



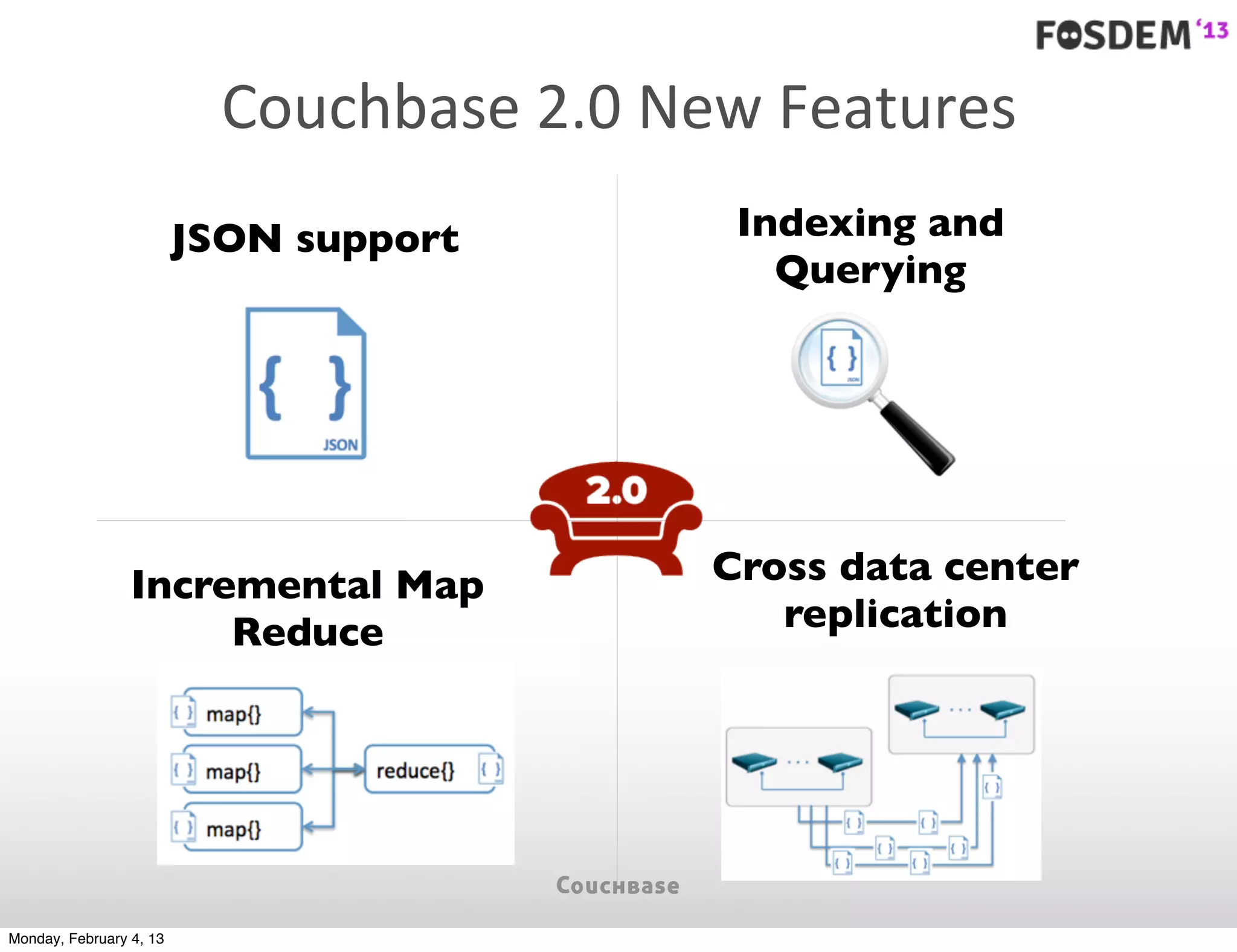

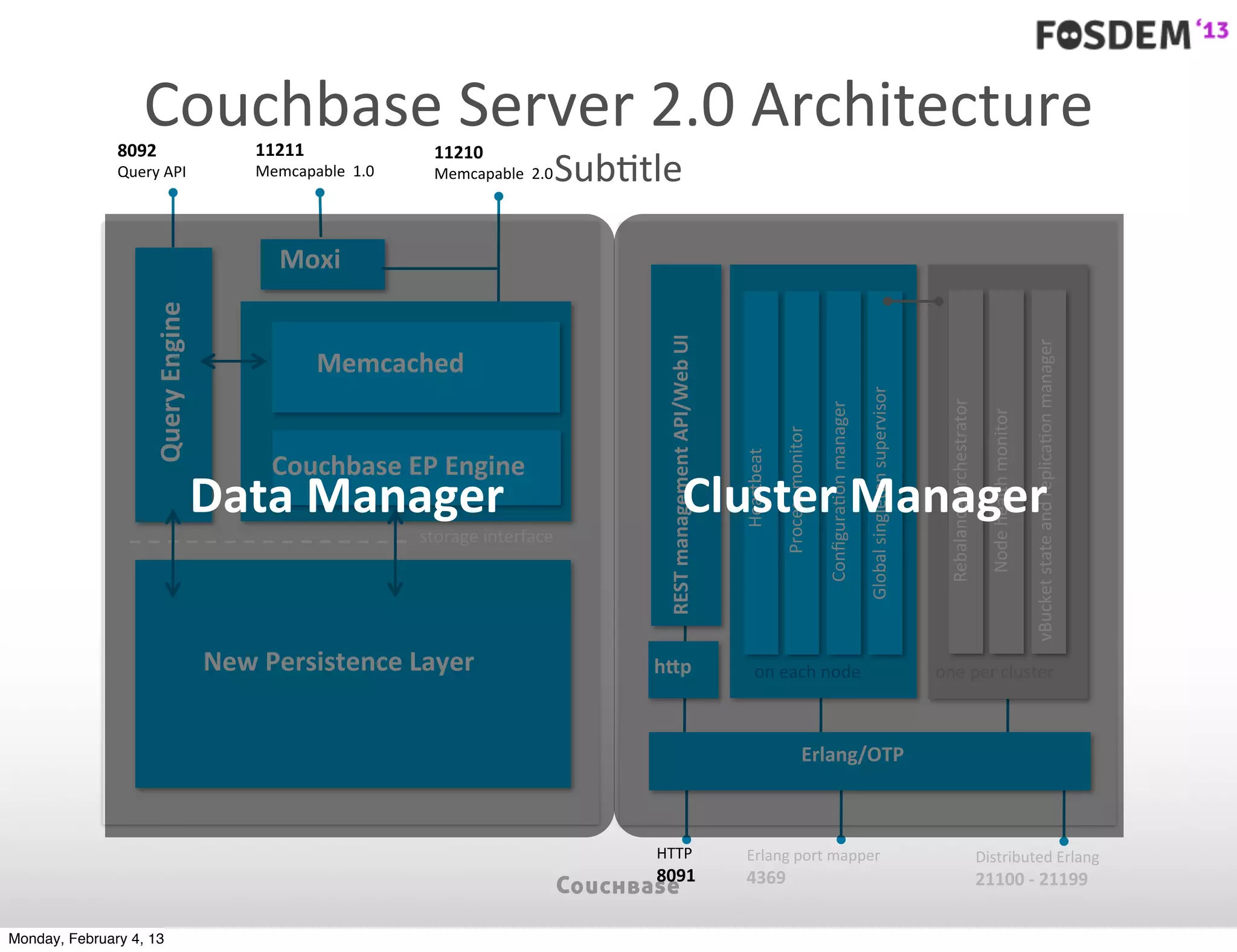
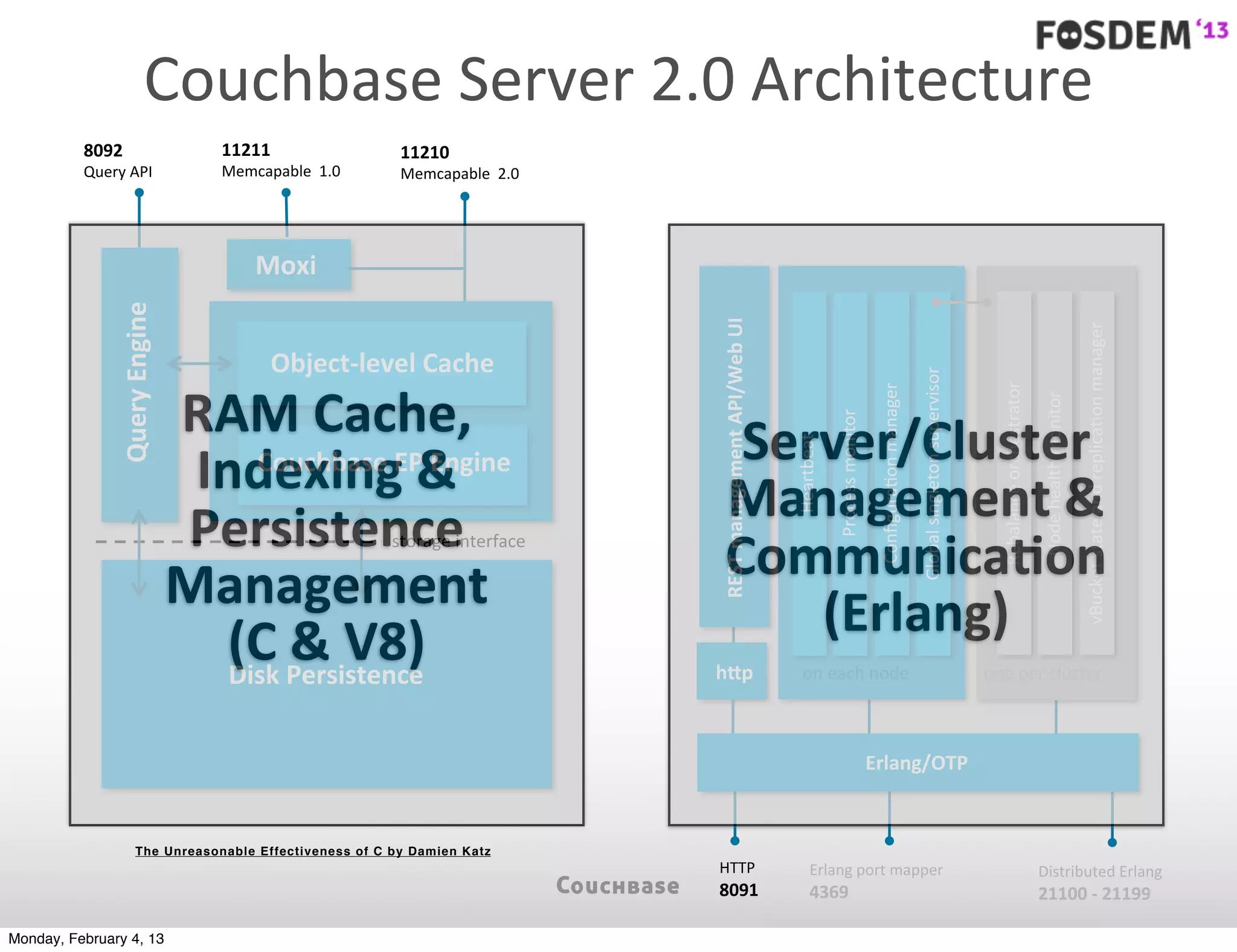






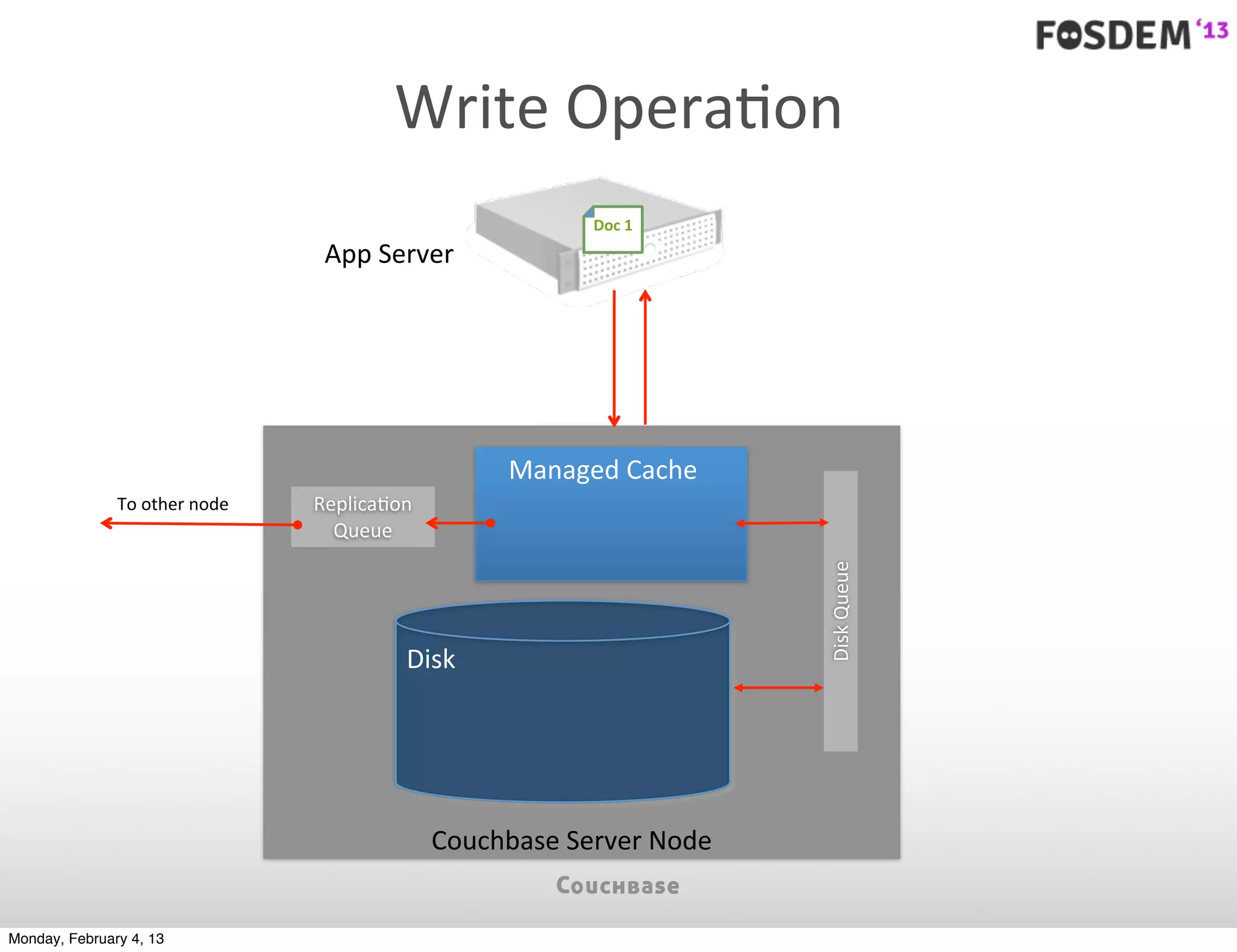
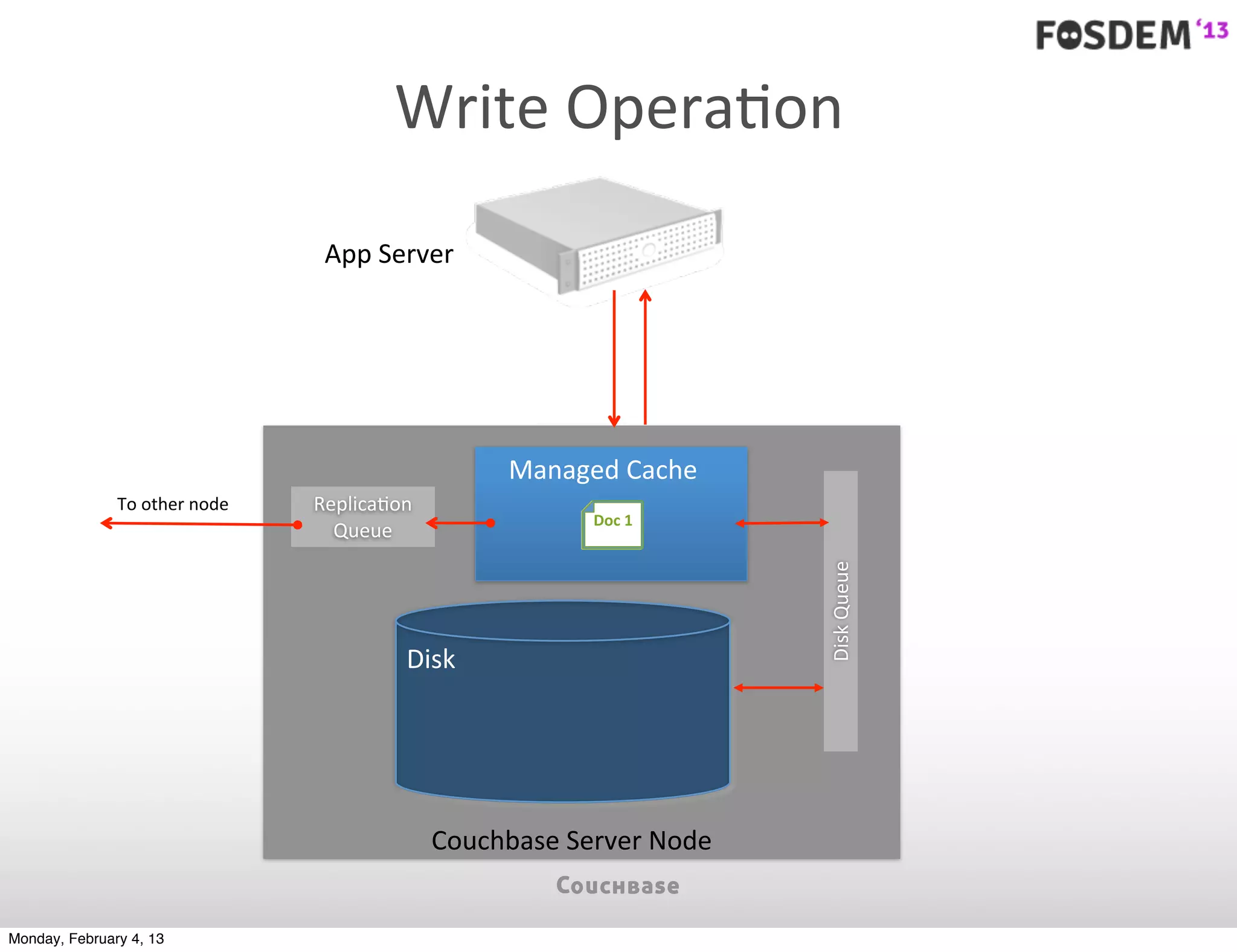
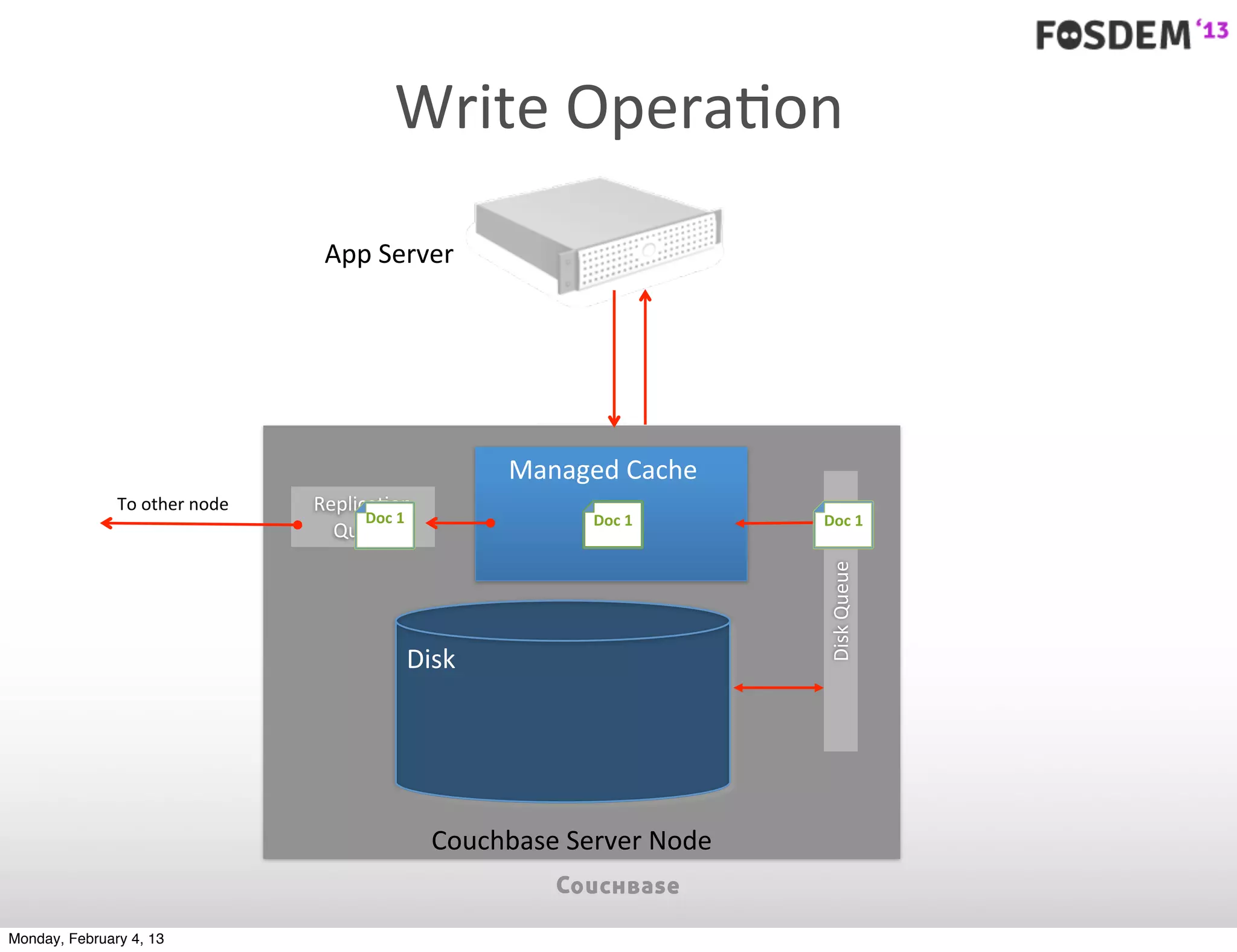
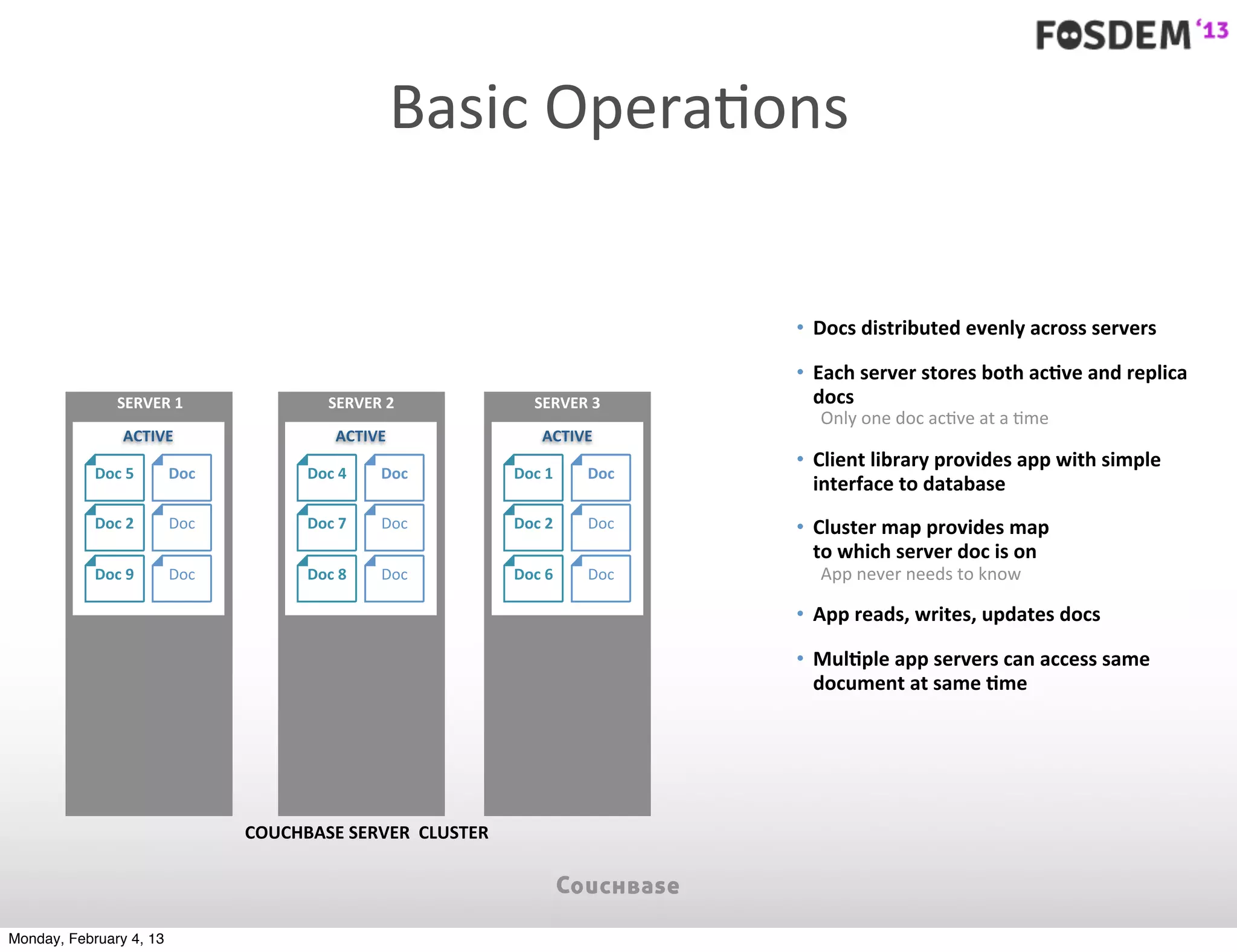
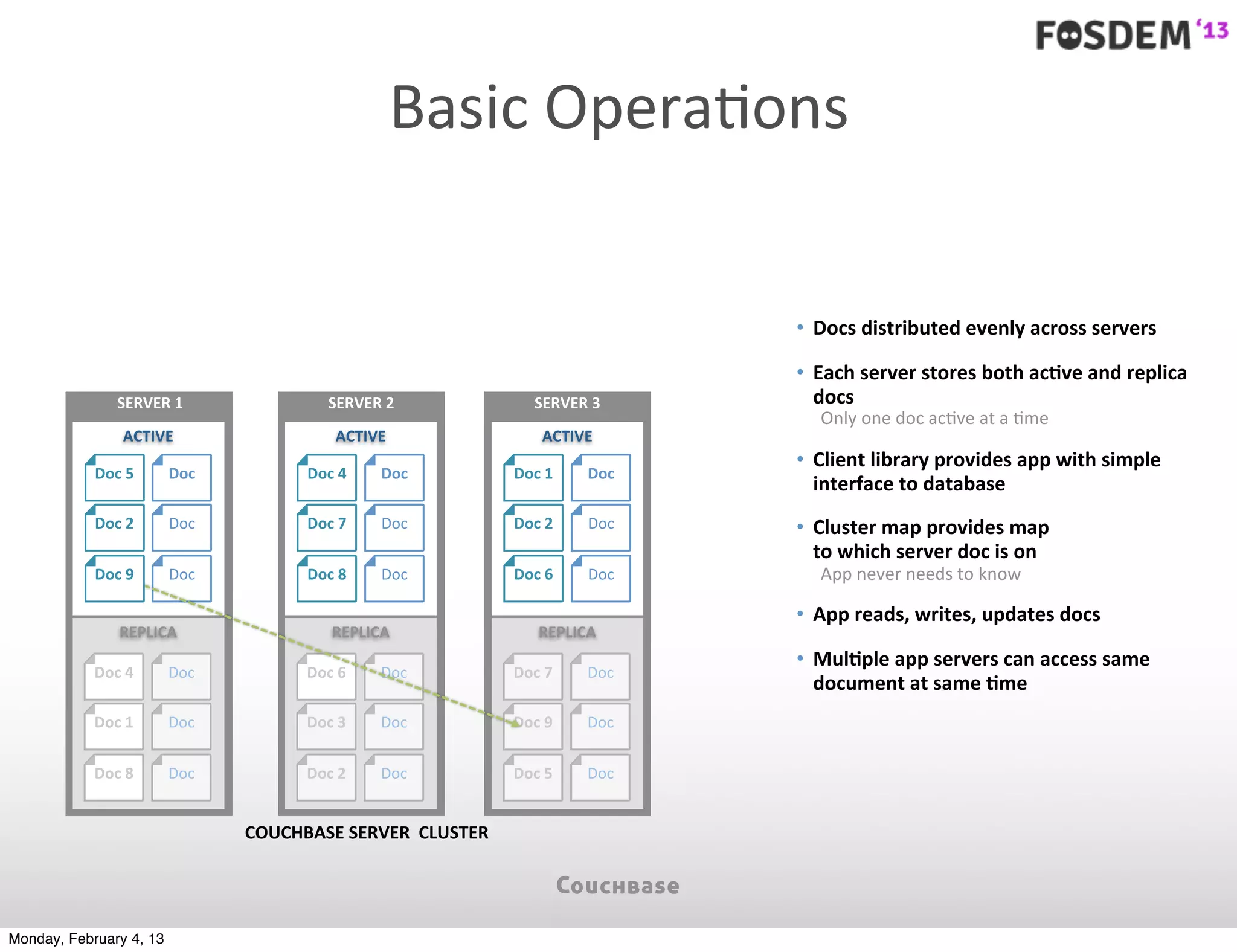
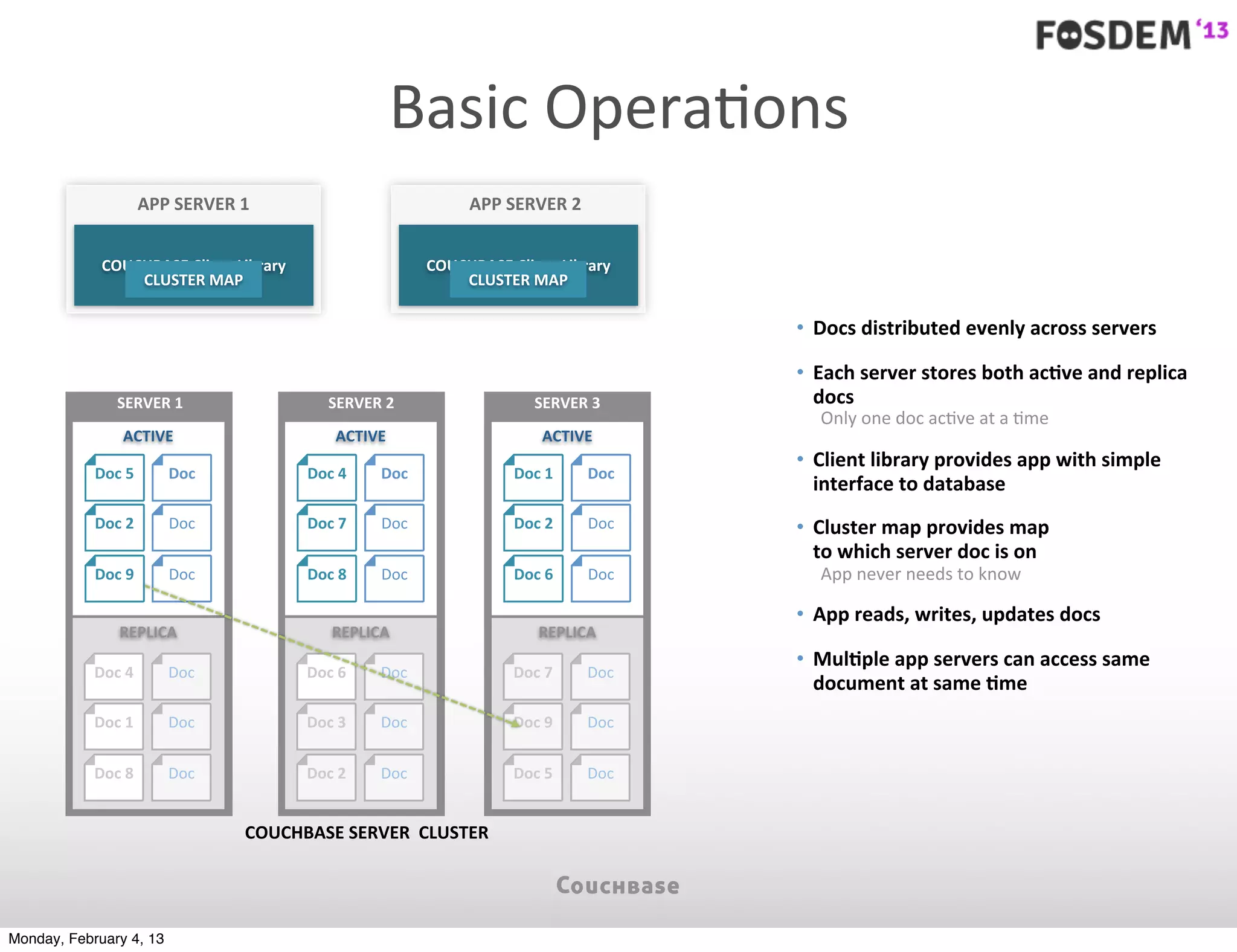
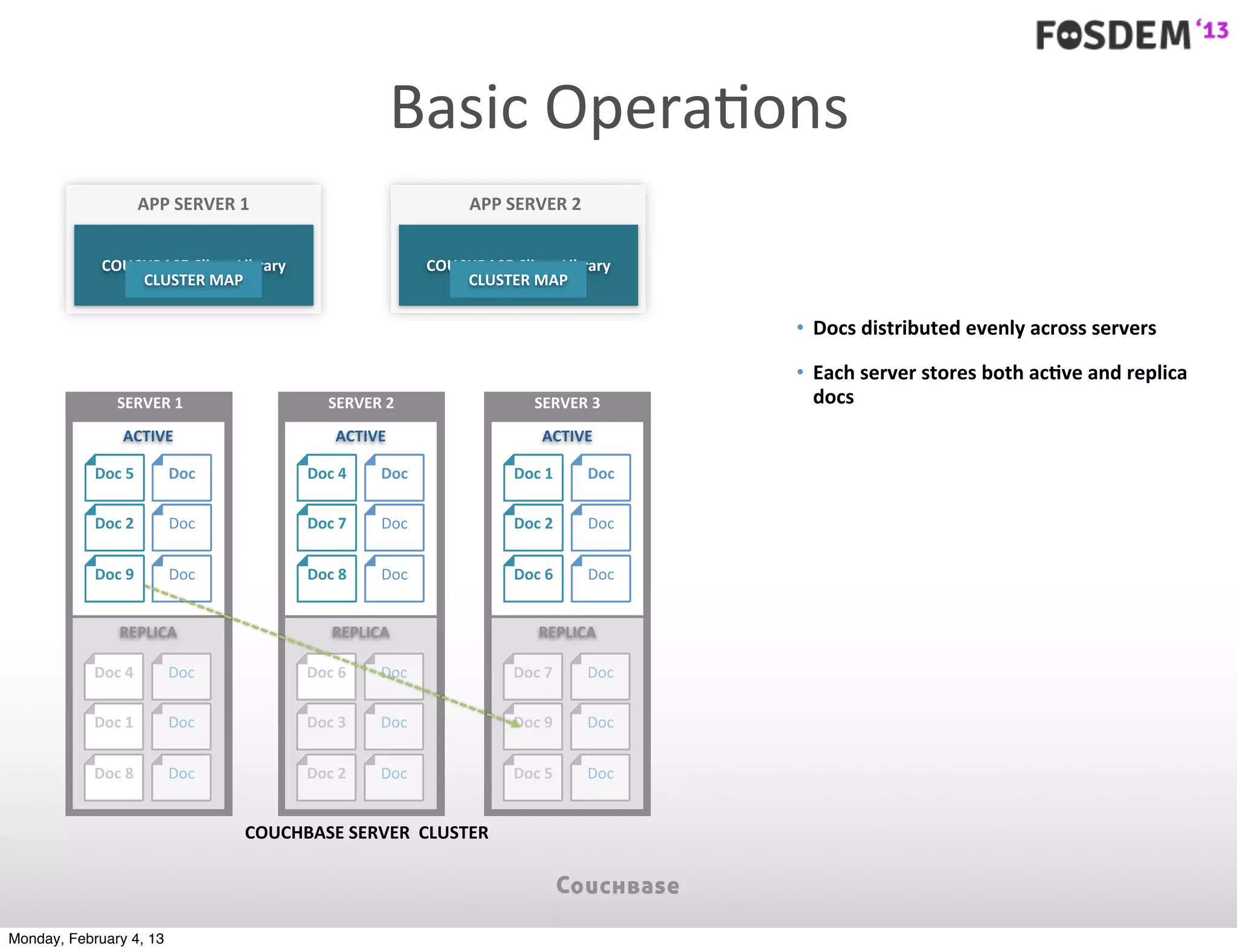
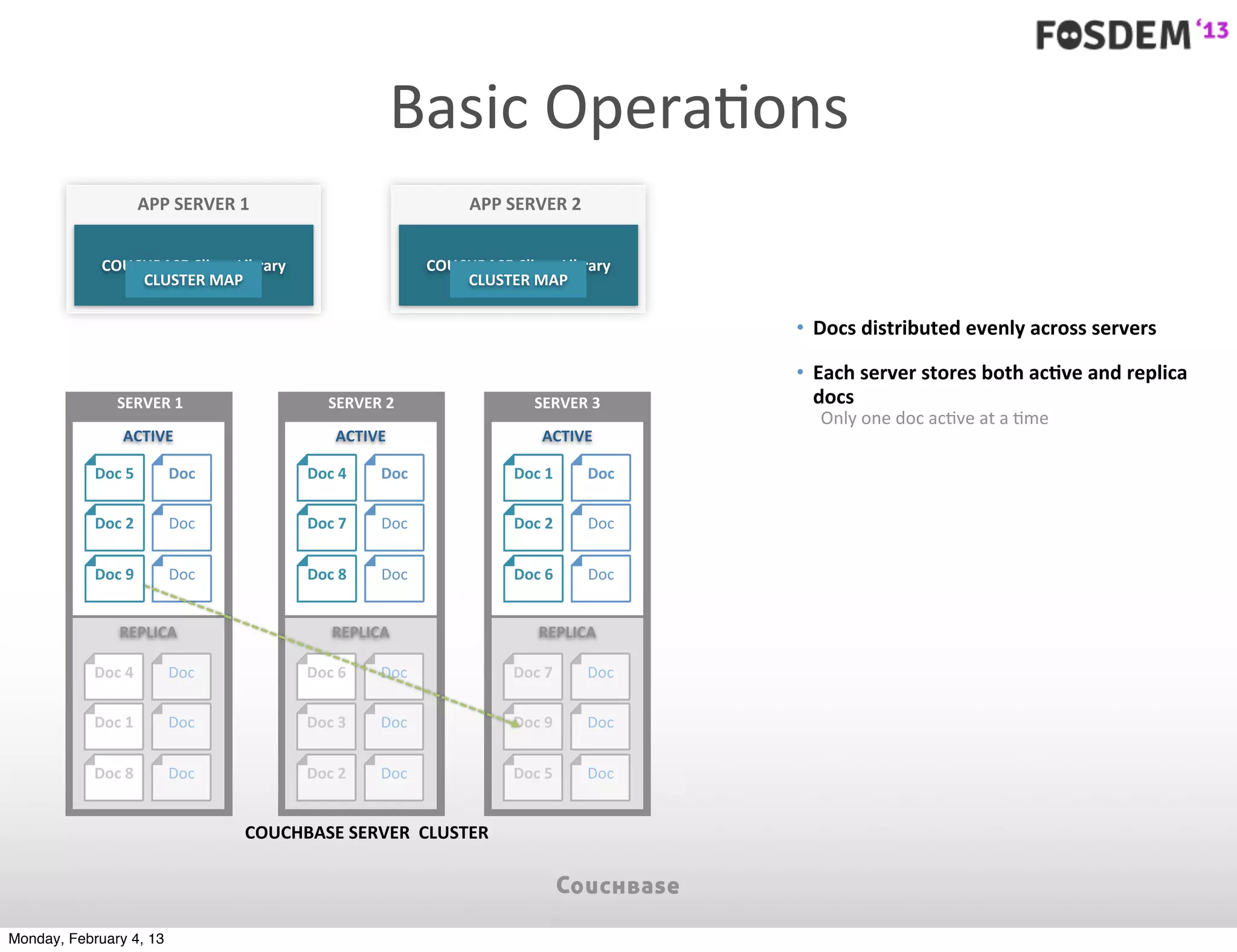
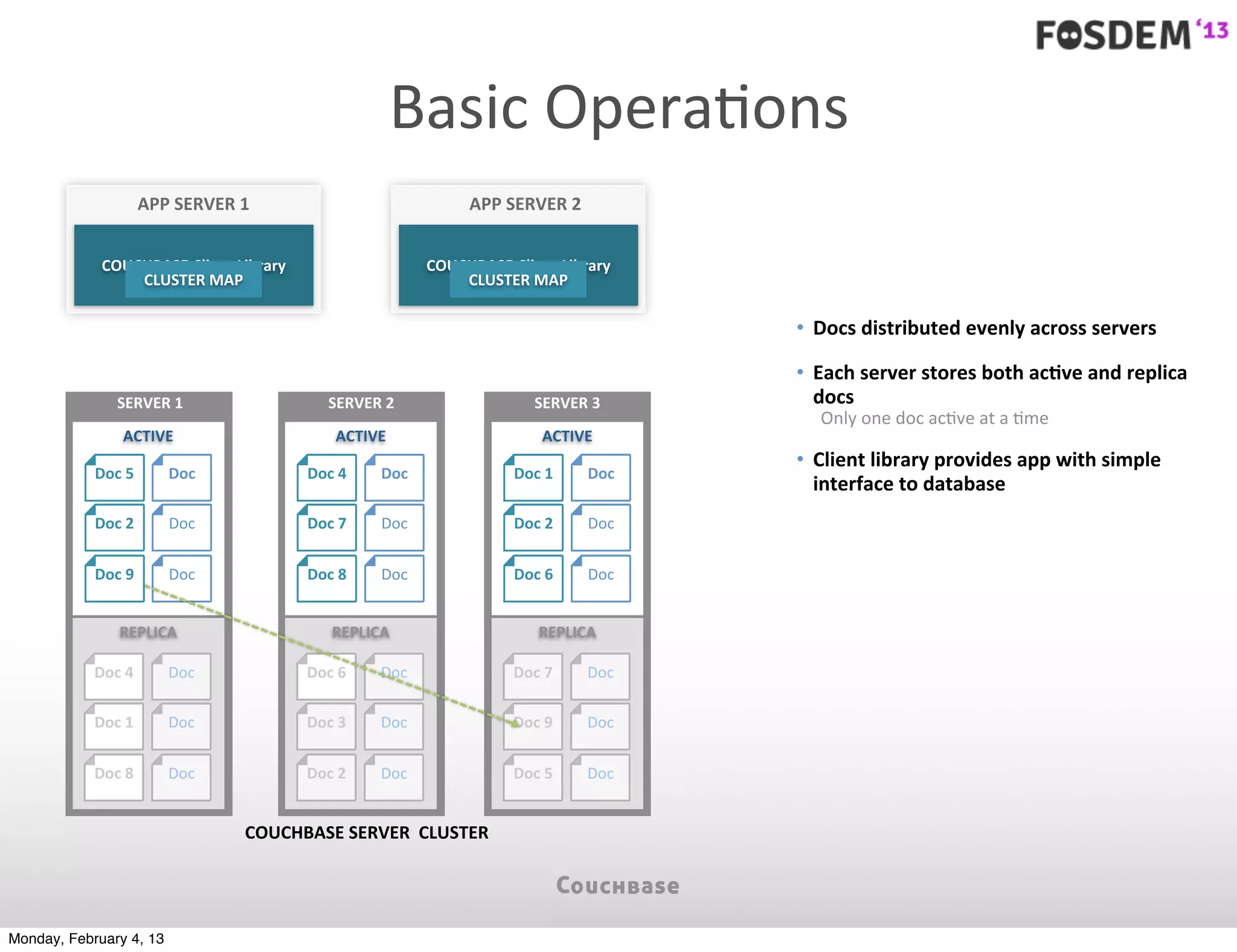
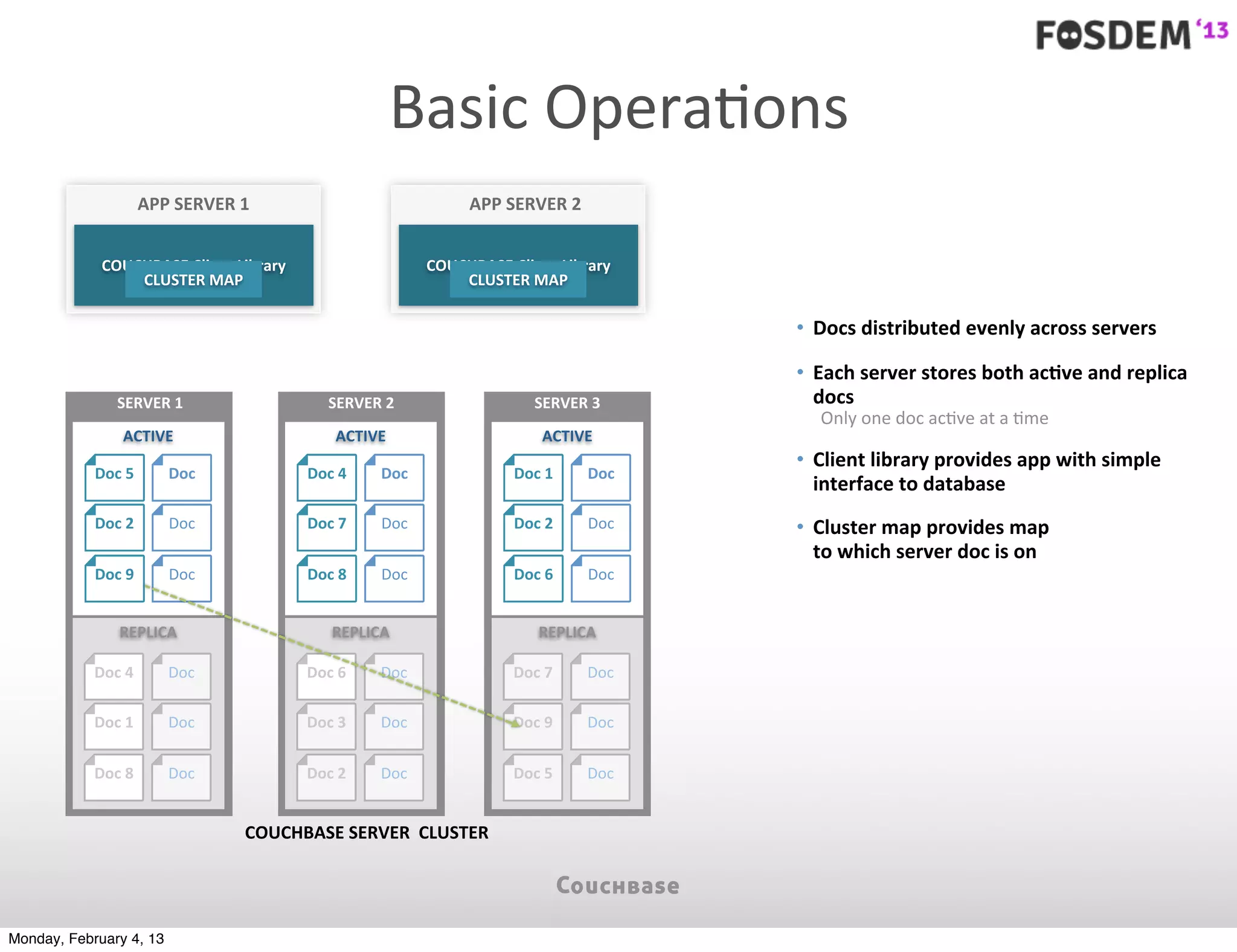
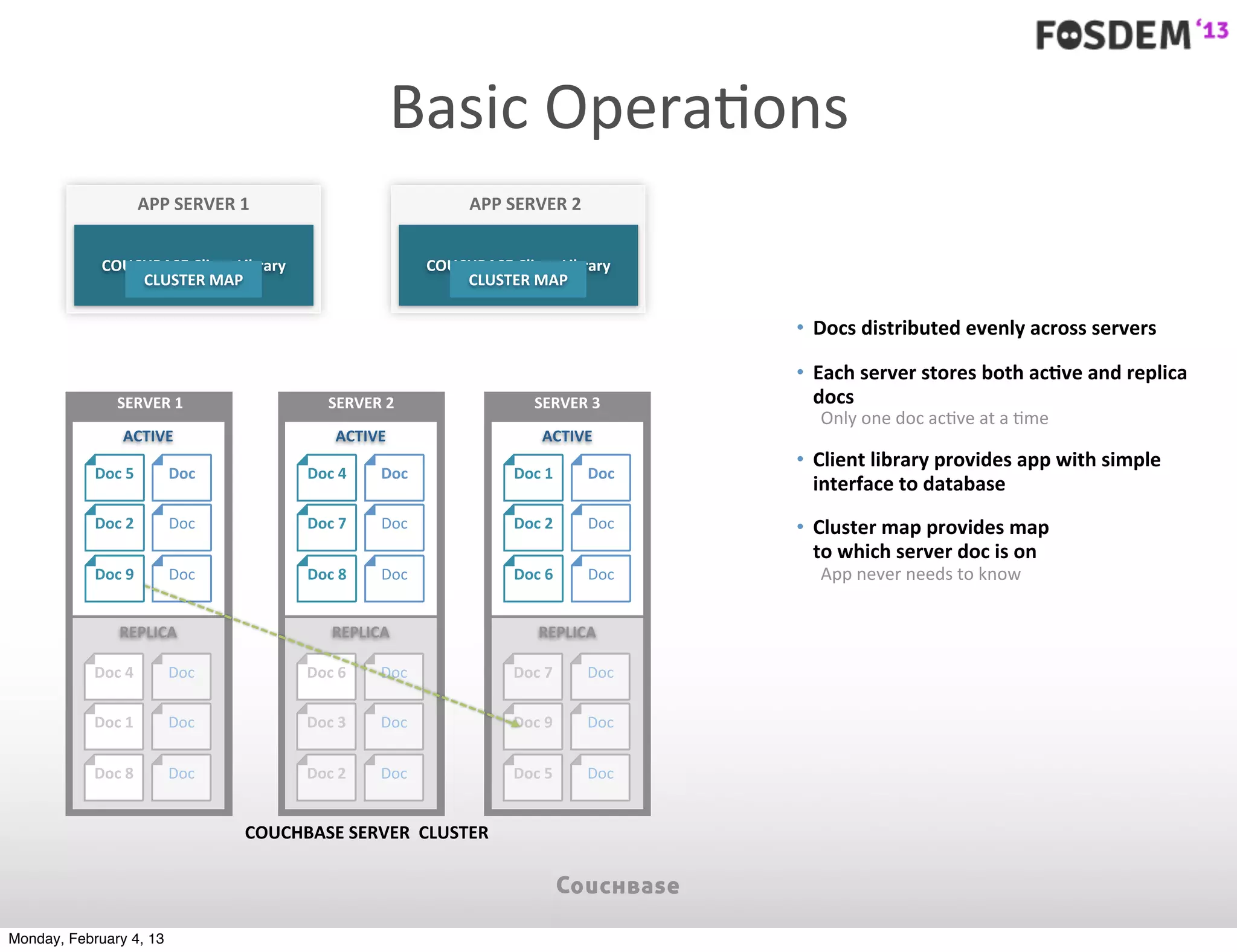
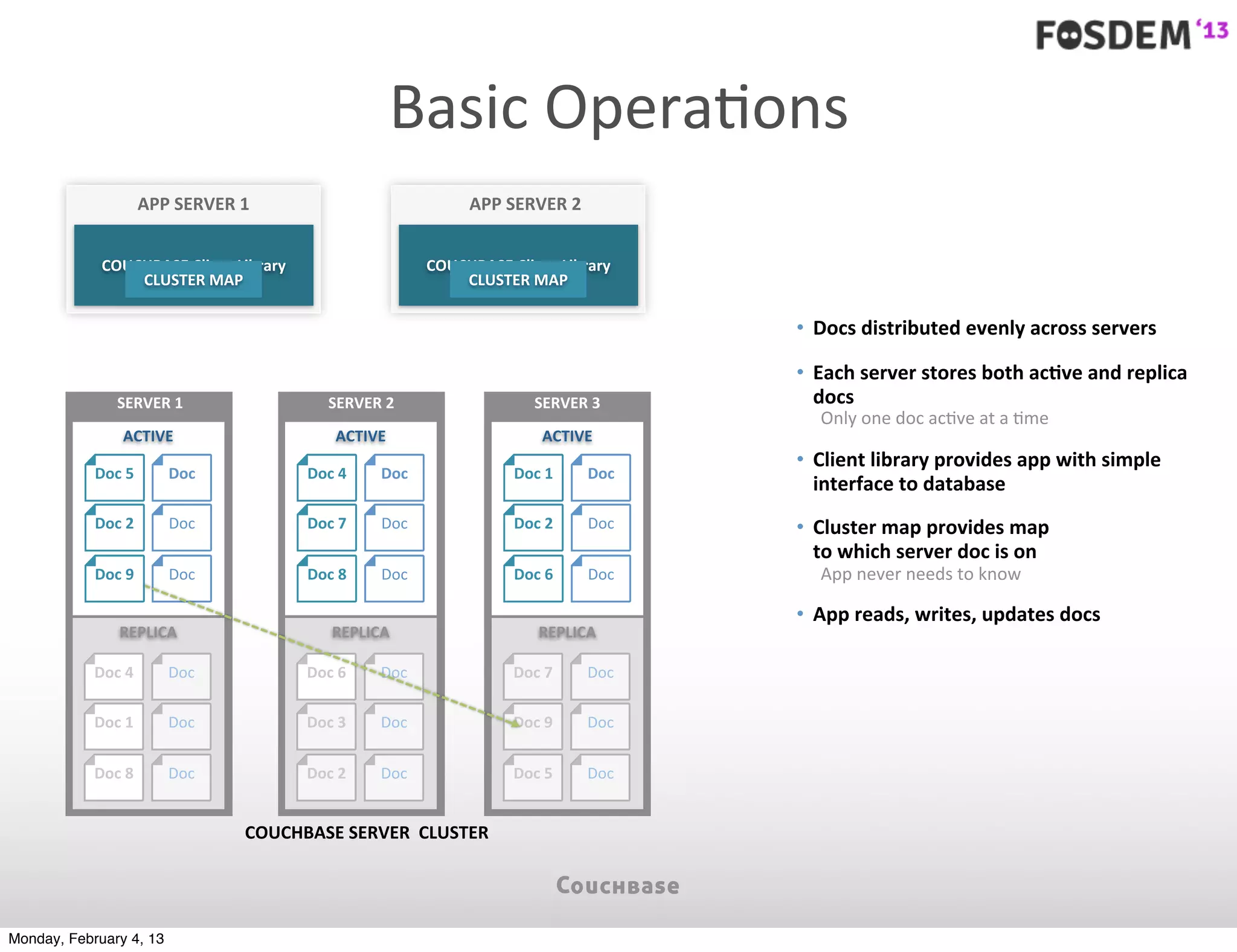
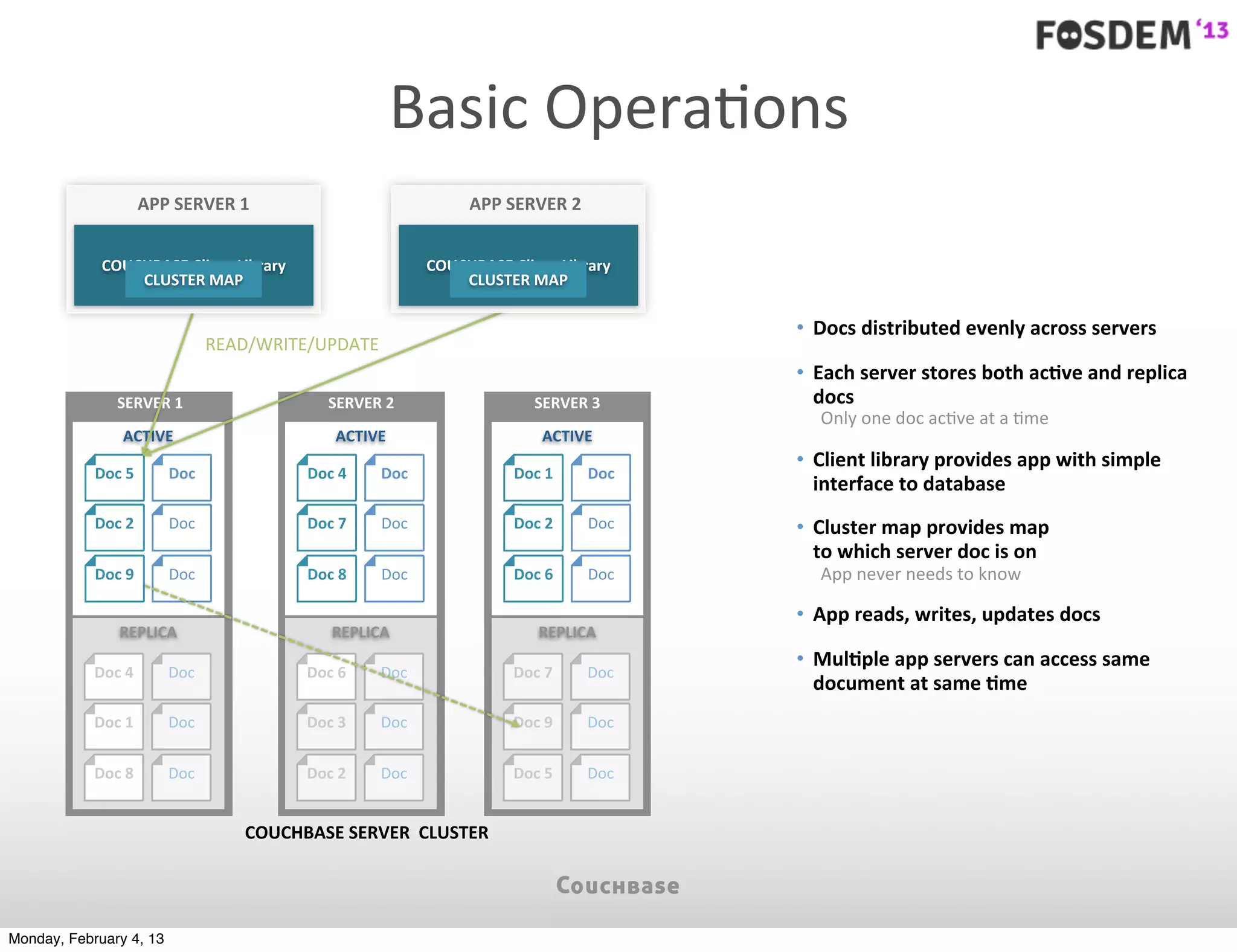

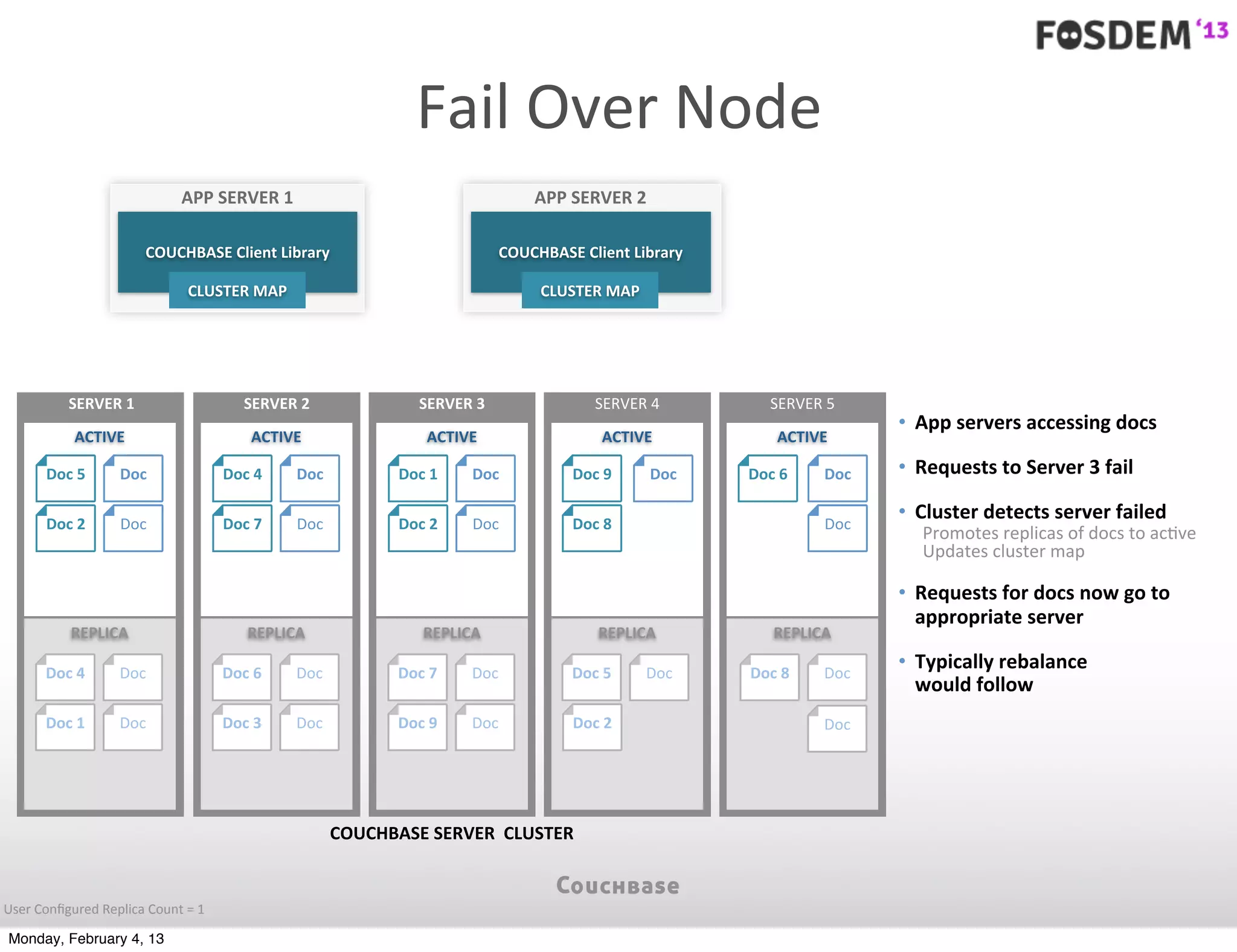
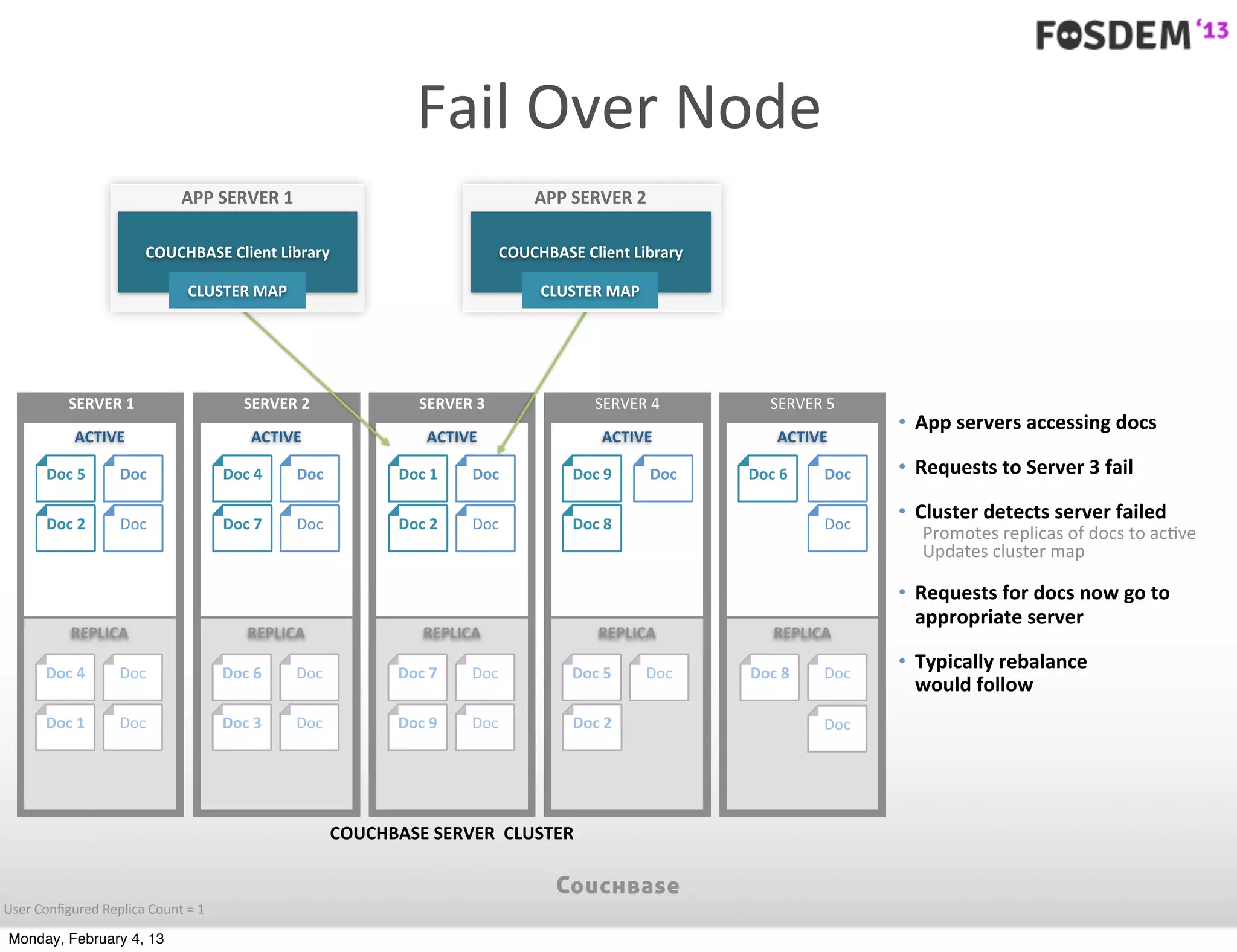
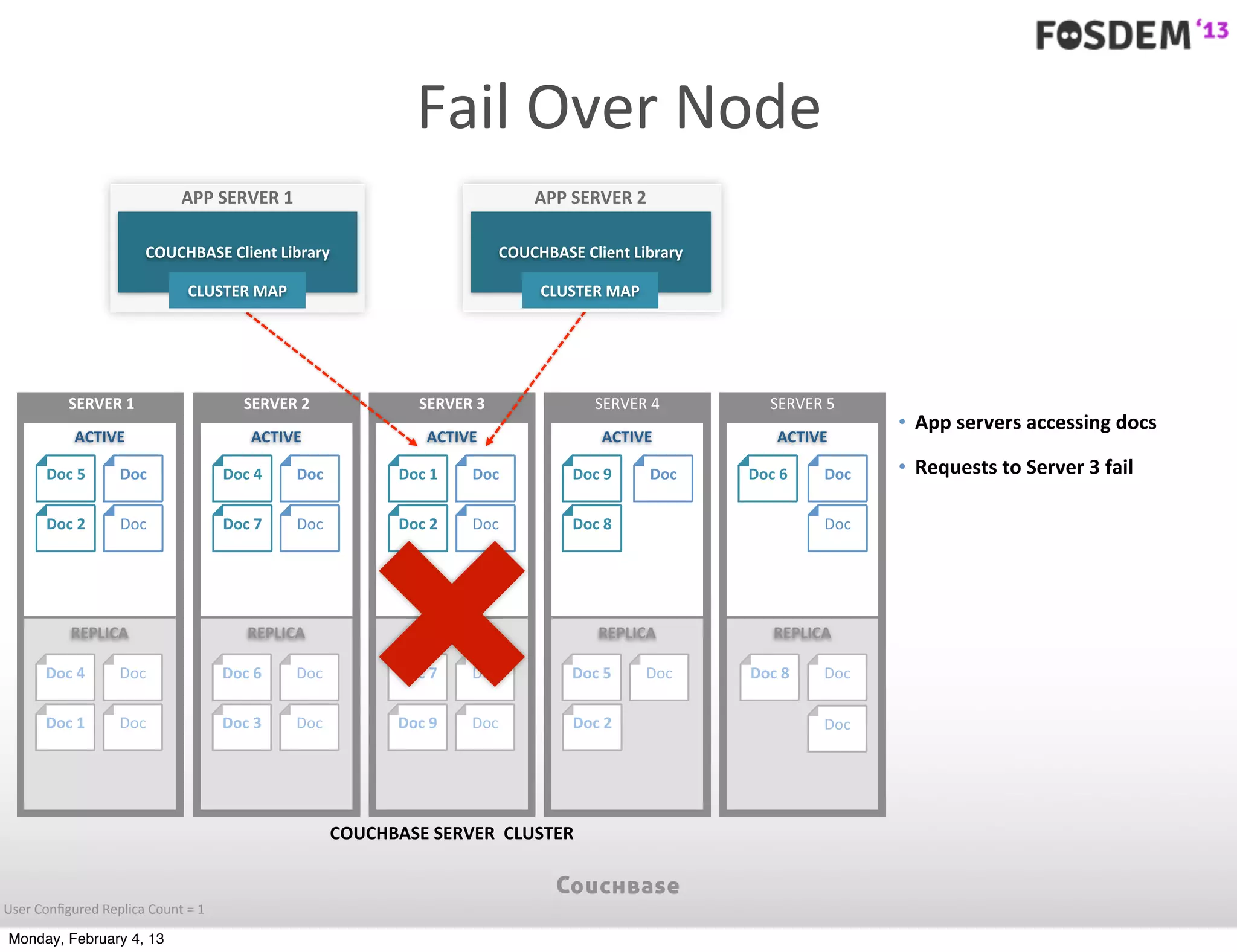
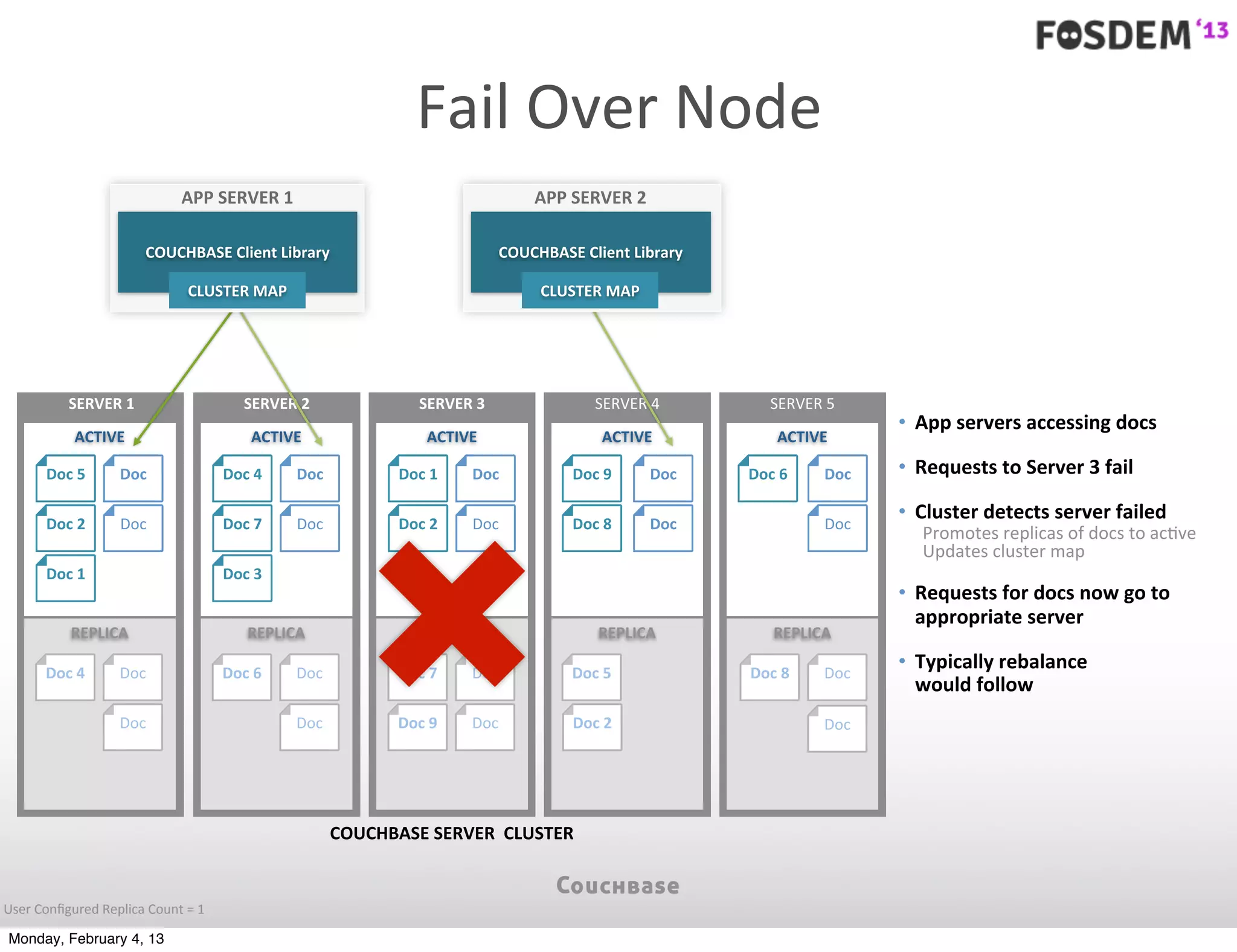
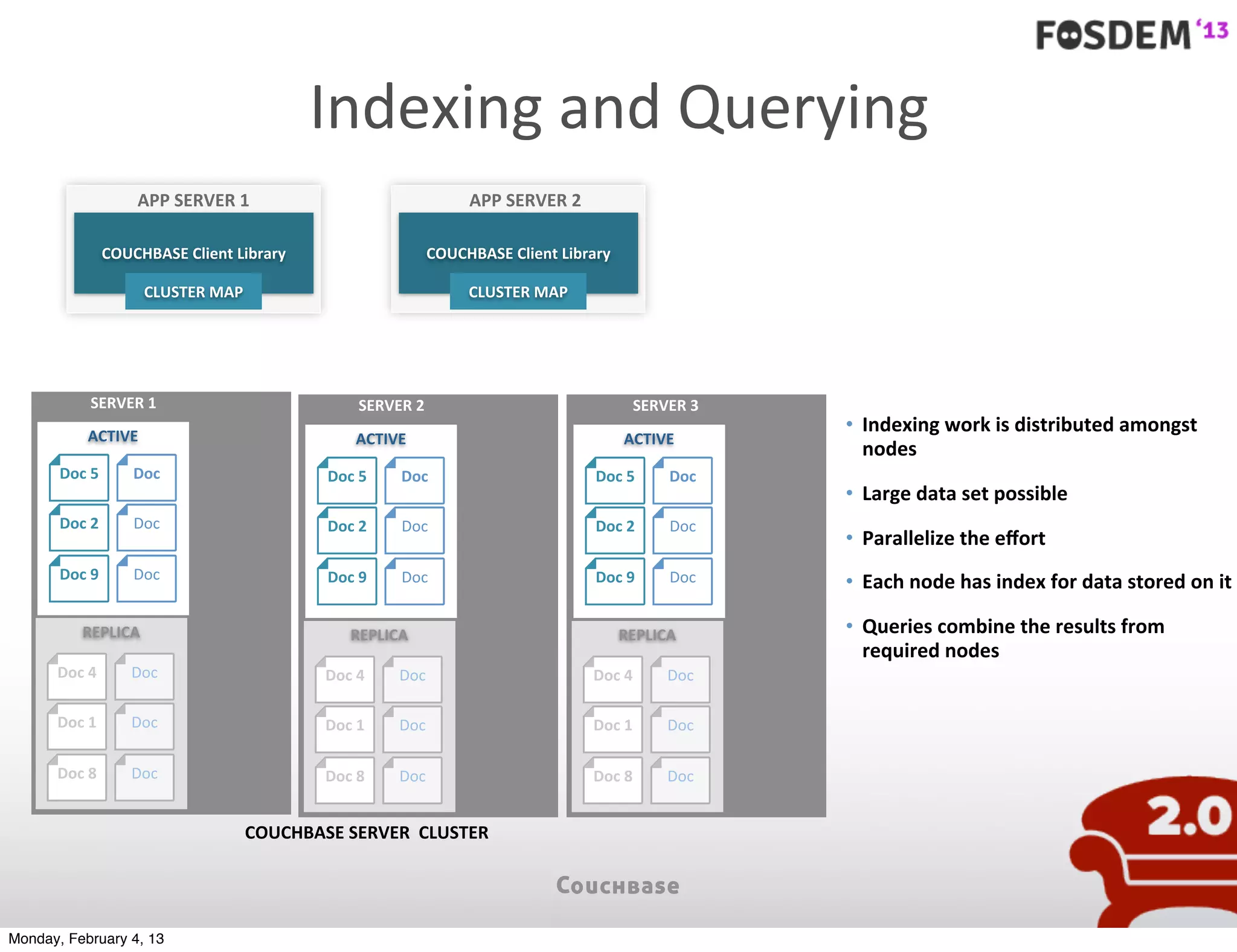
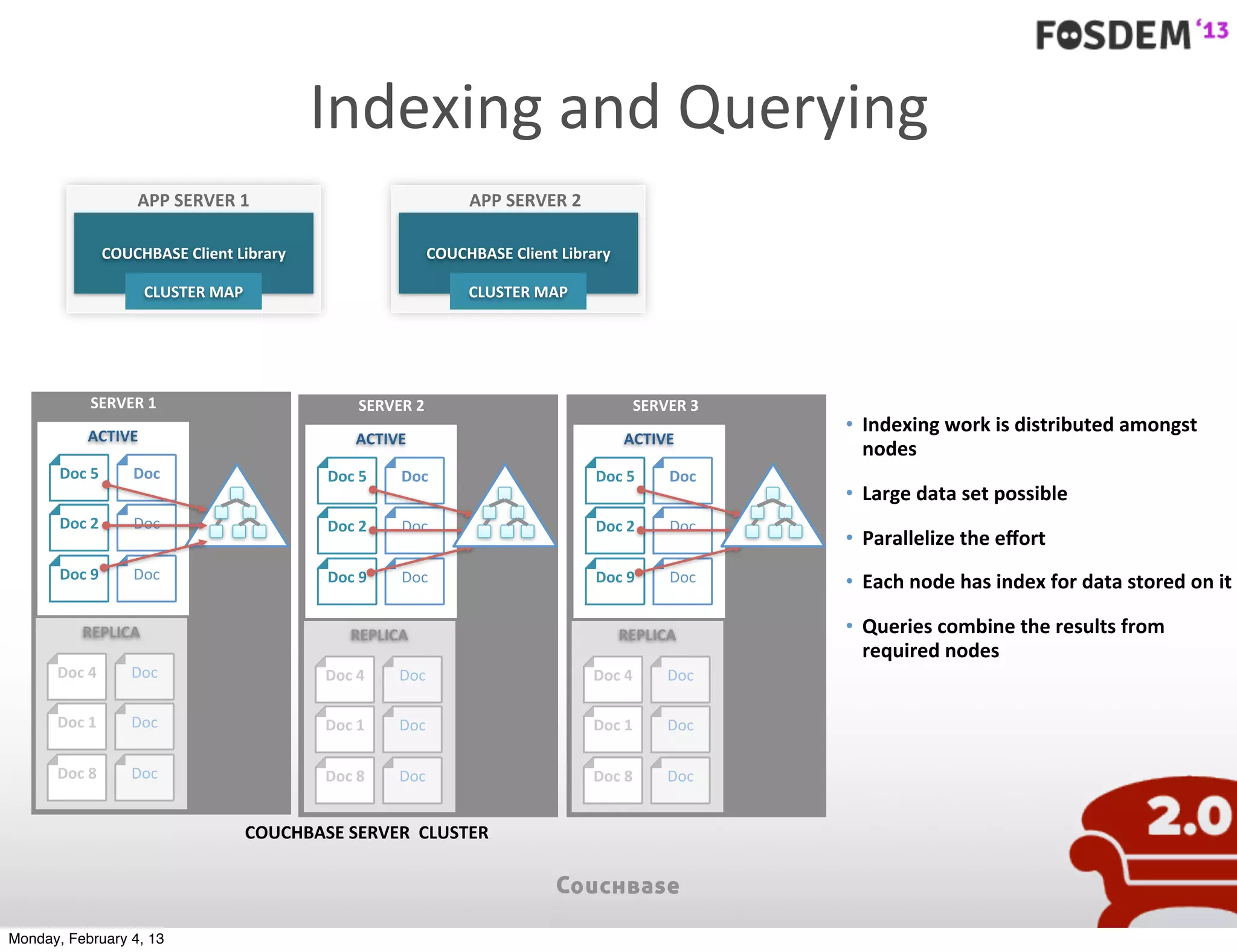
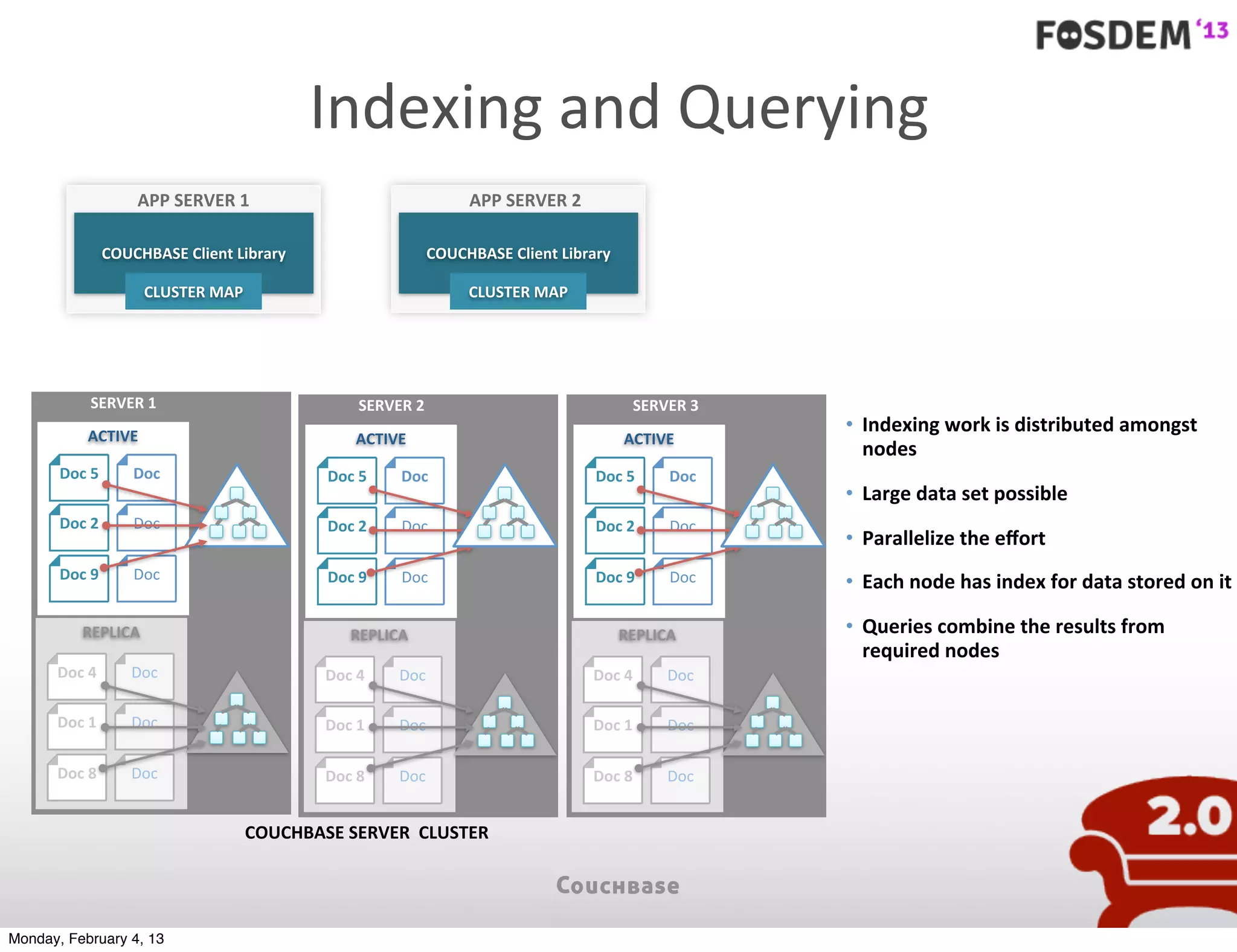
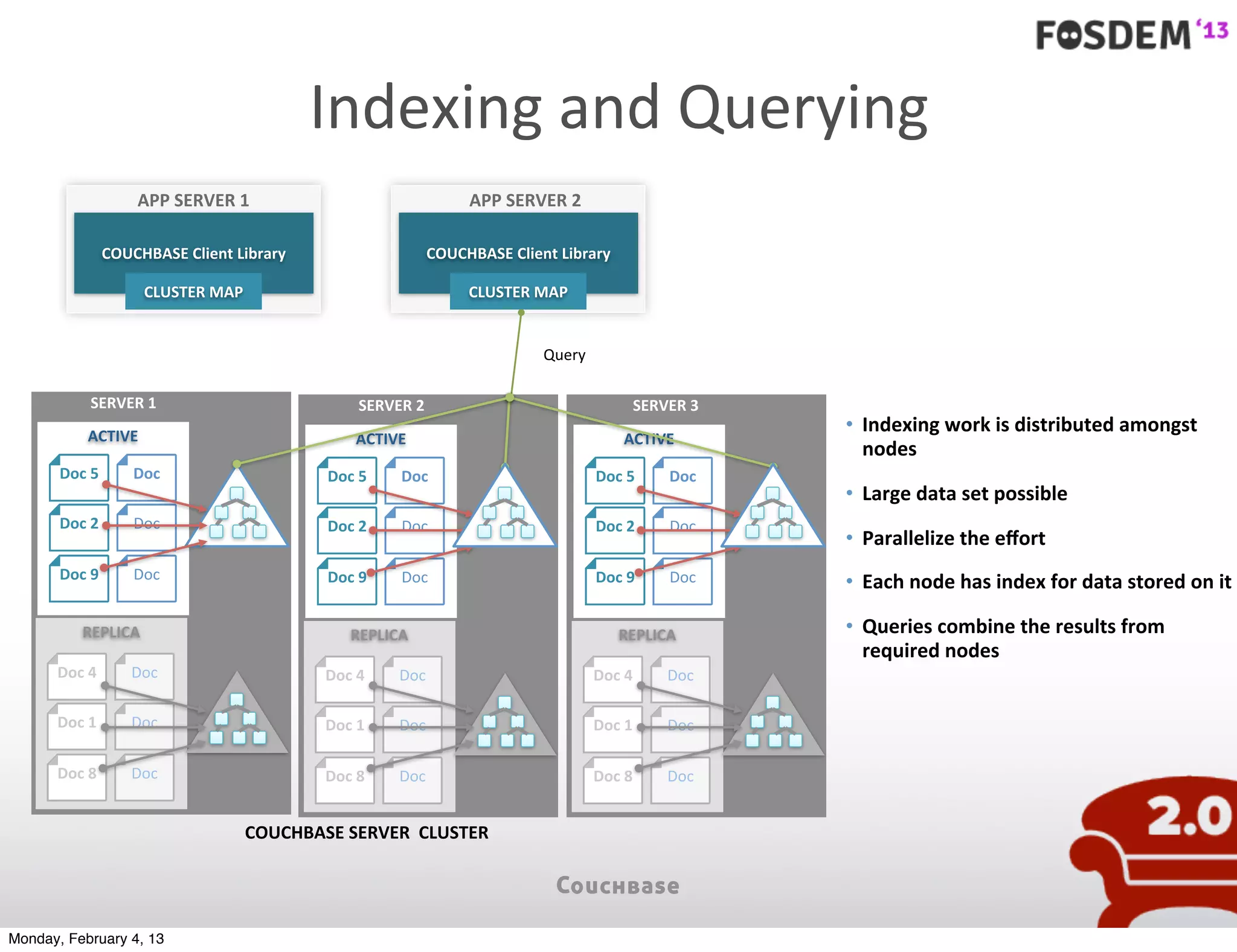
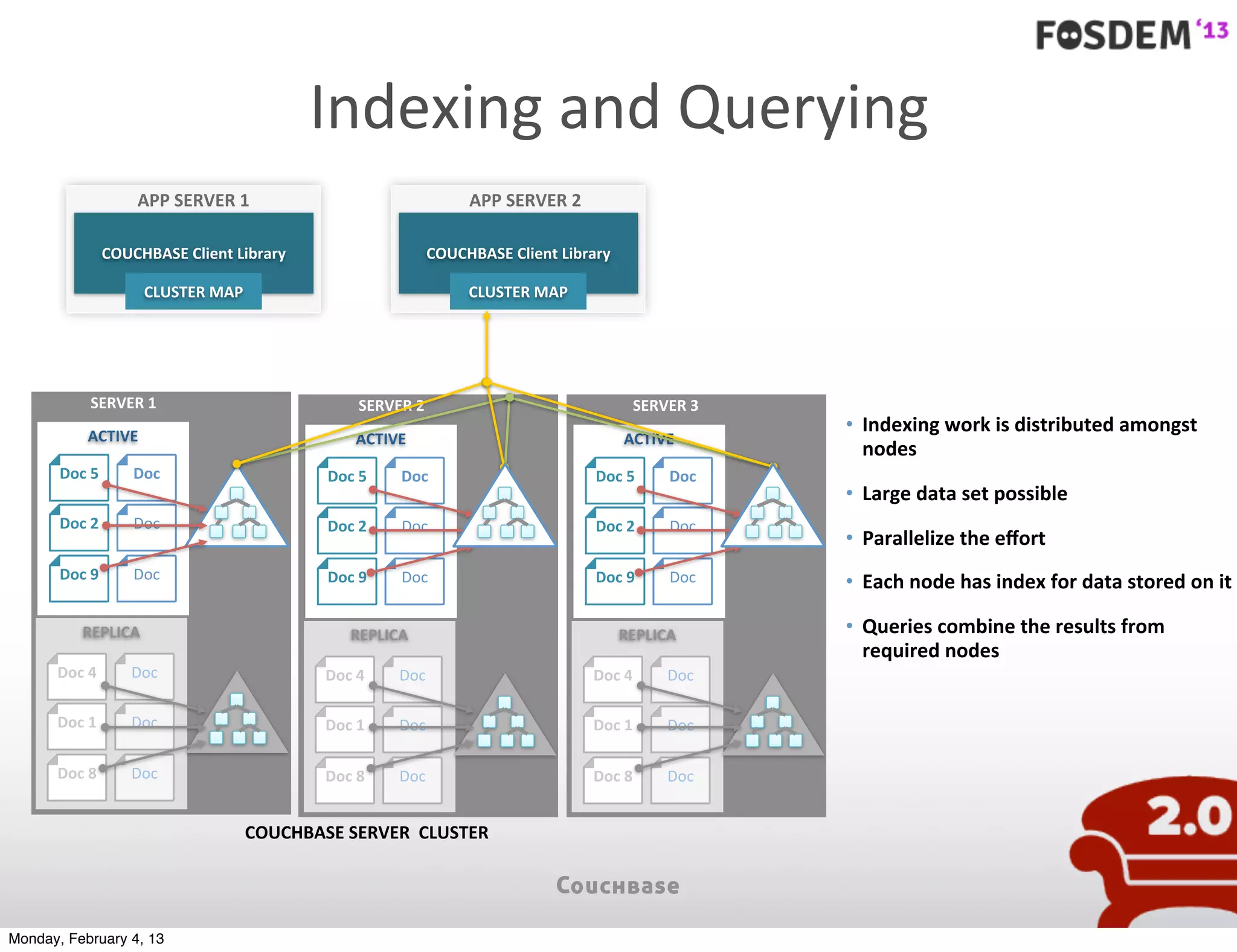
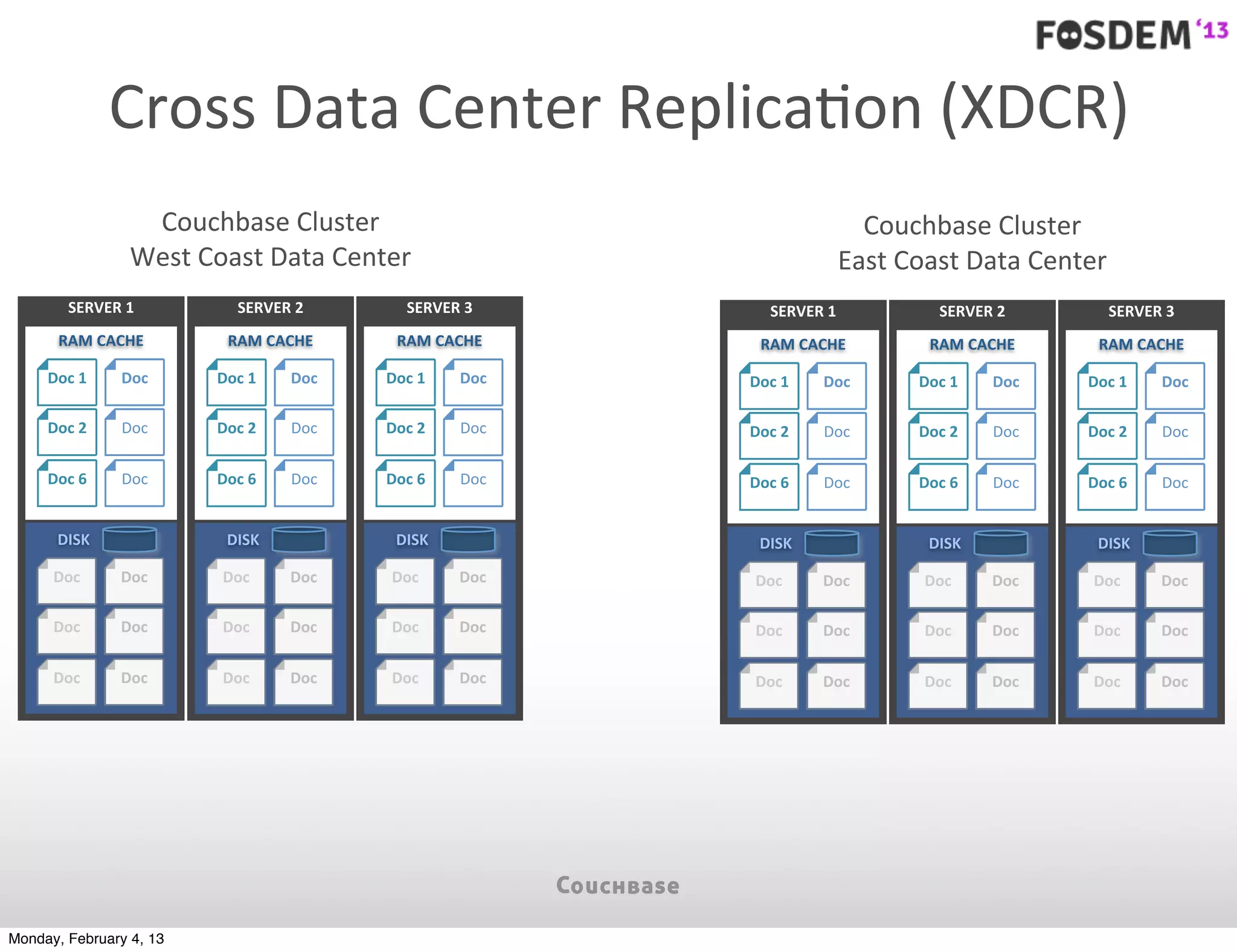
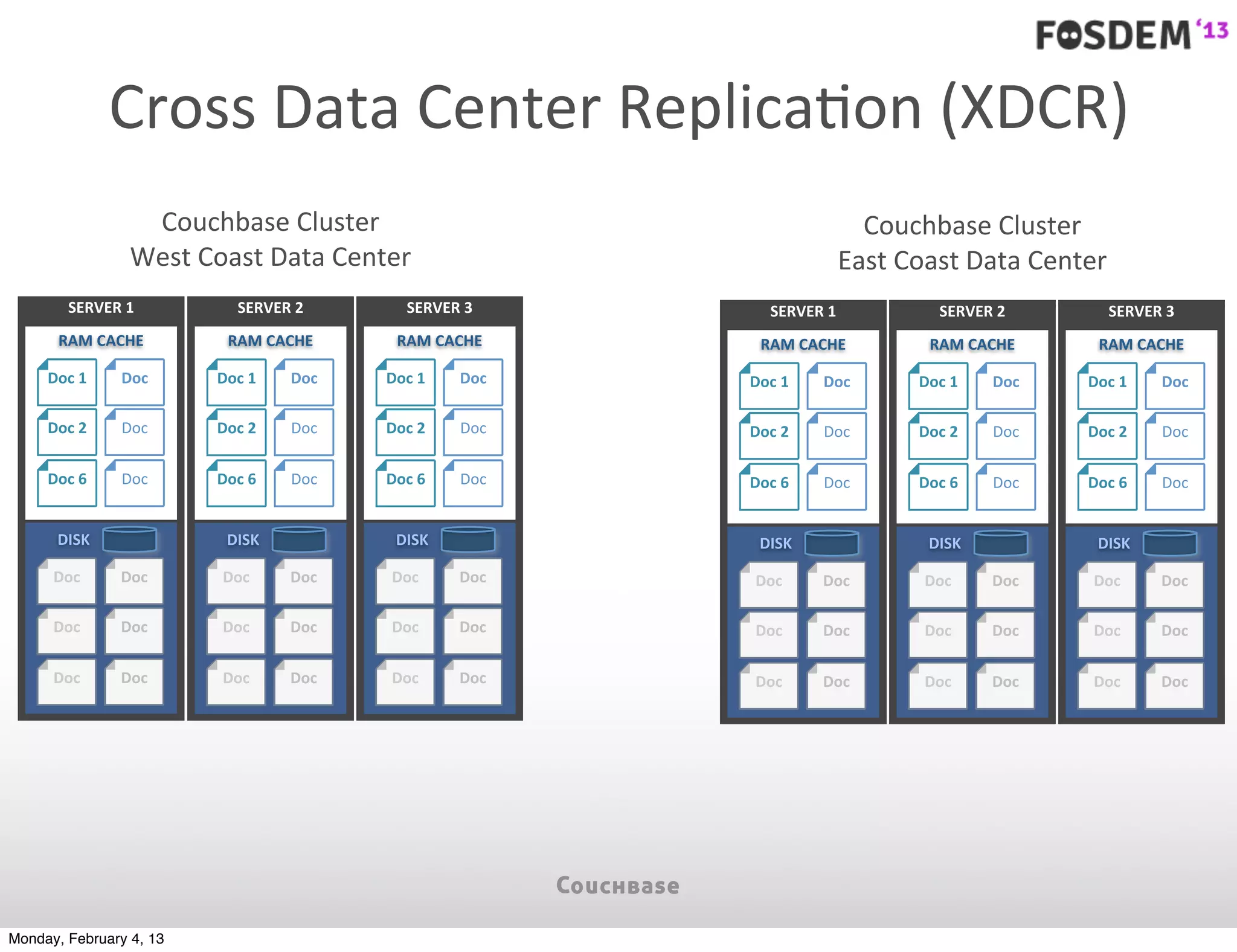

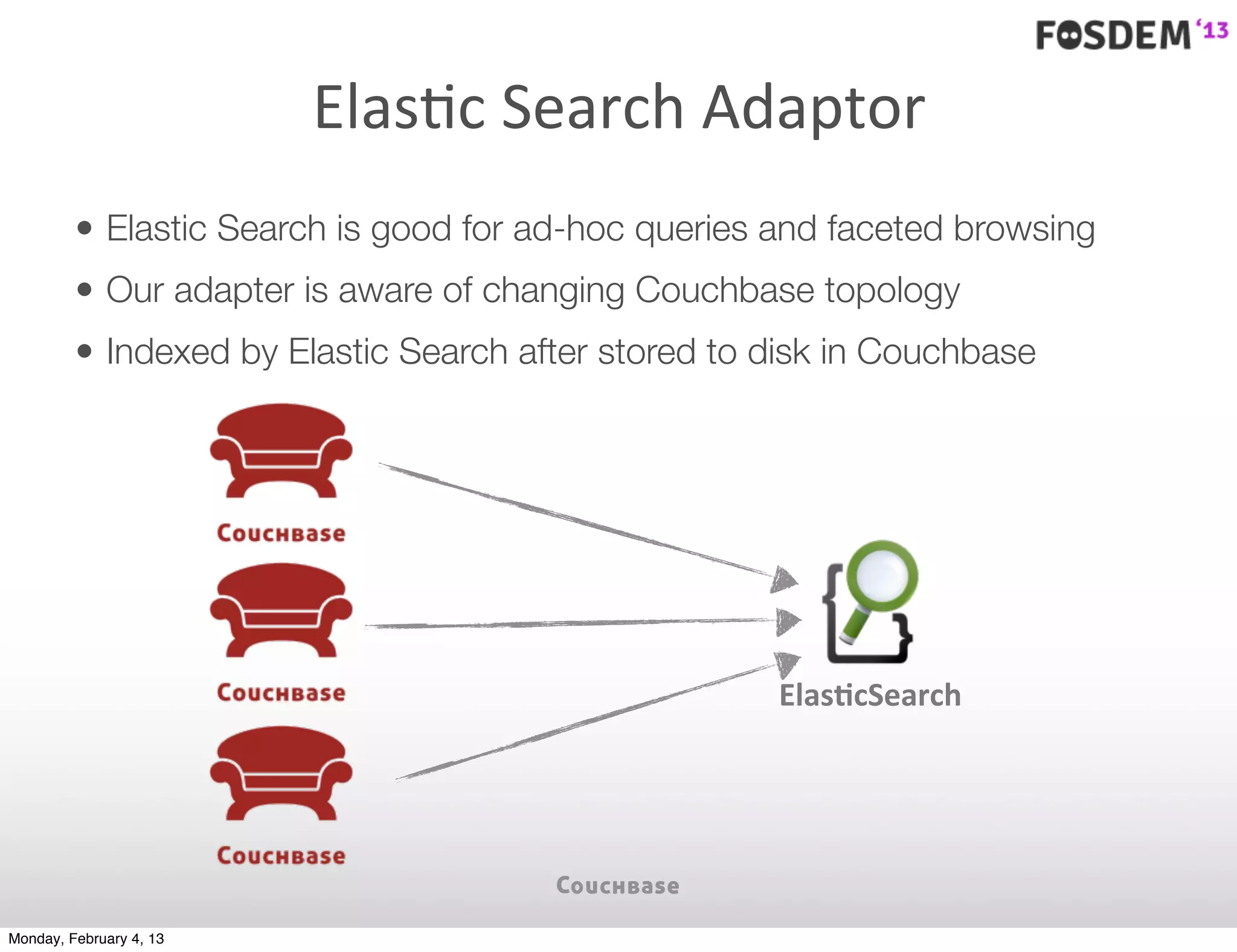

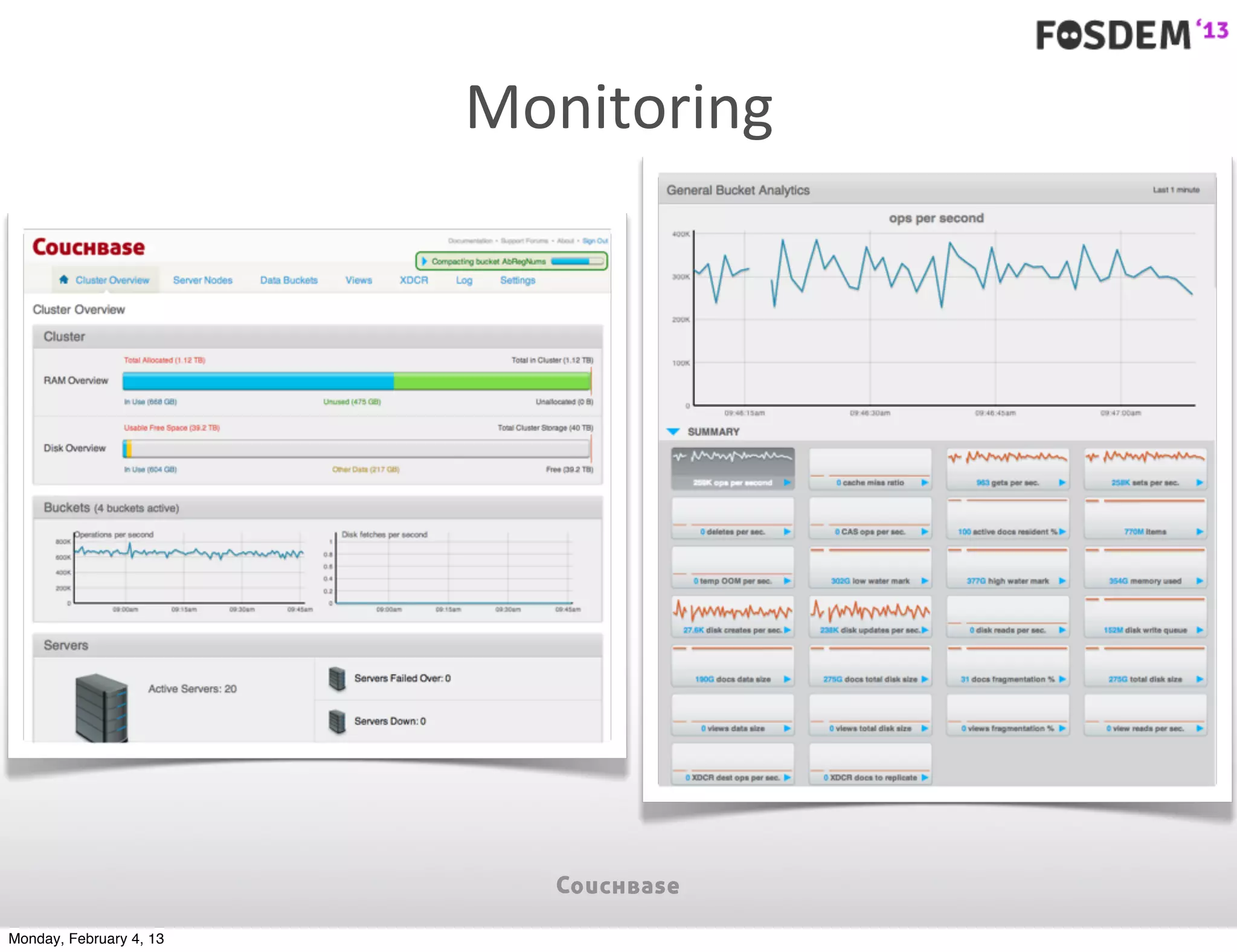

The document outlines the features and architecture of Couchbase Server 2.0, highlighting its capabilities for high scalability, performance, and ease of development. It emphasizes the software's use of a JSON document model and principles such as consistent uptime and efficient data handling across distributed servers. Additionally, it provides an overview of operational procedures like document retrieval and commands, along with the setup for development across various operating systems.


































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















