





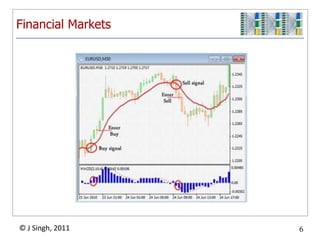

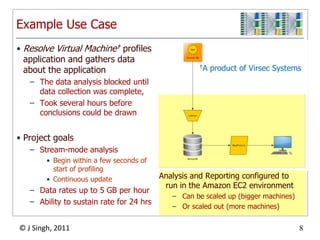
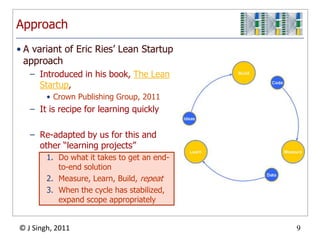



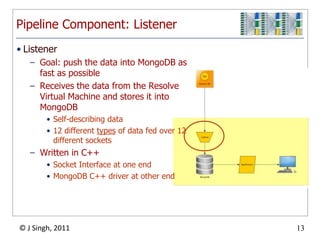




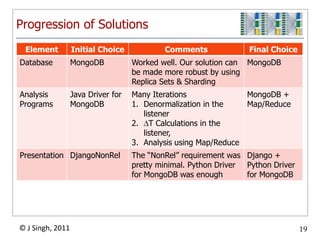



The document discusses a high-throughput data analysis platform designed to process streaming data efficiently, focusing on a specific case study of resolving virtual machine profiles. Key strategies include continuous data collection, fast processing using a combination of MongoDB and map/reduce techniques, and a modular architecture for real-time analytics. The findings emphasize the importance of quick learning cycles and scalability in data processing to enable timely insights and alerts.




































![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)


















































