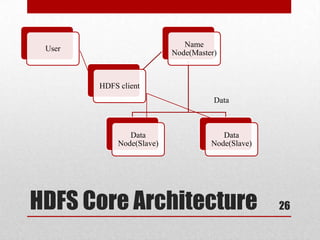
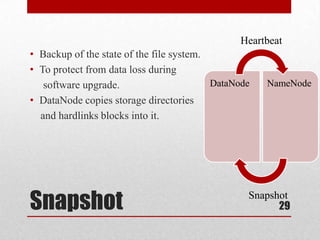
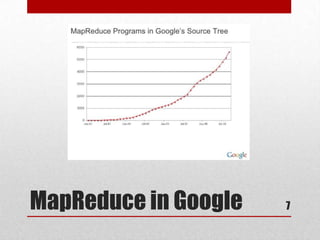
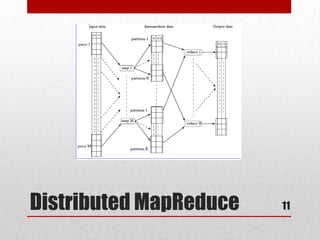
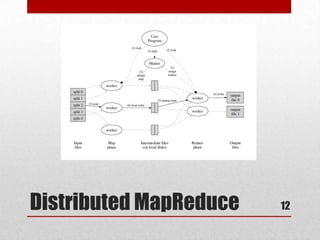
This document discusses large scale computing with MapReduce. It provides background on the growth of digital data, noting that by 2020 there will be over 5,200 GB of data for every person on Earth. It introduces MapReduce as a programming model for processing large datasets in a distributed manner, describing the key aspects of Map and Reduce functions. Examples of MapReduce jobs are also provided, such as counting URL access frequencies and generating a reverse web link graph.













![• MapReduce runtime library[8]:
• Automatic parallelization.
• Load balancing.
• Network and disk transfer optimization.
• Handling of machine failure.
• Robustness.
MapReduce: runtime
library 19](https://image.slidesharecdn.com/largescalecomputingwithmapreducefinal-130220174747-phpapp02/85/Large-scale-computing-with-mapreduce-19-320.jpg)