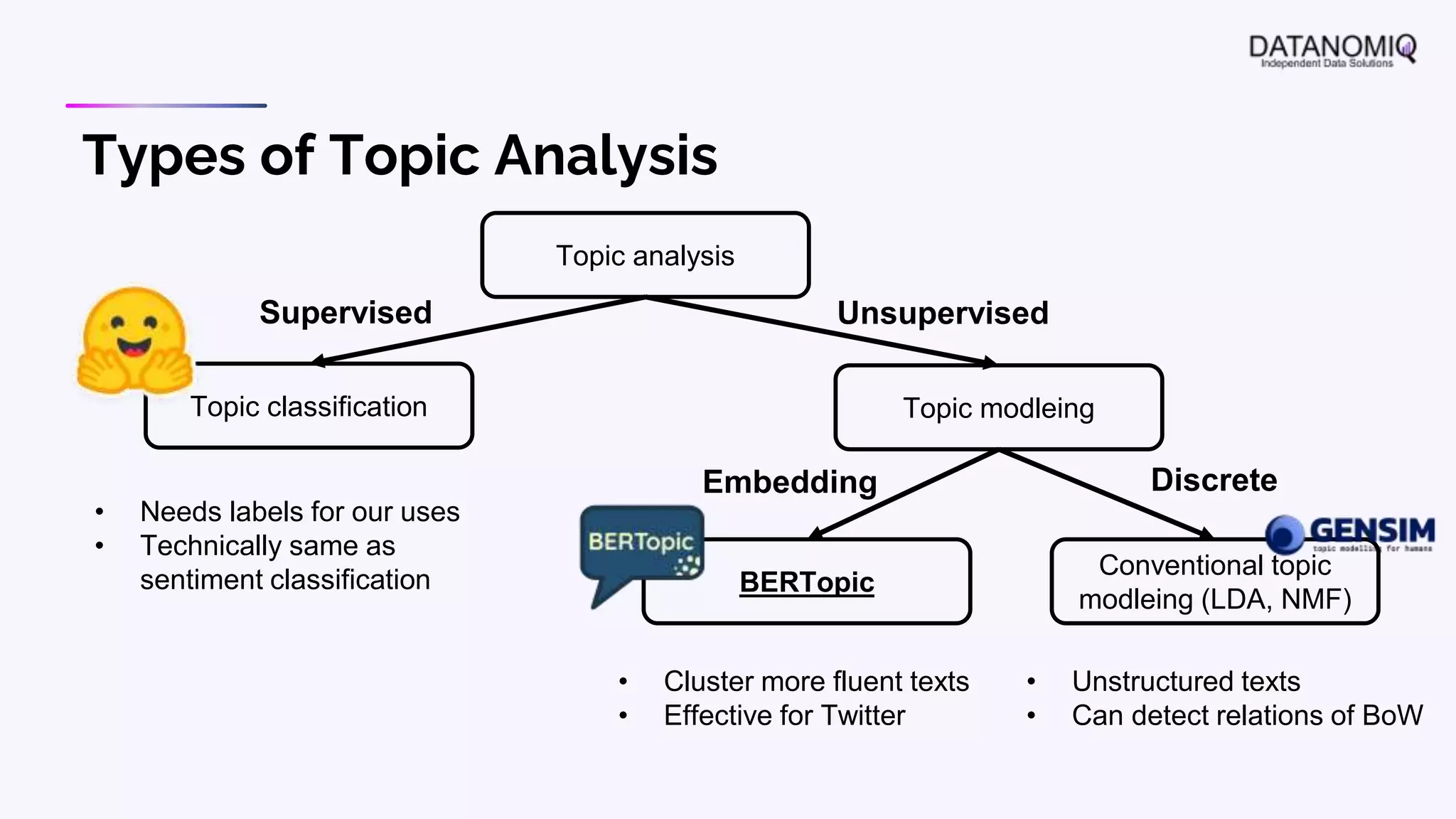
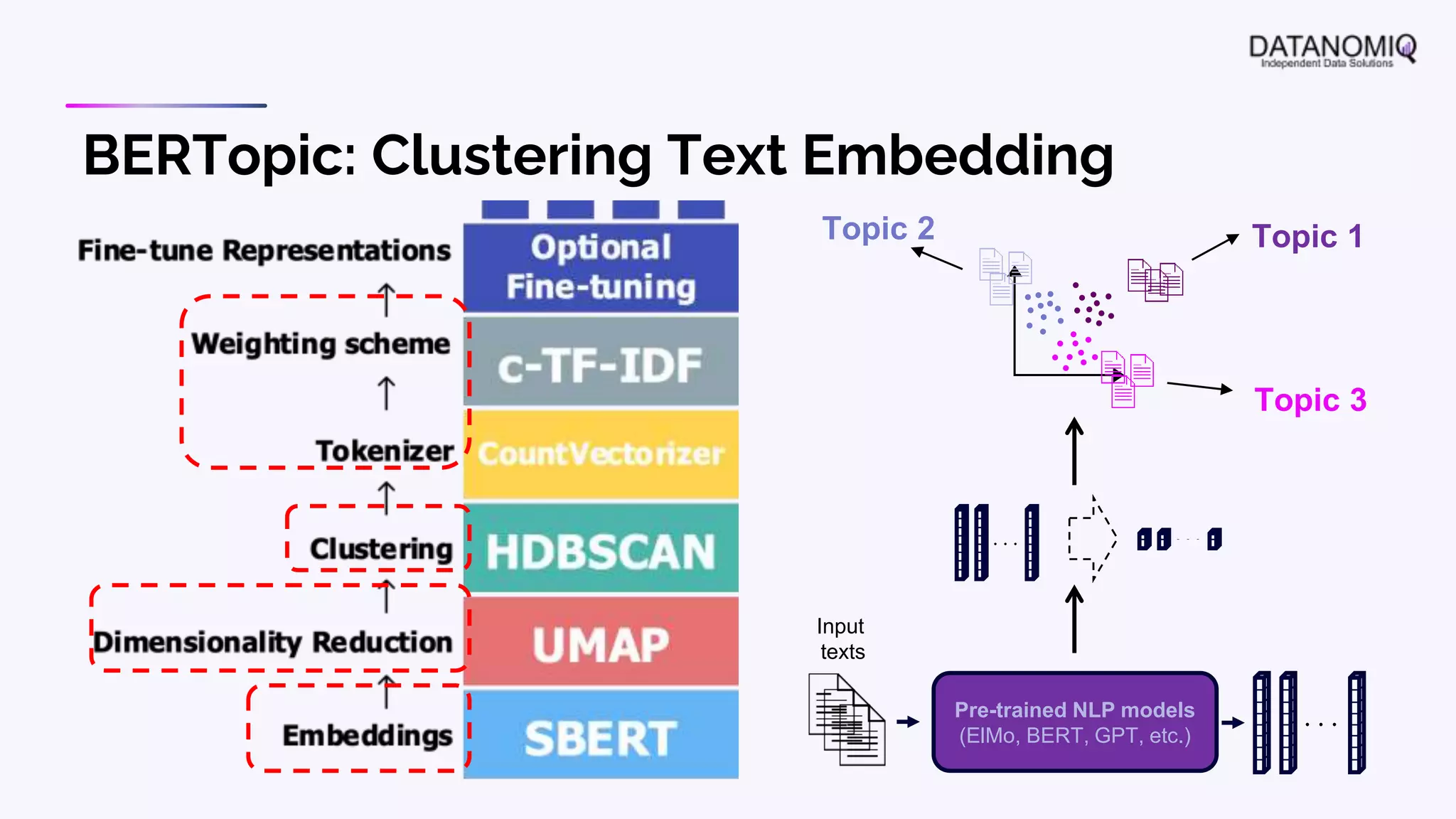
The document discusses various aspects of natural language processing (NLP) using deep learning techniques, emphasizing supervised and unsupervised learning methods, including transfer learning and the use of pre-trained models. It covers concepts such as word embeddings, token embeddings, and methods for visualizing embeddings through dimensionality reduction. Additionally, it explores topic analysis and classification, outlining approaches like BERT and traditional topic modeling techniques.


![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)


































































