Download to read offline























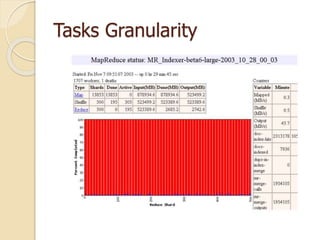
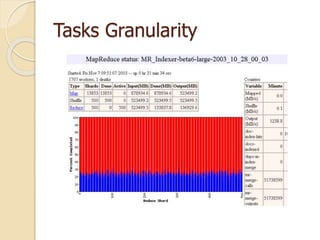
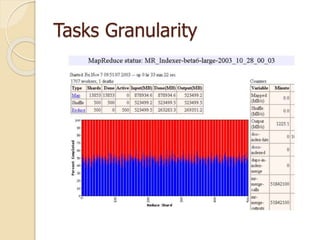






















![Related work
Programming model inspired by functional language
primitives
Partitioning/shuffling similar to many large-scale sorting
systems
◦ NOW-Sort ['97]
Re-execution for fault tolerance
◦ BAD-FS ['04] and TACC ['97]
Locality optimization has parallels with Active Disks/Diamond
work
◦ Active Disks ['01], Diamond ['04]
Backup tasks similar to Eager Scheduling in Charlotte system
◦ Charlotte ['96]
Dynamic load balancing solves similar problem as River's
distributed queues
◦ River ['99]](https://image.slidesharecdn.com/mapreduce-presentation-151110054033-lva1-app6892/85/MapReduce-presentation-64-320.jpg)


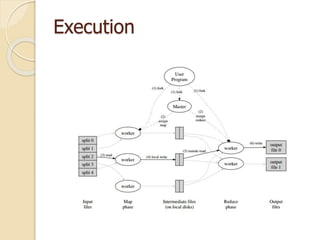
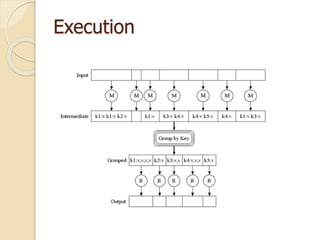
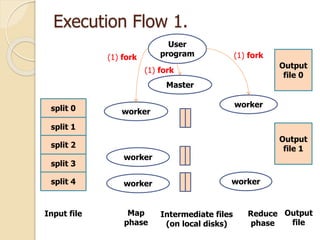
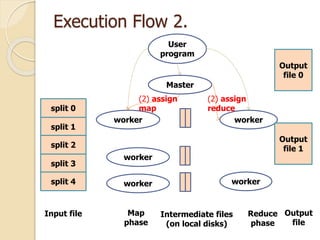
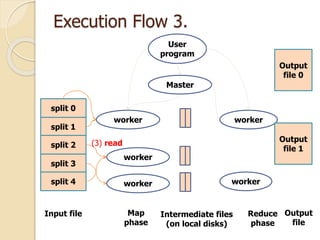
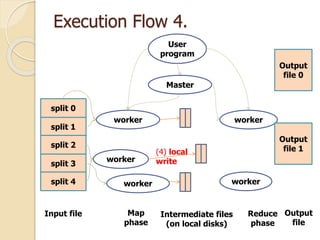
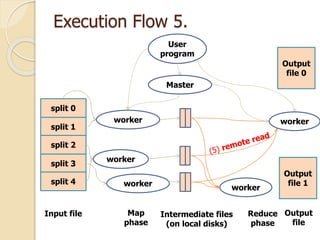
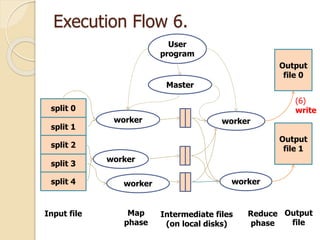
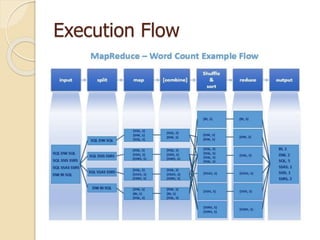
This document describes MapReduce, a programming model and software framework for processing large datasets in a distributed manner. It introduces the key concepts of MapReduce including the map and reduce functions, distributed execution across clusters of machines, and fault tolerance. The document outlines how MapReduce abstracts away complexities like parallelization, data distribution, and failure handling. It has been used successfully at Google for large-scale tasks like search indexing and machine learning.














































































