









![Amazon SimpleDBKey-value storeWritten in Erlang, (as is CouchDB)Data is modeled in terms ofDomain, a container of entities,Item, an entity and Attribute and Value, a property of an ItemEventually Consistent, except when ReadConsistent flag specifiedImpressive performance numbers, e.g., .7 sec to store 1 million recordsSQL-like SELECTselect output_listfrom domain_name[where expression] [sort_instructions] [limit limit]](https://image.slidesharecdn.com/nosql-110601101336-phpapp01/75/NoSQL-and-MapReduce-12-2048.jpg)

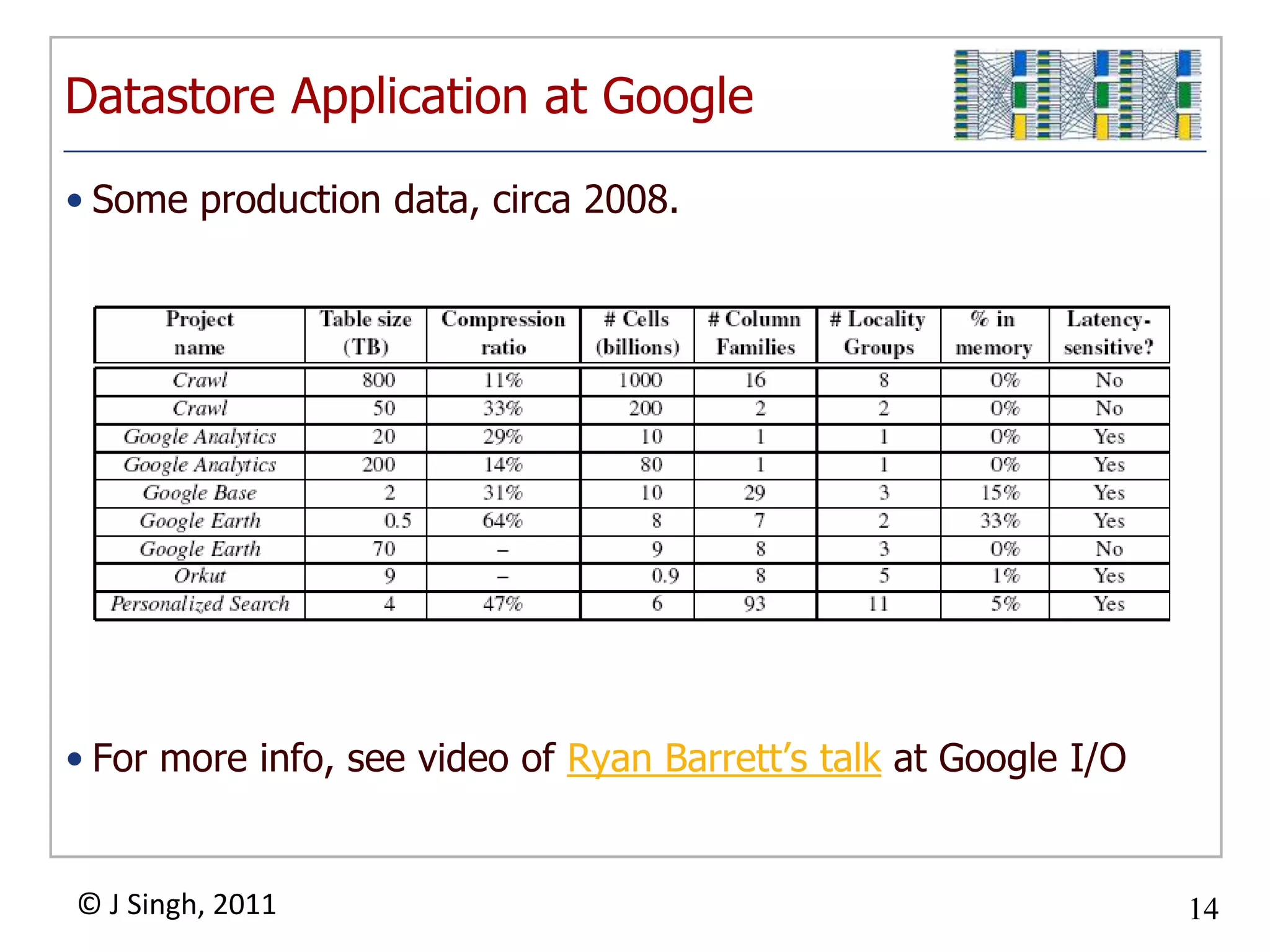

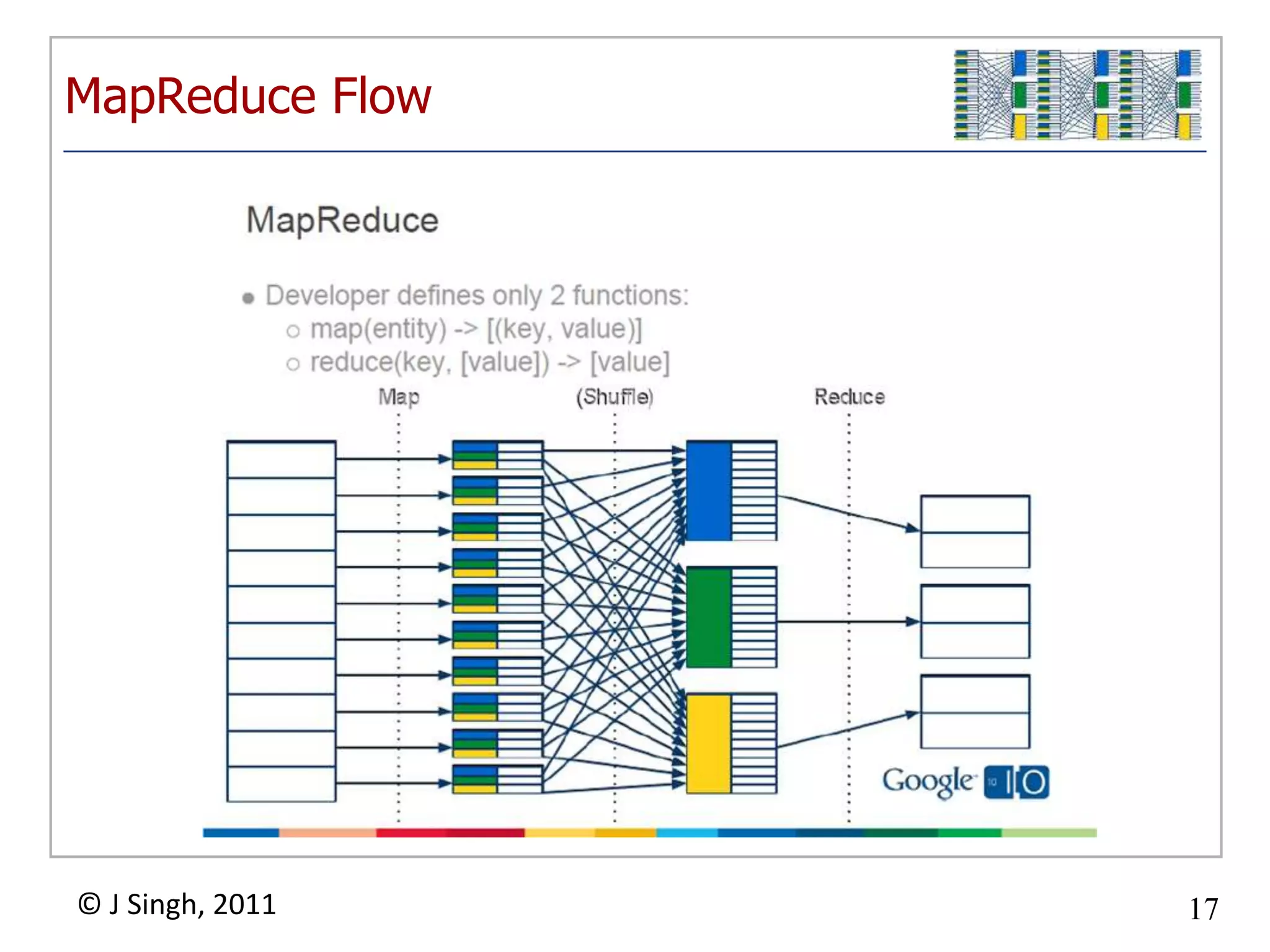





The document discusses NoSQL databases and MapReduce. It provides historical context on how databases were not adequate for the large amounts of data being accumulated from the web. It describes Brewer's Conjecture and CAP Theorem, which contributed to the rise of NoSQL databases. It then defines what NoSQL databases are, provides examples of different types, and discusses some large-scale implementations like Amazon SimpleDB, Google Datastore, and Hadoop MapReduce.











































































































