Downloaded 309 times



![Critical User
MapReduce Program
Execution Fork Fork
Fork
Overview [DG08]
Master
Assign Assign
Map Reduce
Key/Value
Pairs Worker
Remote Output
Local Worker
Split 1 read file 1
Write Write
Split 2
Worker
Split 3
Split 4 .
.
Output
Split 5 Worker file 2
.
.
. Worker
. Output
Intermediate Reduce
Input Files Map Phase Operations Phase Files](https://image.slidesharecdn.com/dwdpresentation-120527232915-phpapp02/85/MapReduce-Paradigm-3-320.jpg)






![Dataflow in Hadoop[CAHER10]
Submit job
map schedule reduce
map reduce](https://image.slidesharecdn.com/dwdpresentation-120527232915-phpapp02/85/MapReduce-Paradigm-12-320.jpg)
![Dataflow in Hadoop[CAHER10]
Read
Input File
map reduce
Block 1
HDFS
Block 2
map reduce](https://image.slidesharecdn.com/dwdpresentation-120527232915-phpapp02/85/MapReduce-Paradigm-13-320.jpg)
![Dataflow in Hadoop[CAHER10]
map Local
FS
reduce
HTTP GET
Local
map FS reduce](https://image.slidesharecdn.com/dwdpresentation-120527232915-phpapp02/85/MapReduce-Paradigm-14-320.jpg)
![Dataflow in Hadoop[CAHER10]
Write
Final
reduce
Answer
HDFS
reduce](https://image.slidesharecdn.com/dwdpresentation-120527232915-phpapp02/85/MapReduce-Paradigm-15-320.jpg)

![Different Workflows[MTAGS11]](https://image.slidesharecdn.com/dwdpresentation-120527232915-phpapp02/85/MapReduce-Paradigm-17-320.jpg)
![Hadoop Applicability by Workflow[MTAGS11]
Score Meaning:
• Score Zero implies Easily adaptable to the workflow
• Score 0.5 implies Moderately adaptable to the
workflow
• Score 1 indicates one of the potential workflow areas
where Hadoop needs improvement](https://image.slidesharecdn.com/dwdpresentation-120527232915-phpapp02/85/MapReduce-Paradigm-18-320.jpg)


![References
[LLCCM12] Kyong-Ha Lee, Yoon-Joon Lee, Hyunsik Choi, Yon Dohn
Chung, and Bongki Moon, “Parallel data processing with MapReduce:
a survey,” SIGMOD, January 2012, pp. 11-20.
[MTAGS11] Elif Dede, Madhusudhan Govindaraju, Daniel Gunter, and
Lavanya Ramakrishnan, “ Riding the Elephant: Managing Ensembles
with Hadoop,” Proceedings of the 2011 ACM international workshop
on Many task computing on grids and supercomputers, ACM, New
York, NY, USA, pp. 49-58.
[DG08]Jeffrey Dean and Sanjay Ghemawat, “MapReduce: simplified
data processing on large clusters,” January 2008, pp. 107-113. ACM.
[CAHER10]Tyson Condie, Neil Conway, Peter Alvaro, Joseph M.
Hellerstein, Khaled Elmeleegy, and Russell Sears, “MapReduce online,”
Proceedings of the 7th USENIX conference on Networked systems
design and implementation (NSDI'10), USENIX Association, Berkeley,
CA, USA, 2010, pp. 21-37.](https://image.slidesharecdn.com/dwdpresentation-120527232915-phpapp02/85/MapReduce-Paradigm-21-320.jpg)


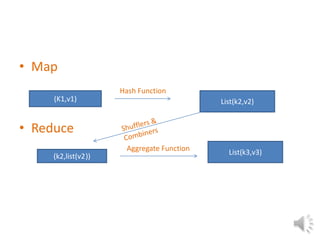
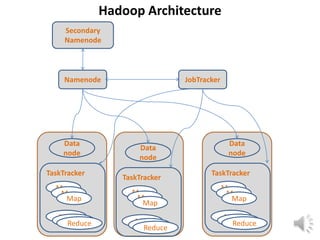
This document provides an overview of the MapReduce paradigm and Hadoop framework. It describes how MapReduce uses a map and reduce phase to process large amounts of distributed data in parallel. Hadoop is an open-source implementation of MapReduce that stores data in HDFS. It allows applications to work with thousands of computers and petabytes of data. Key advantages of MapReduce include fault tolerance, scalability, and flexibility. While it is well-suited for batch processing, it may not replace traditional databases for data warehousing. Overall efficiency remains an area for improvement.



































































