










![Facebook Analytics – Data Collected
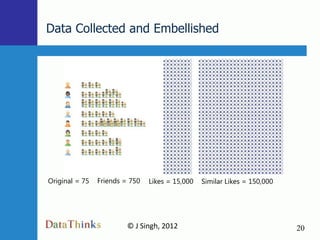
Original = 75 Friends = 750 Likes = up to about 20,000
• Each user record shows anonymized user ID and their likes
– 4110002004281 ['21506845769', '345722385482735', '93433060687']
© J Singh, 2012 16
16](https://image.slidesharecdn.com/mapreduceworkshop-121111105222-phpapp01/85/Facebook-Analytics-with-Elastic-Map-Reduce-16-320.jpg)



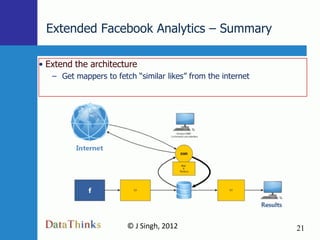



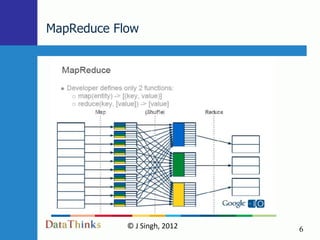
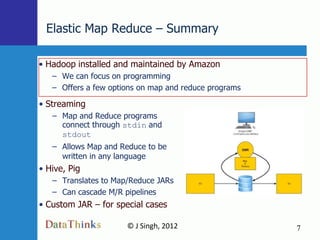
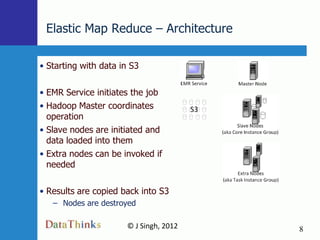
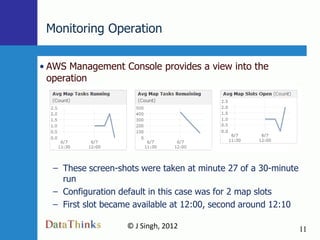
Map Reduce is a simple programming model that is well-suited for distributed computing. Hadoop is an open-source implementation of MapReduce that can run on large clusters of commodity hardware. Amazon Elastic MapReduce (EMR) provides a hosted Hadoop service that simplifies using MapReduce without needing to deploy and manage your own Hadoop cluster. The document discusses using EMR to analyze Facebook data at scale through examples like word counting and analyzing likes.







































































































