Downloaded 438 times

















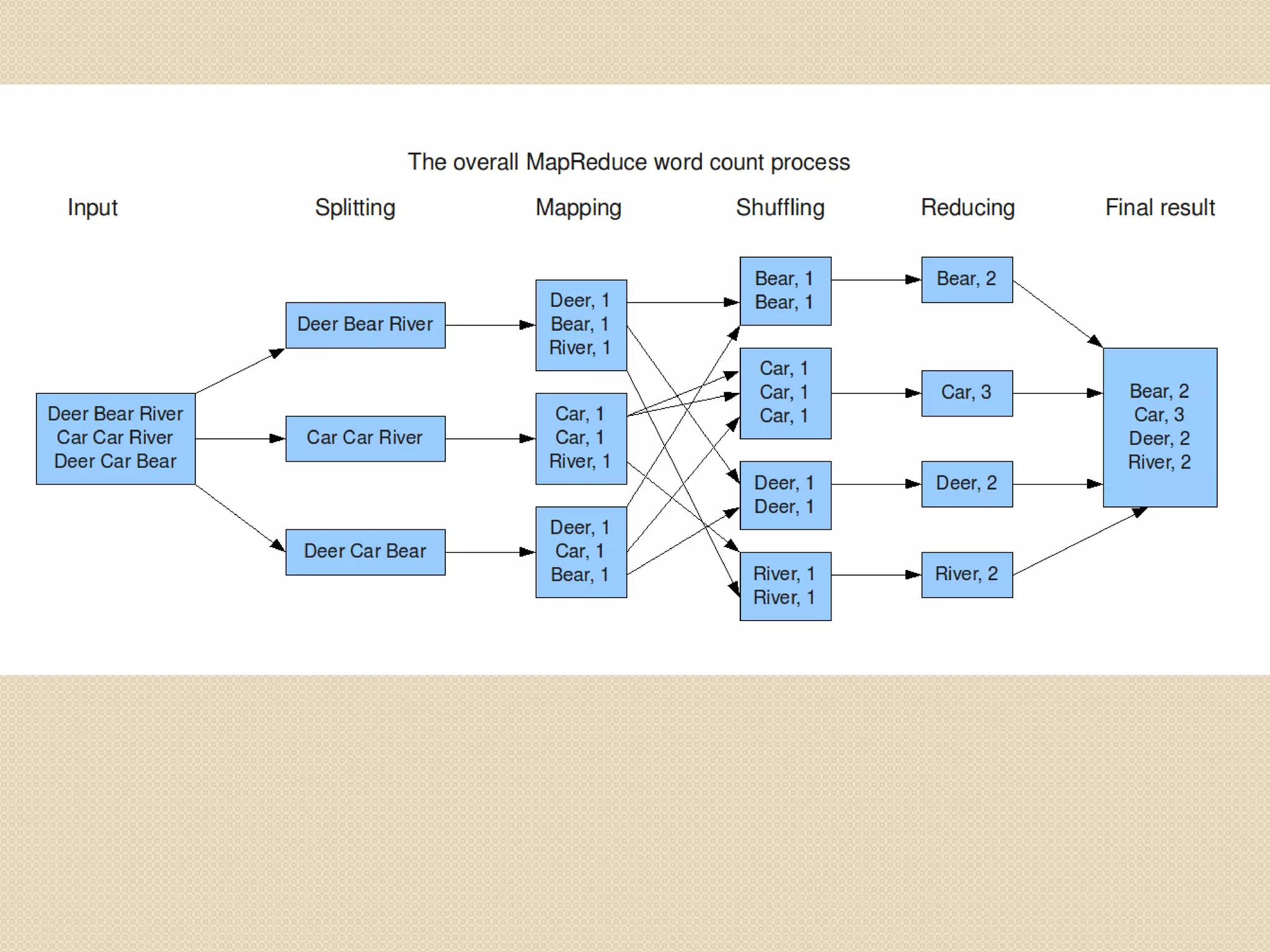
![MapReduce Example
Map function extracts the year and
temp:
◦ (1950, 0), (1950, 22), (1950, -11), (1949,
111), (1949, 78)
MapReduce sorts and groups the
data:
◦ (1949, [111,78])
◦ (1950, [0, 22, -11])
Reduce function iterates through the
list:](https://image.slidesharecdn.com/apachehadoop-120221113220-phpapp01/75/Introduction-to-Apache-Hadoop-18-2048.jpg)

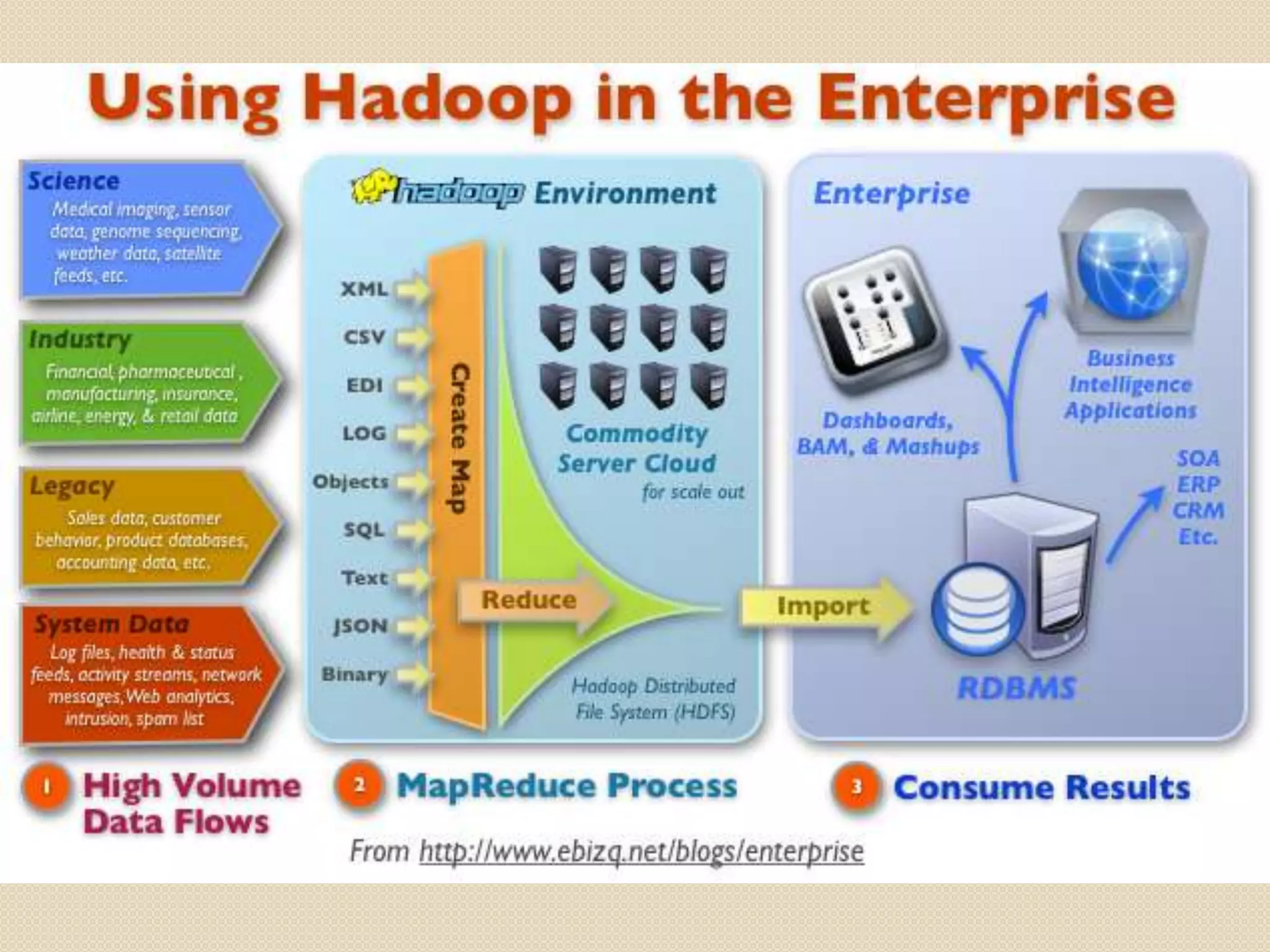






This document provides an introduction and overview of Apache Hadoop. It discusses how Hadoop provides the ability to store and analyze large datasets in the petabyte range across clusters of commodity hardware. It compares Hadoop to other systems like relational databases and HPC and describes how Hadoop uses MapReduce to process data in parallel. The document outlines how companies are using Hadoop for applications like log analysis, machine learning, and powering new data-driven business features and products.



































































