


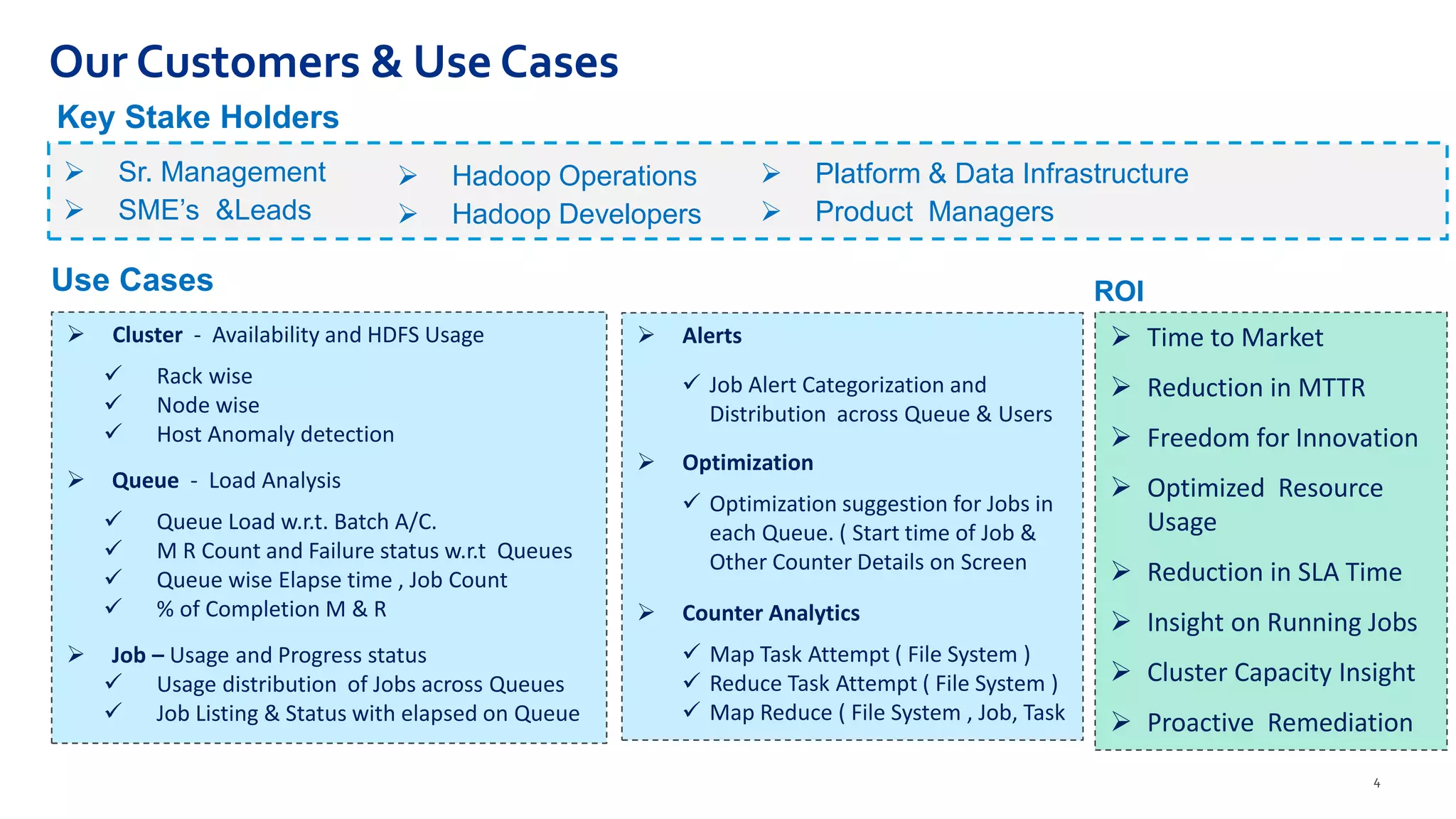

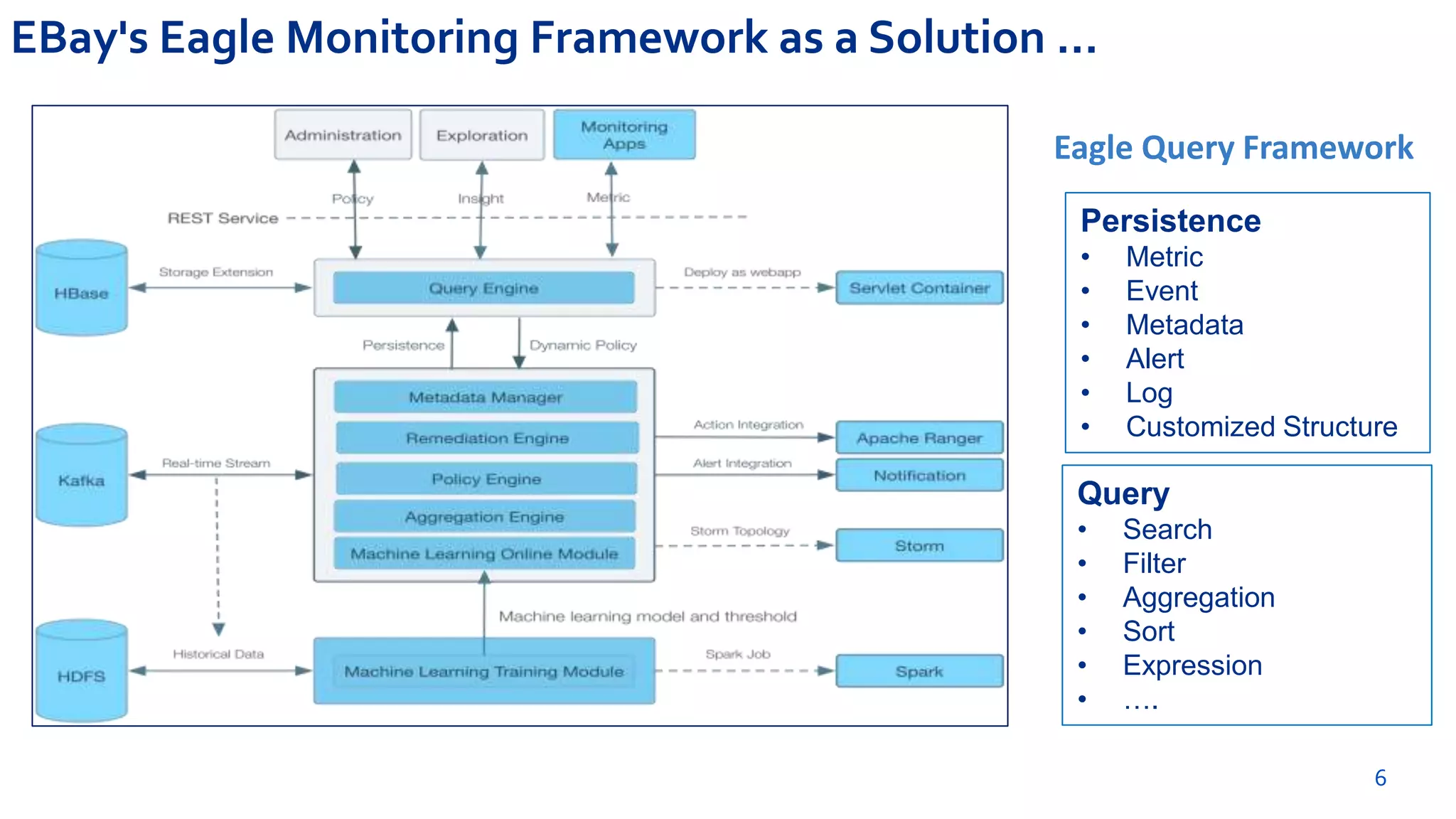





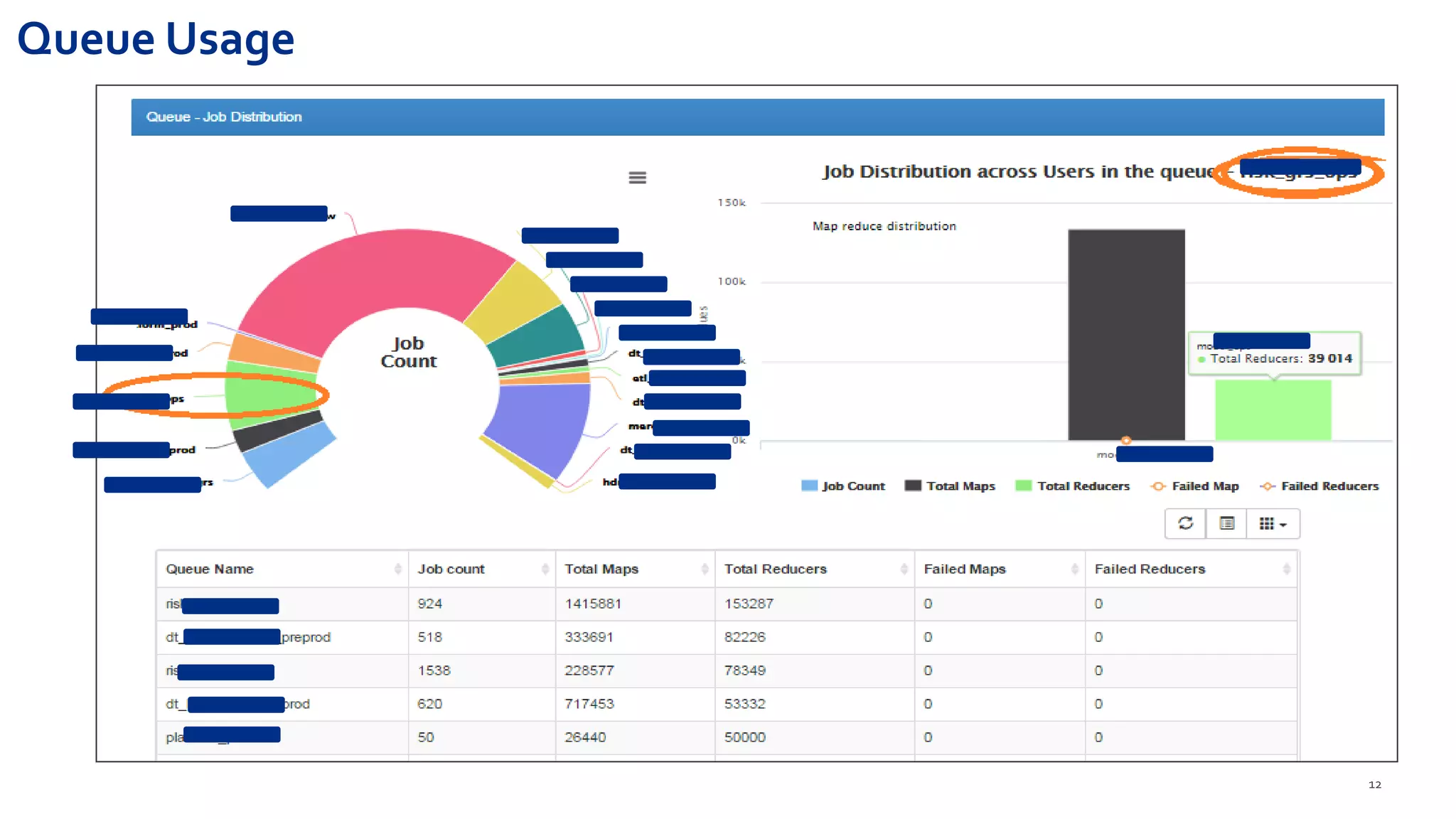


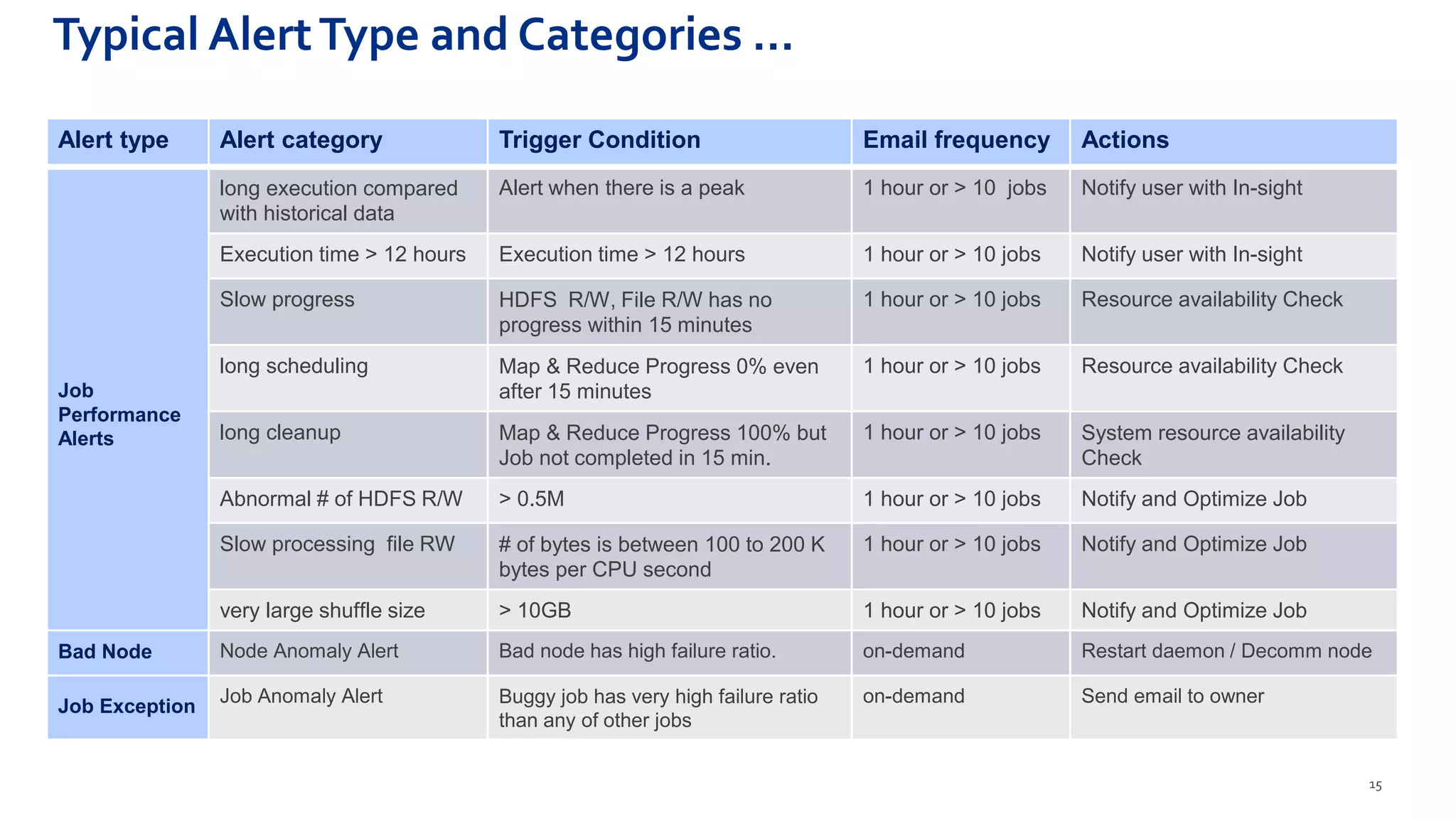
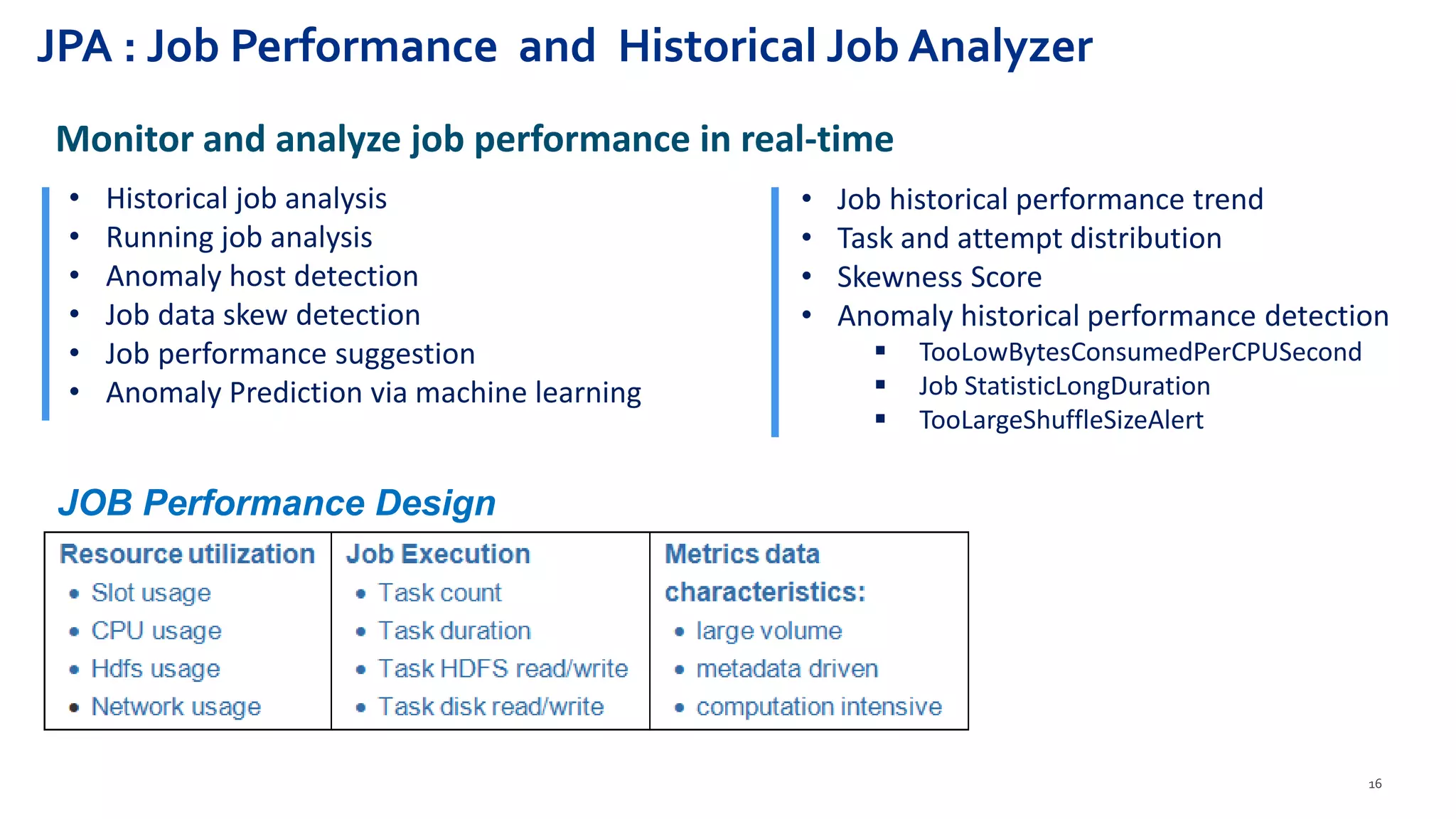





Hadoop Usage Insight (HUI 1.0) is a web-enabled analytics application designed to provide detailed insights into the performance and usage of applications running on Hadoop clusters, processing large volumes of data and metrics. The application includes features for anomaly detection, optimization suggestions, job performance analysis, and real-time monitoring tailored for various stakeholders including management and developers. The solution leverages the Eagle framework for monitoring and alerting based on multiple data sources and metrics correlation.



































































