Downloaded 138 times



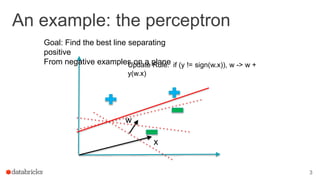









![Why is this hard?
• Need to update model, i.e
• Update(previousModel, newDataPoint) = newModel
• Typical aggregation is associative, commutative
• e.g. sum( P1: sum(sum(0, data[0]), data[1]), P2:
sum(sum(0, data[2]), data[3]))
• General model update violates associativity +
commutativity!
18](https://image.slidesharecdn.com/onlinelearningwithstructuredstreamingsparksummitbrussels2016-161103213812/85/Online-learning-with-structured-streaming-spark-summit-brussels-2016-18-320.jpg)
![Solution: Make Assumptions
• Result may be partition-dependent, but we don’t
care as long as we get some valid result.
average-models(
P1: update(update(previous model, data[0]), data[1]),
P2: update(update(previous model, data[2]), data[3]))
• Only partition-dependent if update and average
don’t commute - can still be deterministic
otherwise!
19](https://image.slidesharecdn.com/onlinelearningwithstructuredstreamingsparksummitbrussels2016-161103213812/85/Online-learning-with-structured-streaming-spark-summit-brussels-2016-19-320.jpg)

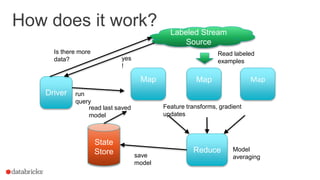

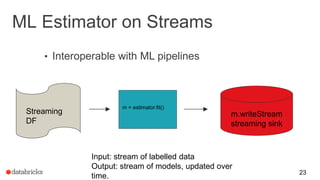





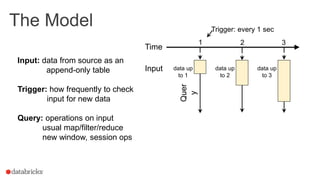
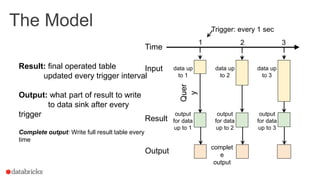
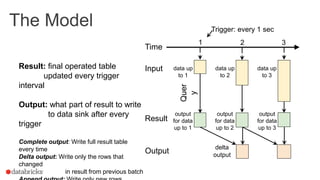
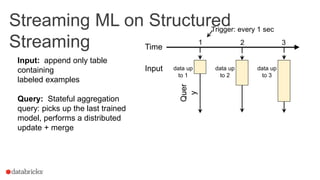
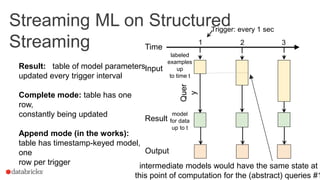
This document summarizes an online presentation about online learning with structured streaming in Spark. The key points are: - Online learning updates model parameters for each data point as it arrives, unlike batch learning which sees the full dataset before updating. - Structured streaming in Spark provides a single API for batch, streaming, and machine learning workloads. It offers exactly-once guarantees and understands external event time. - Streaming machine learning on structured streaming works by having a stateful aggregation query that picks up the last trained model and performs a distributed update and merge on each trigger interval. This allows modeling streaming data in a fault-tolerant way.










































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)












