Downloaded 193 times

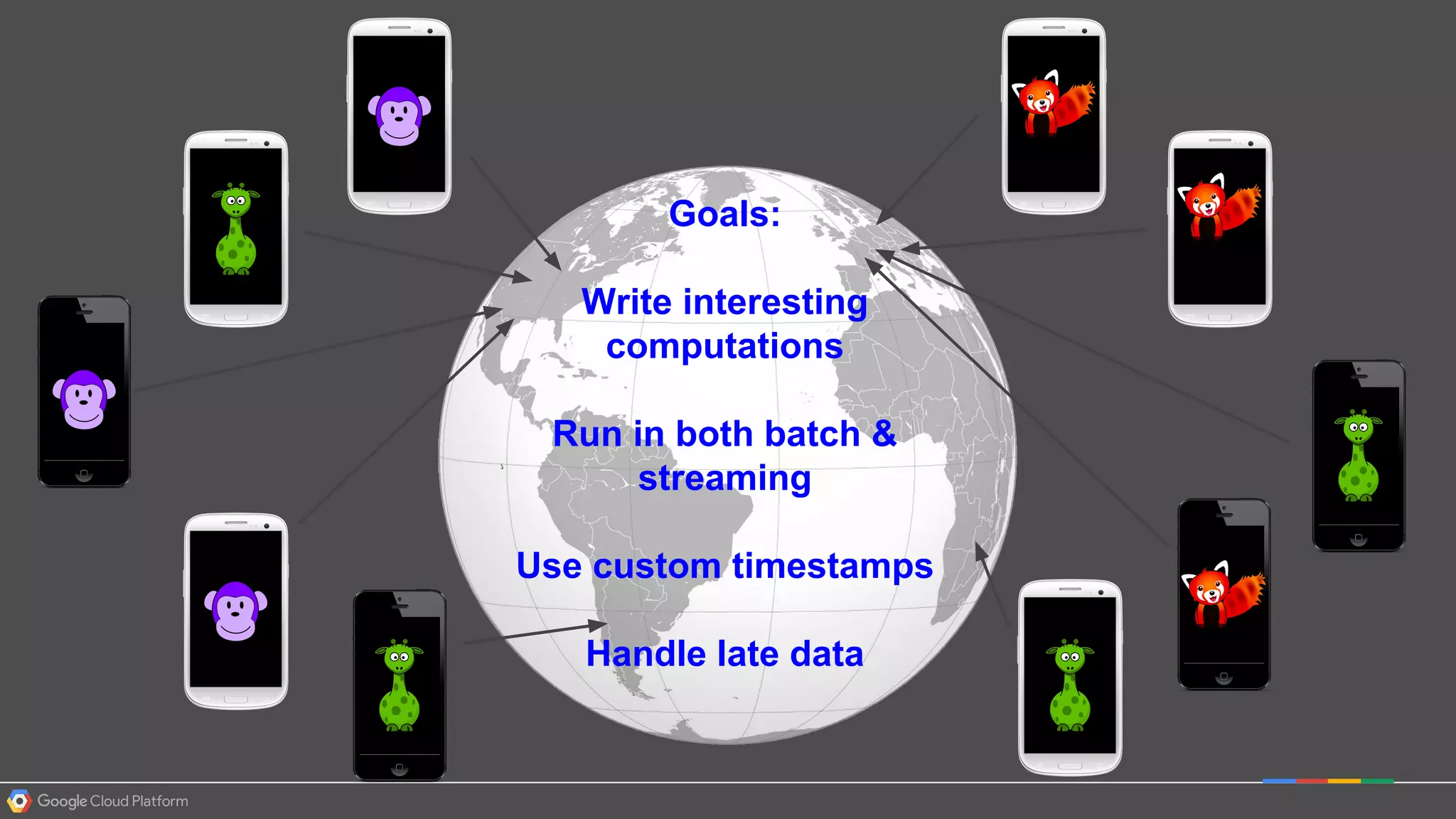




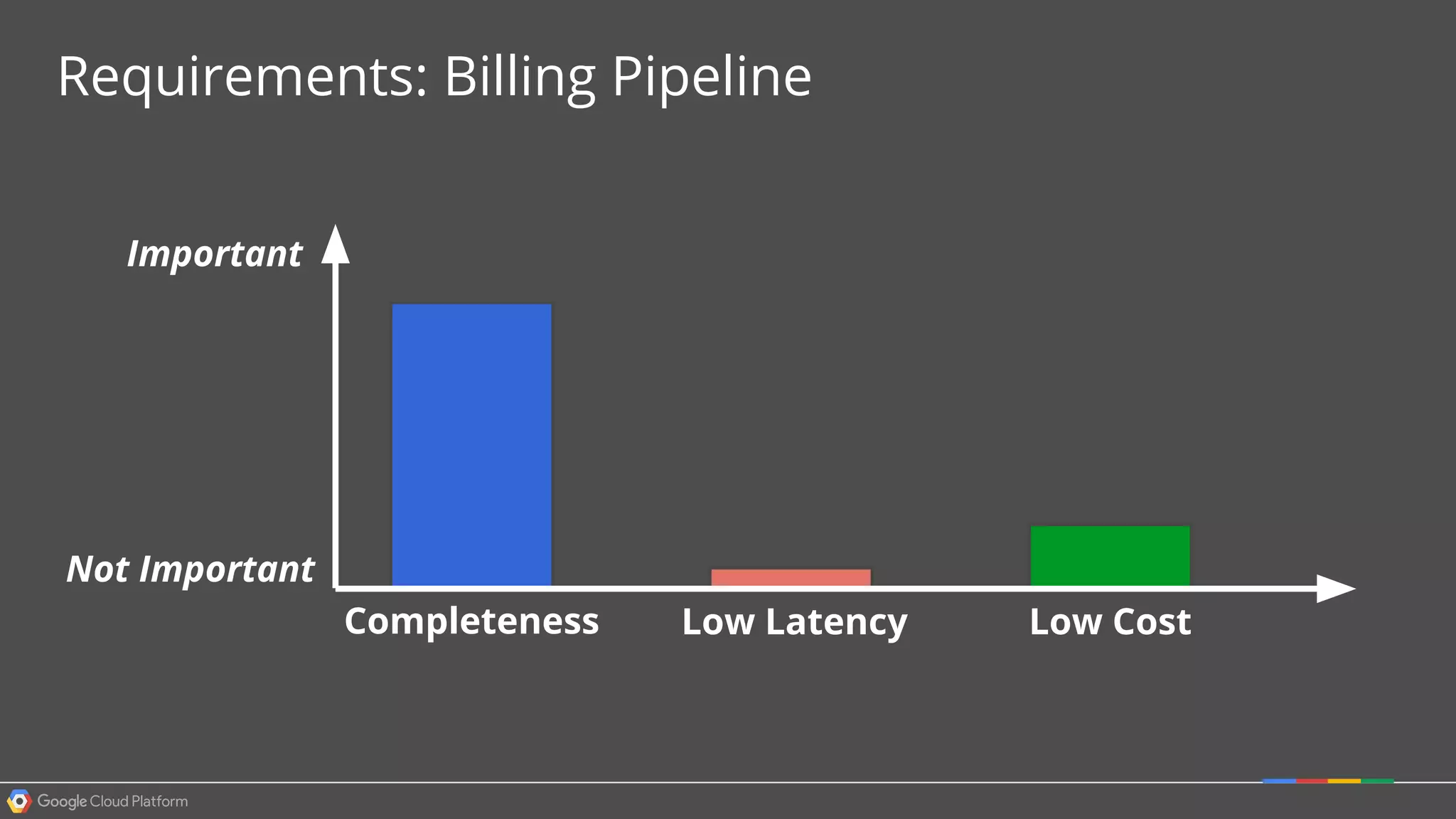
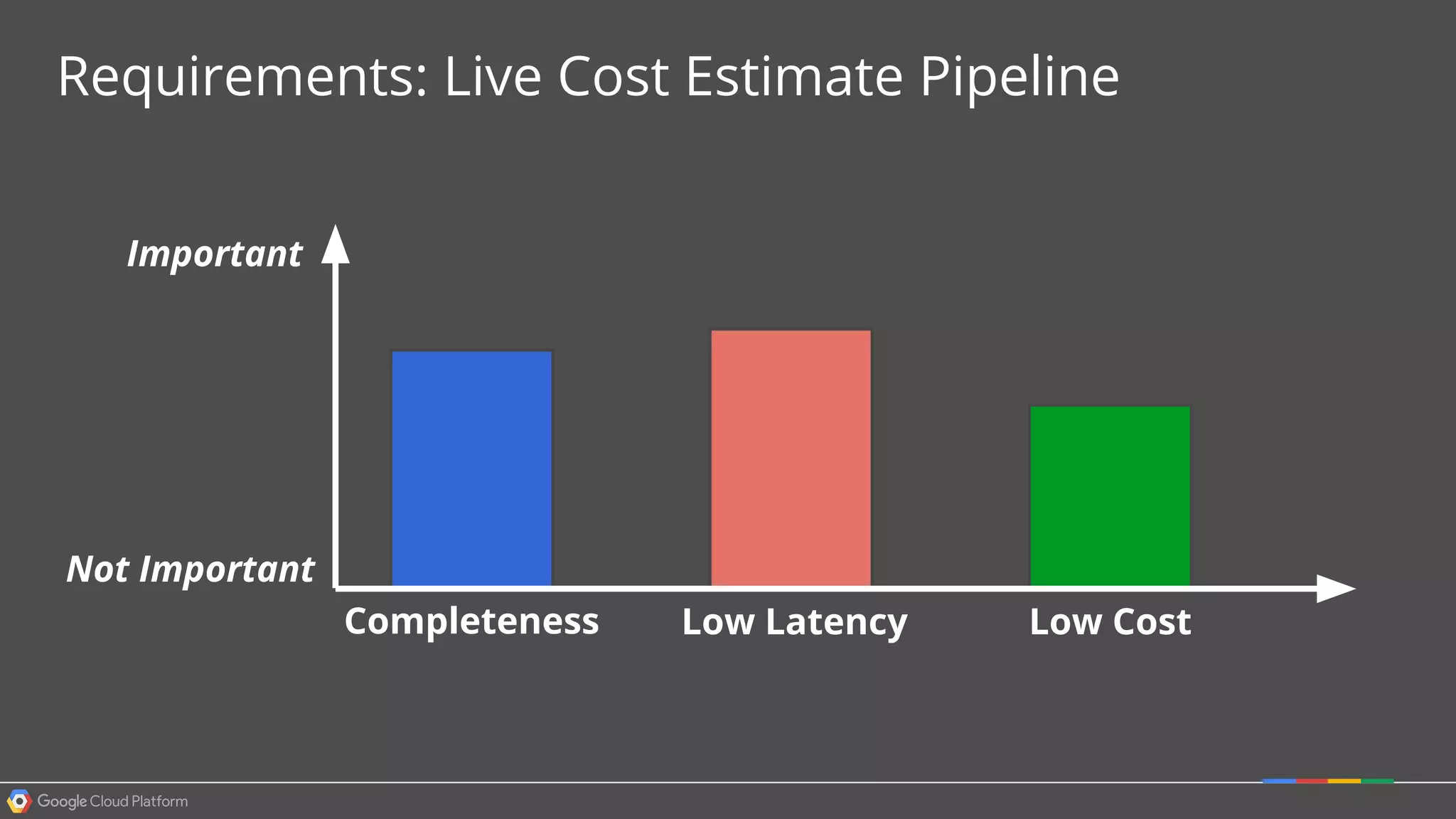
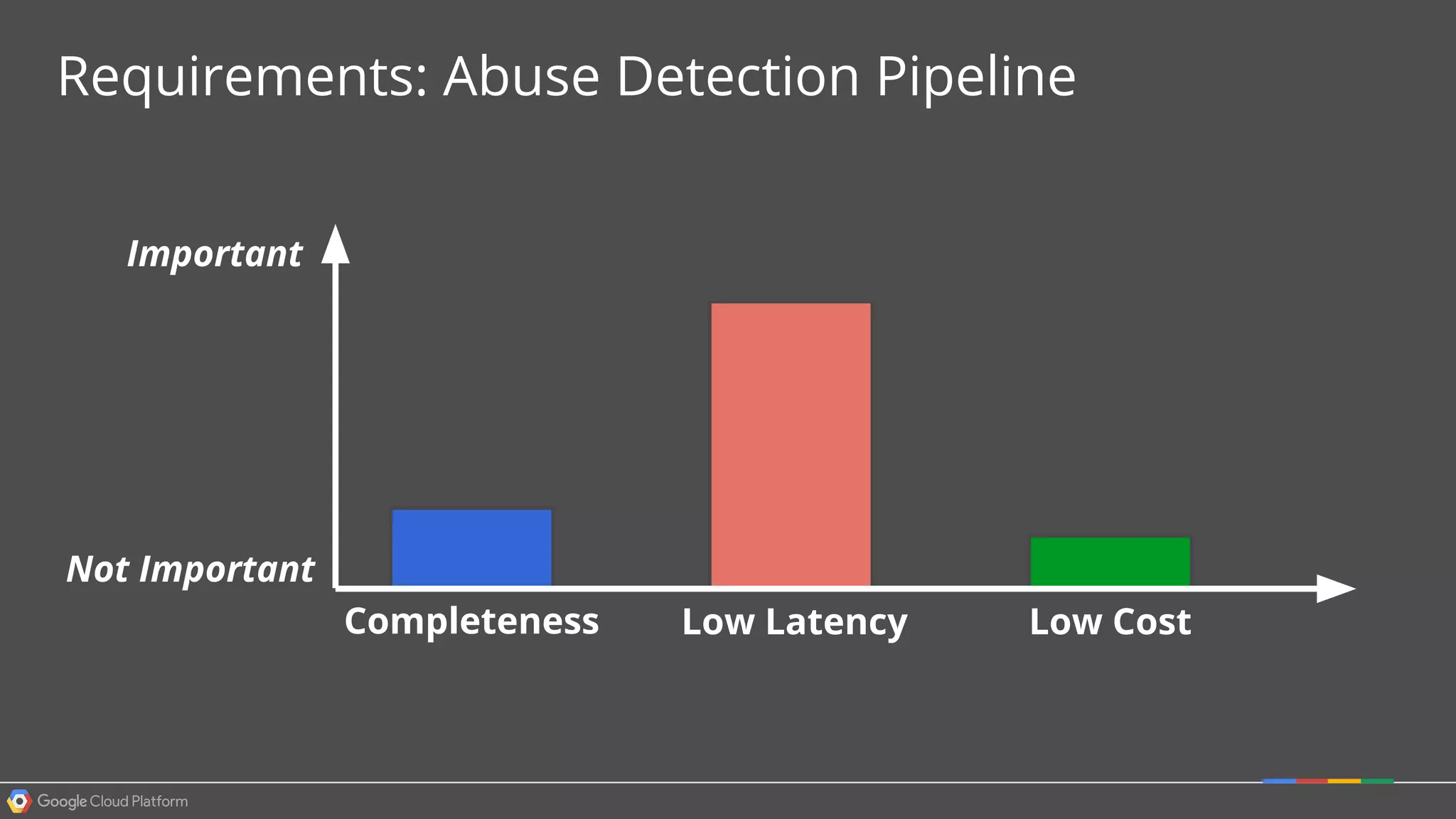
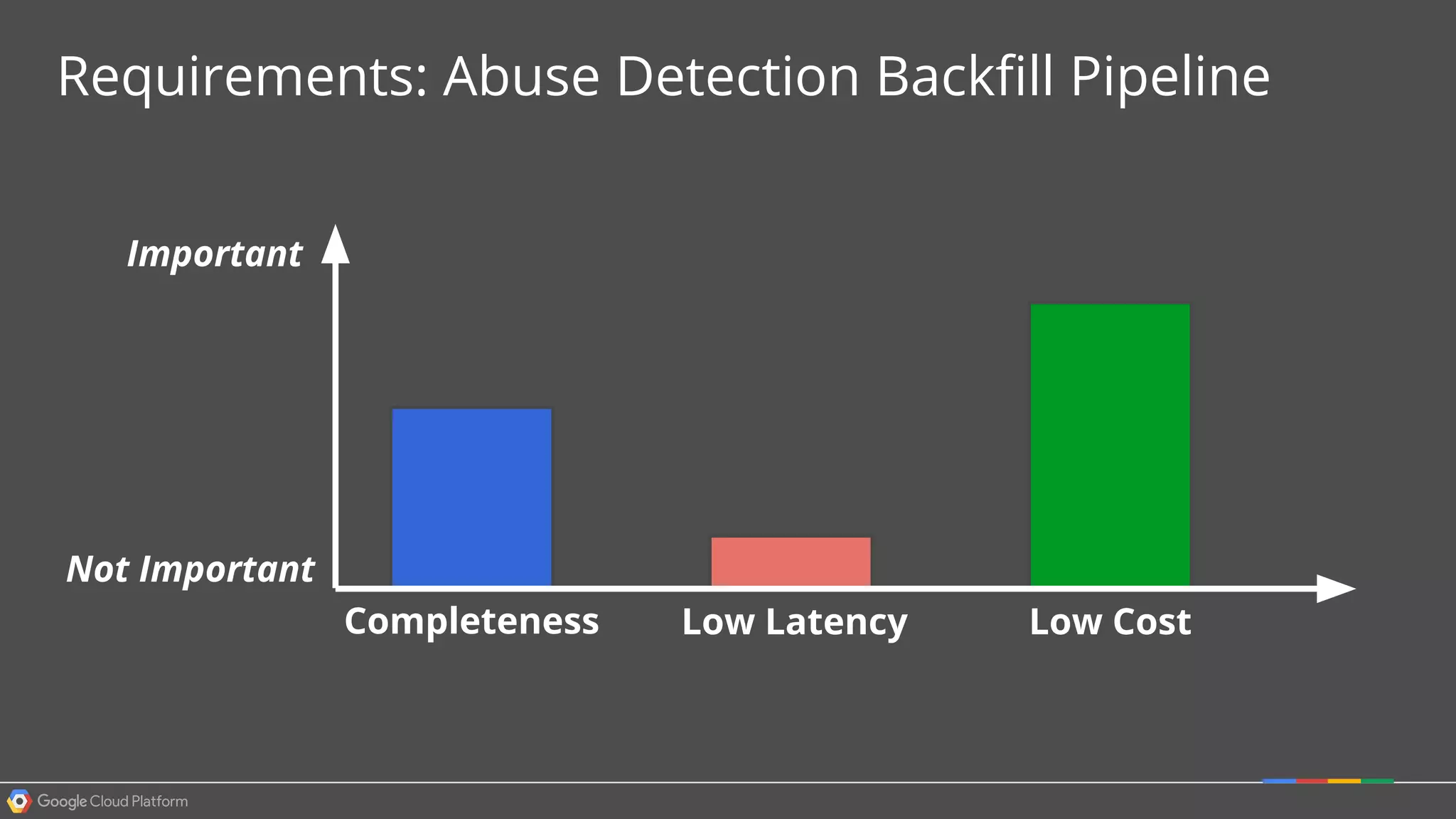


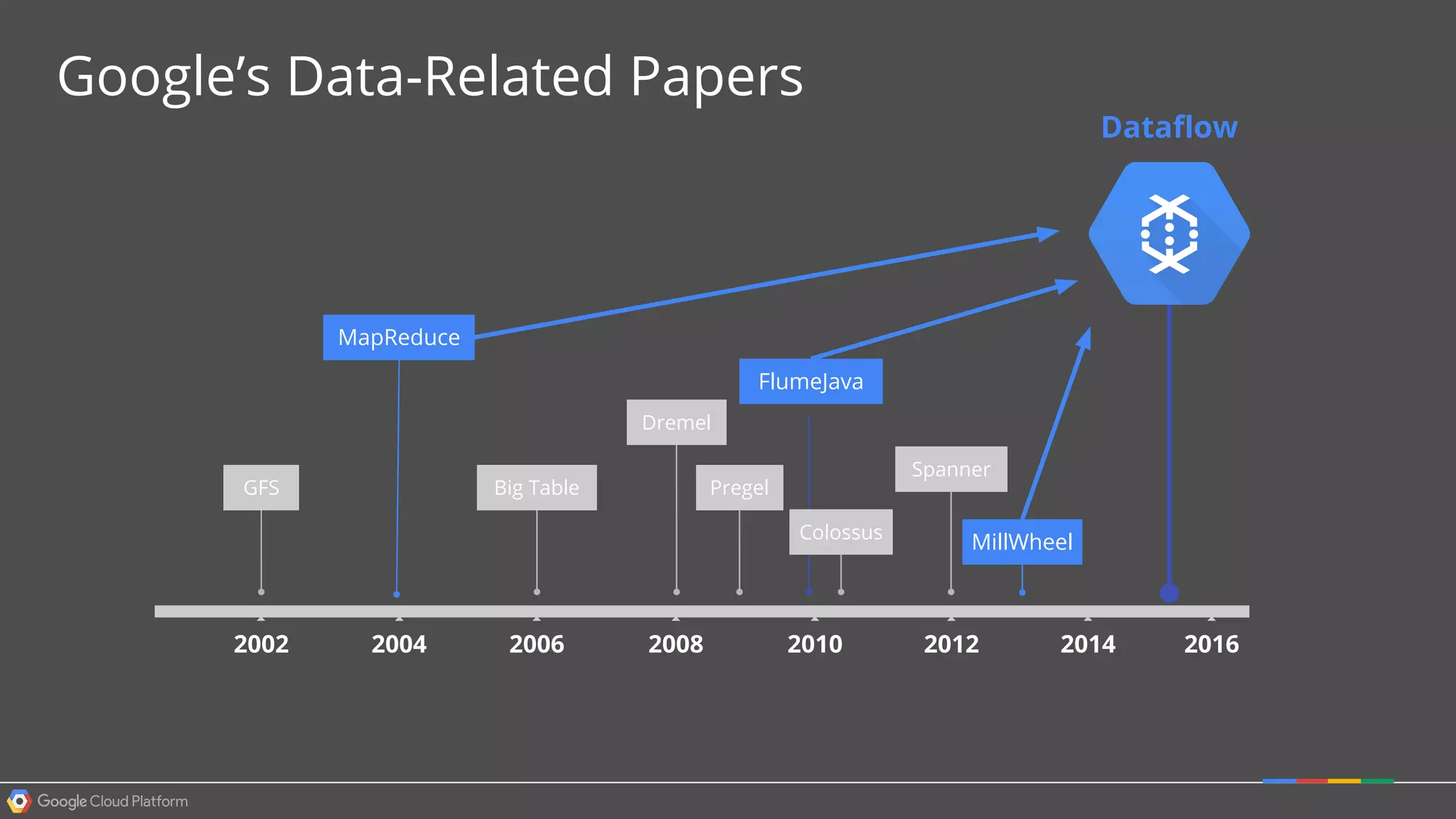
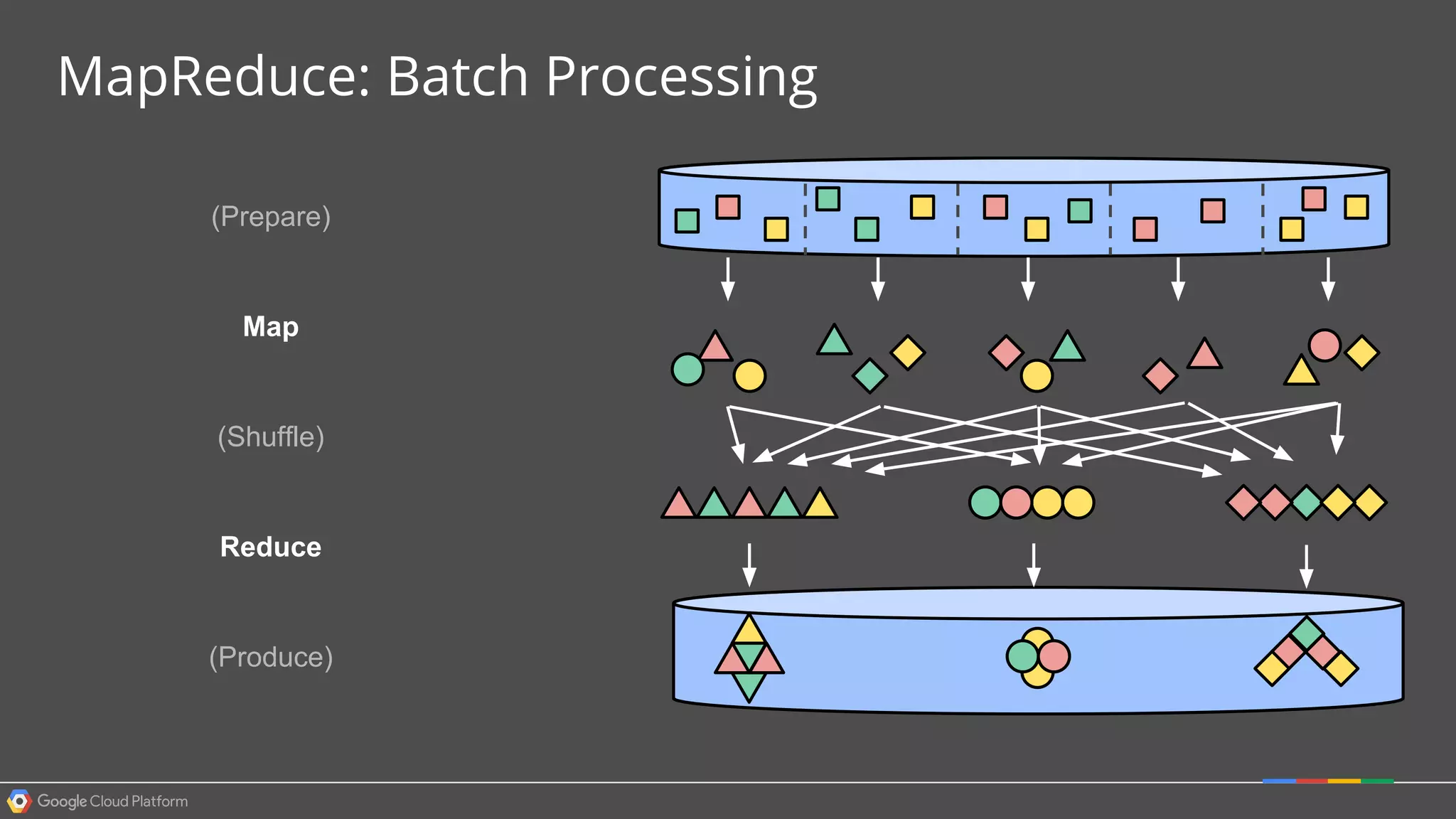
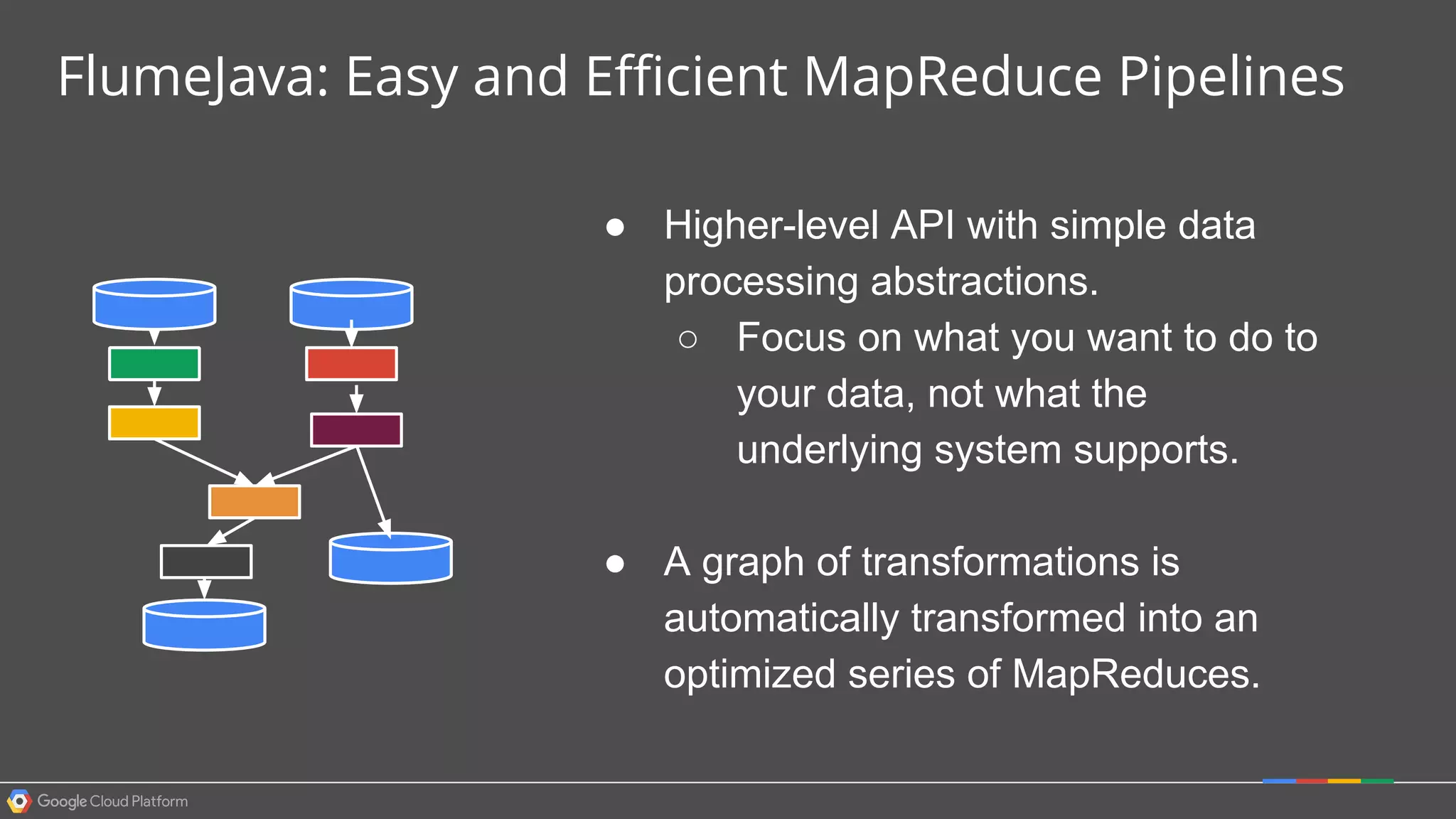
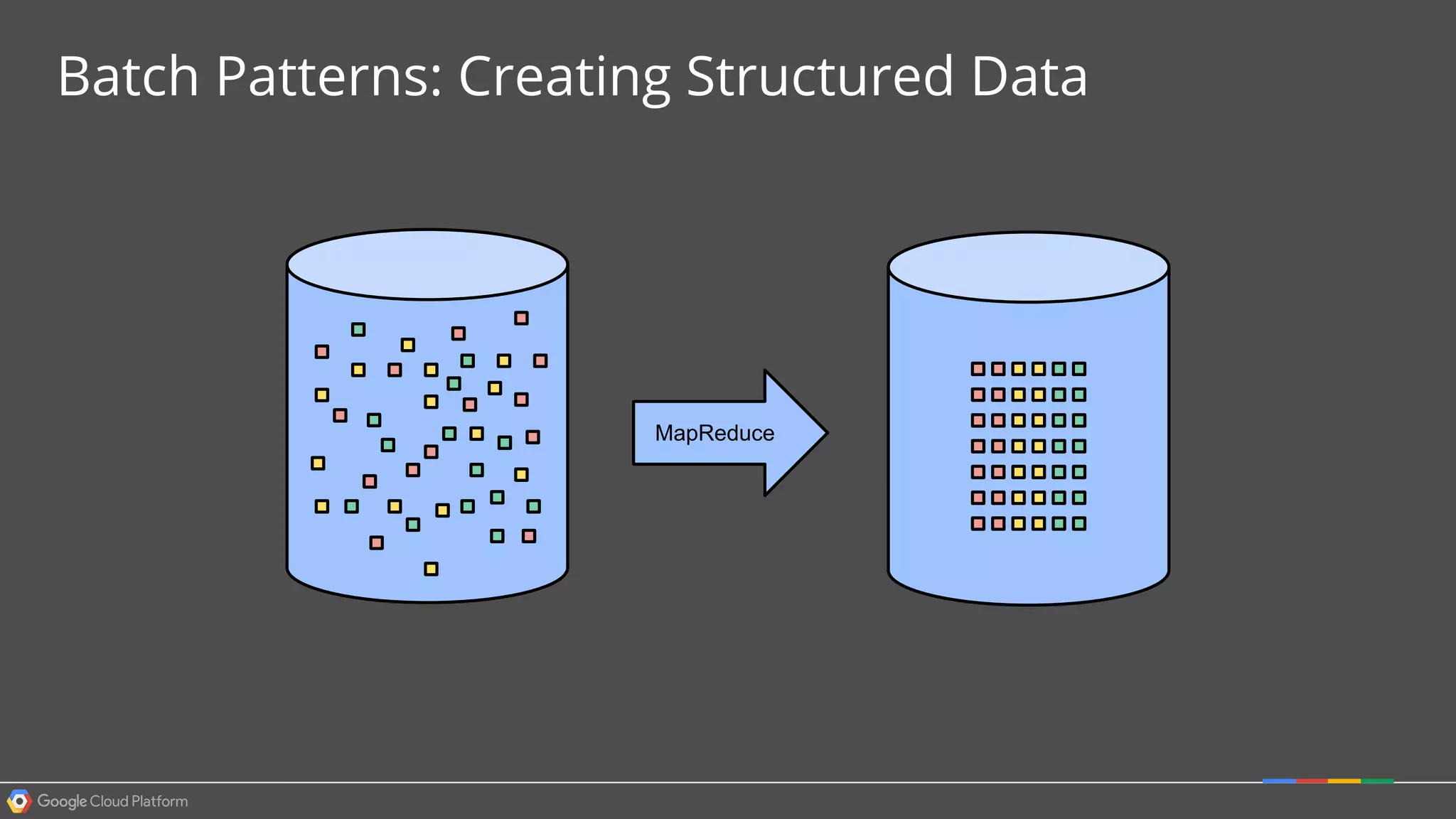
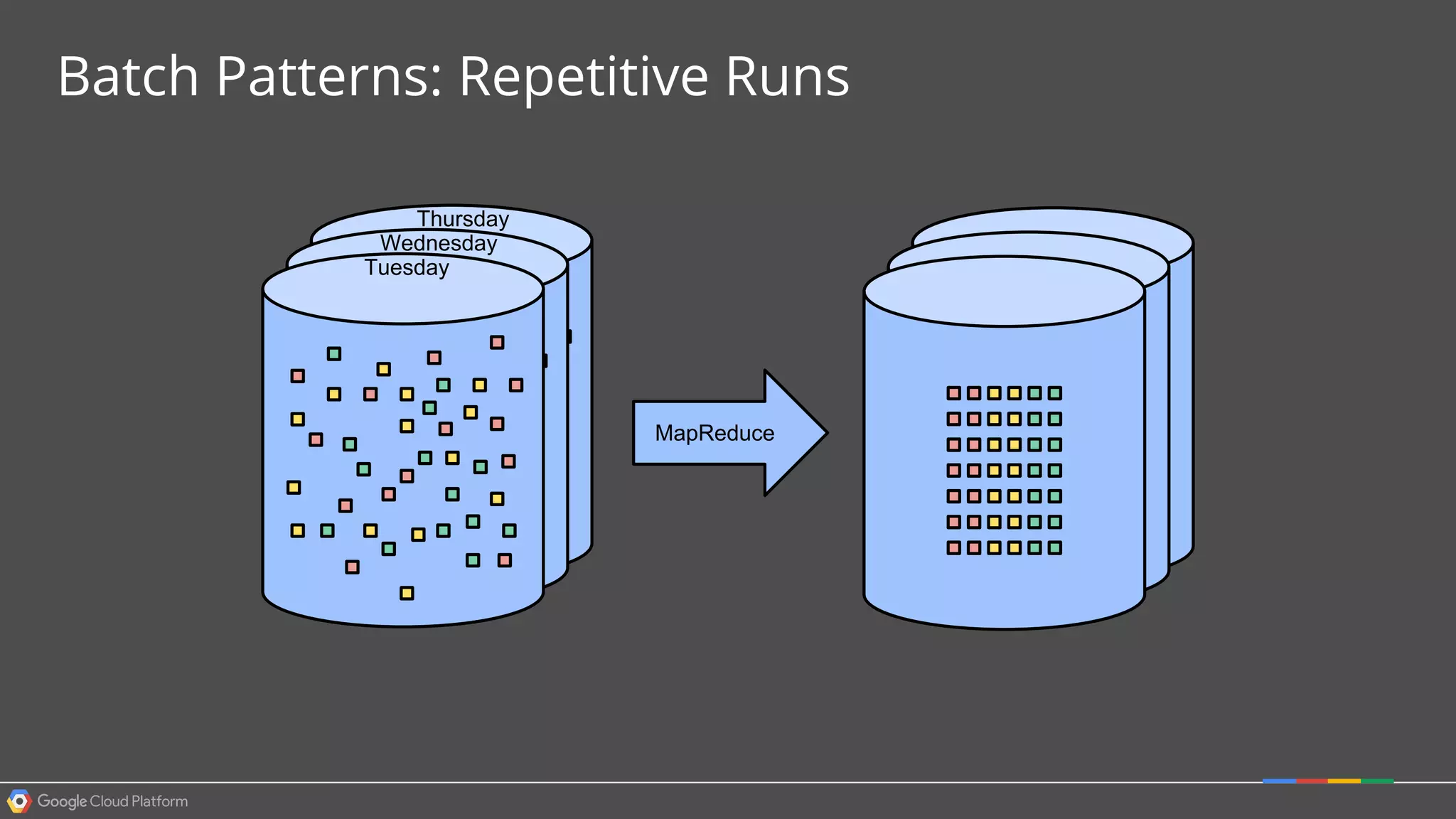
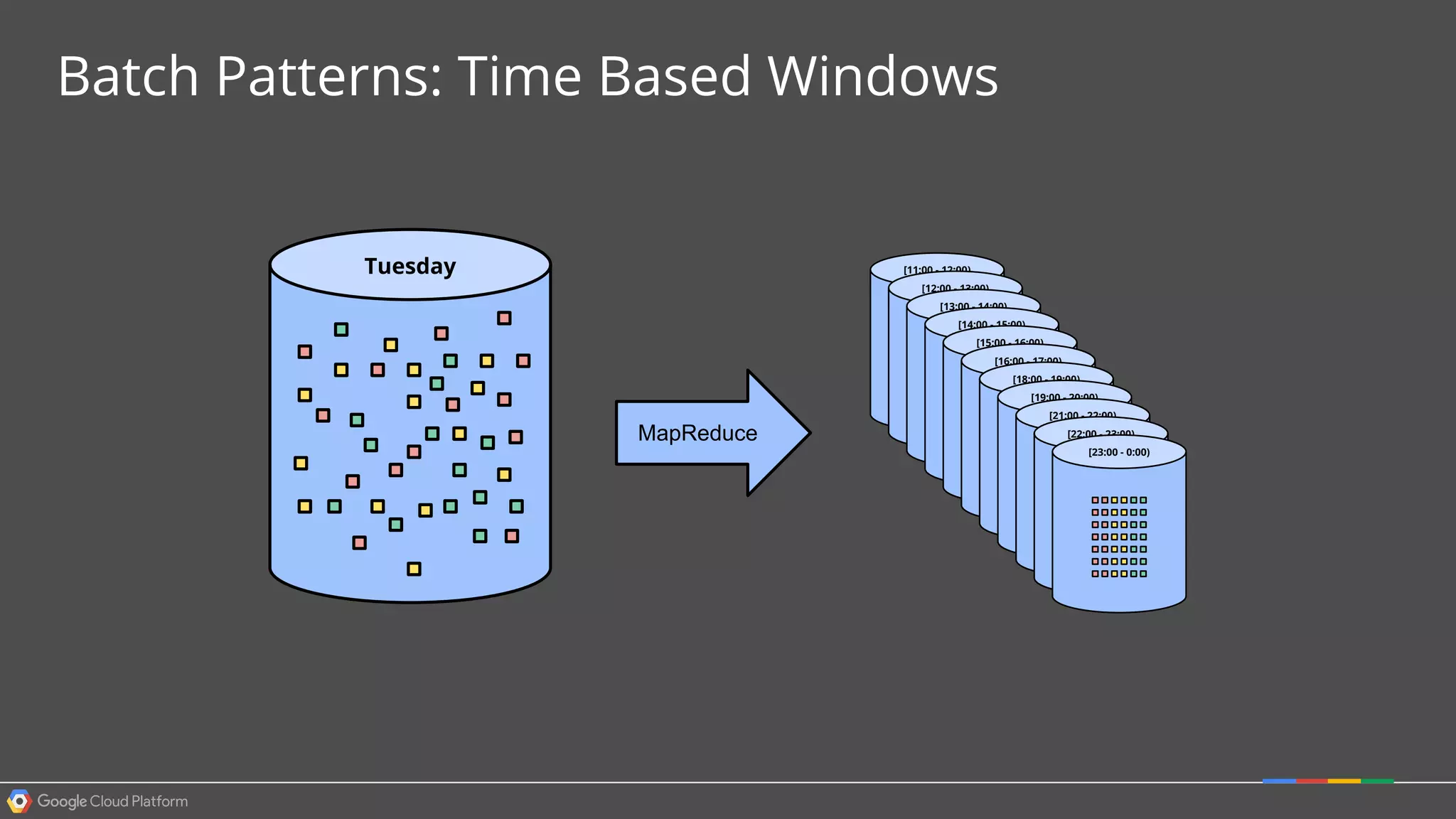
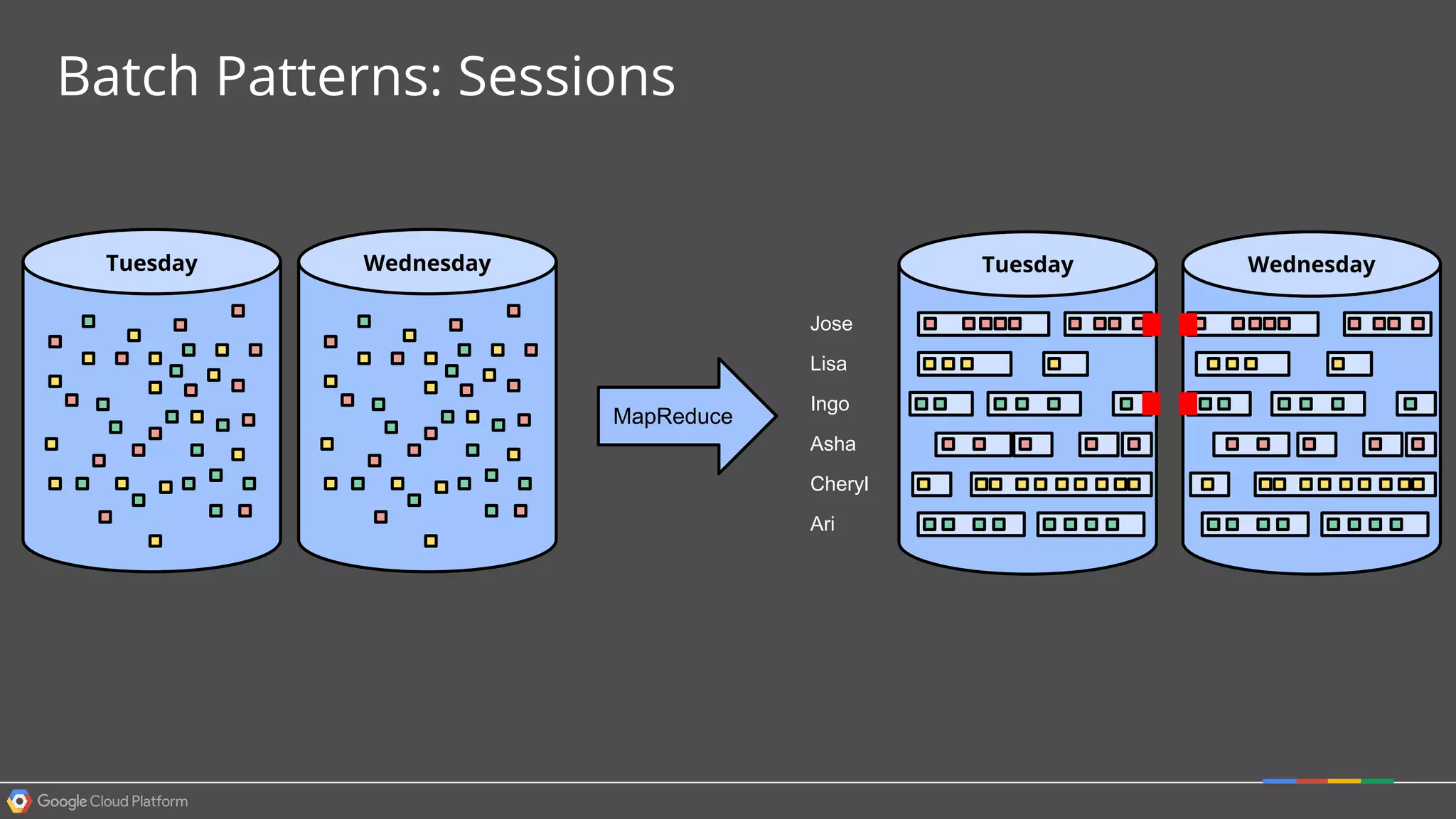
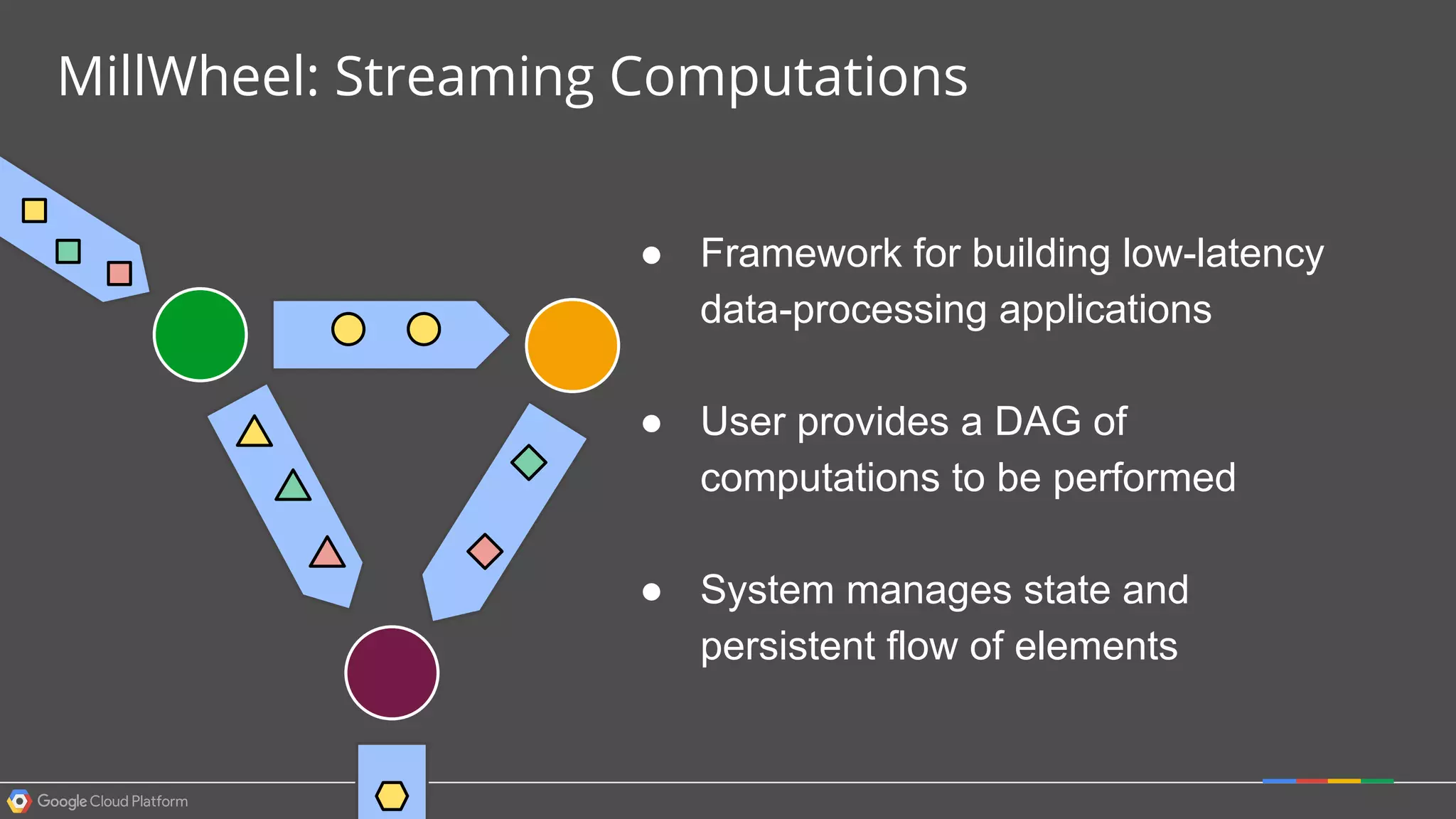
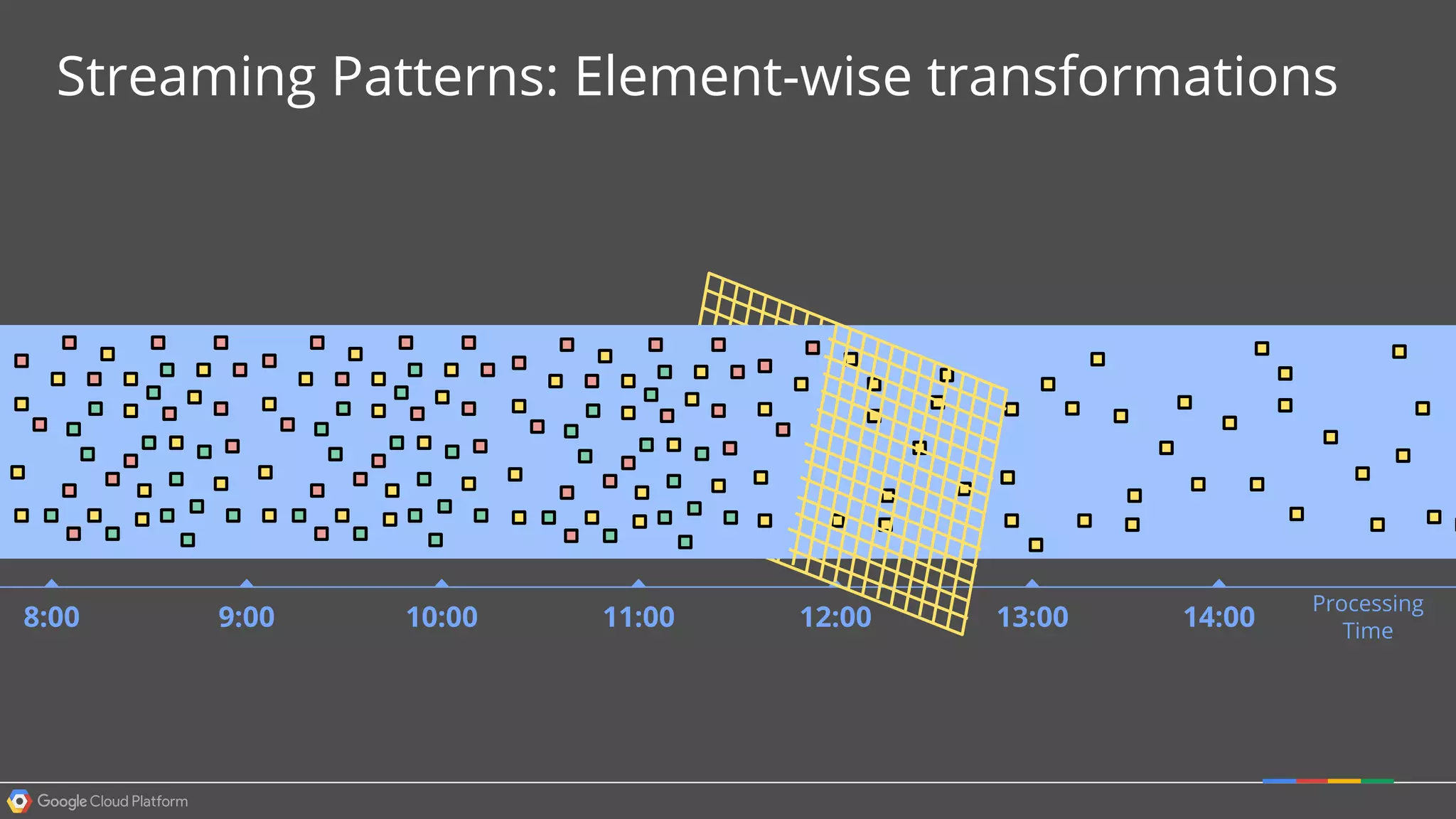
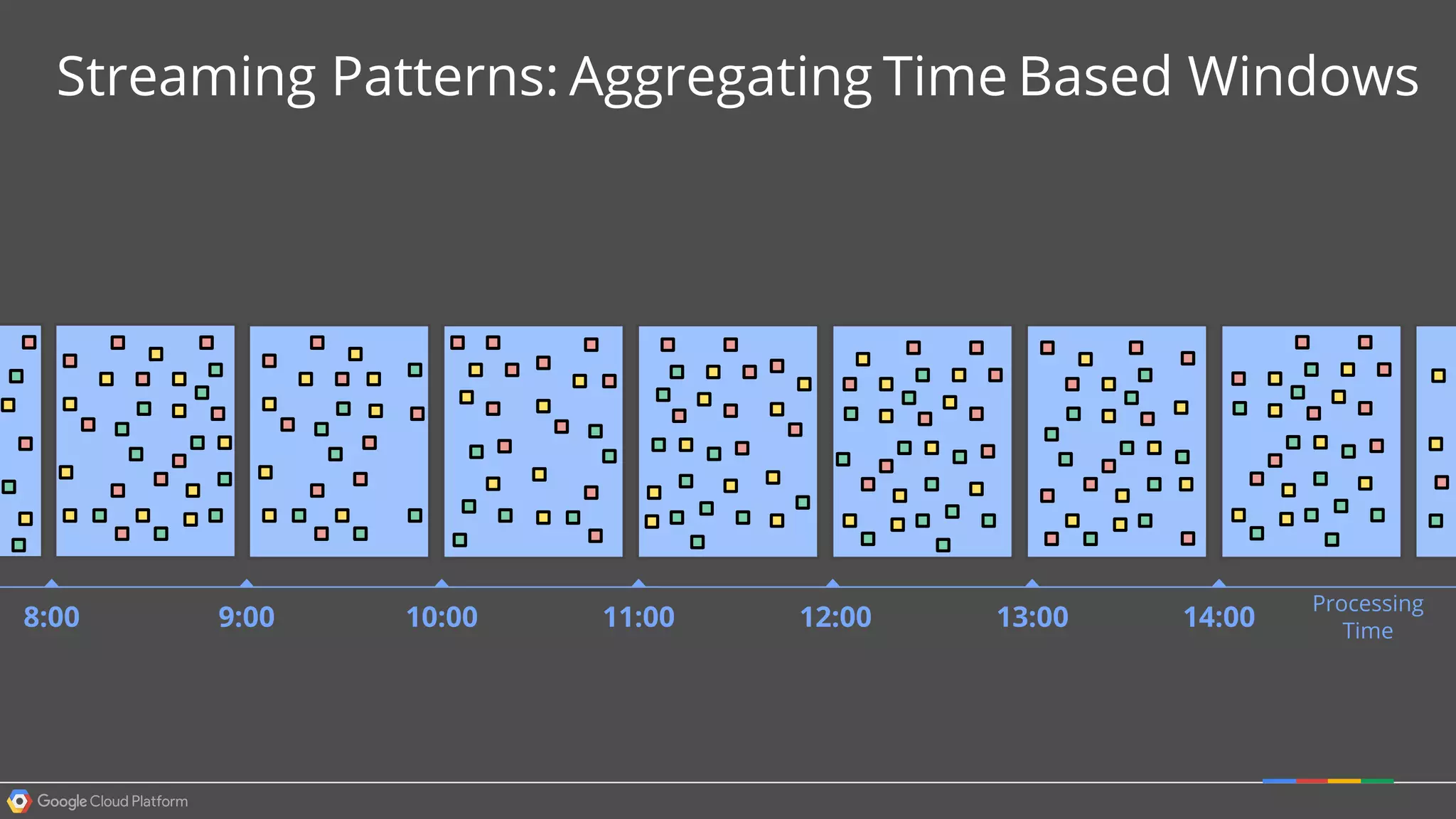
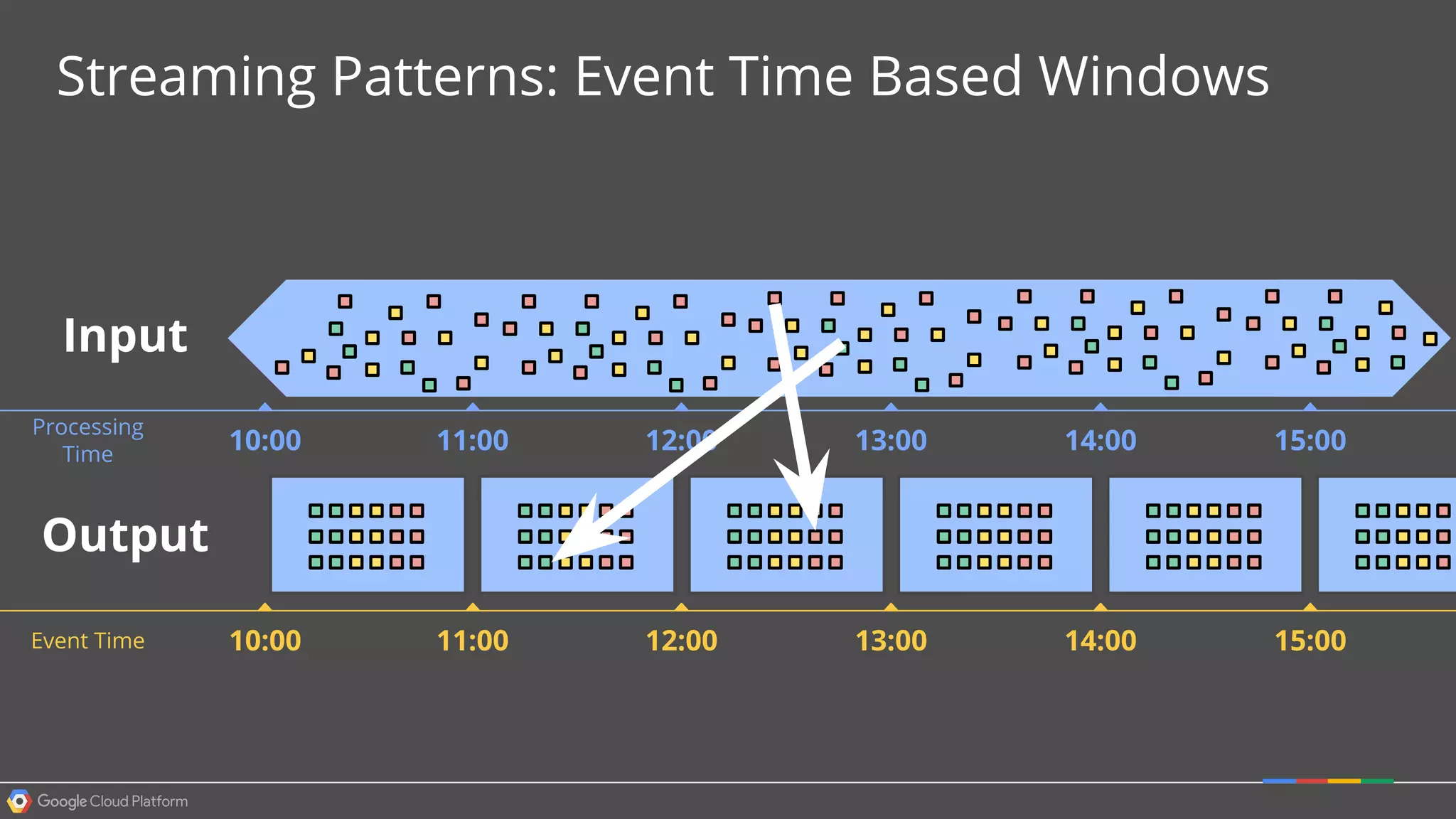

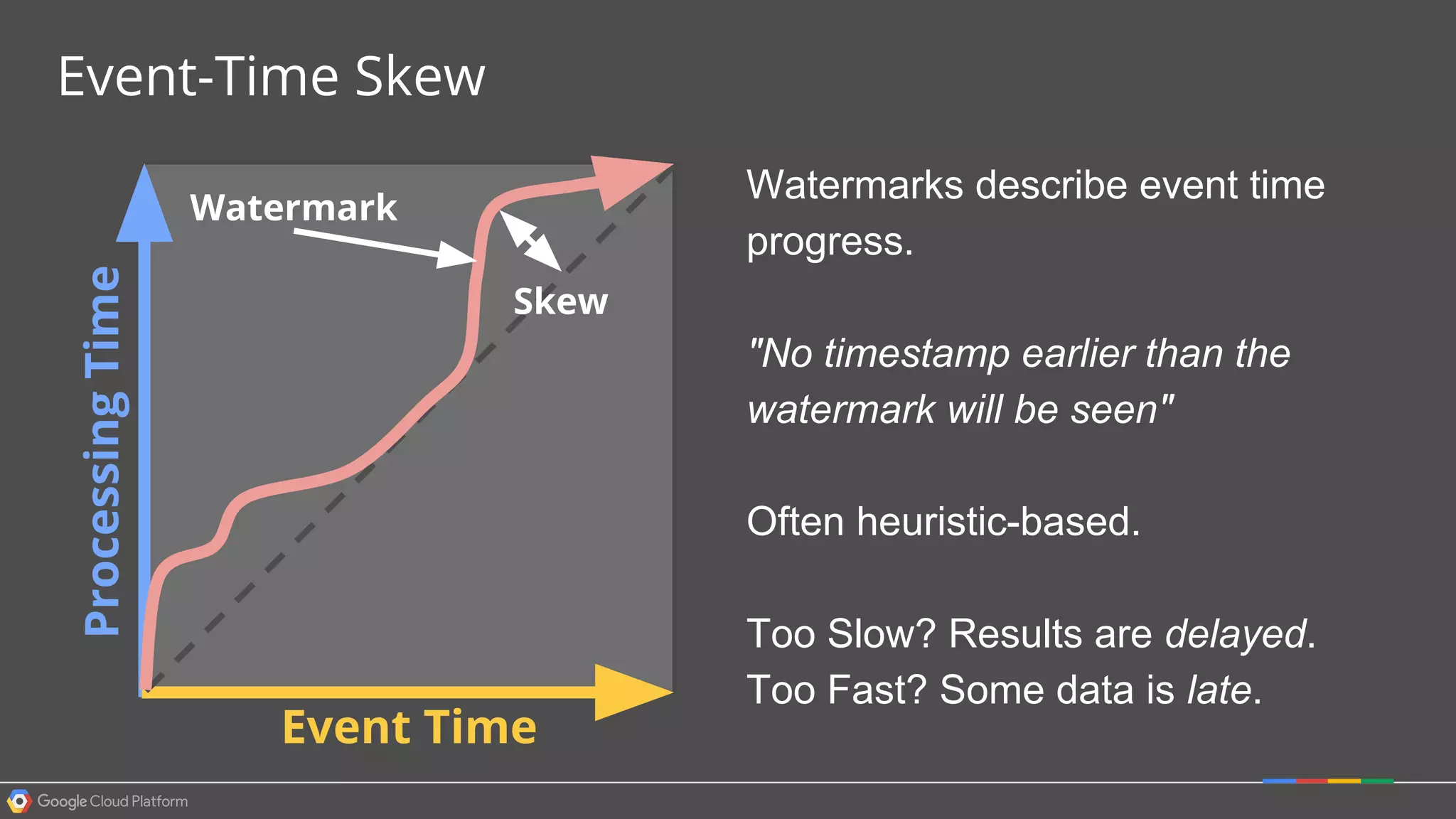


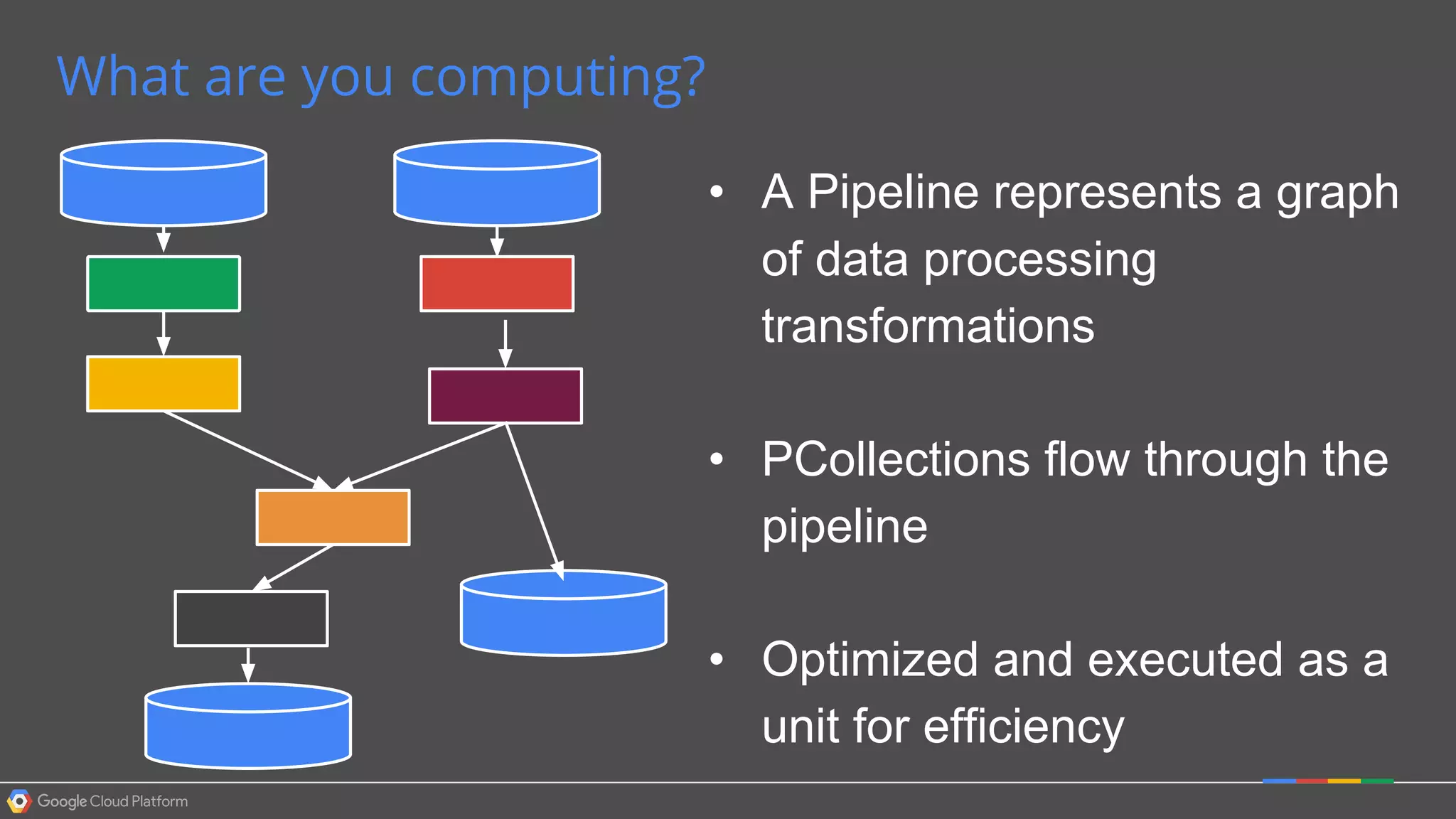
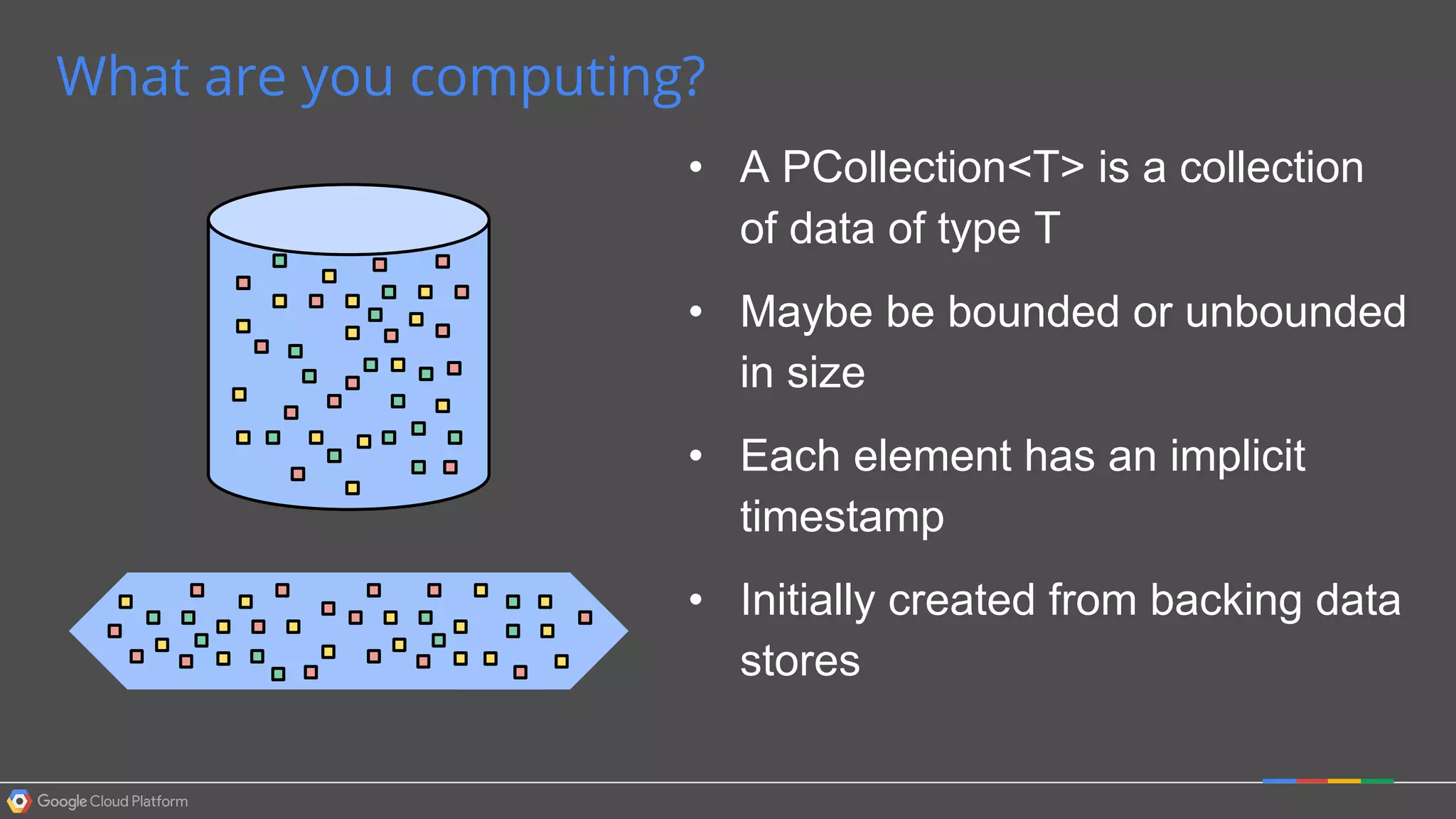

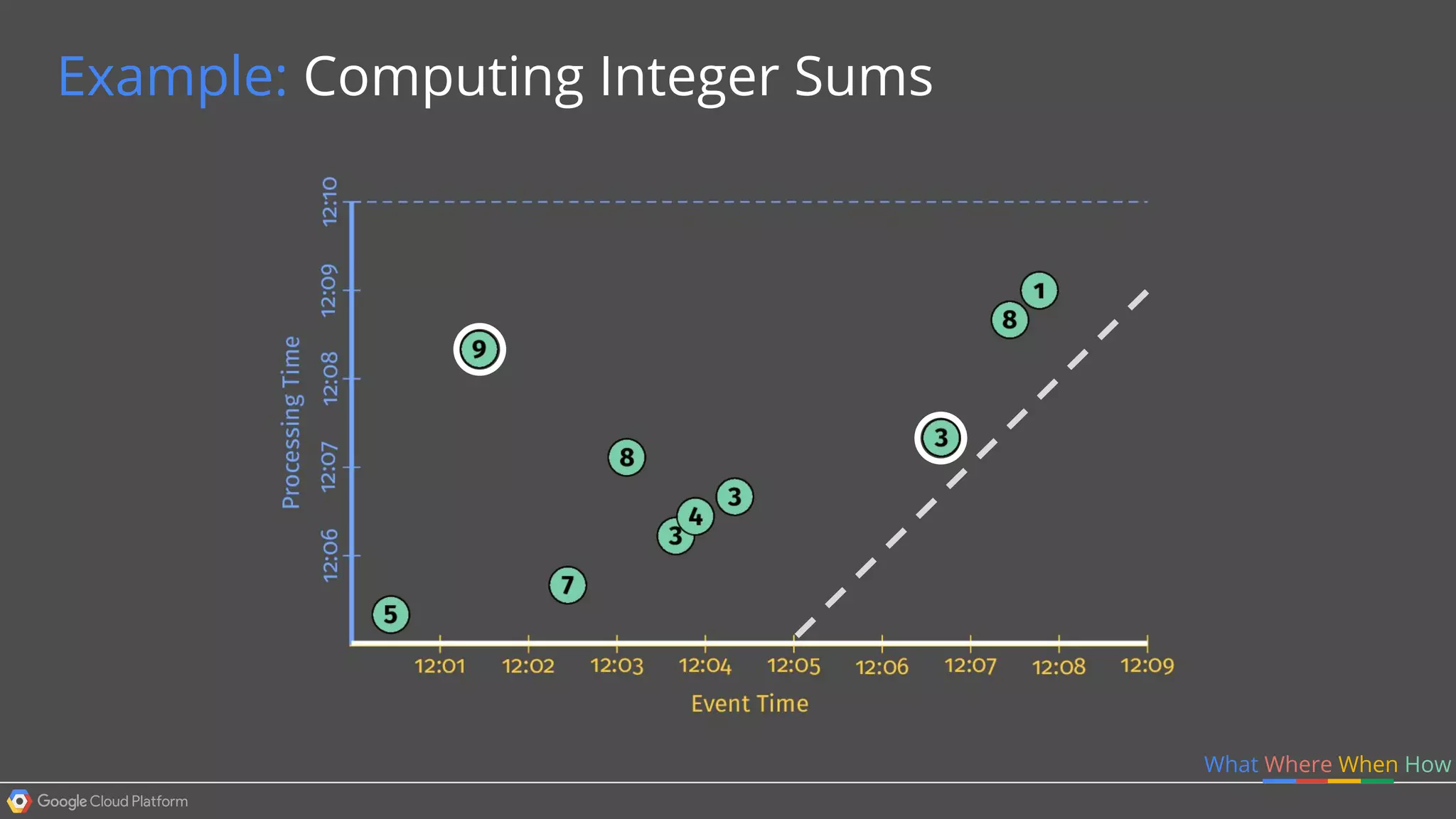
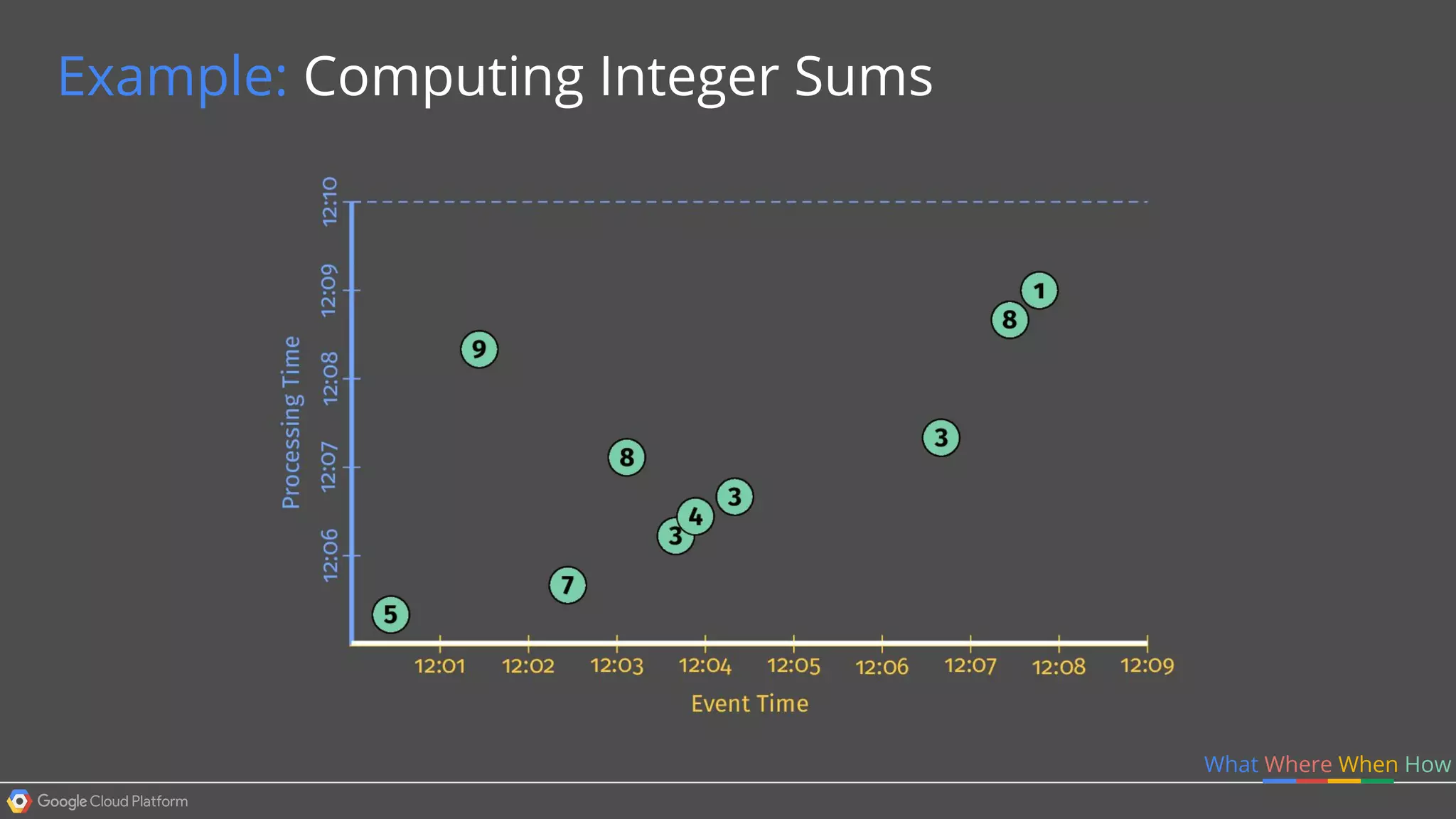
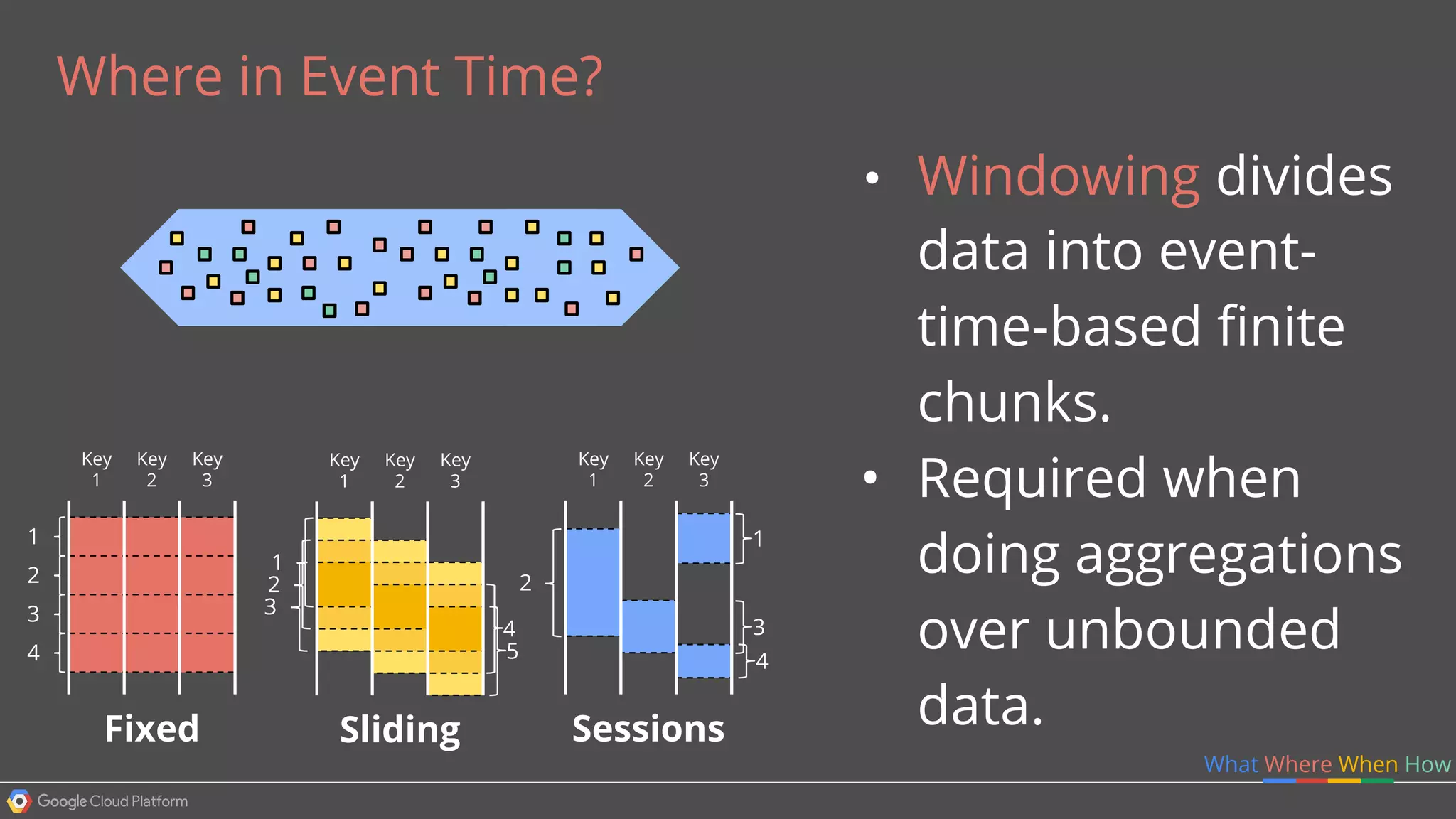
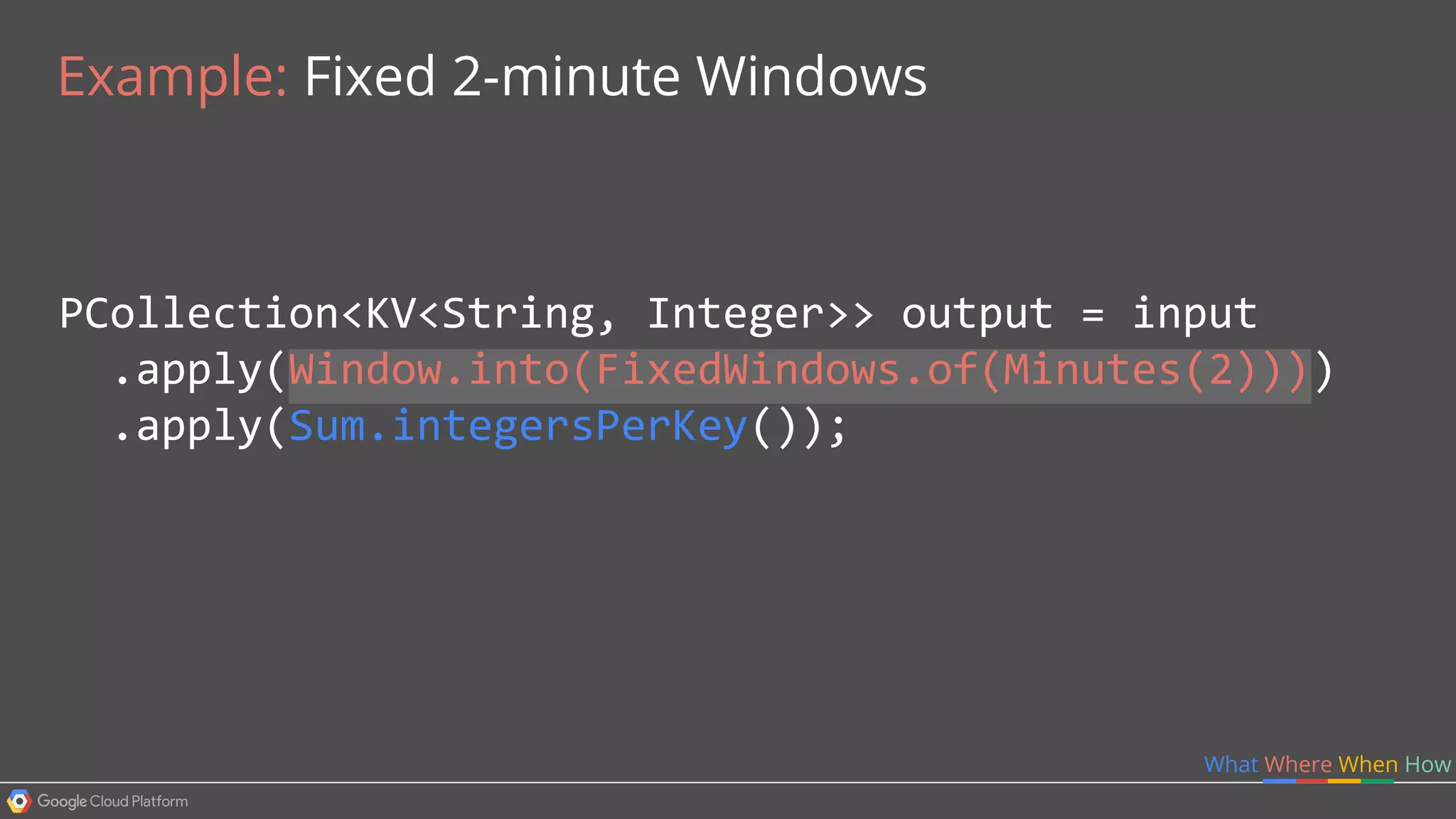
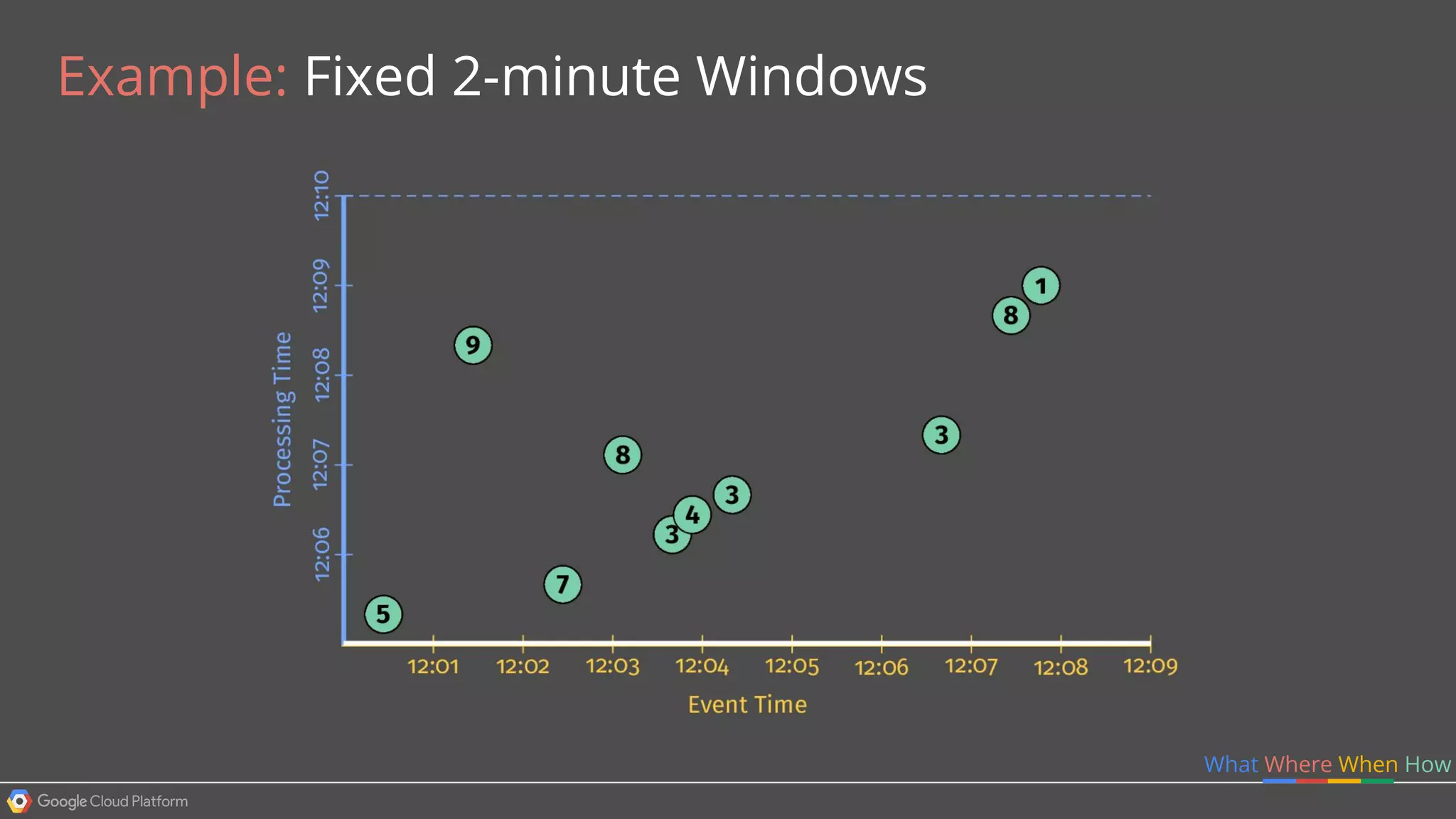
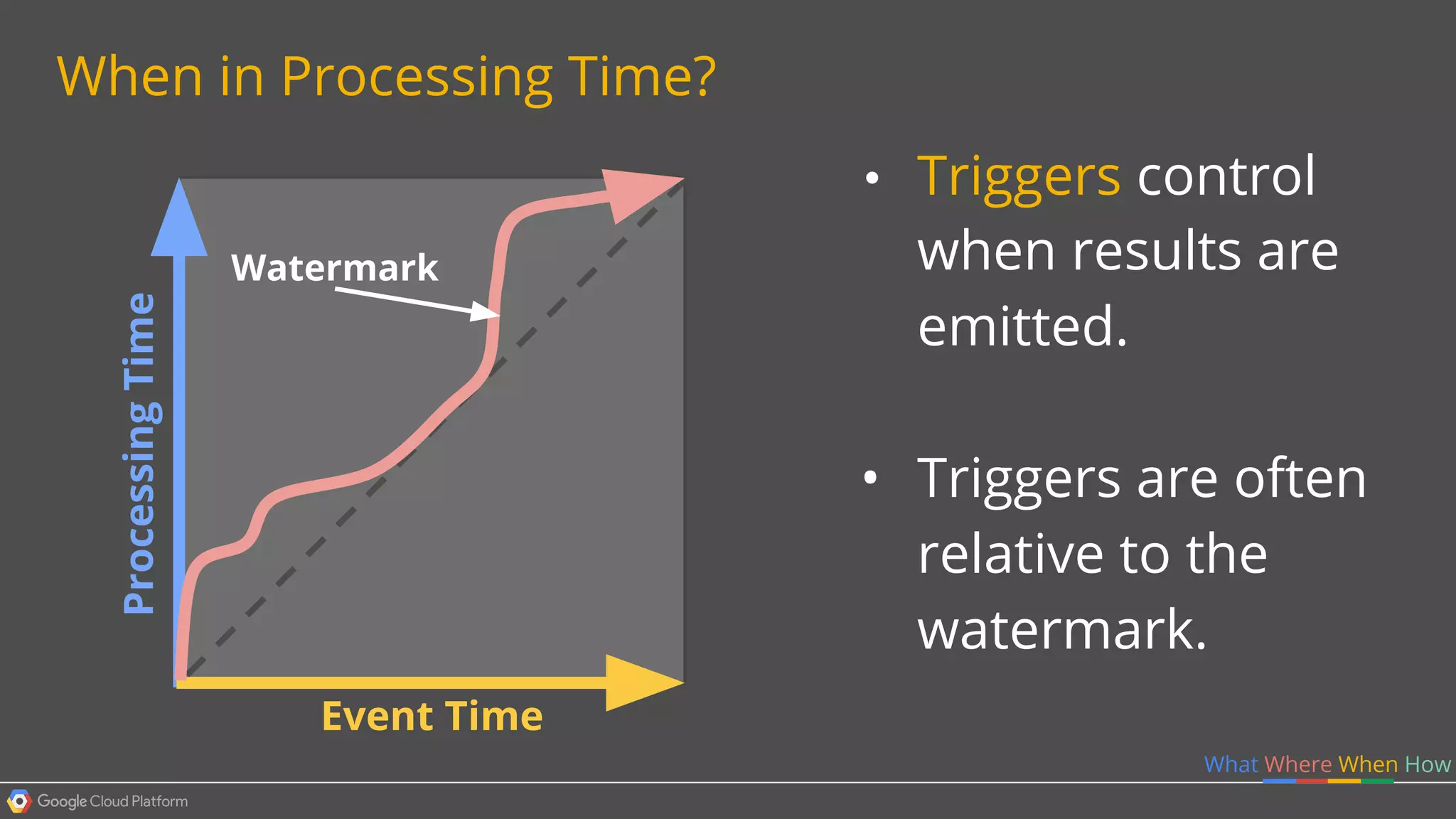
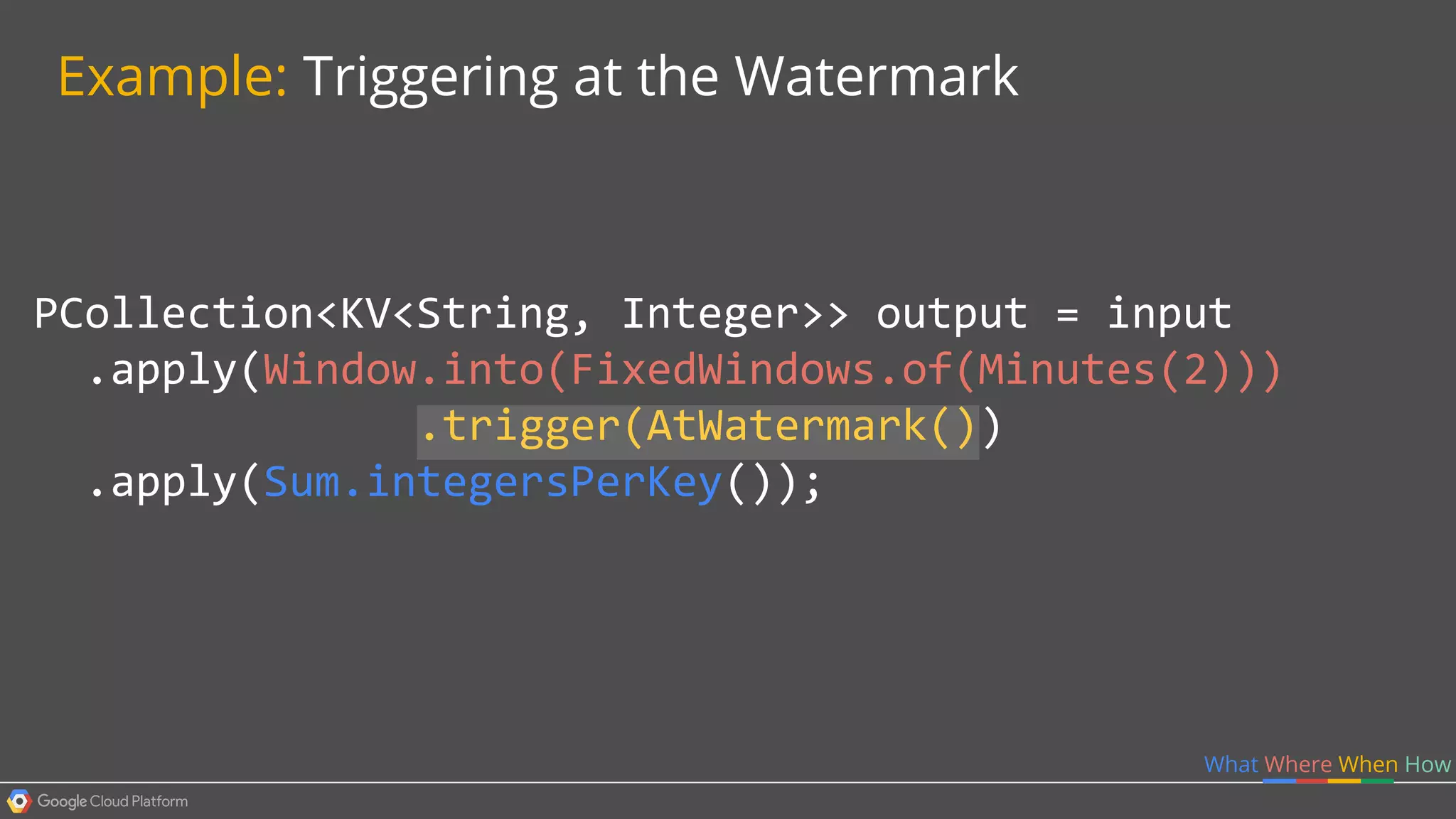
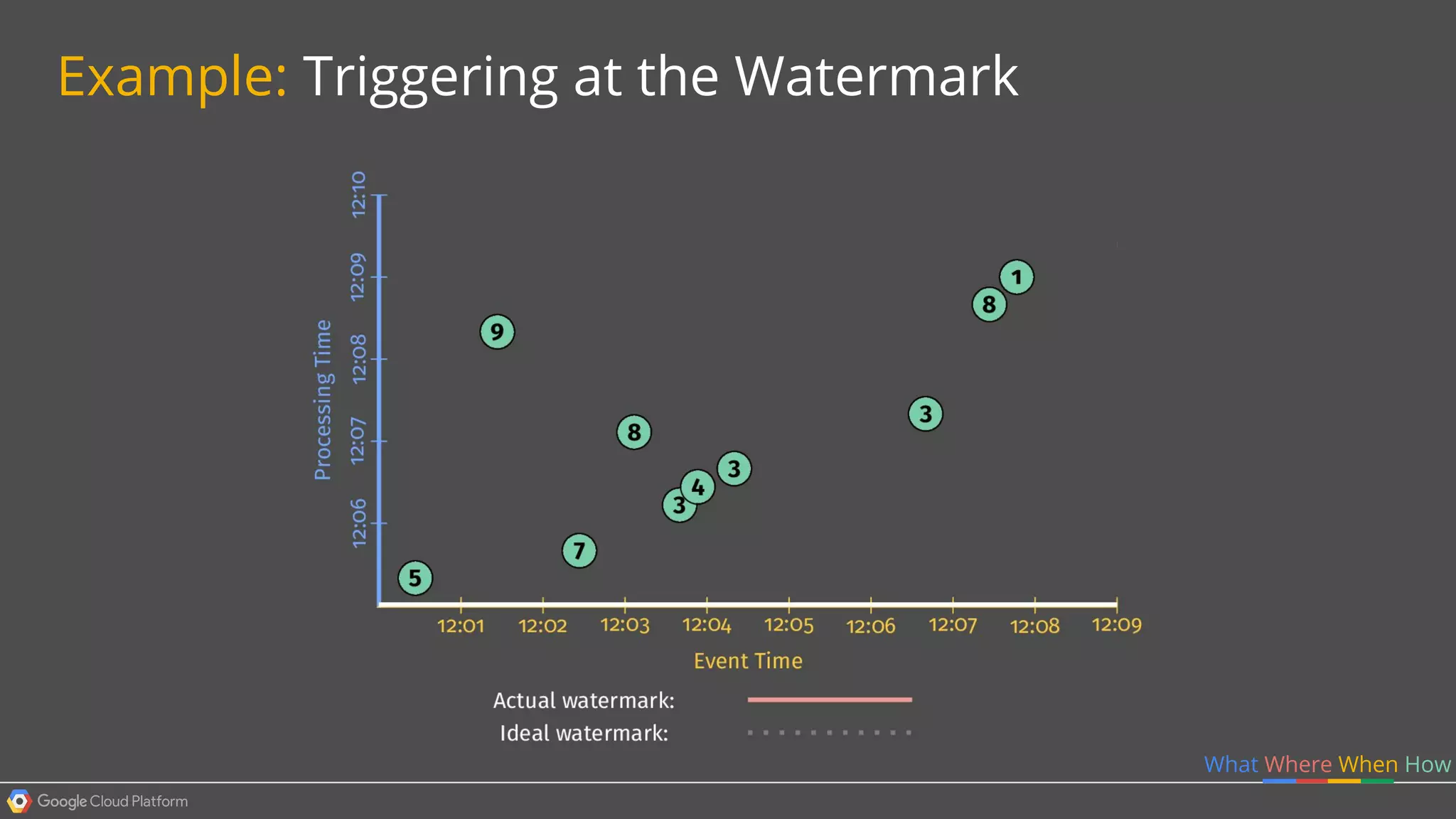

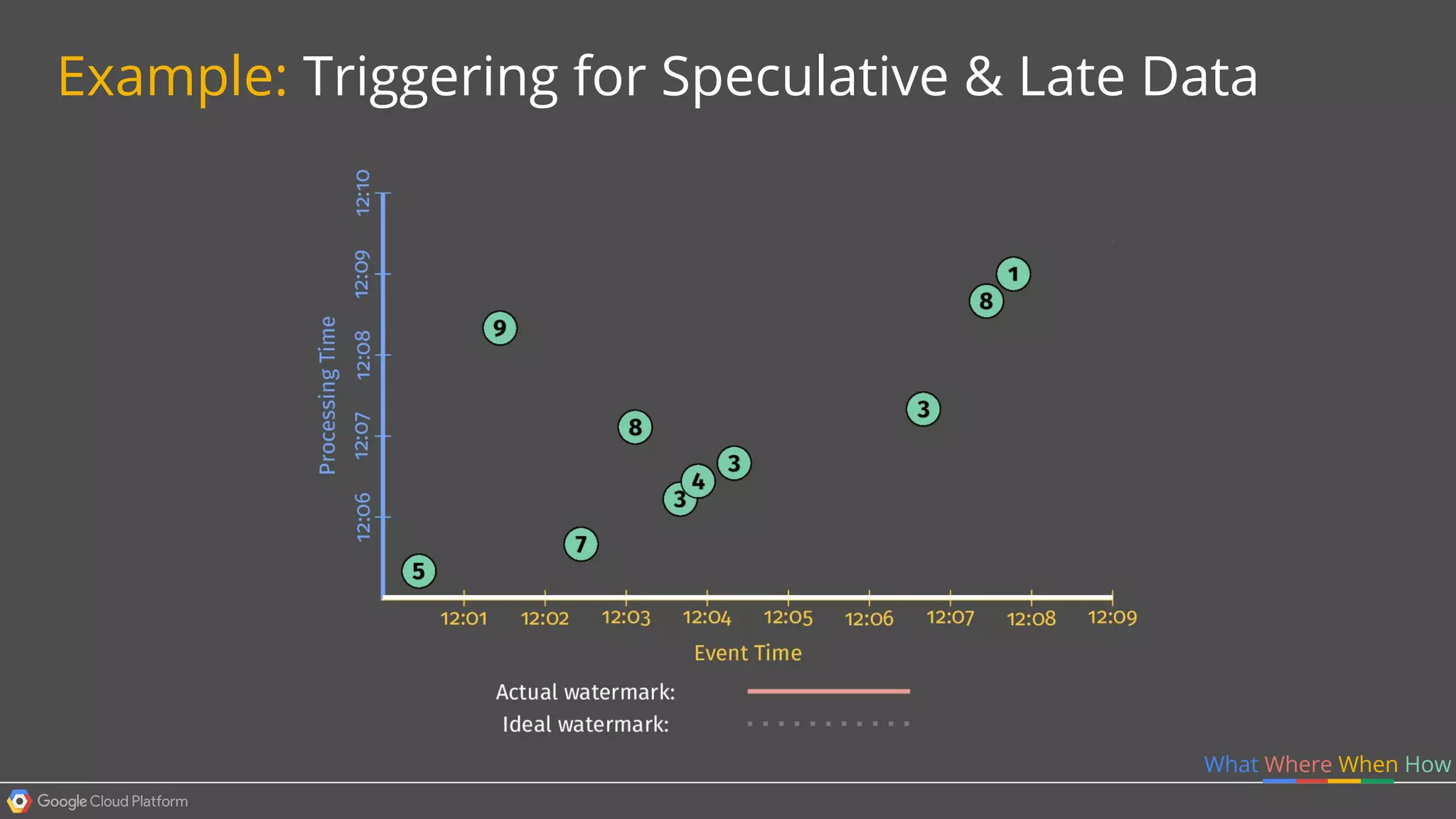
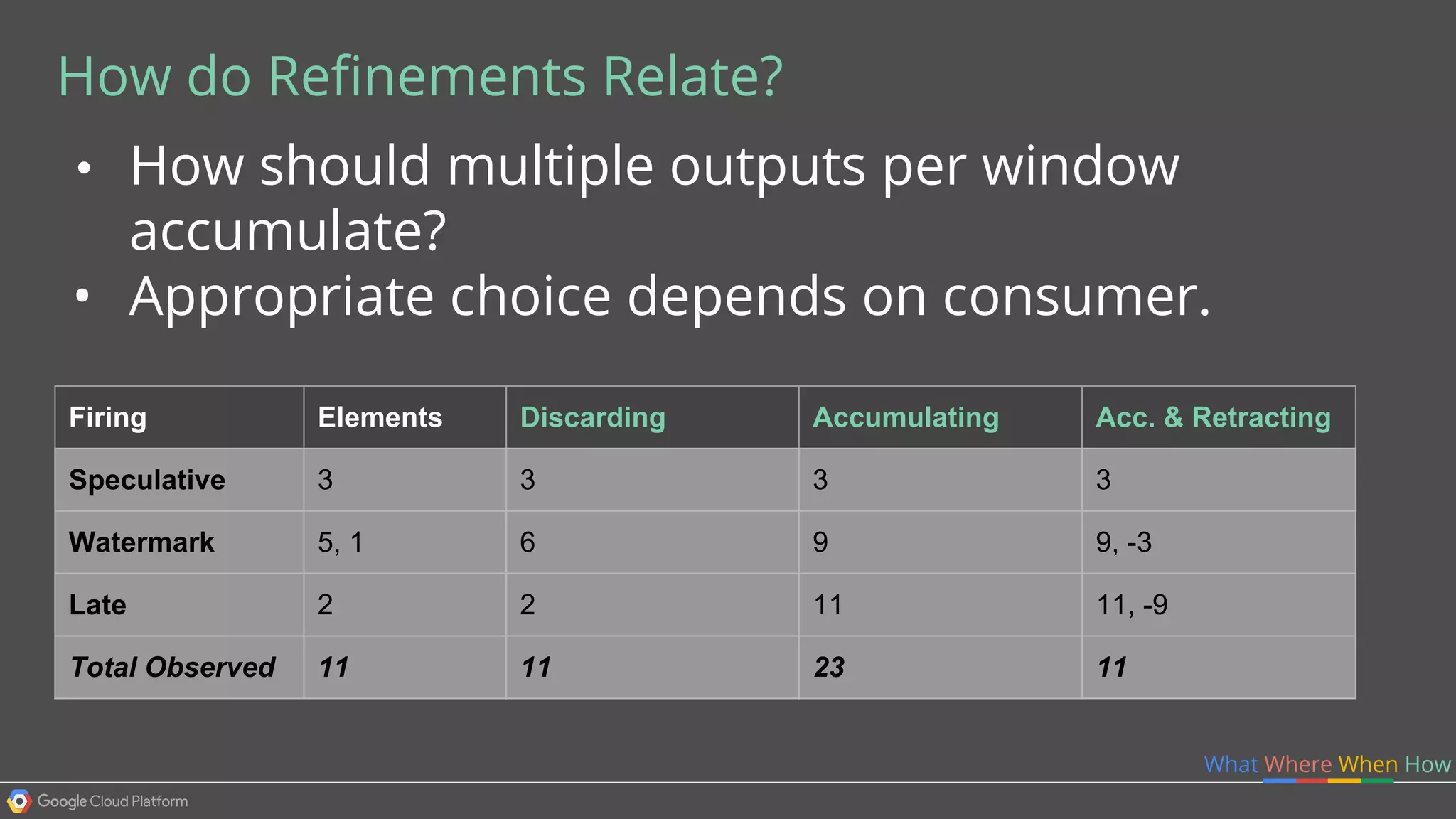

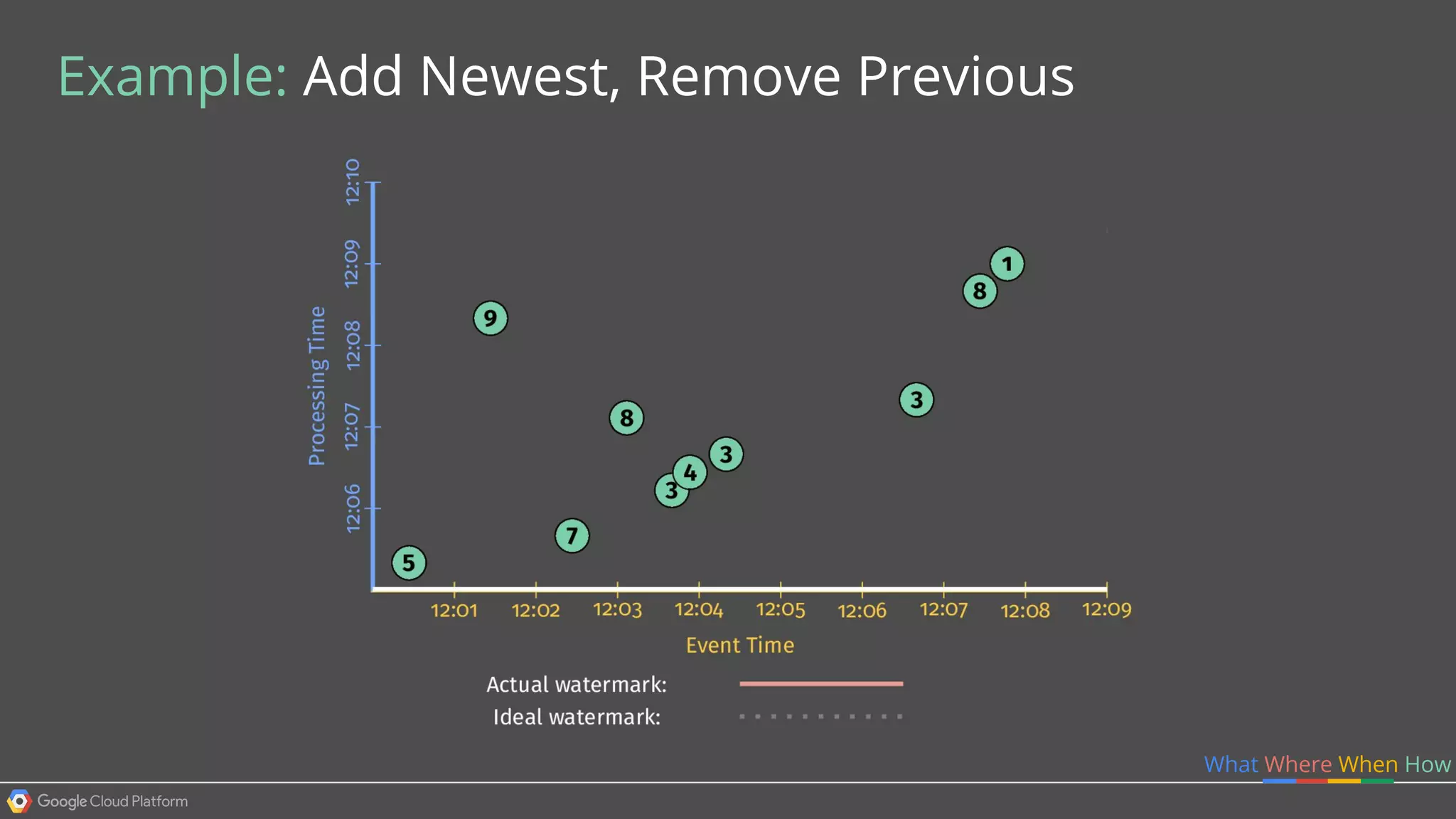
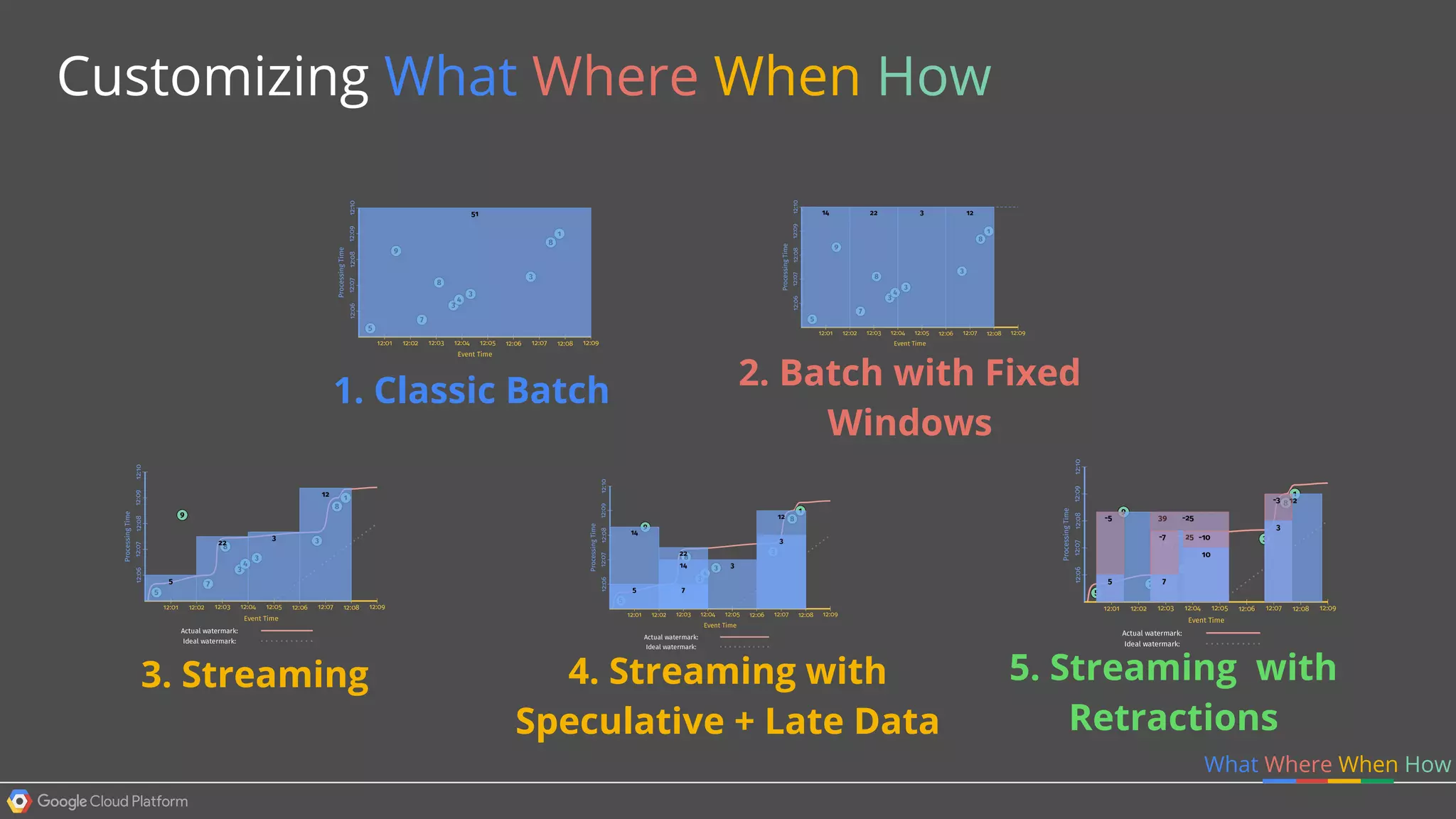

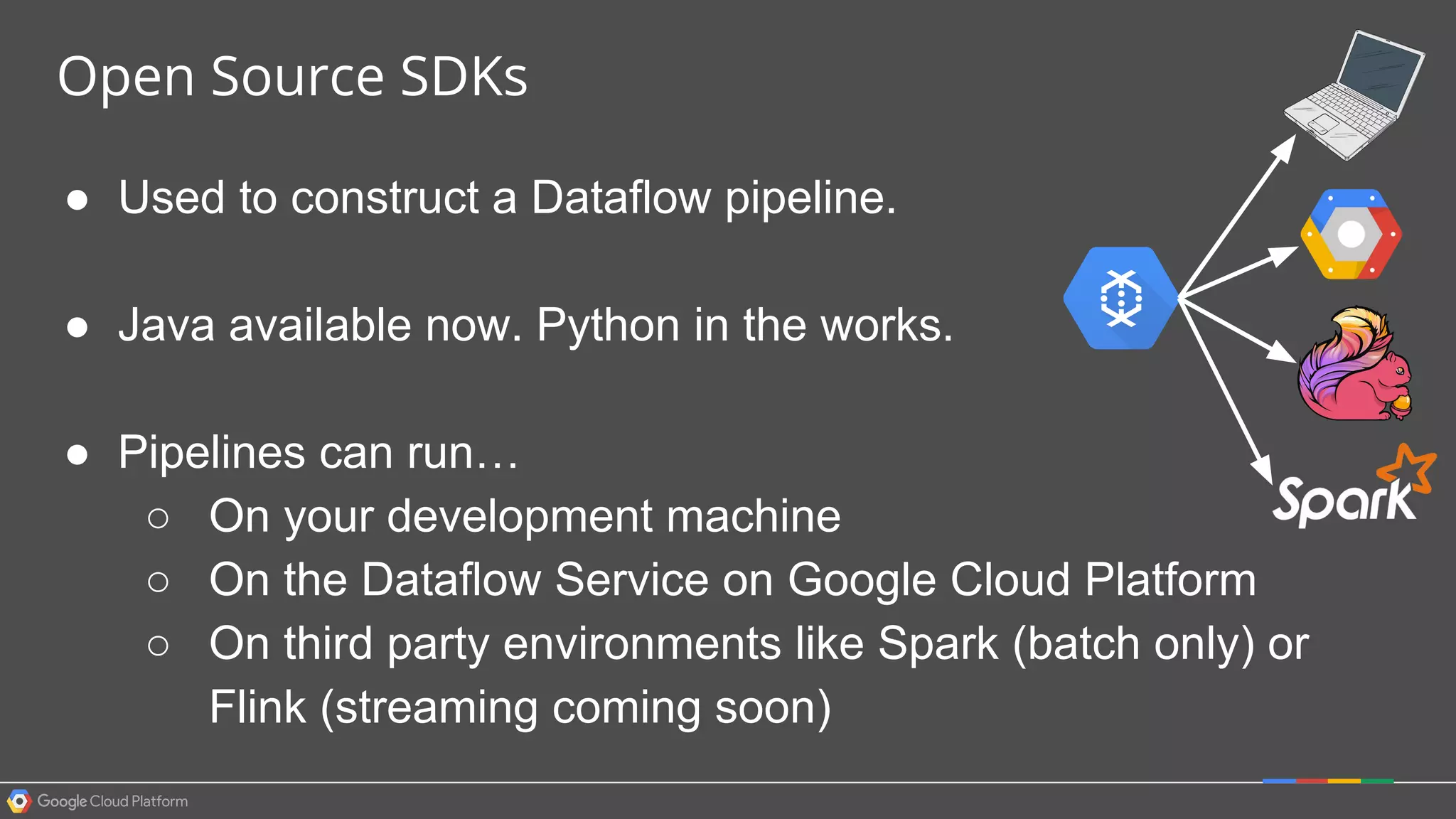


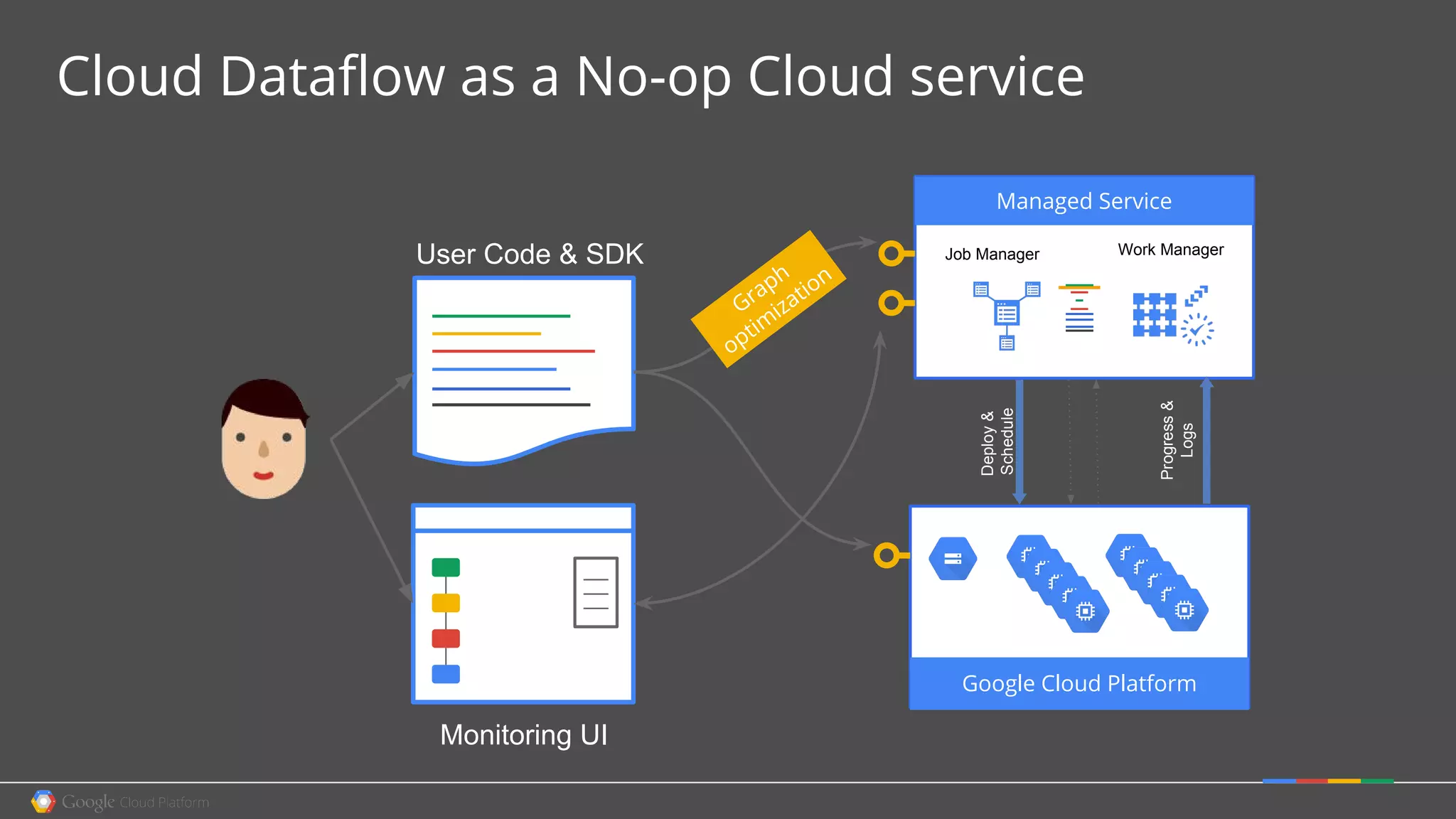
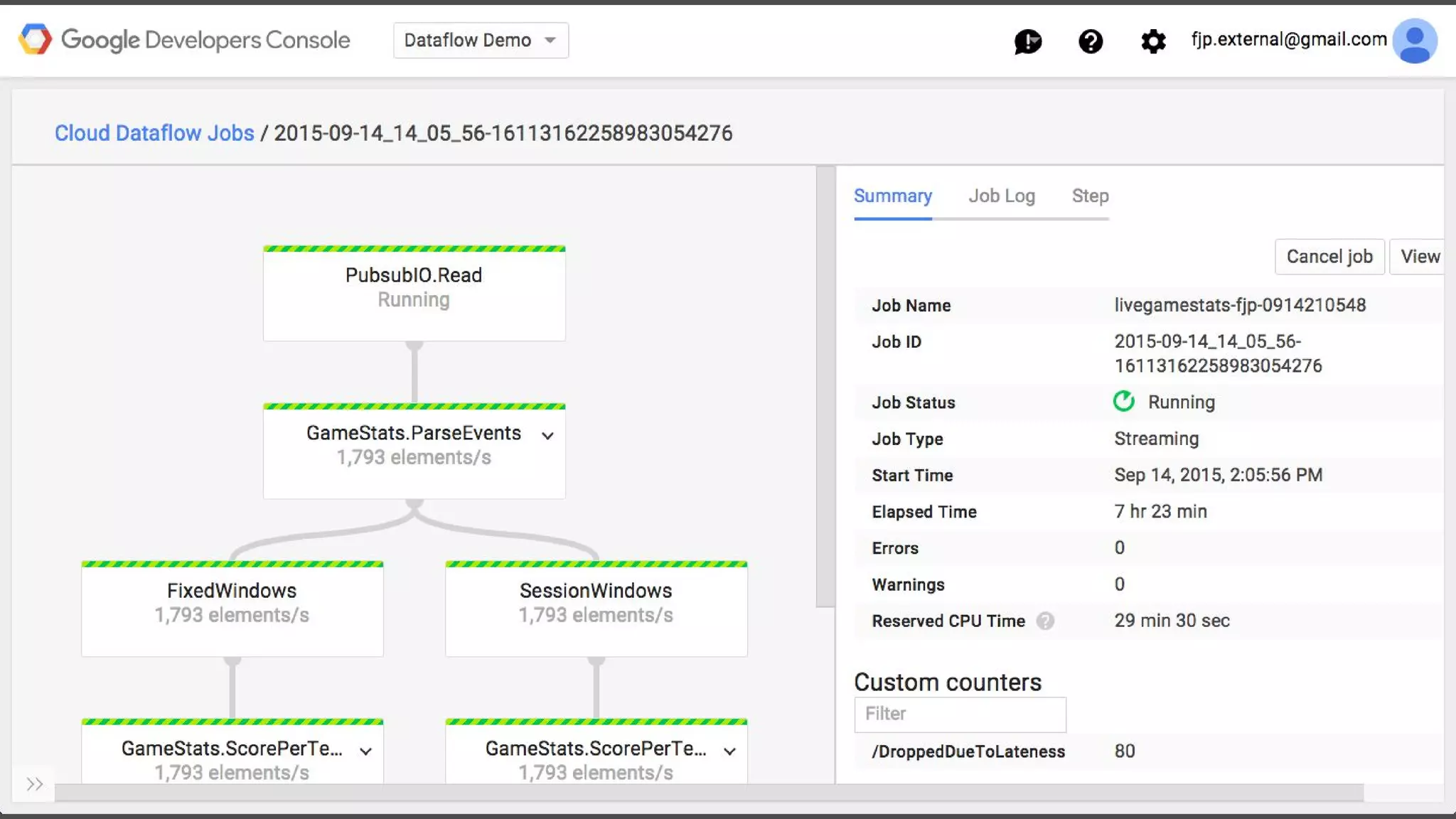
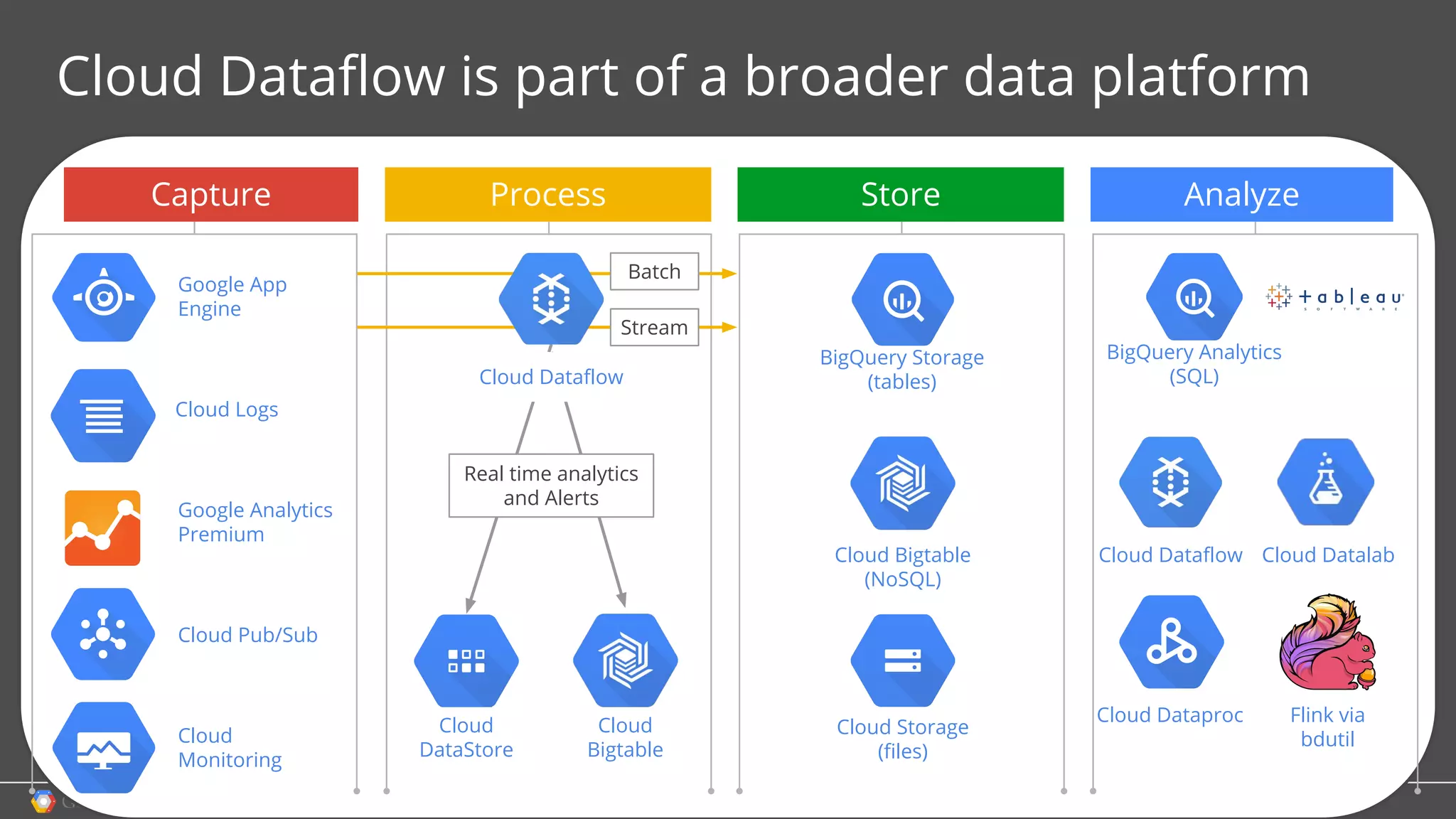

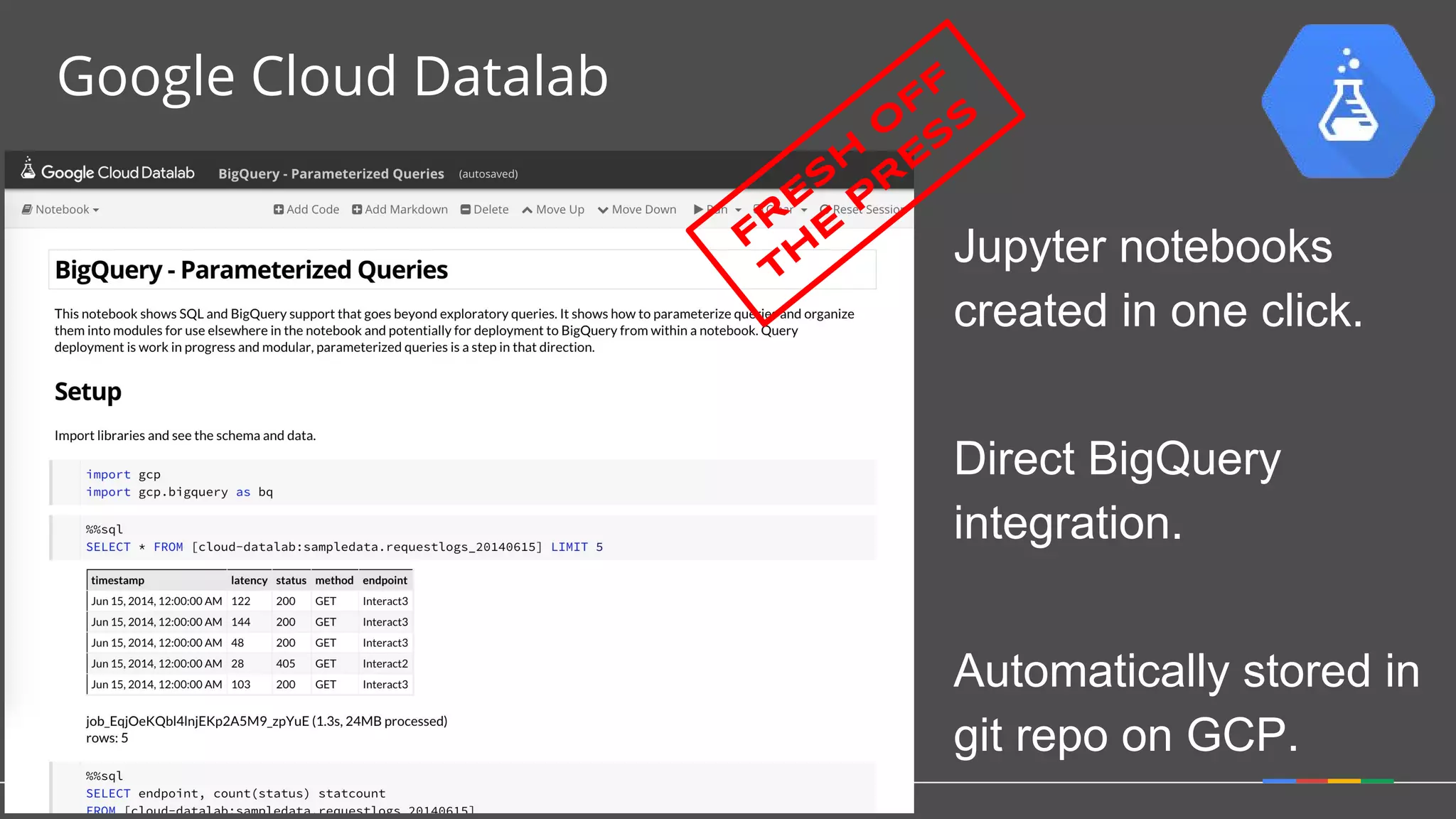


1. Google Cloud Dataflow is a fully managed service that allows users to define data processing pipelines that can run batch or streaming computations. 2. The Dataflow programming model defines pipelines as directed graphs of transformations on collections of data elements. This provides flexibility in how computations are defined across batch and streaming workloads. 3. The Dataflow service handles graph optimization, scaling of workers, and monitoring of jobs to efficiently execute user-defined pipelines on Google Cloud Platform.
































































































![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)








![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

