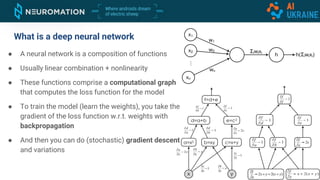
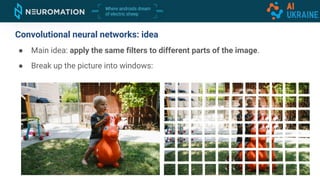
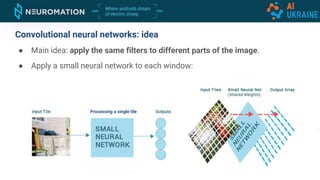
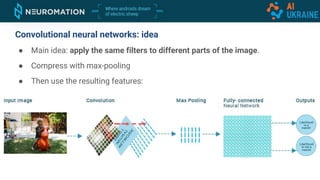
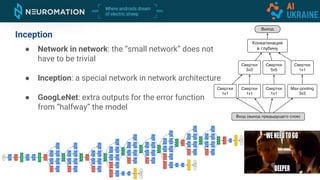
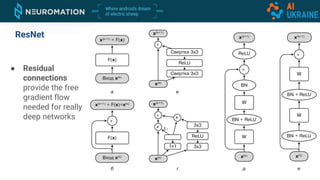
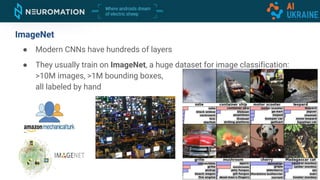
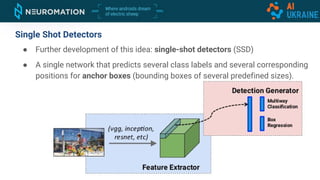
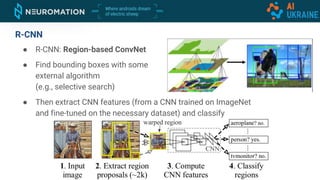
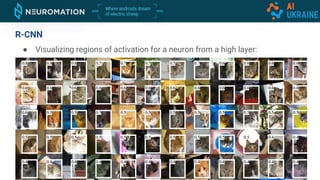
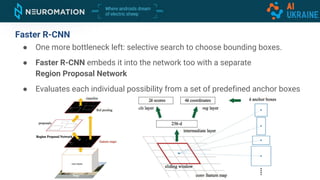
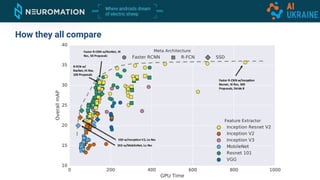
Deep neural networks can be used for object detection and segmentation. Convolutional neural networks (CNNs) are specifically designed for image processing tasks. CNNs apply filters across an image in a sliding window manner and use max pooling to reduce dimensionality. Modern CNNs have hundreds of layers and are trained on large datasets like ImageNet for classification. For object detection, CNNs can generate bounding boxes and classify objects within them using approaches like YOLO, SSD, R-CNN, and Mask R-CNN. While requiring large labeled datasets, synthetic data generation can provide pixel-perfect labels to train detection models at a large scale.