Download as PDF, PPTX









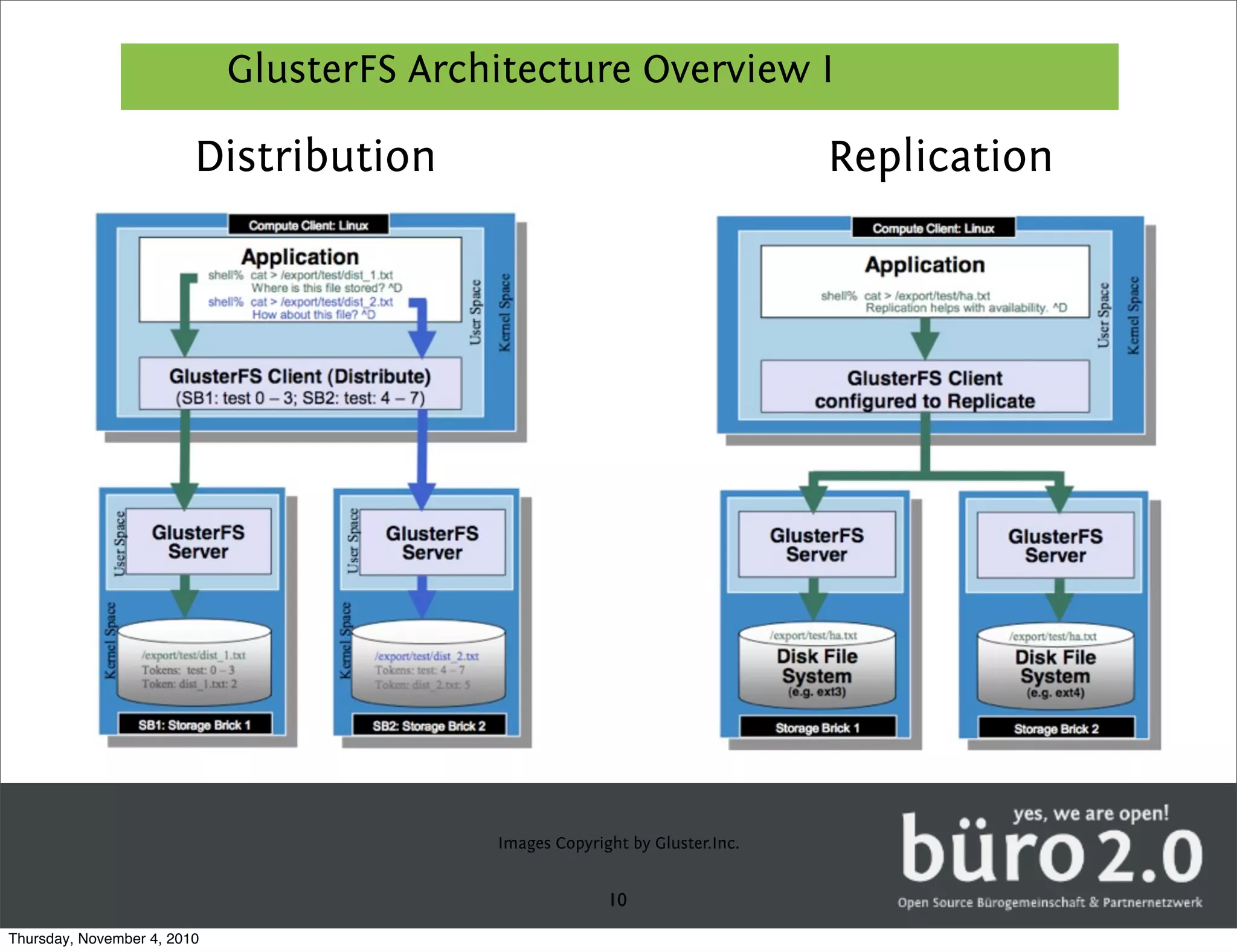
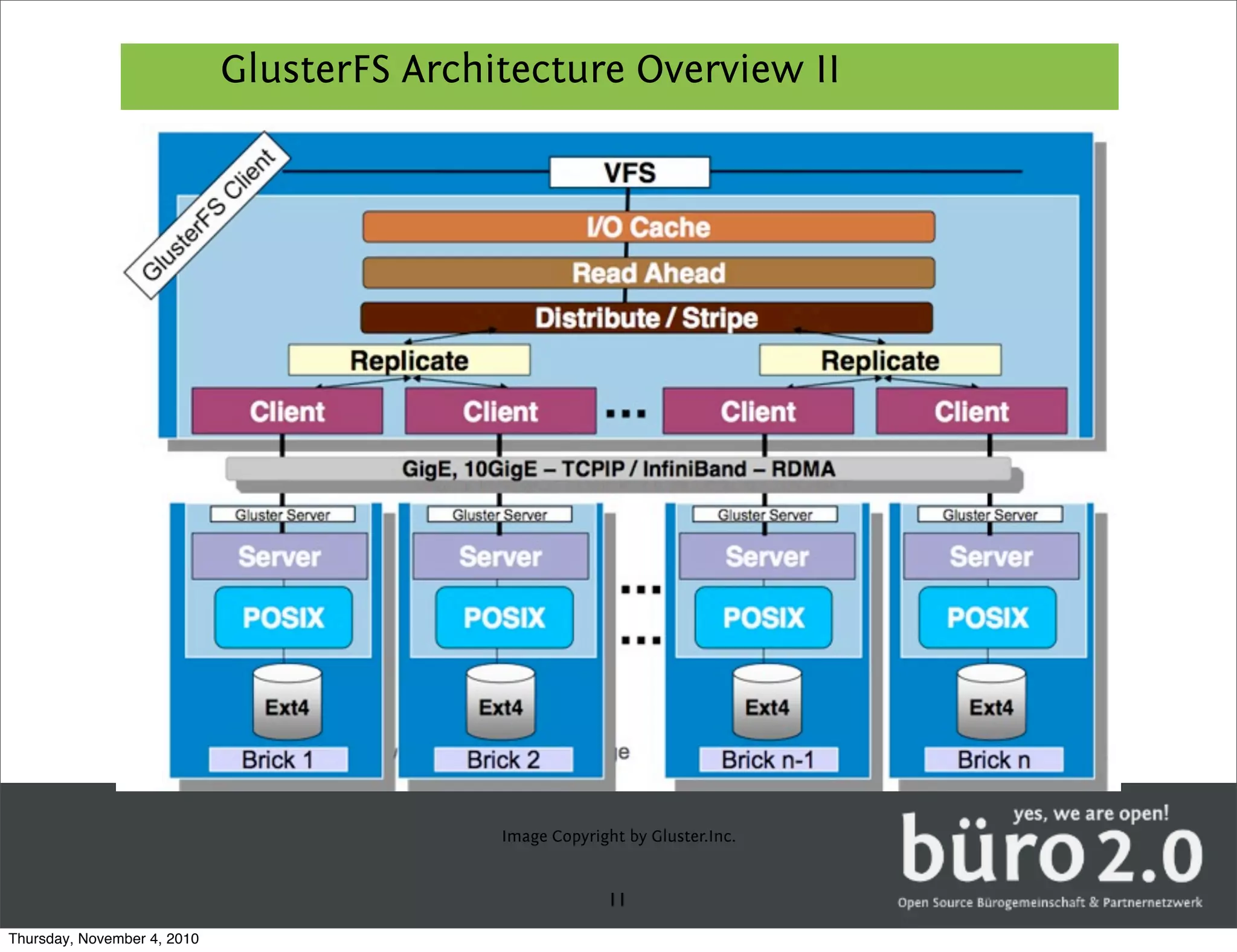
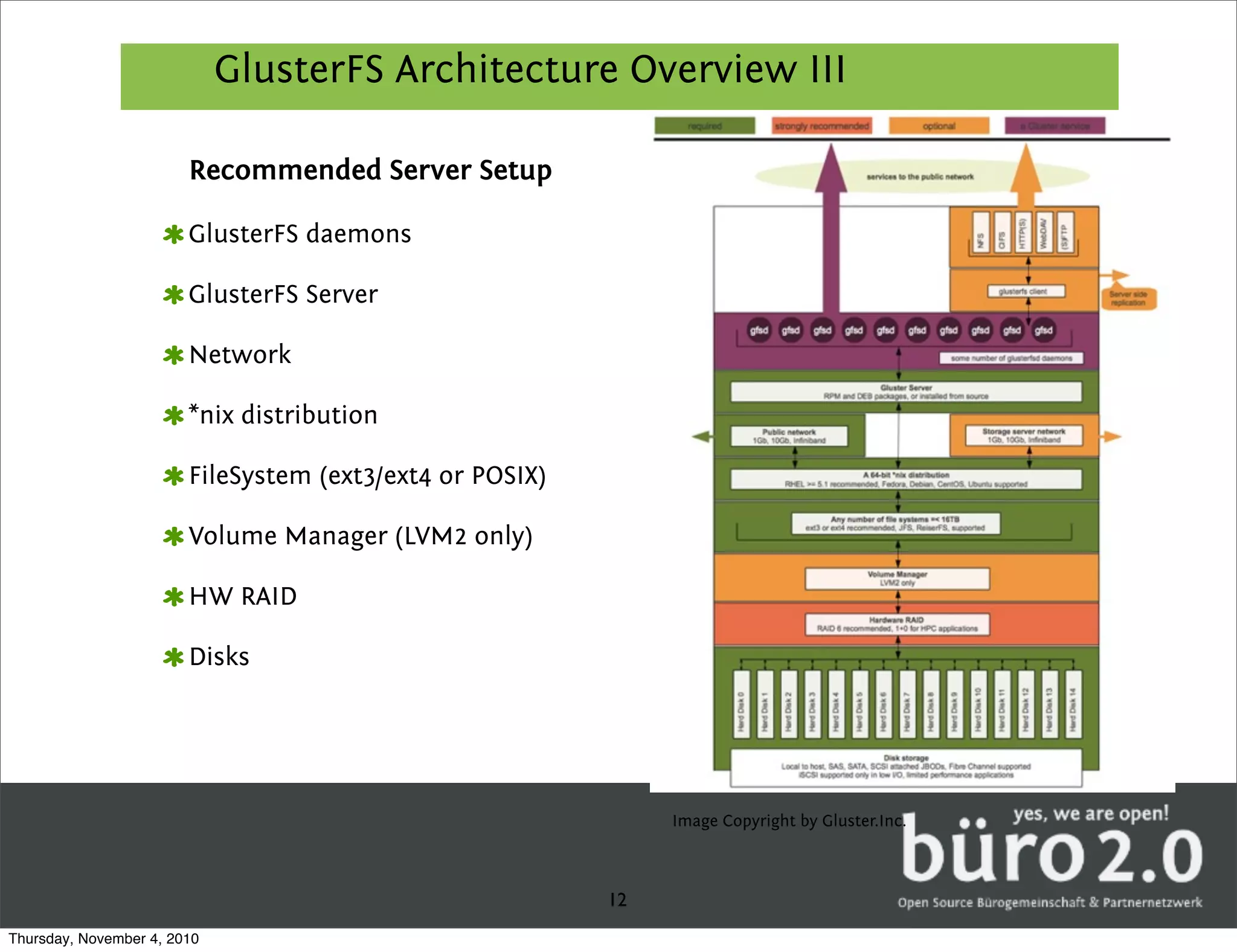

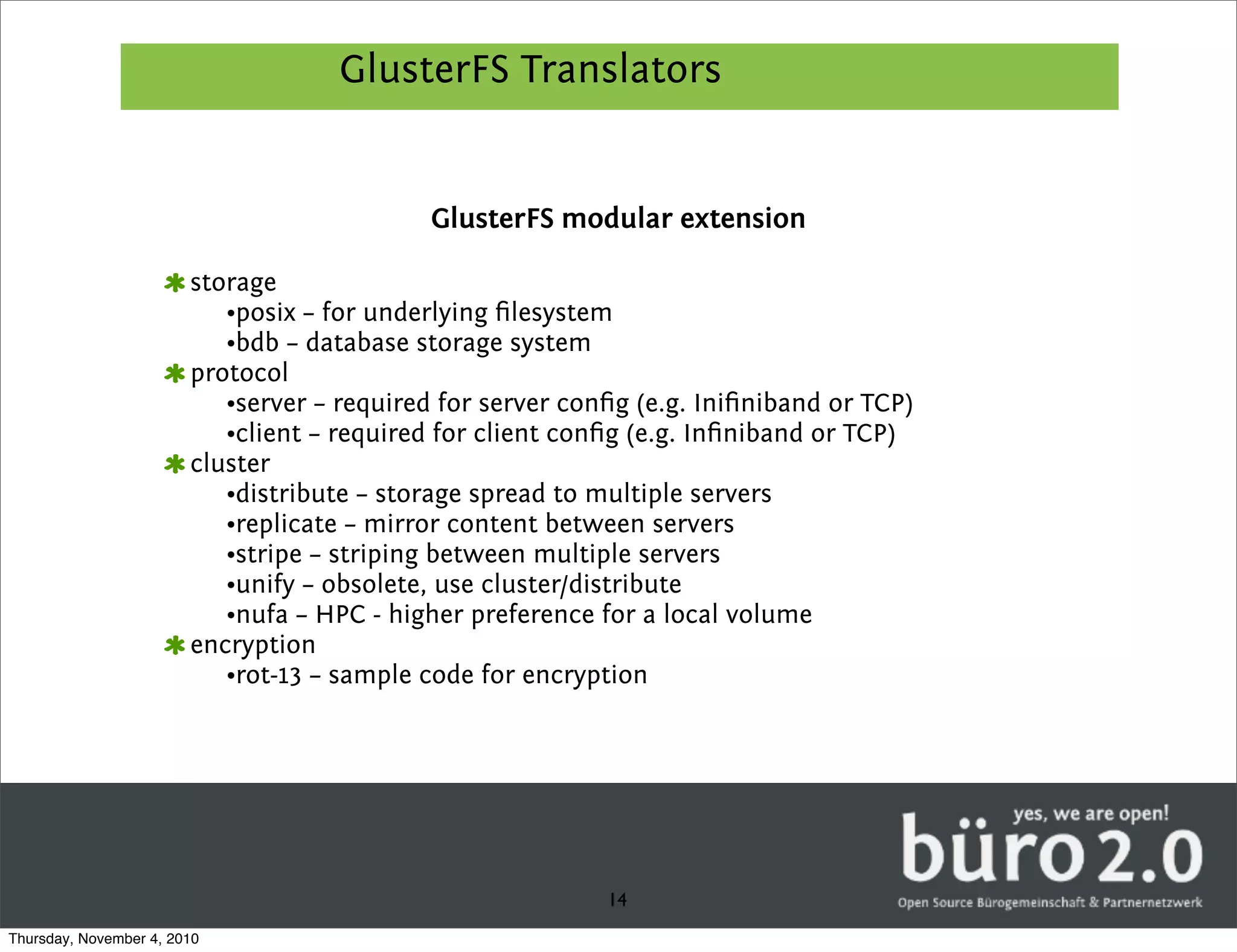














GlusterFS is a distributed replicated parallel file system that allows files to be striped, replicated, and distributed across servers for high performance and high availability. It has a fully distributed architecture without a metadata server and uses FUSE for mounting volumes. GlusterFS distributes data across multiple servers and can replicate files on different servers for redundancy. It uses configurable translators for storage, protocols, clustering, encryption and other features.


































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















