Download as PDF, PPTX








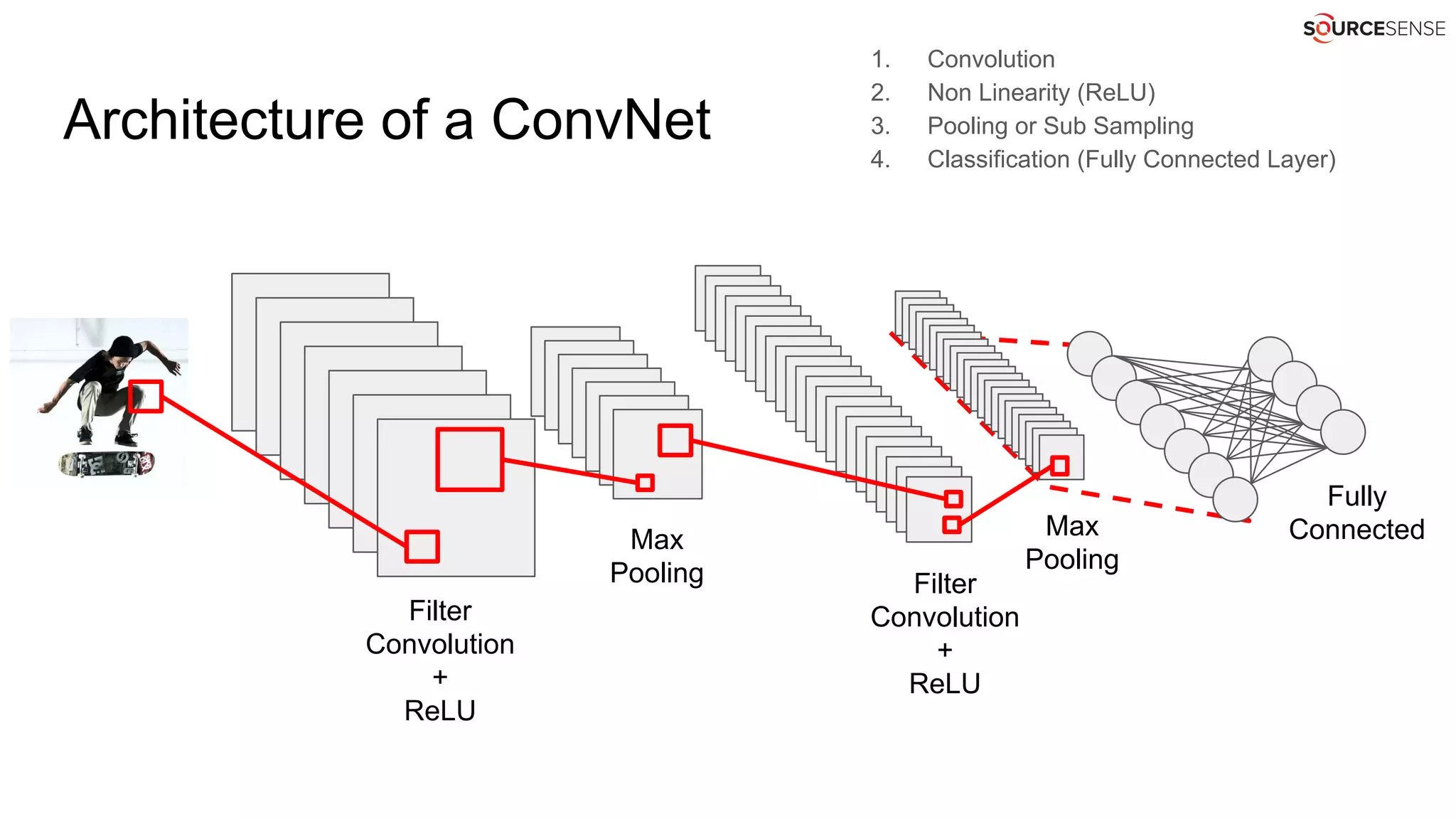

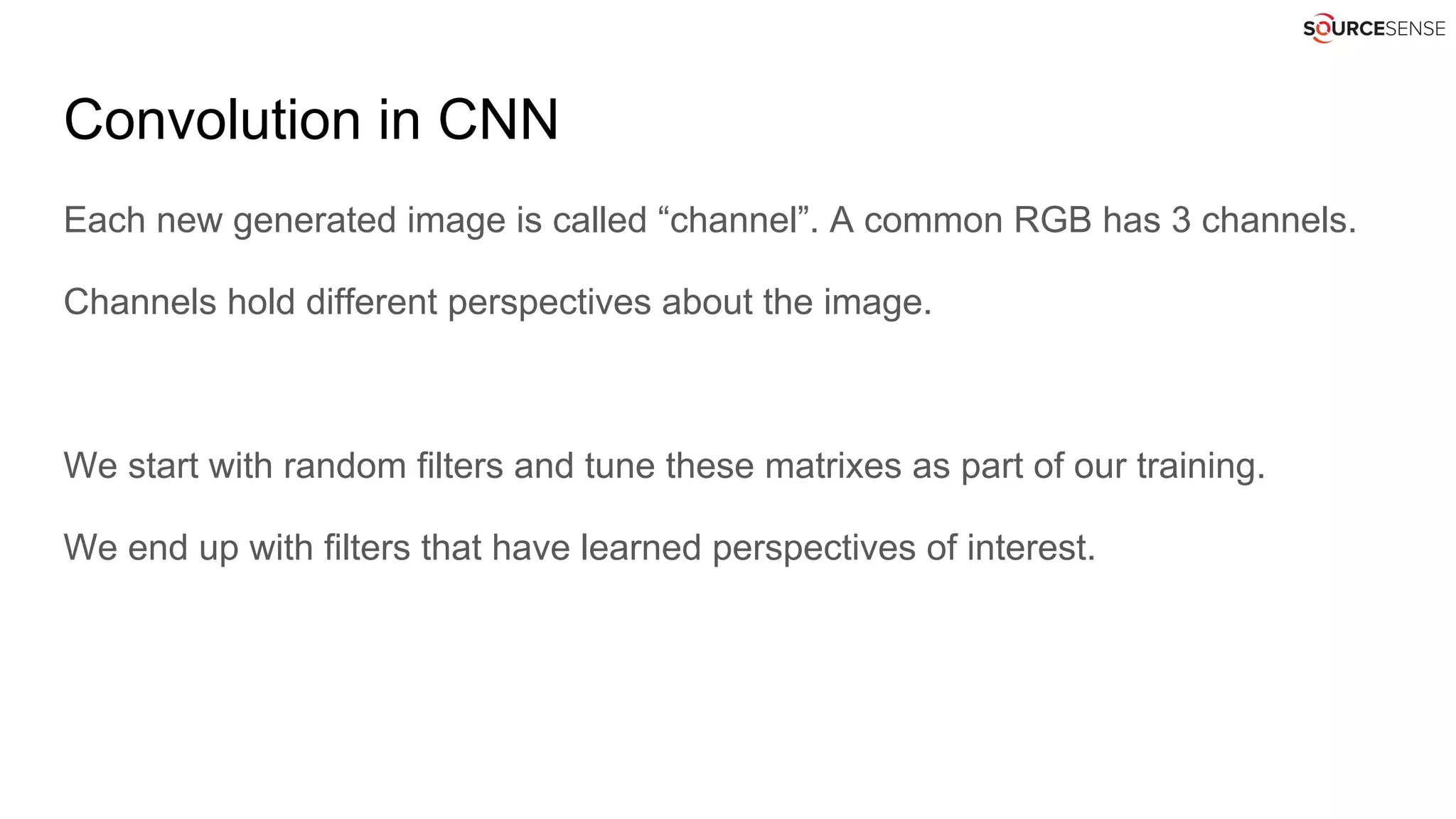


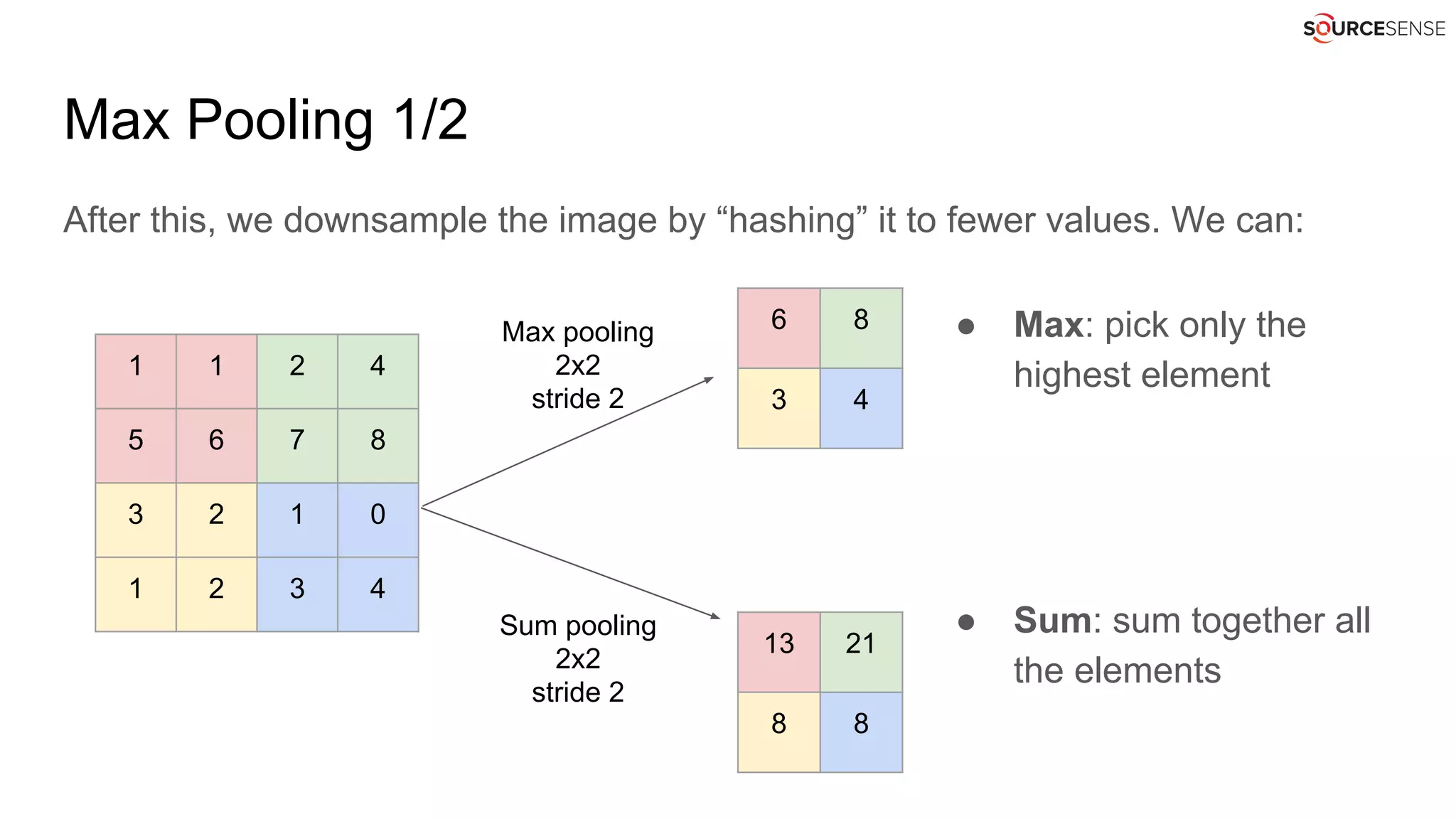
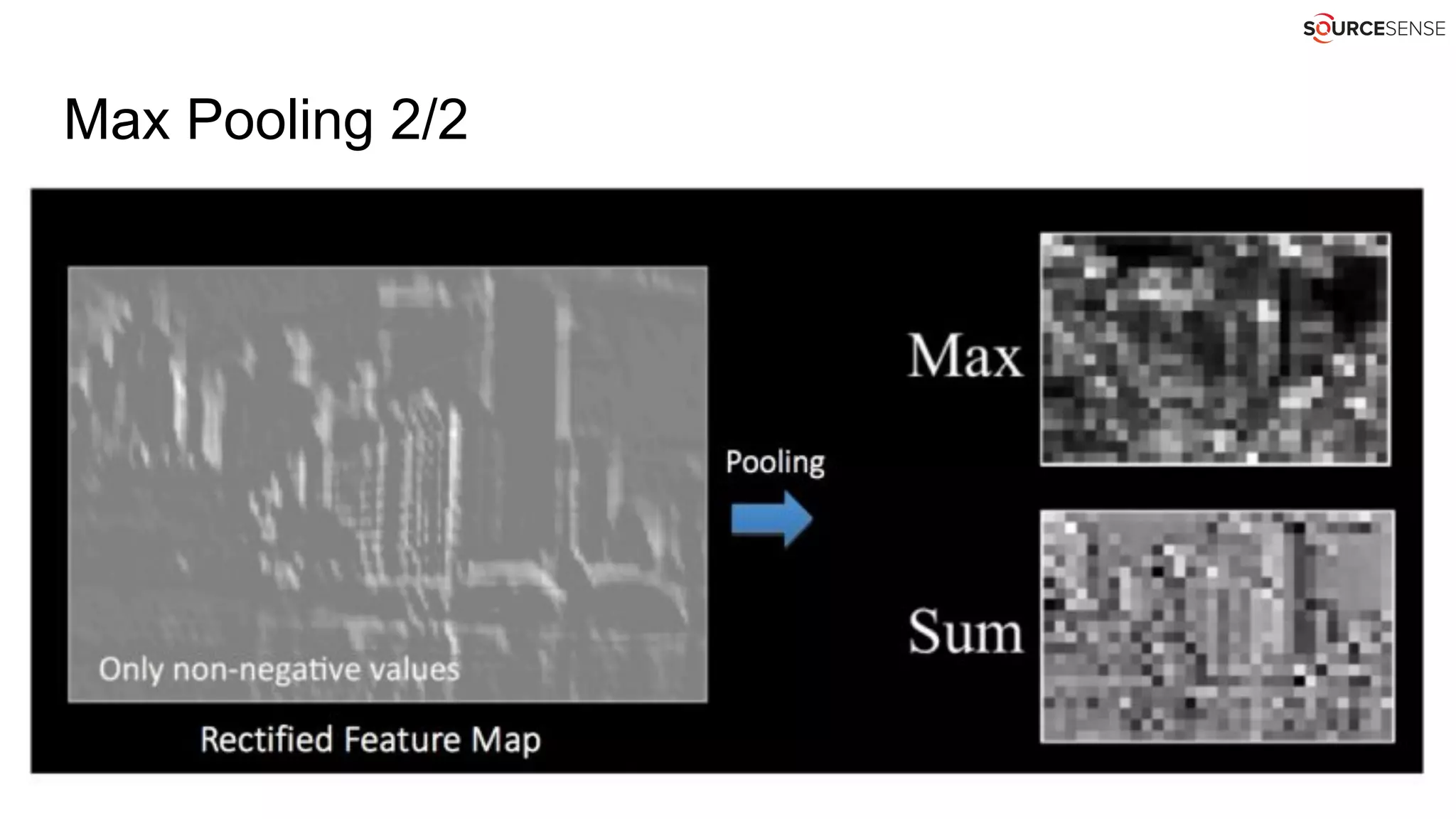


![Words as integers without embedding
Vocabulary of words.
V = [‘fight’, ‘kill’, ‘queen’, ‘king’, ‘man’, ‘woman’, ‘love’,...]
“One hot vector” encoding representation of single words.
‘fight’ = [1 0 0 0 0 0 0 …]
‘kill’ = [0 1 0 0 0 0 0 …]
‘queen’ = [0 0 1 0 0 0 0 …]
Can correlate documents (TF-IDF), but can’t correlate single words to each other:
“I fight the king” = [ 1 1 0 1 0 0 0 …]
“fight the tirannny”= [ 0 1 0 1 0 0 1 …]](https://image.slidesharecdn.com/3codemotionimagesandwords-mechanicsofautomatedcaptioningwithneuralnetworksextended-190125103719/75/Alberto-Massidda-Images-and-words-mechanics-of-automated-captioning-with-neural-networks-Codemotion-Milan-2018-21-2048.jpg)
![Words as floats with vector embedding
Word embedding.
Fixed length, real valued vector encoding representation of single words.
Close concepts have close vectors.
‘fight’ = [0.17 0.53 0.89 0.03 0.00 0.54 0.11 ]
‘kill’ = [0.17 0.53 0.91 0.06 0.00 0.54 0.12 ]
‘queen’ = [0.22 0.45 0.13 0.53 0.90 0.41 0.00 ]
Vector operation yields to coherent results: king - man + woman = queen](https://image.slidesharecdn.com/3codemotionimagesandwords-mechanicsofautomatedcaptioningwithneuralnetworksextended-190125103719/75/Alberto-Massidda-Images-and-words-mechanics-of-automated-captioning-with-neural-networks-Codemotion-Milan-2018-22-2048.jpg)


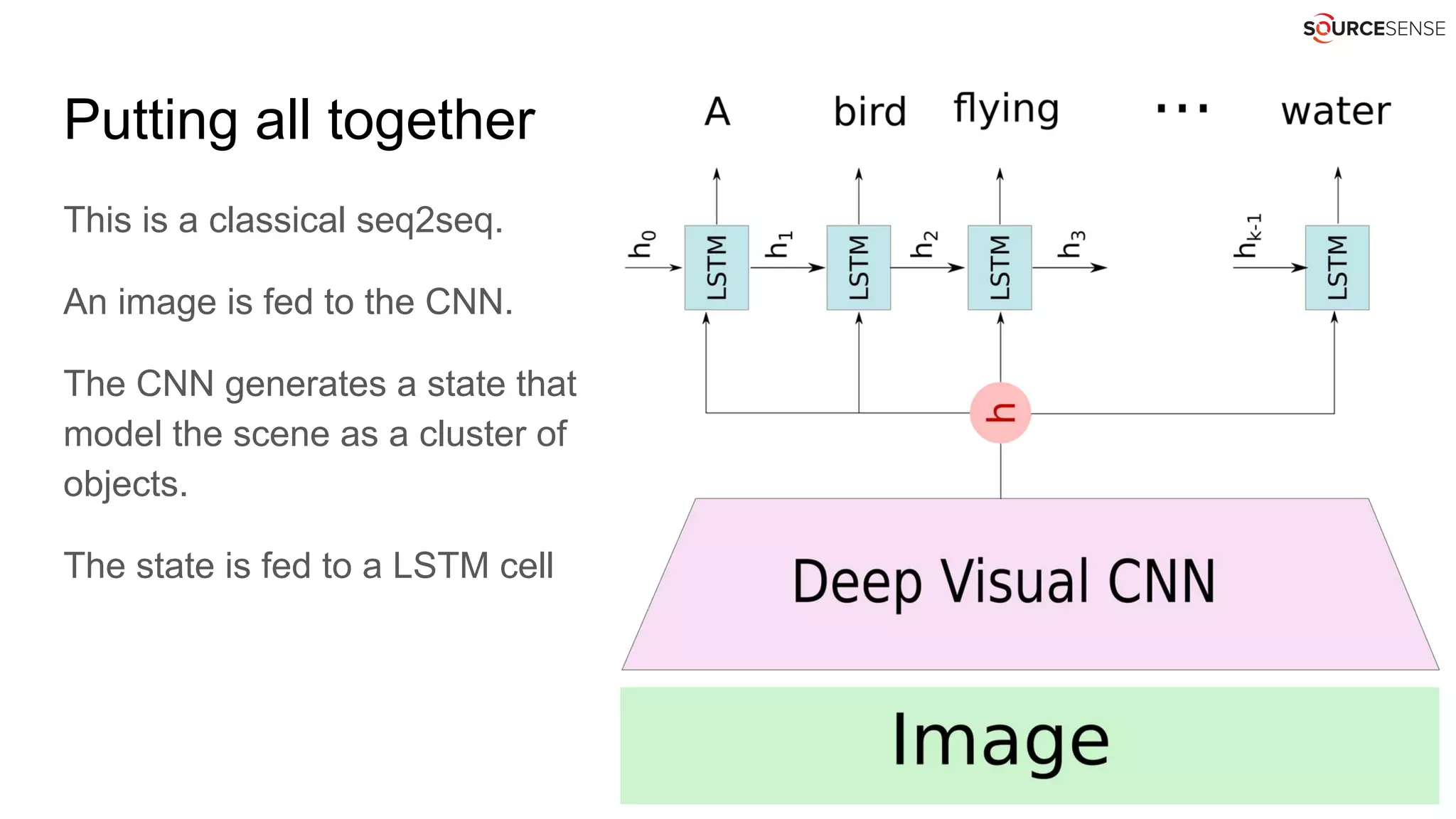

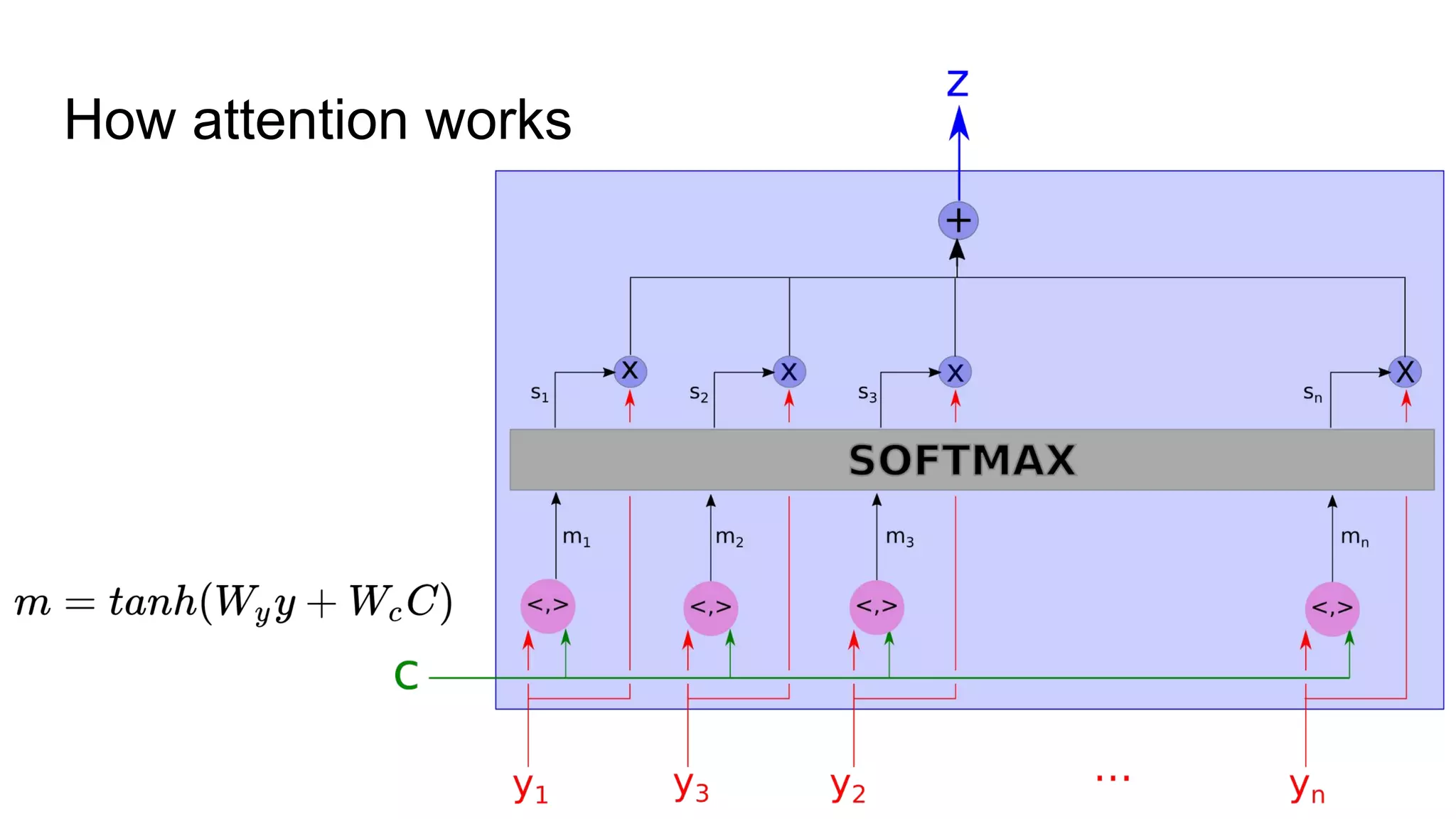
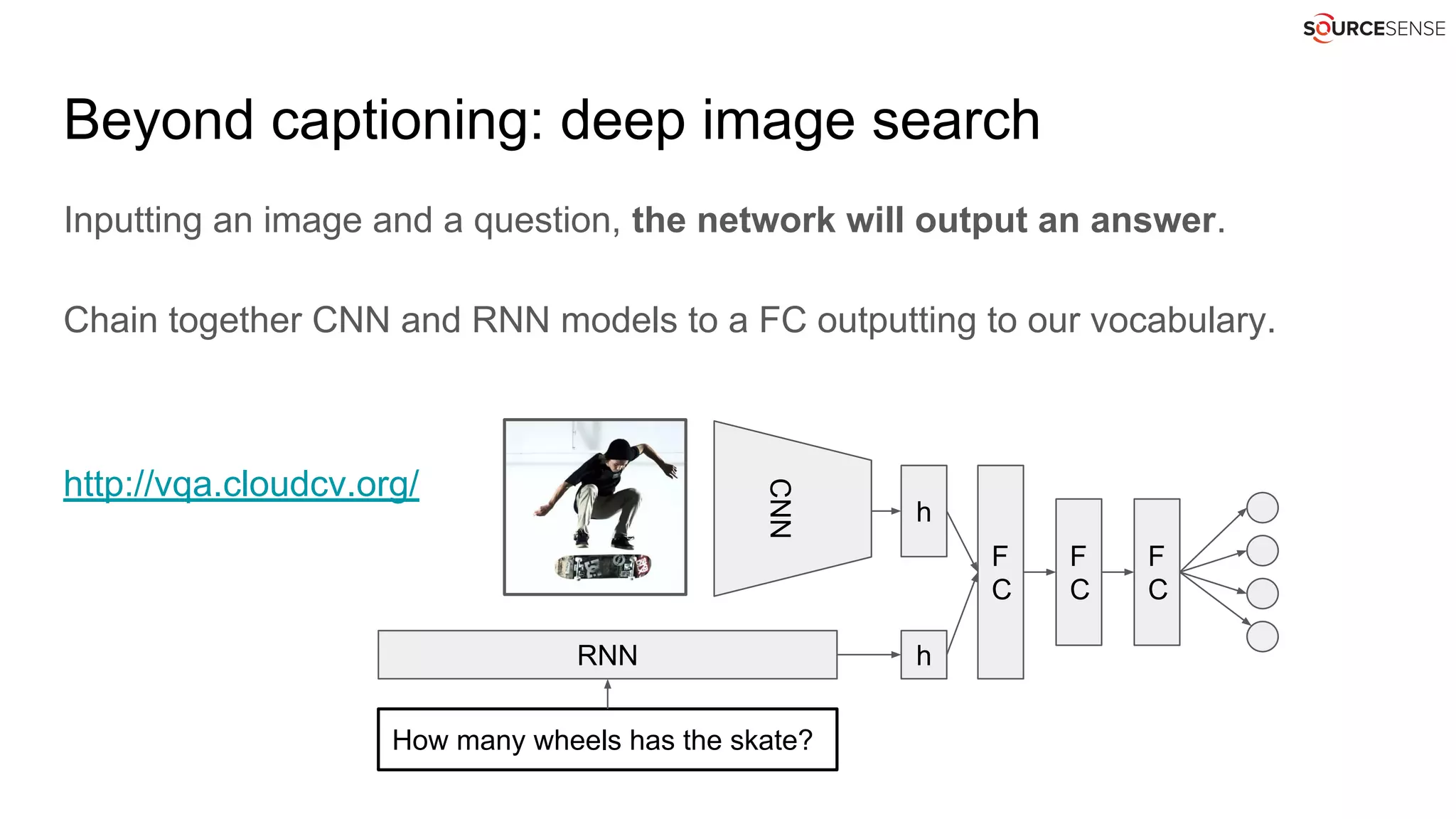


The document discusses the mechanics of automated captioning using neural networks, focusing on object recognition and language generation. It highlights the use of convolutional neural networks (CNNs) for image analysis and recurrent neural networks (RNNs) for generating descriptive text. Further, it covers techniques for improving performance and extends the application to deep image search functionalities.







































































![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)







