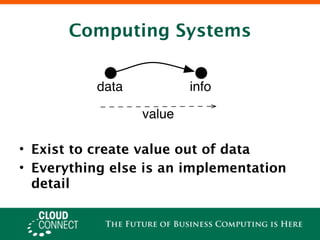
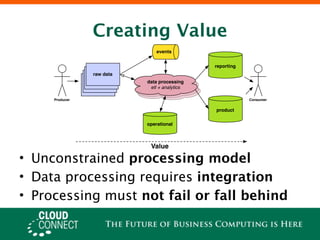
Offline processing with Hadoop allows for scalable, simplified batch processing of large datasets across distributed systems. It enables increased innovation by supporting complex analytics over large data sets without strict schemas. Hadoop adoption is moving beyond legacy roles to focus on data processing and value creation through scalable and customizable systems like Cascading.




![Data Warehousing != Data
ETL
Processing
process streams
hub and spoke [distributed]
[monolithic]
• Data Warehousing
– monolithic systems and data schema
– distribution through manual federation/
sharding
• Data Processing
– cluster of peer systems
– dynamic even distribution of data and
processing](https://image.slidesharecdn.com/processingbigdata-cwensel-100319150804-phpapp01/85/Processing-Big-Data-6-320.jpg)
![Data Warehousing
data
raw data ETL warehouse ETL reporting
loggers [BI, KPI, etc]
loggers [cache]
loggers
ETL
ETL
data
mining
product Consumer
R, SAS, some data
Excel, etc
Analyst
• Agility, no “one size fits all” schema,
resistant to change
• Complex Analytics, cannot be represented
by SQL
• Massive Data Sets, won’t fit or too](https://image.slidesharecdn.com/processingbigdata-cwensel-100319150804-phpapp01/85/Processing-Big-Data-7-320.jpg)







![Hadoop MapReduce
Count Job Sort Job
[ k, [v] ] [ k, [v] ]
Map Reduce Map Reduce
[ k, v ] [ k, v ] [ k, v ] [ k, v ]
File File File
[ k, v ] = key and value pair
[ k, [v] ] = key and associated values collection
• Nearly impossible to “think in”
• Apps are many dependent MR jobs](https://image.slidesharecdn.com/processingbigdata-cwensel-100319150804-phpapp01/85/Processing-Big-Data-16-320.jpg)
![Cascading
Word Count/Sort Flow
Map Reduce Map Reduce
[ f1,f2,.. ] [ f1,f2,.. ] [ f1,f2,.. ]
Parse Group Count Sort
[ f1,f2,.. ]
[ f1,f2,.. ]
Data [ f1, f2,... ] = tuples with field names Data
• Alternative model & API to MapReduce
– pipe/filters of re-usable operations
• For rapidly implementing Data Processing
Systems
• Open-Source](https://image.slidesharecdn.com/processingbigdata-cwensel-100319150804-phpapp01/85/Processing-Big-Data-17-320.jpg)















































































