

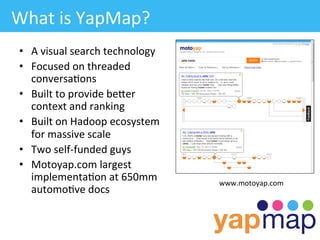

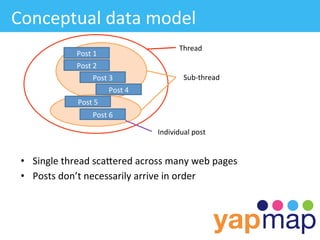
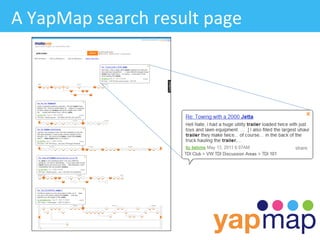



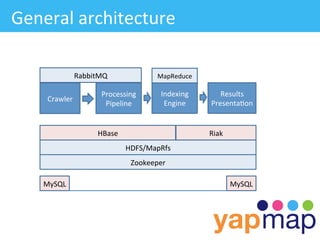


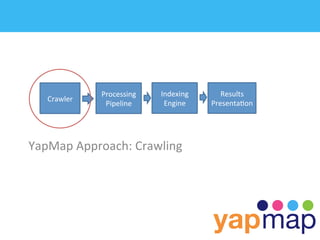

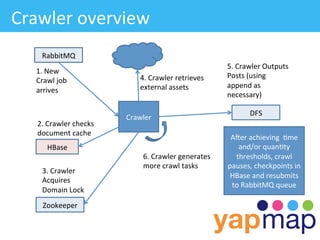

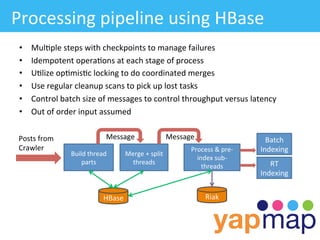


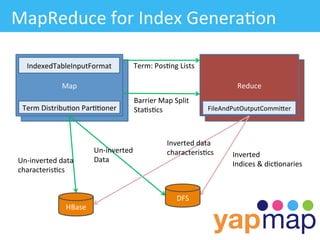
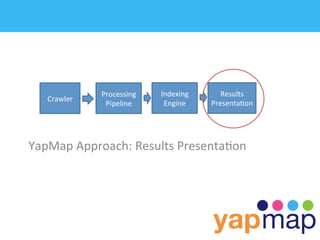

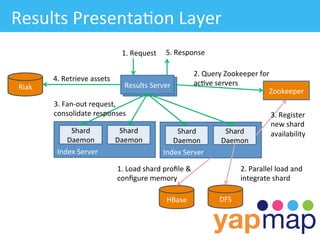





The document discusses YapMap, a visual search technology focused on threaded conversations. It was built using Hadoop to handle massive scales of data. The presentation covers YapMap's approach to crawling forums and message boards to build a searchable index, its distributed processing pipeline in Hadoop to reconstruct threads from individual posts and generate pre-indexed sub-threads, and how it presents search results with contextual threads and posts.






















































































