This document provides an overview of convolutional neural networks (CNNs or ConvNets). It discusses the history of ConvNets from their origins in modeling the visual cortex to modern applications in computer vision tasks. The document explains what ConvNets are through their use of filters, activation maps, and pooling layers. It also discusses methods for visualizing and understanding what different layers of ConvNets are learning from images.



![HISTORY
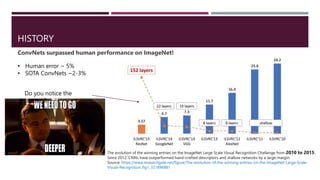
1998.. First ConvNet paper!
Gradient-based learning applied to document recognition [LeCun, Bottou, Bengio, Haffner1998]
https://ieeexplore.ieee.org/document/726791
LeNet-5
• Small architecture.
• 60K parameters.
• Used backpropagation.
6 5x5 filters
s=1
Average
pooling
16 5x5 filters
s=1
Average
pooling FC: 120
neurons
FC: 84
neurons
𝑦: 10 outputs (digits)](https://image.slidesharecdn.com/convnets-230620184325-18155a70/85/convnets-pptx-5-320.jpg)
![HISTORY
2012.. AlexNet: One of the most impactful papers in computer vision!
ImageNet Classification with Deep Convolutional Neural Networks [Krizhevsky, Sutskever, Hinton, 2012]
https://papers.nips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
• Winner of ImageNet Competition in 2012.
• Compared to LeNet-5:
• Activation function: ReLU
• Deeper ~60M parameters
• More Data.
• GPU Computation.
• Regularization strategies: Dropout.
AlexNet
It was all about scale.
https://www.image-
net.org/](https://image.slidesharecdn.com/convnets-230620184325-18155a70/85/convnets-pptx-6-320.jpg)
![HISTORY
2013.. ZFNet
Visualizing and Understanding Convolutional Networks [Zeiler, Fergus, NYU, 2013]
https://arxiv.org/abs/1311.2901
• Winner of ImageNet Competition in 2013.
• Compared to AlexNet:
• Used visualization insights to boost
performance.
• Normalization across feature maps.
• Smaller filter size and stride.
• Initial seed for a startup: resulted in to 2 better
submissions on ImageNet.
ZFNet https://www.image-
net.org/](https://image.slidesharecdn.com/convnets-230620184325-18155a70/85/convnets-pptx-7-320.jpg)


![WHAT ARE CNNS LEARNING?
From Yann LeCun slides. Feature visualization of convolutional net trained on ImageNet from [Zeiler & Fergus 2013]:](https://image.slidesharecdn.com/convnets-230620184325-18155a70/85/convnets-pptx-14-320.jpg)



![VISUALIZING LAYERS
Feature visualization of convolutional net trained on ImageNet from [Zeiler & Fergus 2013]:](https://image.slidesharecdn.com/convnets-230620184325-18155a70/85/convnets-pptx-19-320.jpg)
![VISUALIZING LAYERS
Feature visualization of convolutional net trained on ImageNet from [Zeiler & Fergus 2013]:](https://image.slidesharecdn.com/convnets-230620184325-18155a70/85/convnets-pptx-20-320.jpg)
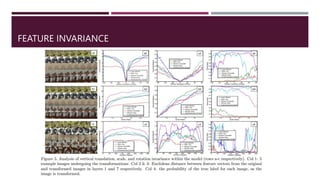
![VISUALIZING LAYERS
Feature visualization of convolutional net trained on ImageNet from [Zeiler & Fergus 2013]:](https://image.slidesharecdn.com/convnets-230620184325-18155a70/85/convnets-pptx-21-320.jpg)
![VISUALIZING LAYERS
Feature visualization of convolutional net trained on ImageNet from [Zeiler & Fergus 2013]:](https://image.slidesharecdn.com/convnets-230620184325-18155a70/85/convnets-pptx-22-320.jpg)
![VISUALIZING LAYERS
Feature visualization of convolutional net trained on ImageNet from [Zeiler & Fergus 2013]:](https://image.slidesharecdn.com/convnets-230620184325-18155a70/85/convnets-pptx-23-320.jpg)


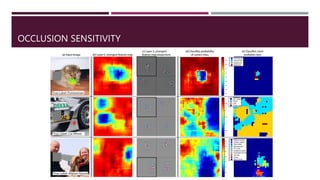
![OCCLUSION SENSITIVITY
Feature visualization of convolutional net trained on ImageNet from [Zeiler & Fergus
2013]](https://image.slidesharecdn.com/convnets-230620184325-18155a70/85/convnets-pptx-28-320.jpg)

![ZFNET: TRAINING SETUP
Built on top of ImageNet [Krizhevsky, Sutskever, Hinton, 2012]
Labeled dataset: ImageNet (1.3m images & 1000 classes)
Preprocessing:
Resize to: 256 × 256
Subtract per-pixel mean.
Augmentation: 10 sub-crops.
Cross-entropy loss function suitable for image classification.
Parameters:
Convolutional layers’ filters.
Weights matrices in fully connected (FC) layers.
Biases.
Backpropagation + Stochastic Gradient Descent (SGD)
Learning rate (starting) 10−2
& momentum of 0.9
Dropout: rate of 0.5 in FC layers.
Weights initialized to 10−2
& biases to 0.
Stopped training after 70 epochs (12 days) on GTX580 GPU.](https://image.slidesharecdn.com/convnets-230620184325-18155a70/85/convnets-pptx-30-320.jpg)