Downloaded 93 times



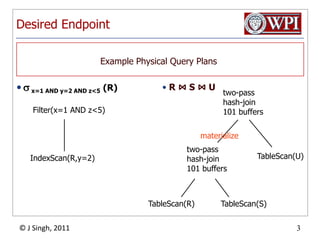




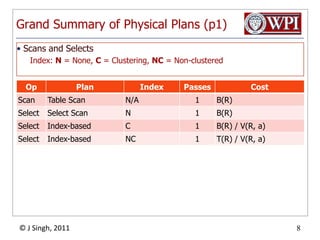
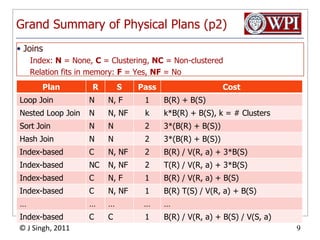



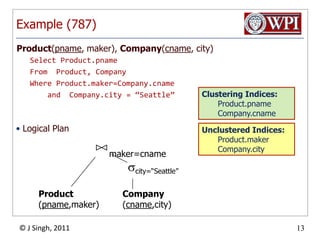
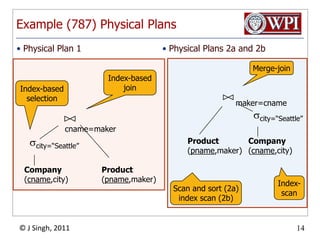
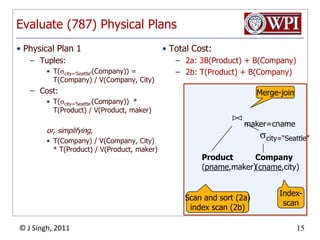




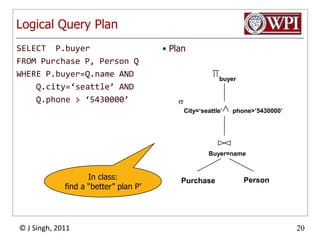



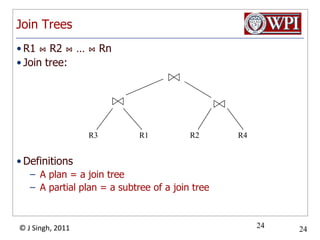


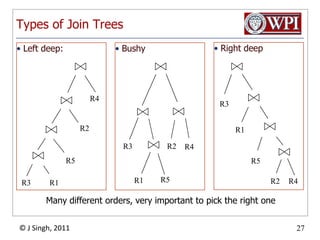












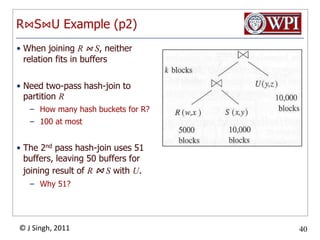



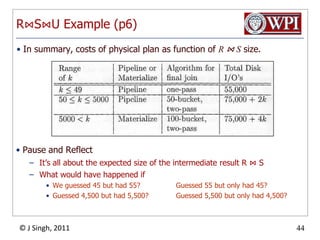



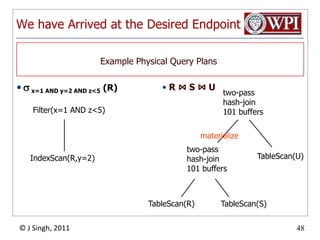




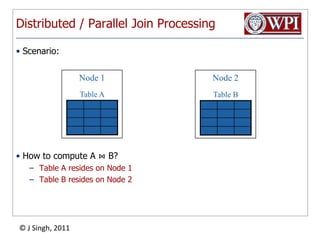
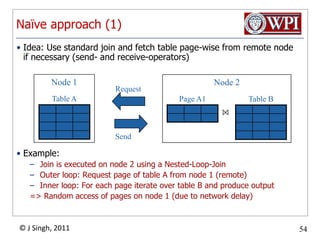
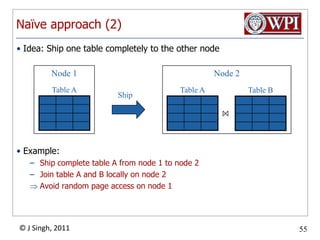


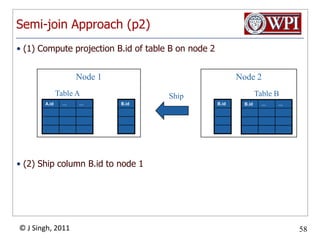
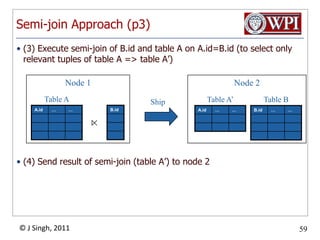
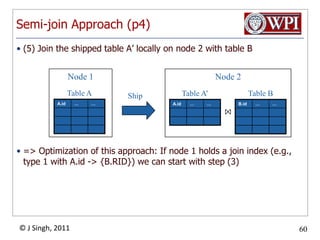


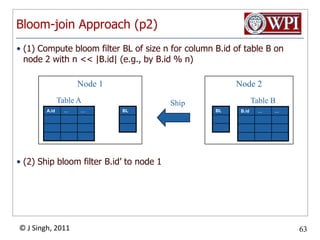
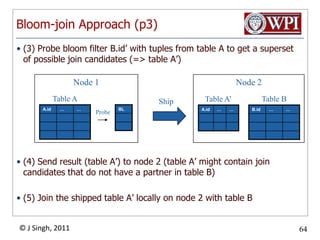

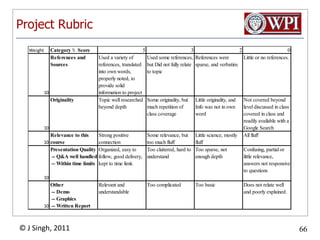

The document discusses query optimization in database management systems. It covers converting SQL queries to logical and physical query plans, improving logical plans through algebraic transformations, and choosing the optimal physical query plan by considering the order of operations and join trees. The goal is to select the most efficient physical plan by estimating the size of relations and intermediate results.
















































































