Download to read offline




![13
Batch Processing with Unix Tools, MapReduce, and Spark
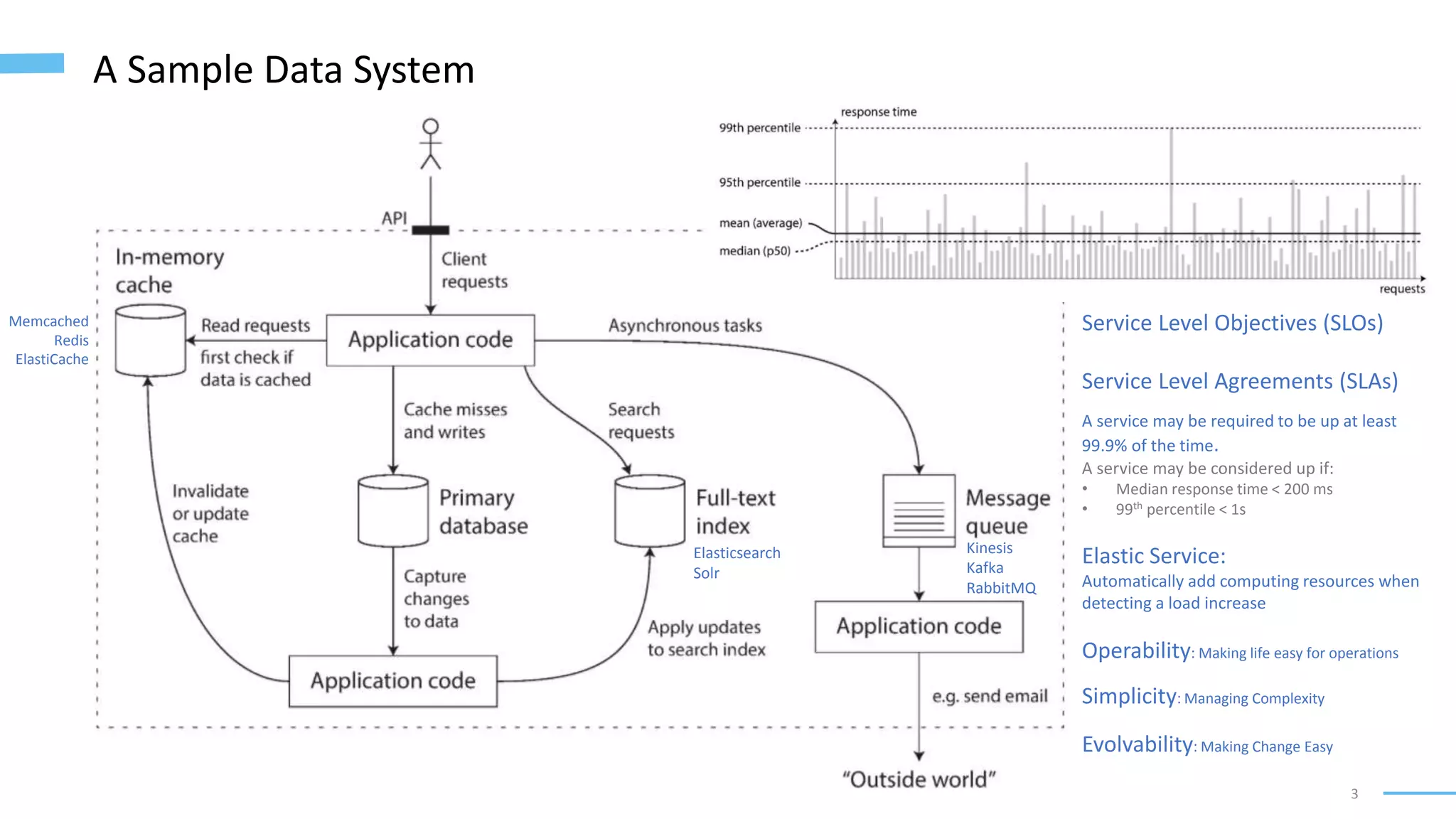
• Services [HTTP/REST-based APIs] (online systems)
• Batch Processing Systems (offline systems)
• Stream Processing Systems (near-real-time systems)
Batch Processing Web Logs with Unix Tools
Output:
MapReduce and Distributed Filesystems
• Read a set of input files and break it up into records.
• Call the mapper function to extract a key and value from each input record.
awk '{print $7}': it extracts the URL ($7) as the key and leaves the value empty.
• Sort all the key-value pairs by key.
This is done by the first sort command.
• Call the reducer function to iterate over the sorted key-value pairs.
uniq -c, which counts the number of adjacent records with the same key.
Read log file
Split each line, get http ($7 token)
Alphabetically sort by URL
Counts of distinct URL
Sort by number in reverse
Output the first 5 lines
Downsides of MapReduce
• A MapReduce job can only start when all tasks in the preceding jobs (that generate its
inputs) have completed
• Mappers are often redundant: they just read back the same file that was just written
by a reducer and prepare it for the next stage of partitioning and sorting.
• Storing intermediate state in a distributed filesystem means those files are replicated
across several nodes, which is often overkill for such temporary data.
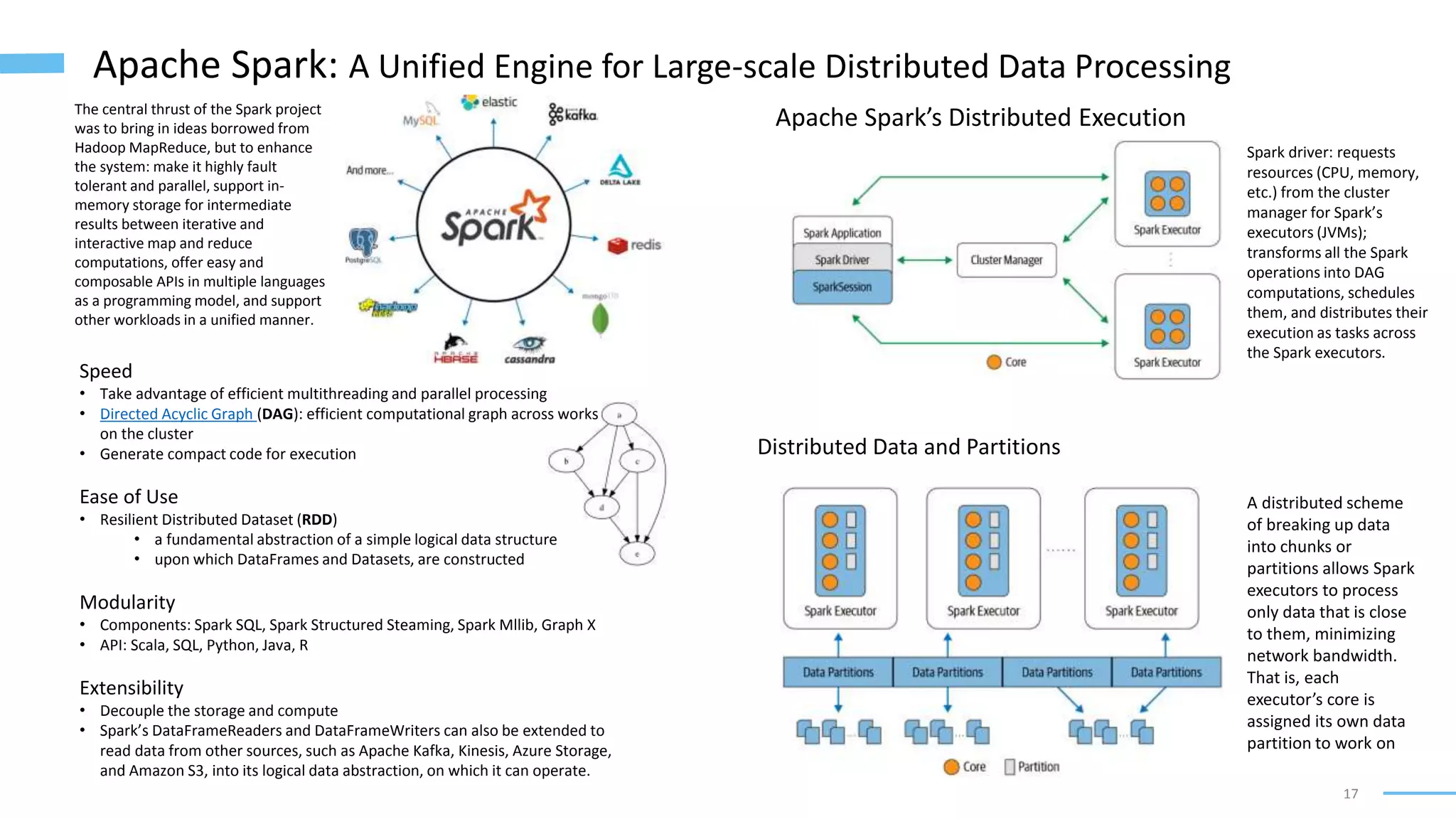
Solution: Dataflow Engines (such as Spark)
• Explicitly model the flow of data through several processing stages
• Parallelize work by partitioning inputs, and they copy the output of one function over
the network to become the input to another function
• All joins and data dependencies in a workflow are explicitly declared, the scheduler
has an overview of what data is required where, so it can make locality optimizations](https://image.slidesharecdn.com/softwarearchitecturefordataapplications-220212133506/75/Software-architecture-for-data-applications-13-2048.jpg)


![20
Apache Spark’s Structured APIs
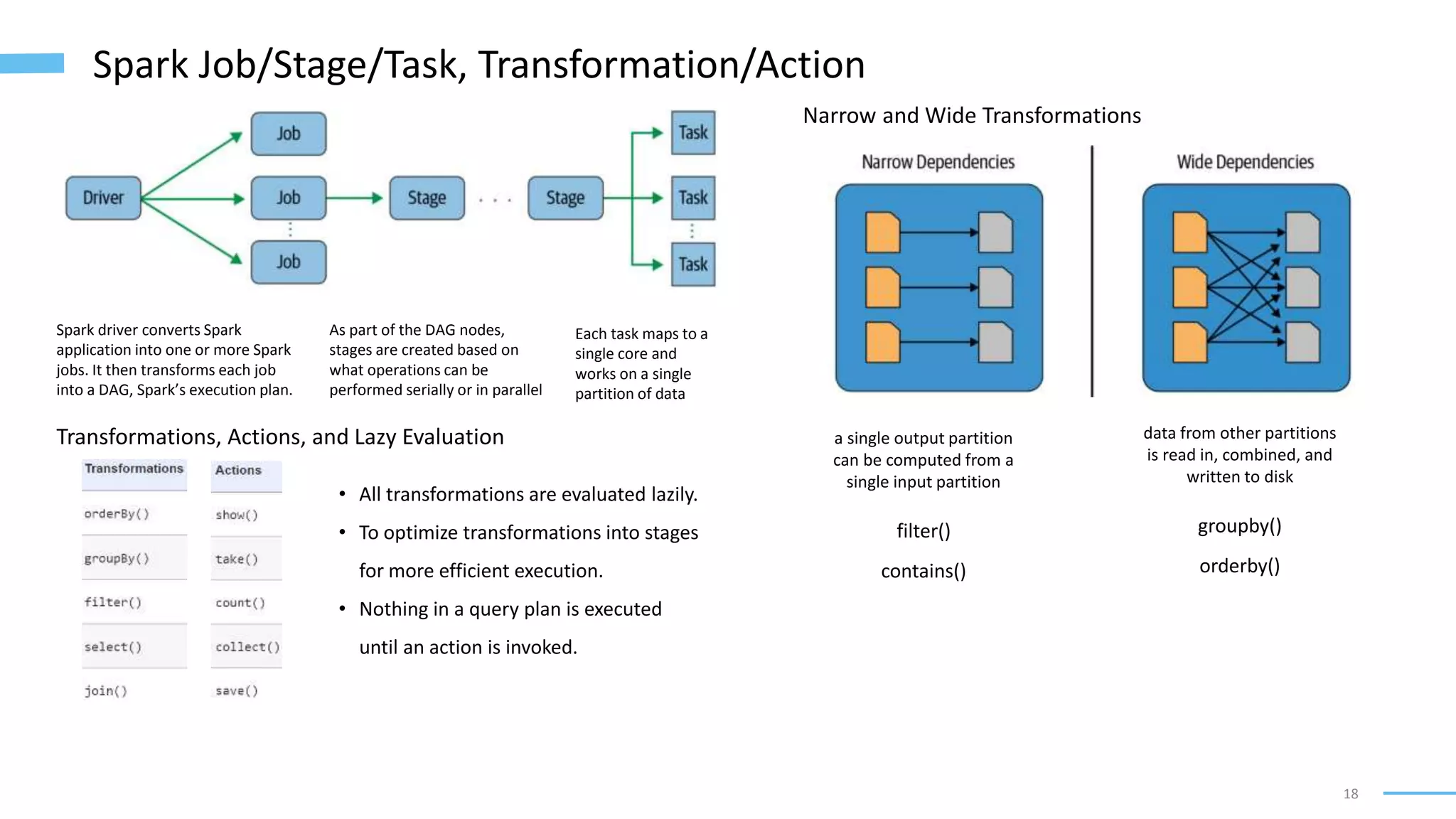
The RDD is the most basic abstraction in Spark
• Dependencies
instructs Spark how an RDD is constructed with its inputs
• Partitions (with some locality information)
ability to parallelize computation on partitions across executors
• Compute function: Partition => Iterator[T]
produces an Iterator[T] for the data that will be stored in the RDD
Basic Python data types in Spark
Python structured data types in Spark
Schemas and Creating DataFrames
A schema defines the column names and associated data types for a DataFrame.
schema = "author STRING, title STRING, pages INT“
blogs_df = spark.createDataFrame(data, schema)](https://image.slidesharecdn.com/softwarearchitecturefordataapplications-220212133506/75/Software-architecture-for-data-applications-20-2048.jpg)




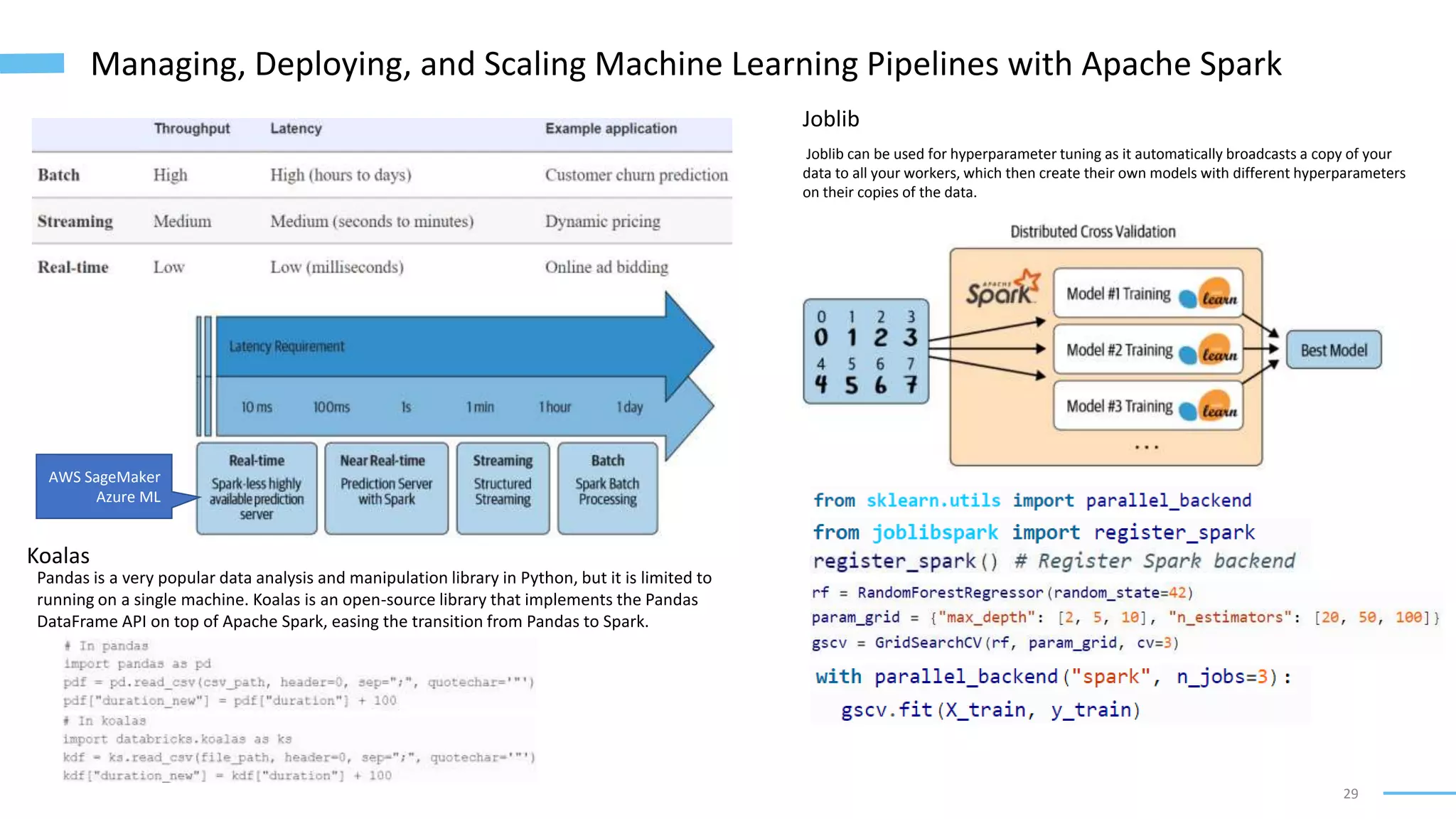


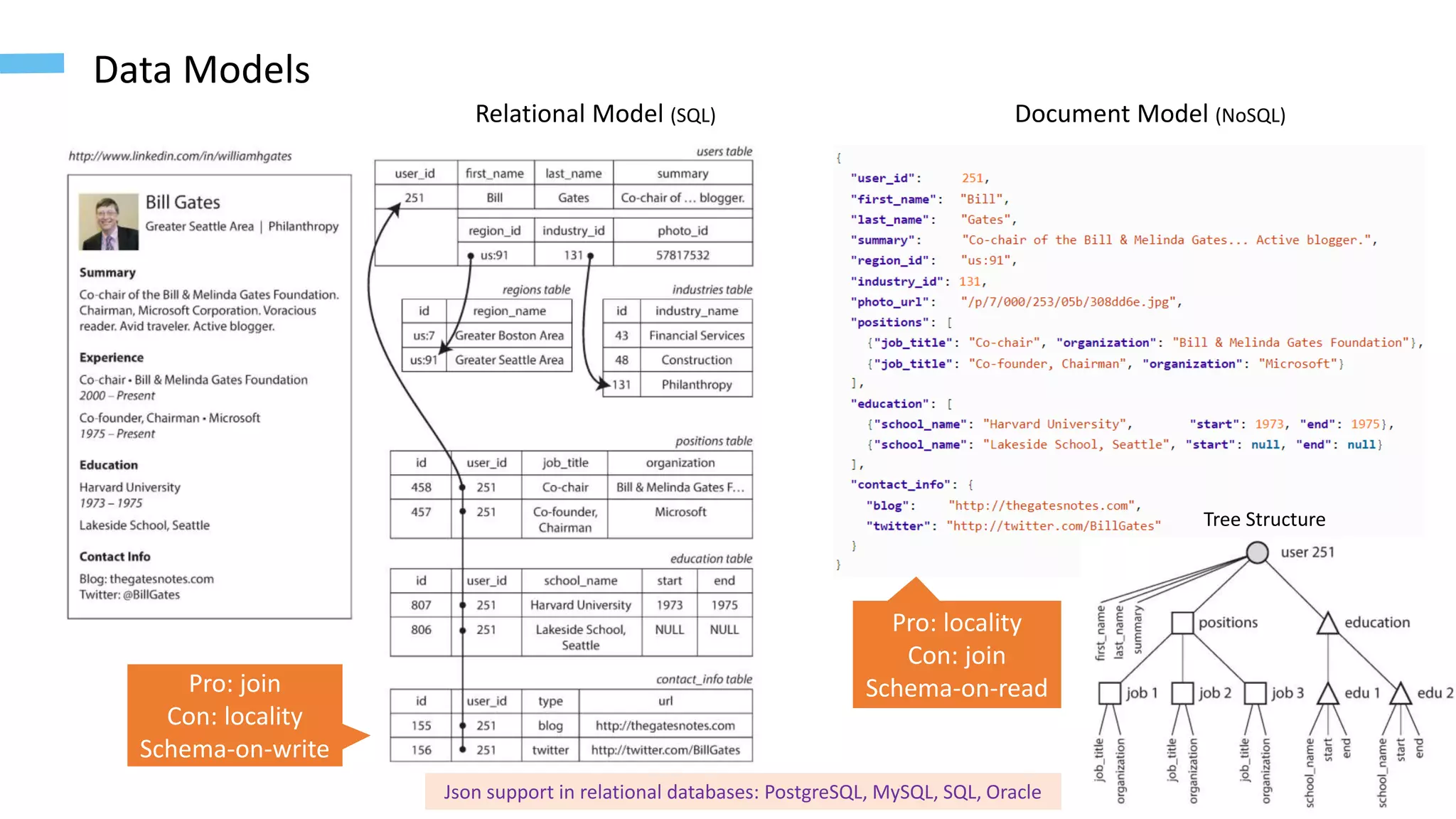
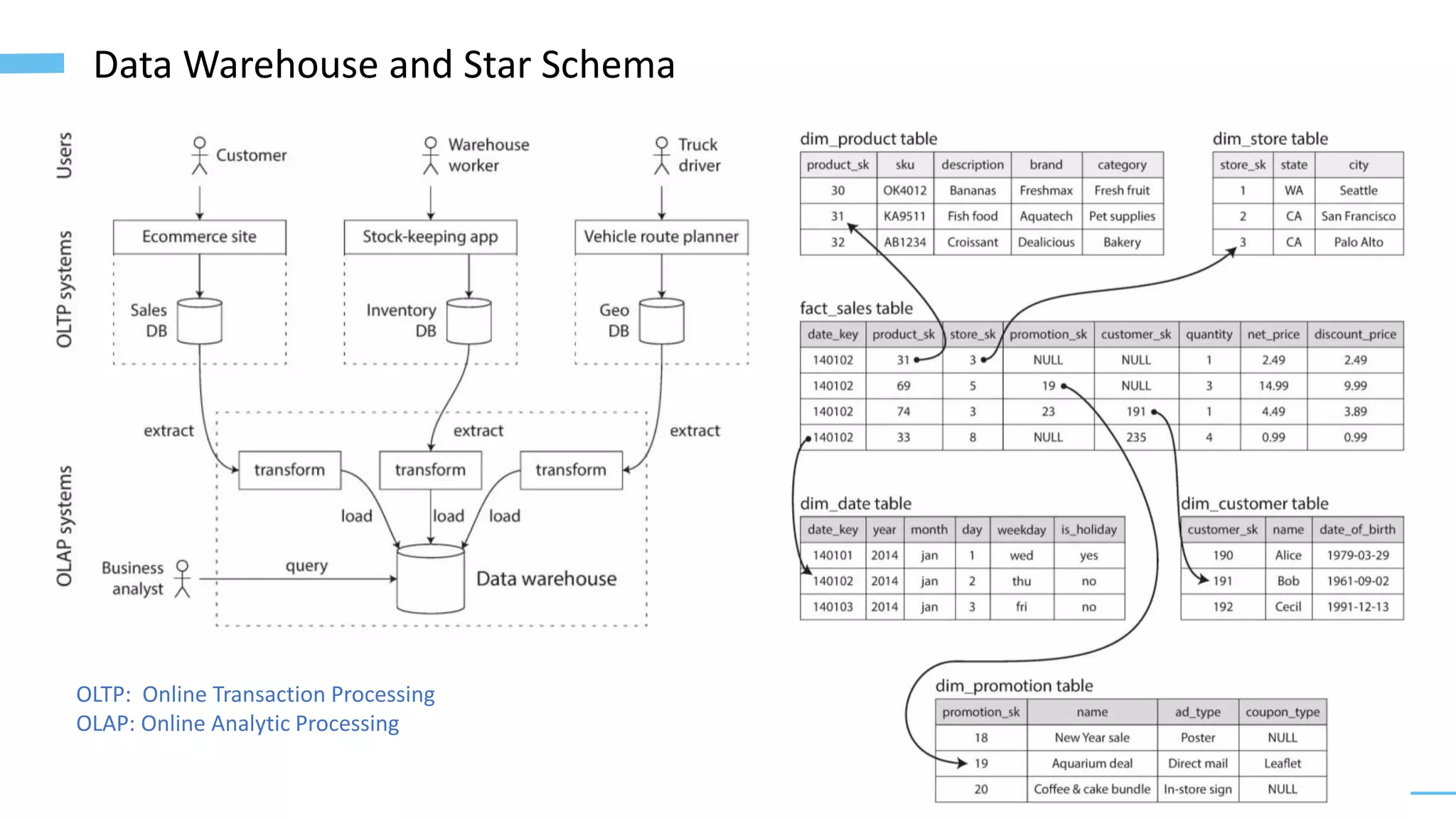
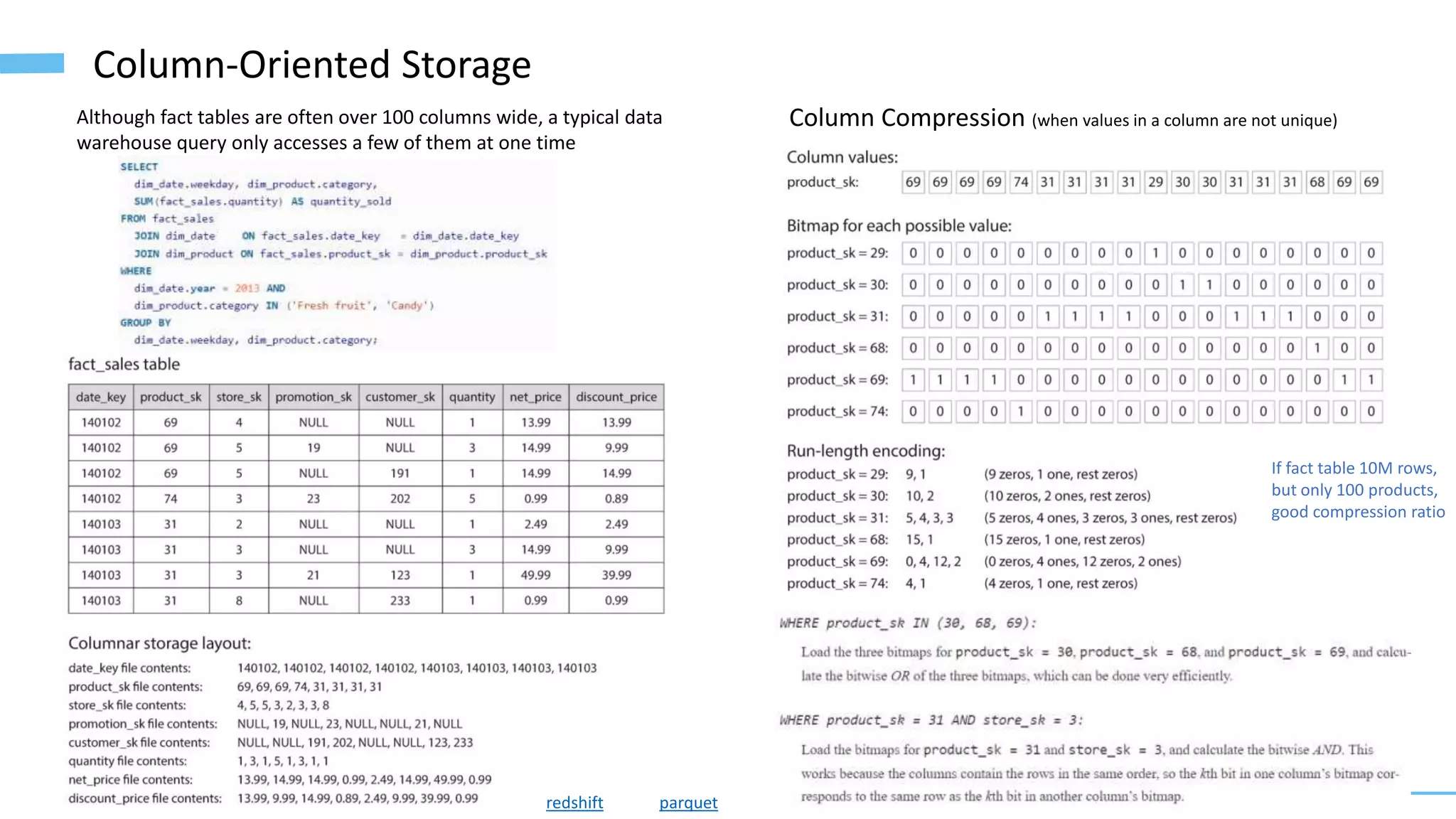
The document provides an overview of software architecture considerations for data applications. It discusses sample data system components like Memcached, Redis, Elasticsearch, and Solr. It covers topics such as service level objectives, data models, query languages, graph models, data warehousing, machine learning pipelines, and distributed systems. Specific frameworks and technologies mentioned include Spark, Kafka, Neo4j, PostgreSQL, and ZooKeeper. The document aims to help understand architectural tradeoffs and guide the design of scalable, performant, and robust data systems.

































































![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Petrovic - Is it really that expensive to build an AI sy...](https://cdn.slidesharecdn.com/ss_thumbnails/ybqhdwvusbg7jms3doxh-9-251216105605-7aab5a10-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marko Djordjevic - AI can help Agriculture.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/c0huq0ztiubmgccem2hc-marko-djordjevic-ai-can-help-agriculture-251218125253-7606f036-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jean Del Rosario - How to Reduce GenAI Costs up to 73.45%.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zjehcwqsiwjisav1znml-5-251217093201-eae4440a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

