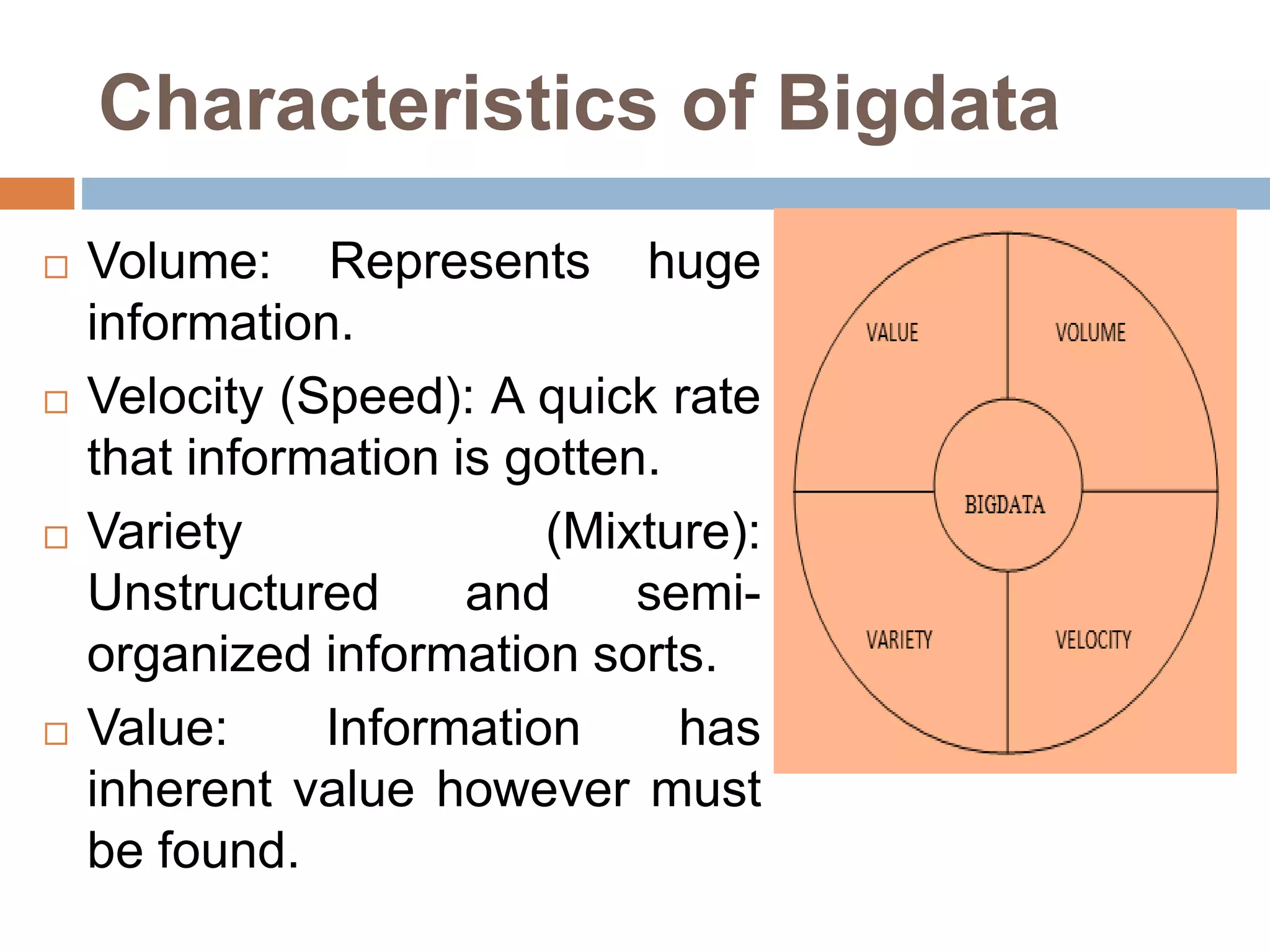
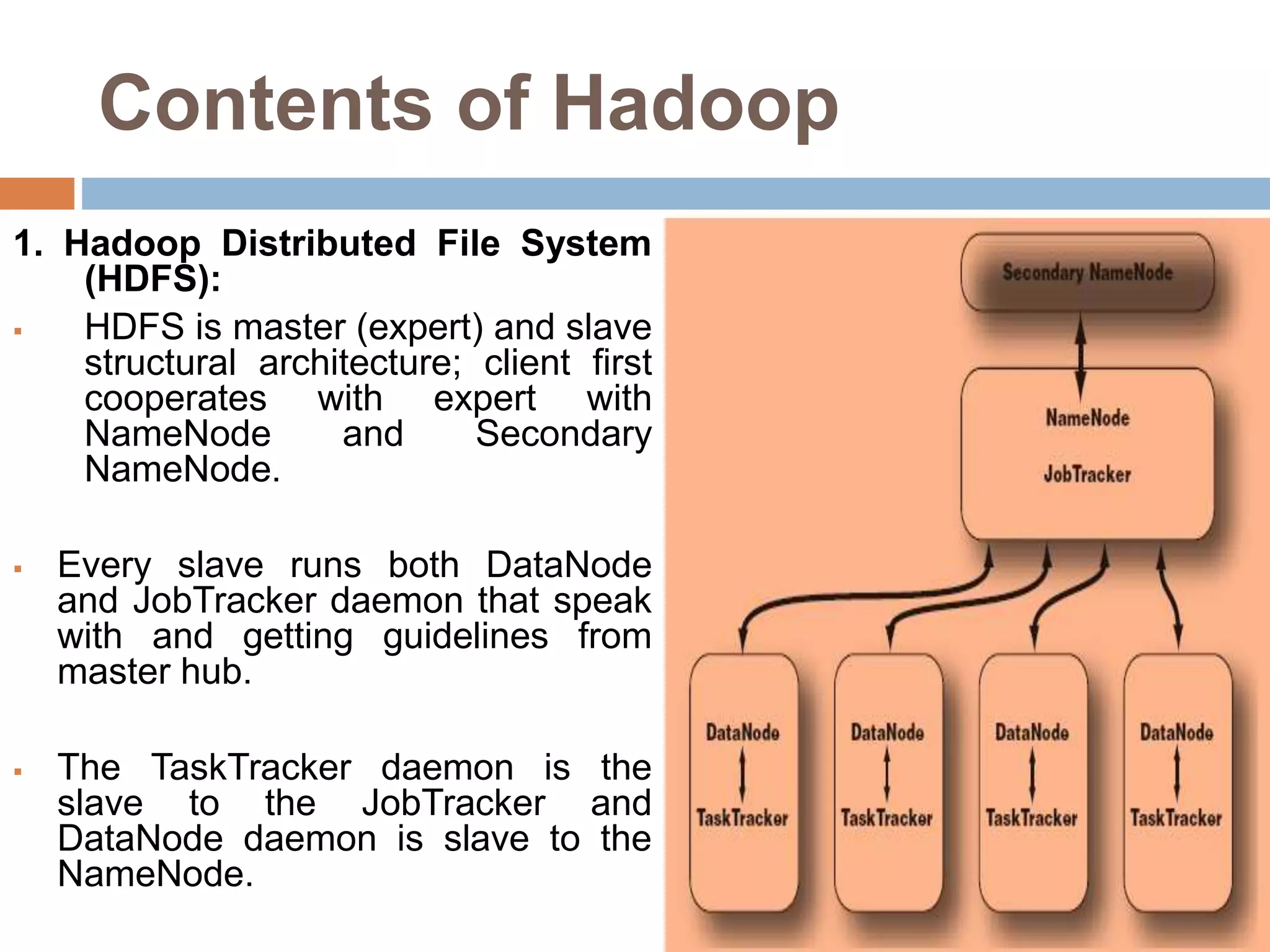
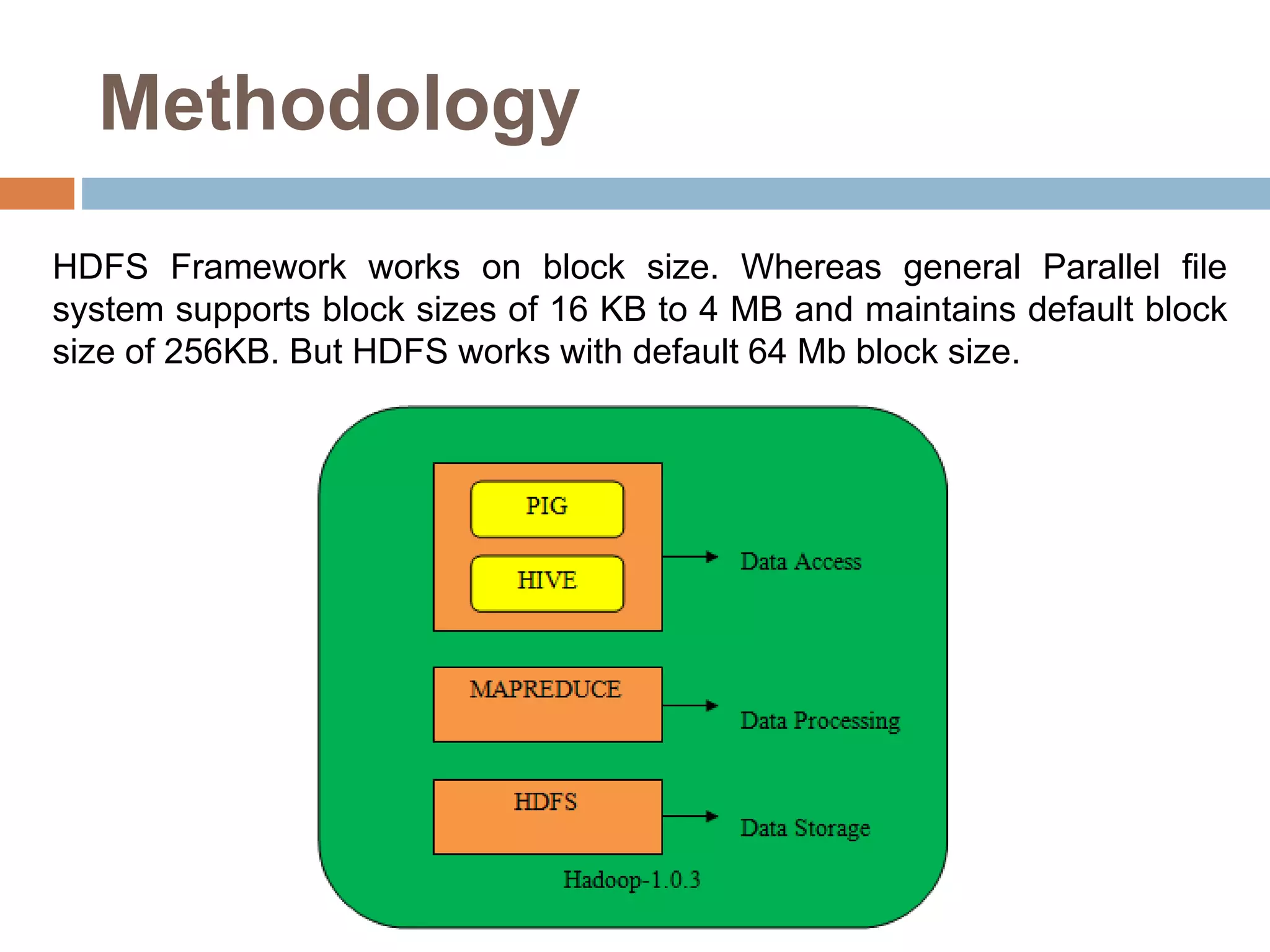
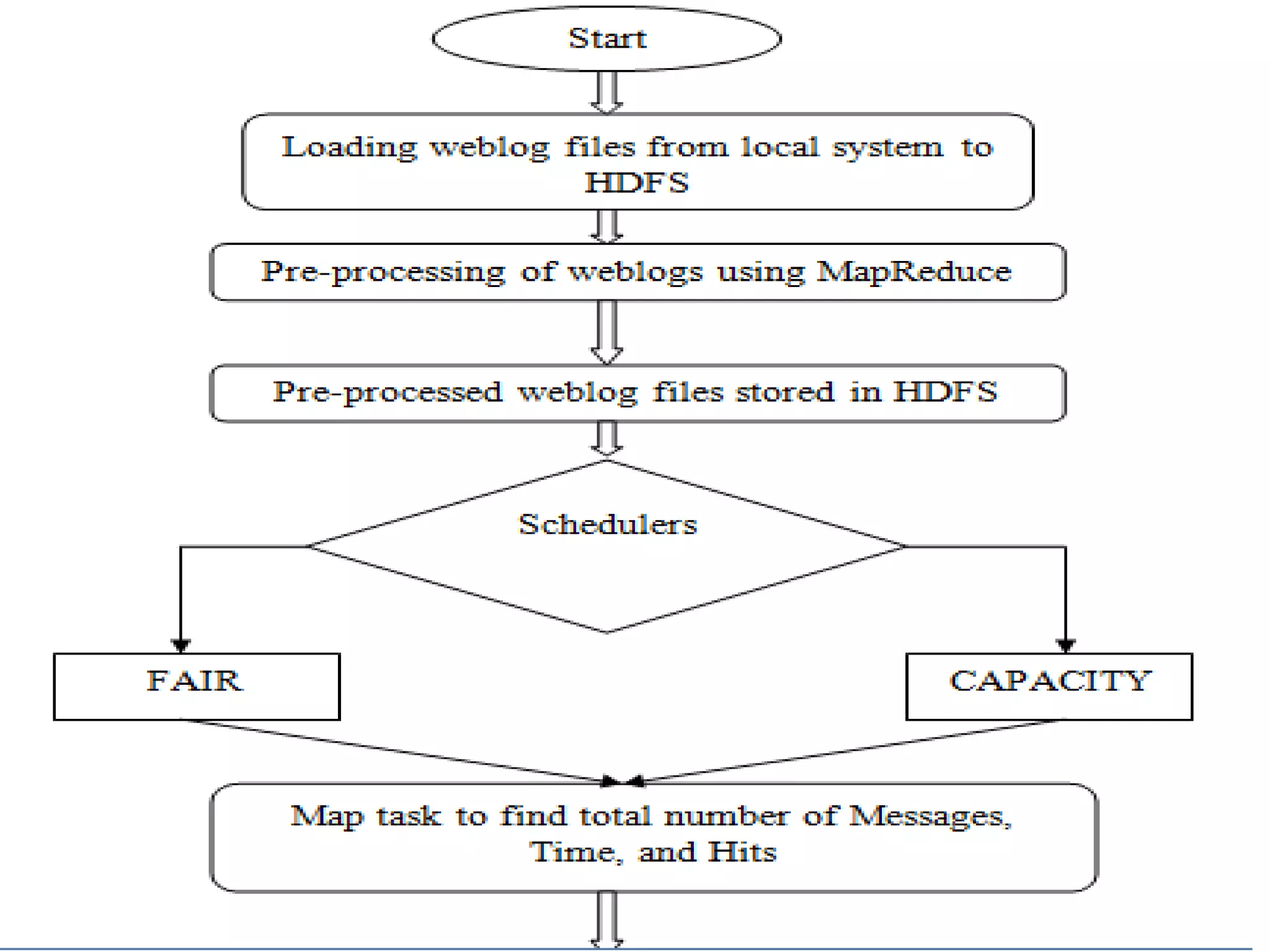
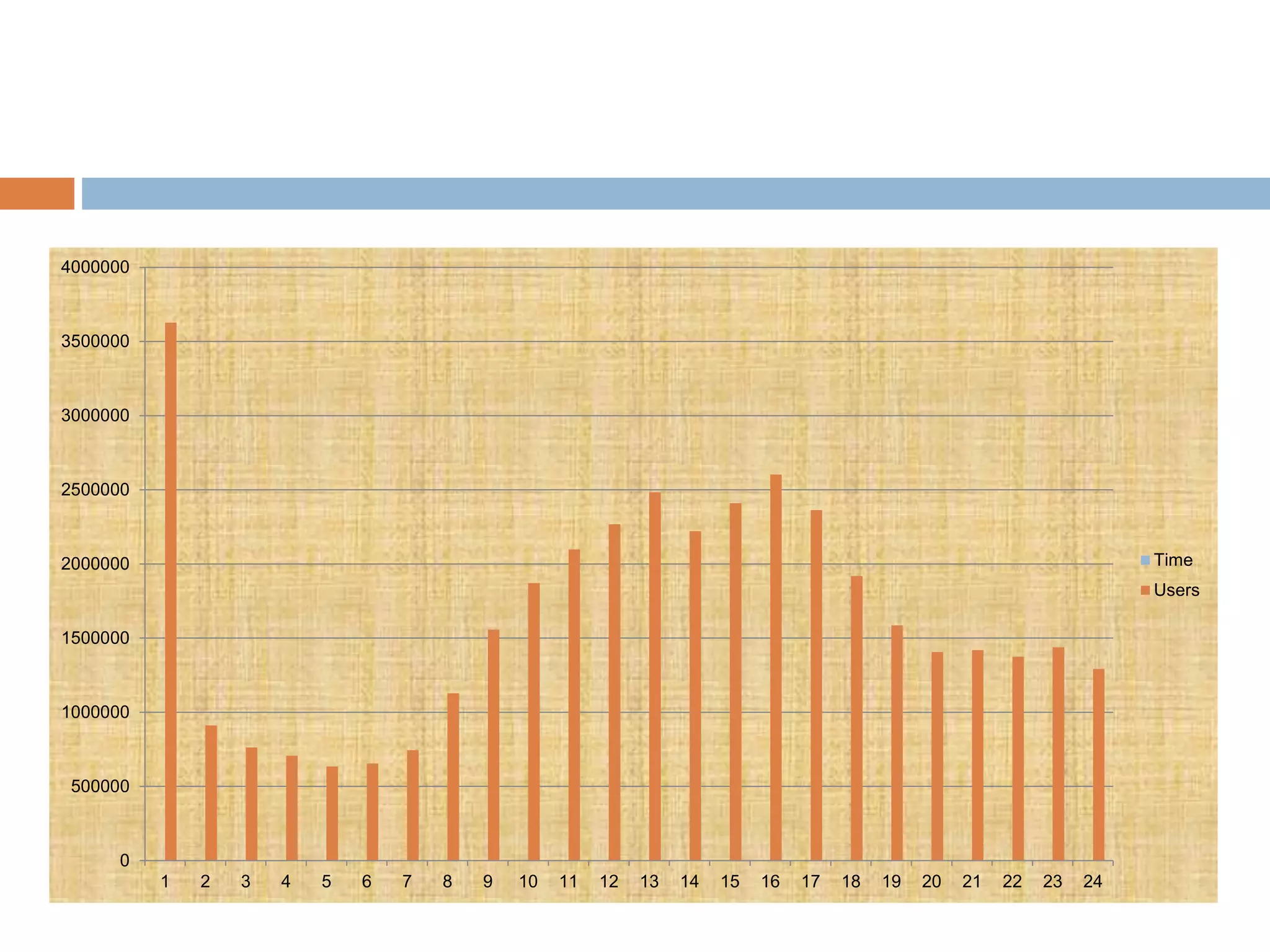
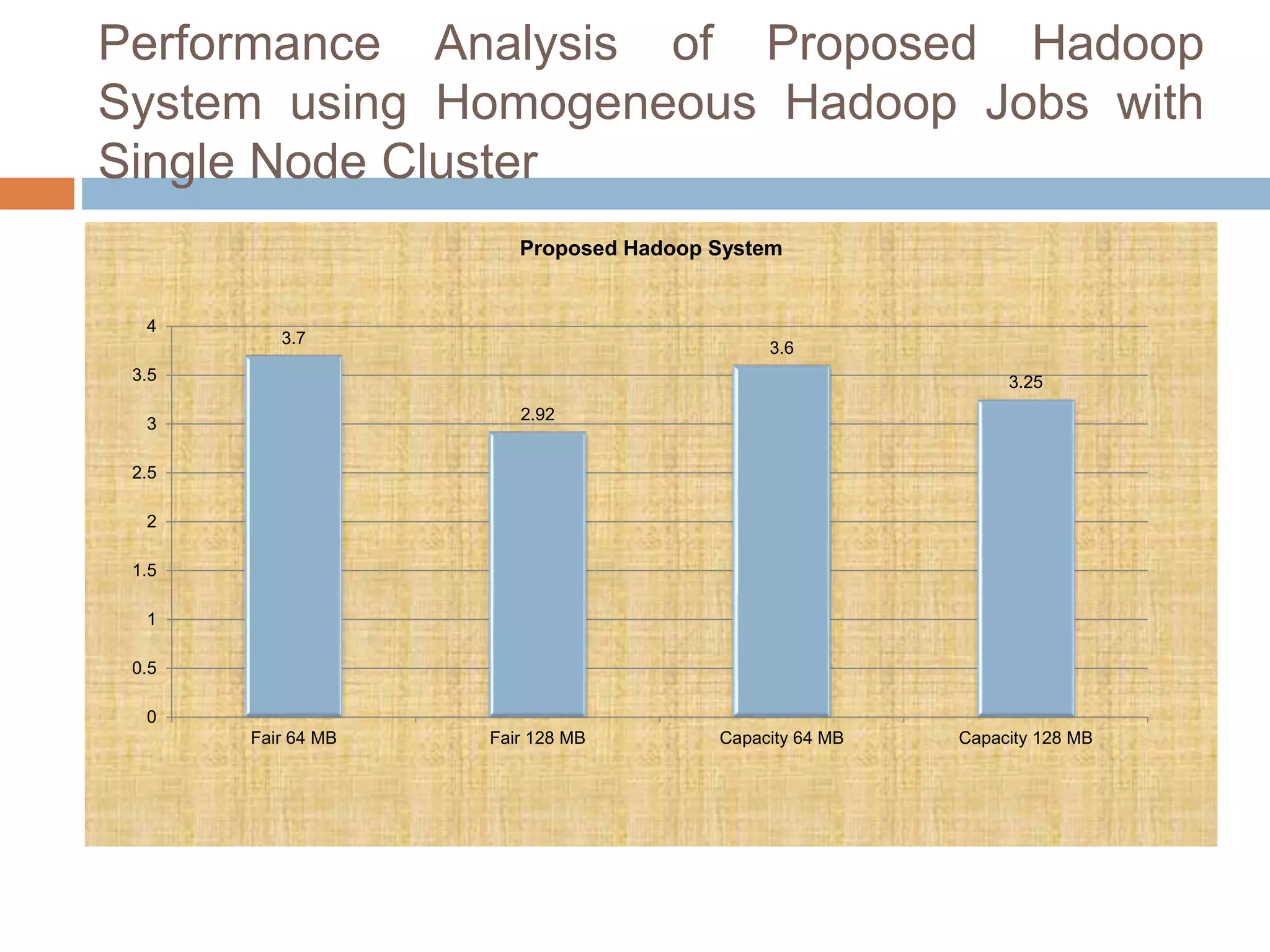
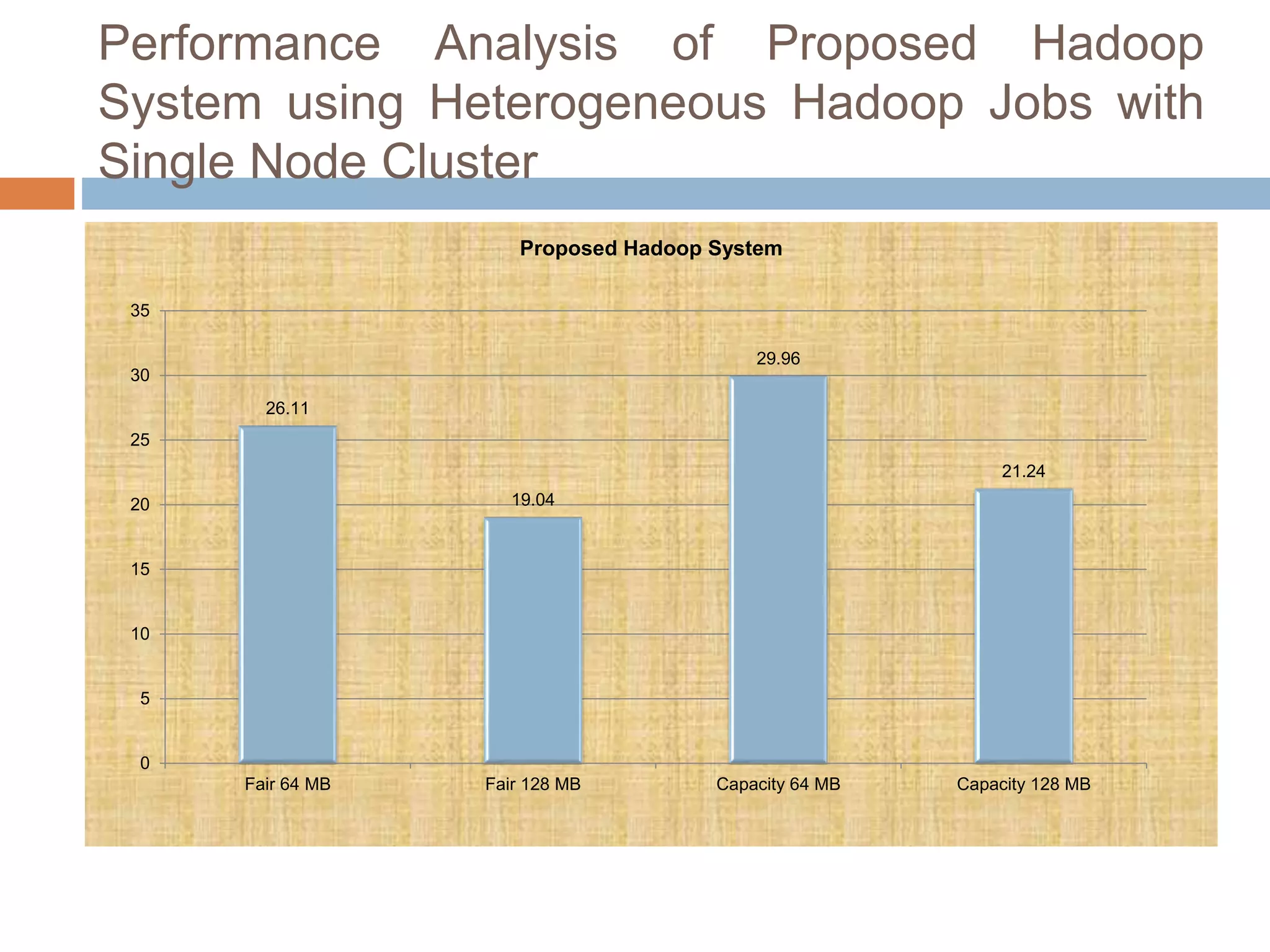
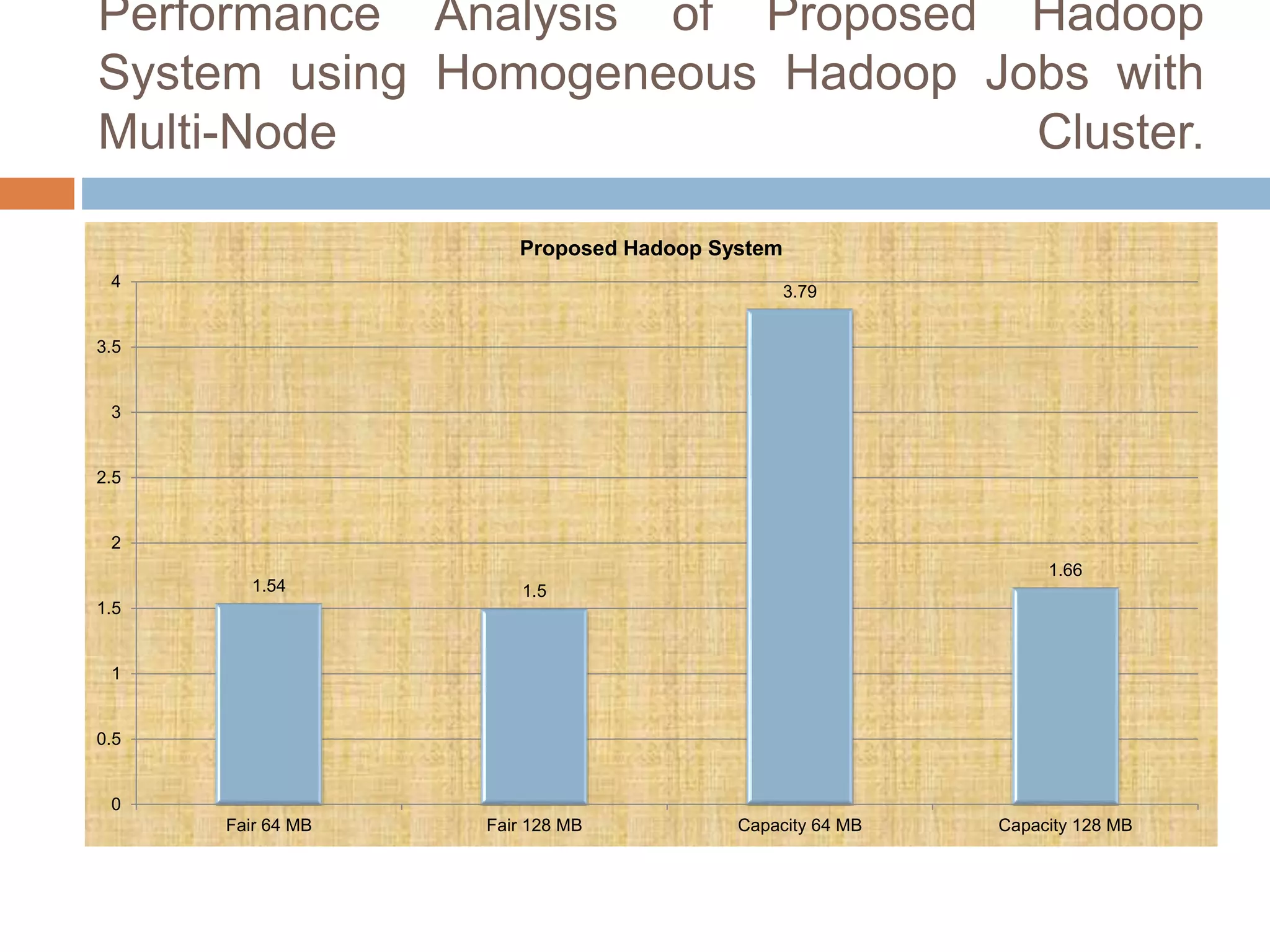
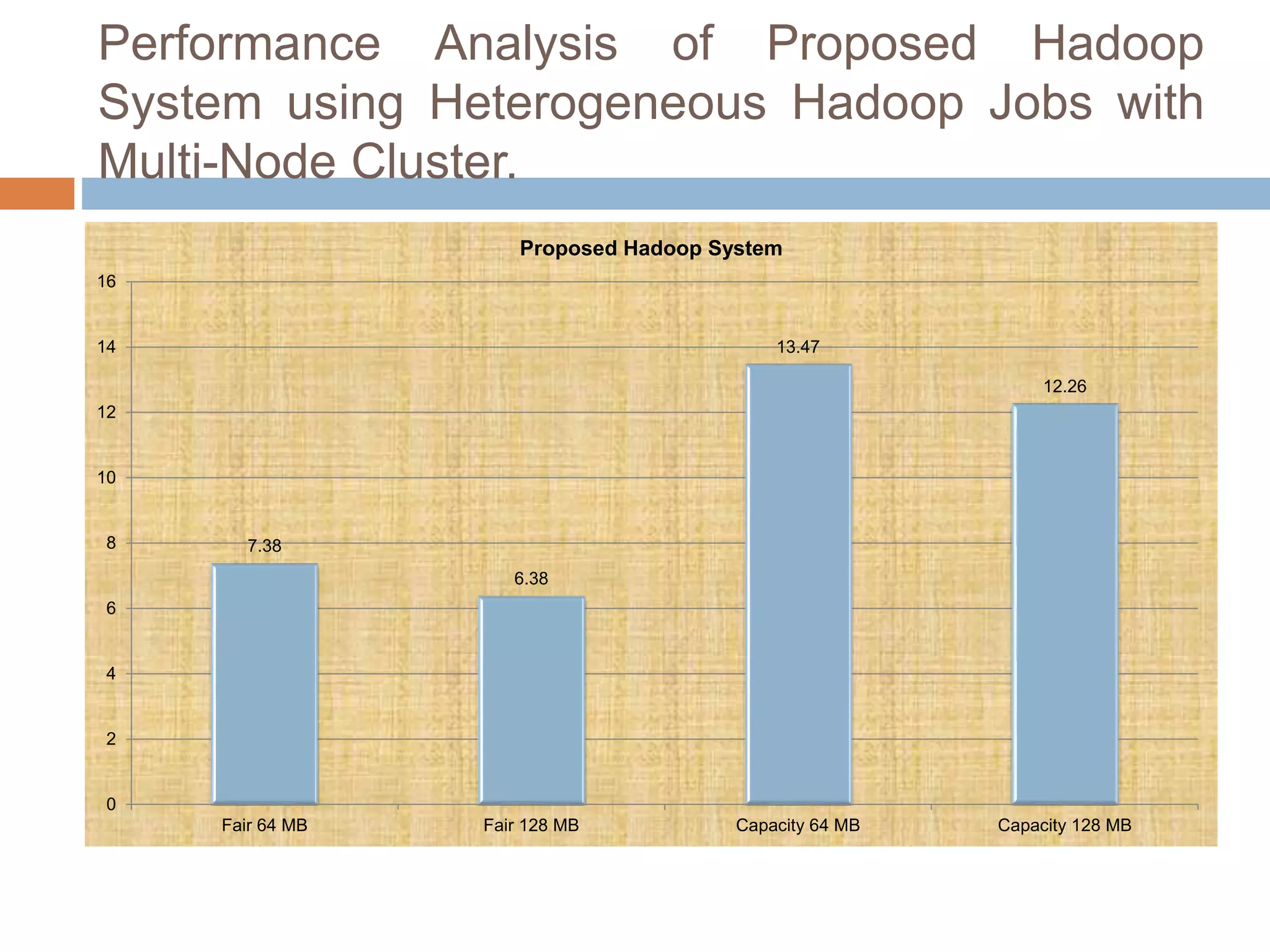
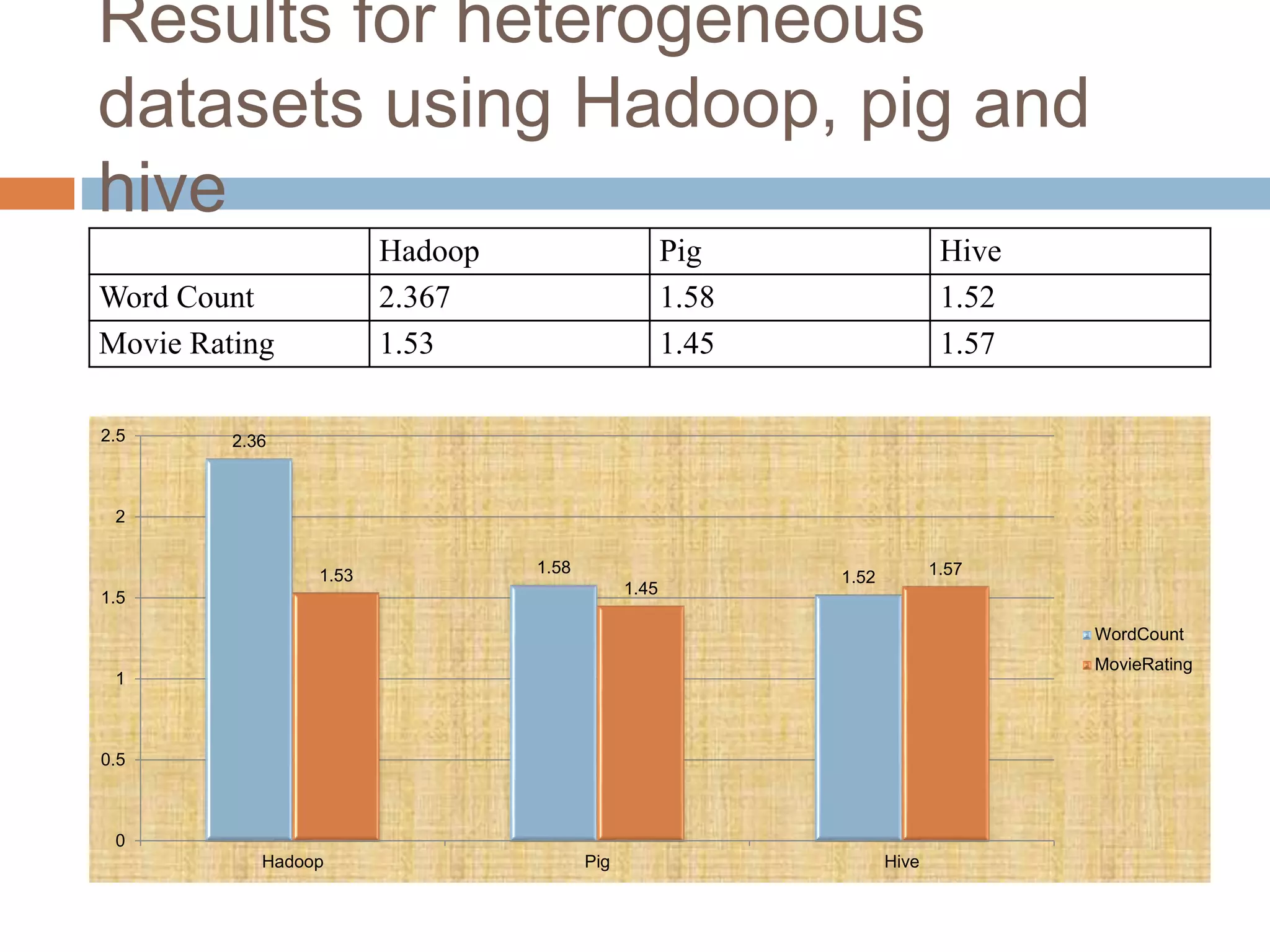
The document discusses optimization of job scheduling in Hadoop clusters, highlighting issues with the default FIFO scheduler and introducing alternative approaches such as the Fair Scheduler and Capacity Scheduler. It details the characteristics of big data, the functionality of Hadoop's HDFS and MapReduce, and presents methodologies for job scheduling to enhance performance. The findings indicate improvements in processing speed and efficiency through the proposed scheduling techniques when handling large datasets.
















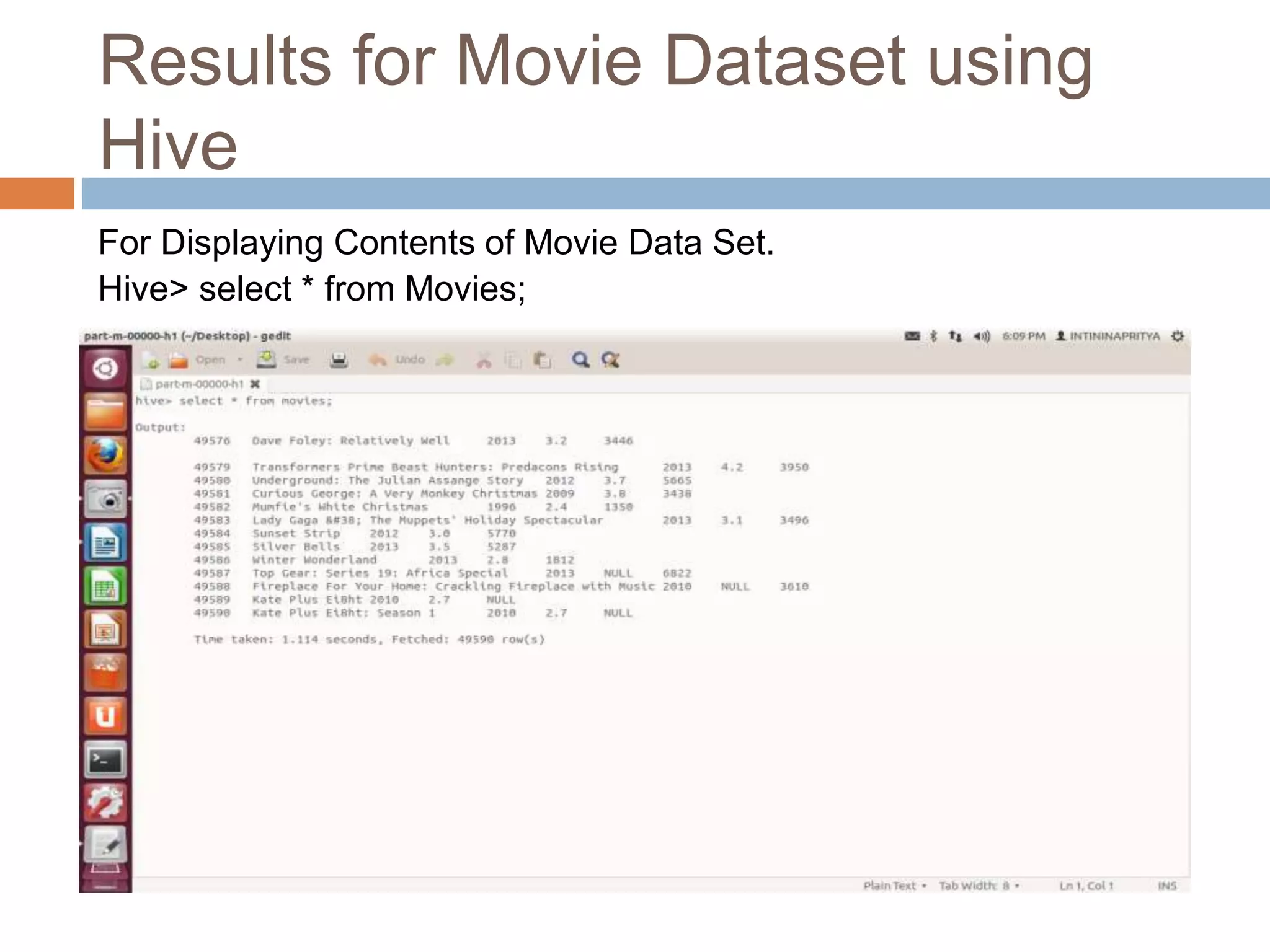
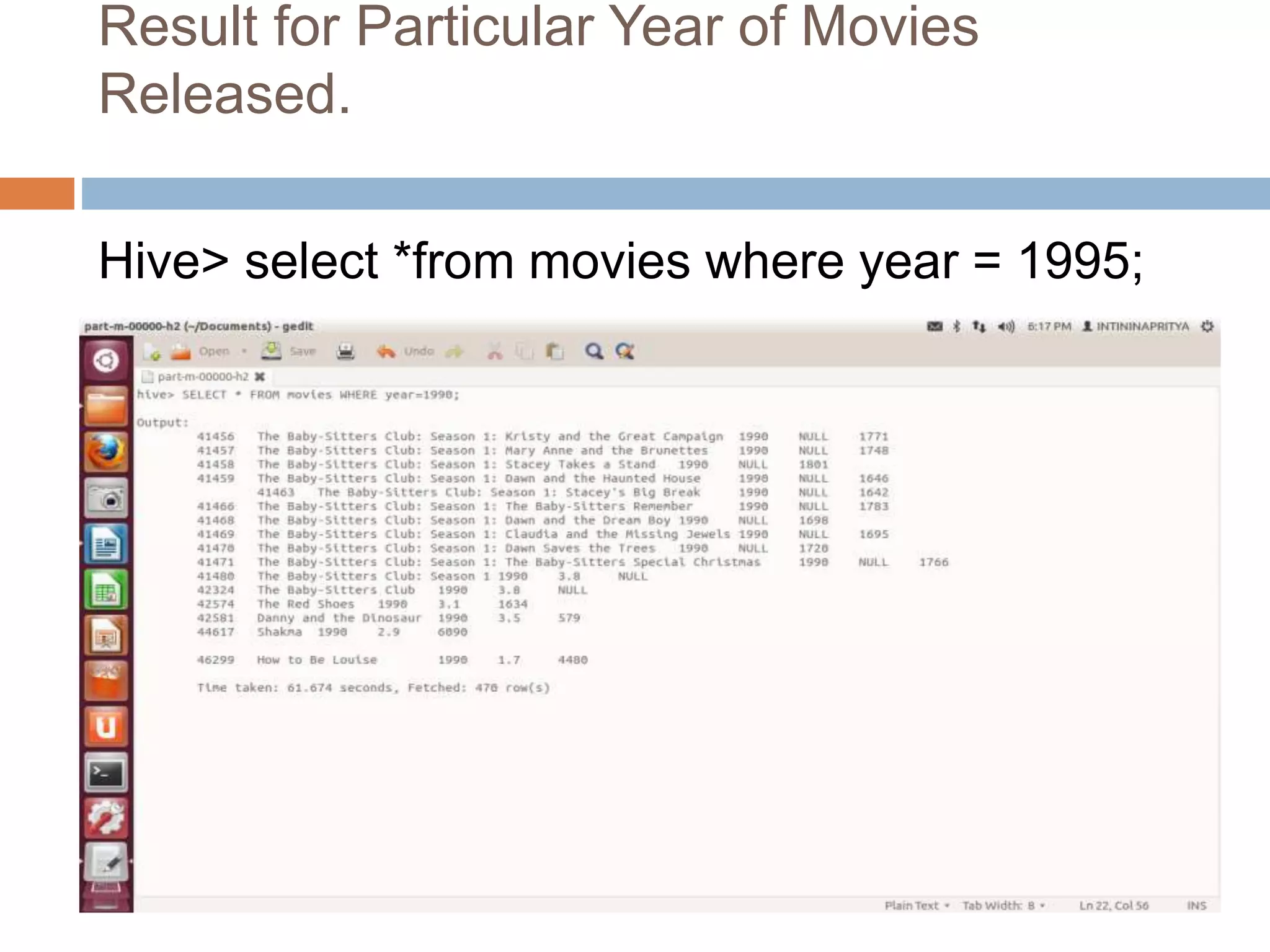
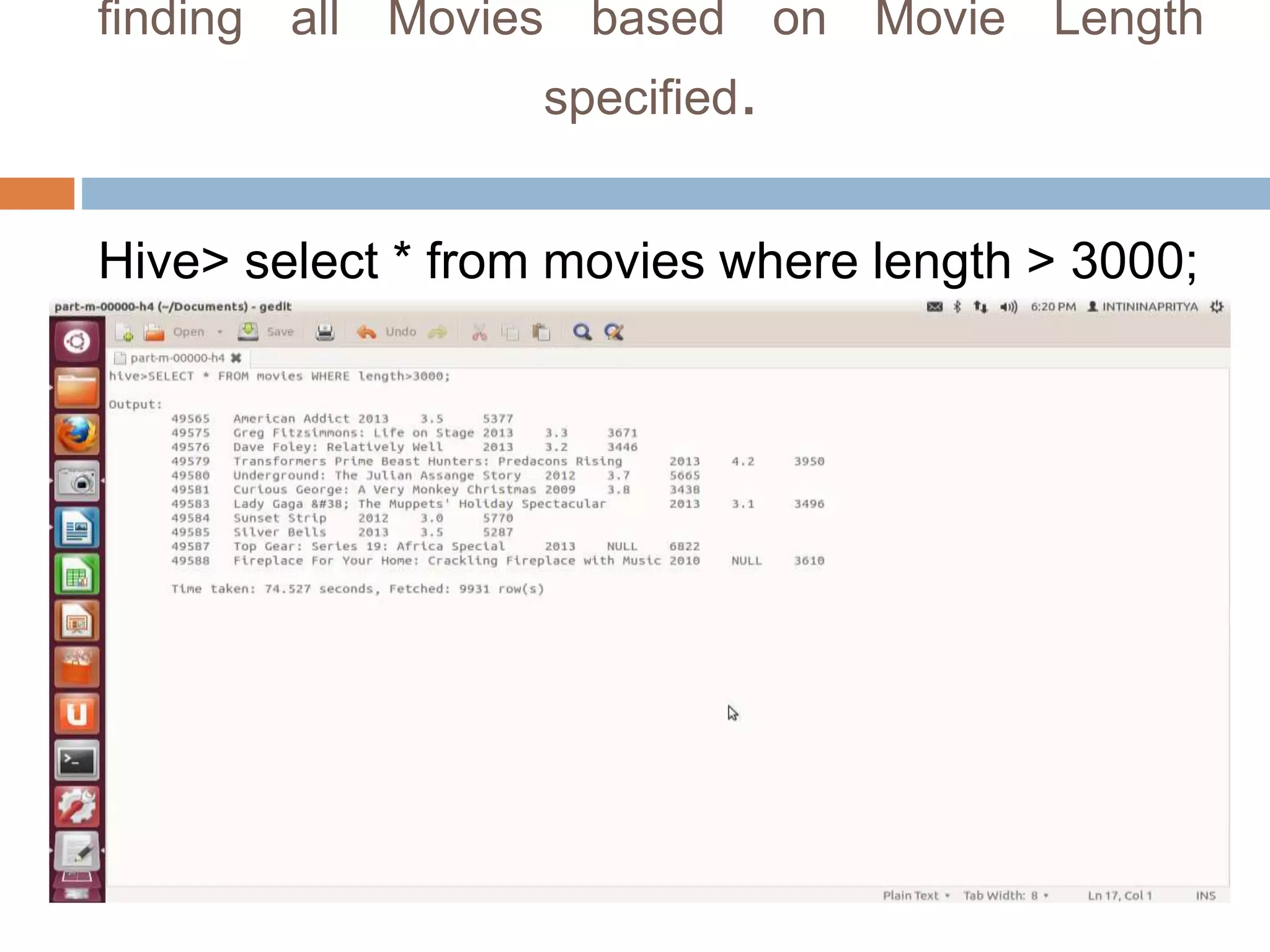
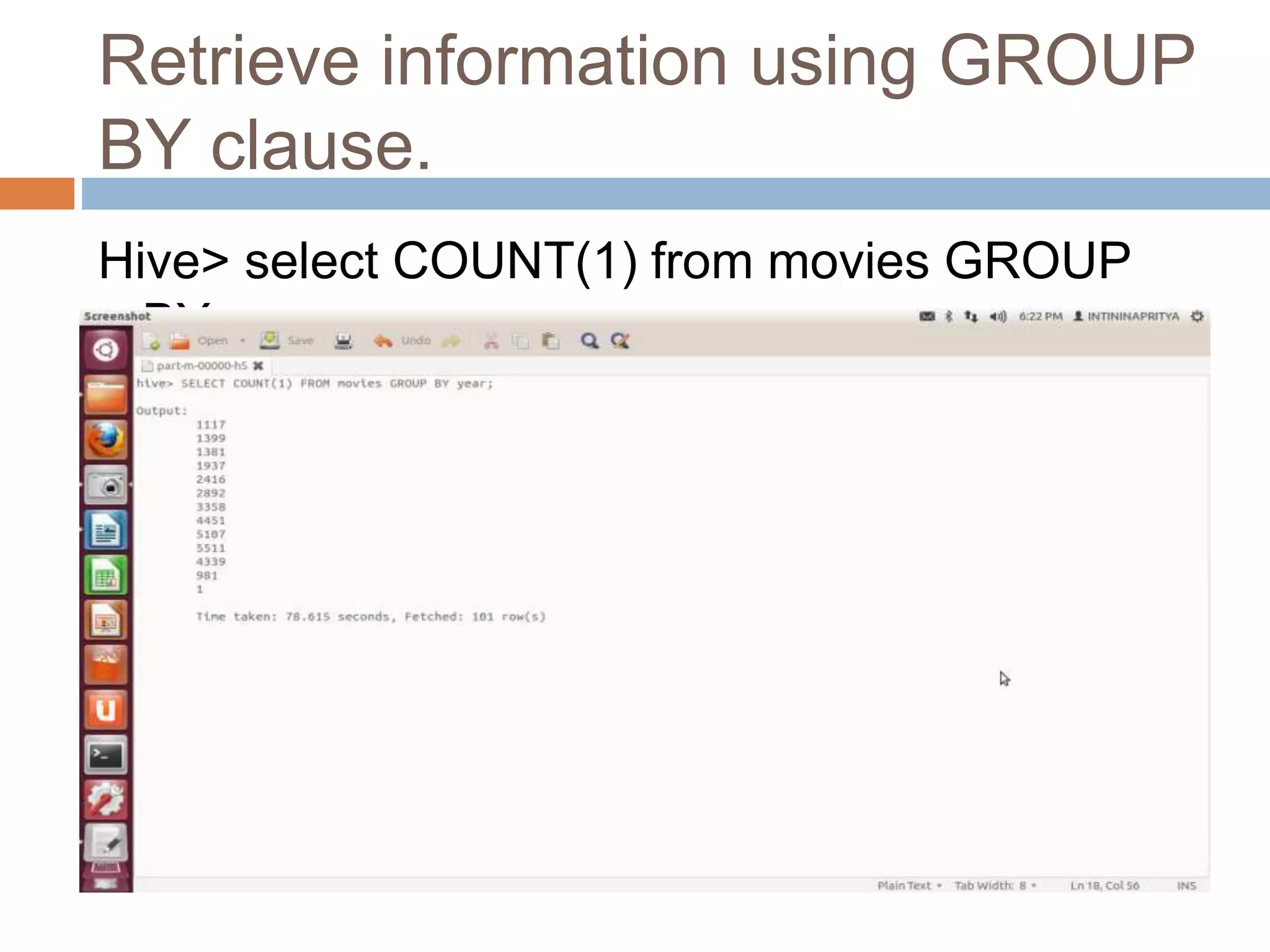
















![Resource Aware Scheduling for Hadoop [Final Presentation]](https://cdn.slidesharecdn.com/ss_thumbnails/fyppresentationfinal-120226092754-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































































