Download as PDF, PPTX







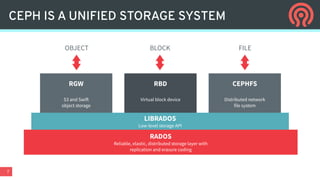



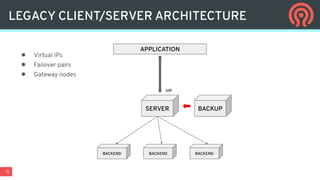
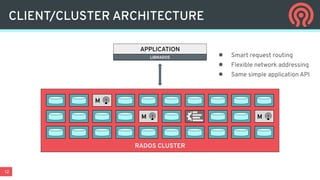
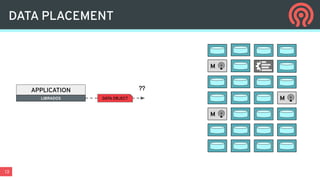
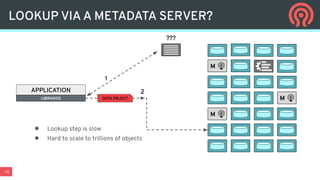
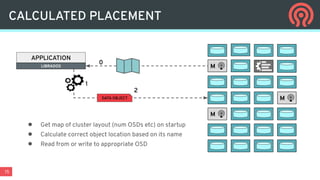
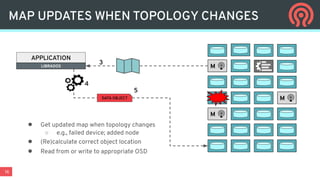

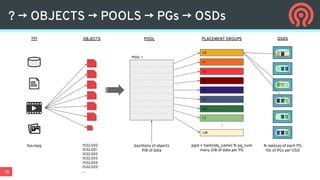

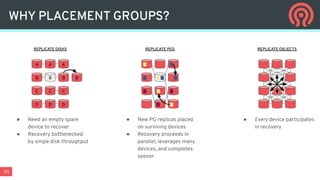





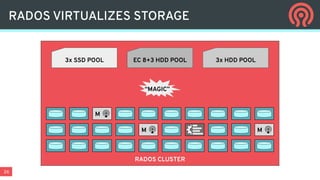
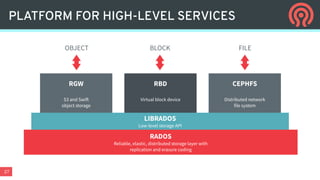


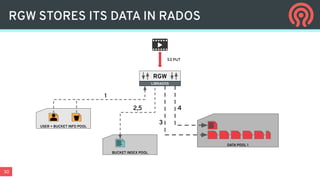
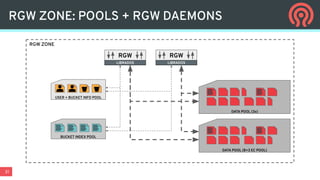
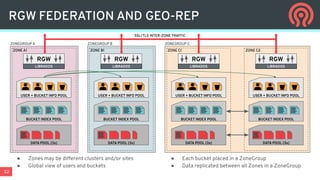




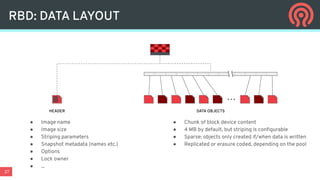
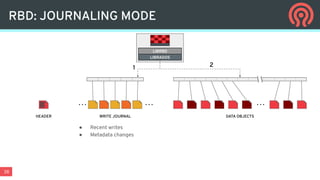
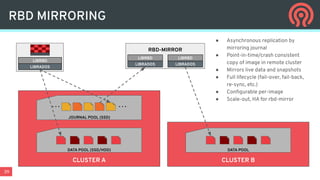


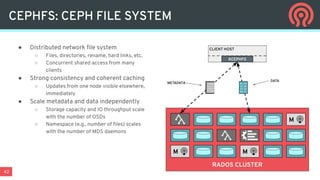

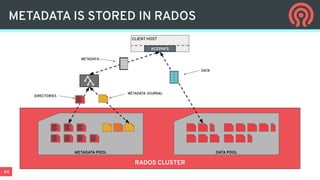
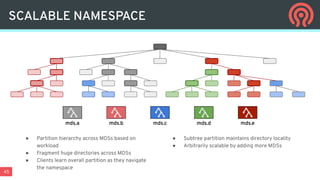

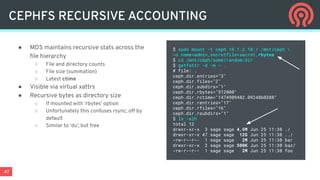

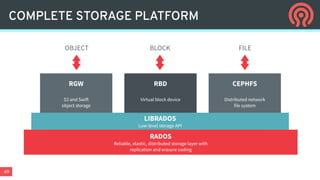











Ceph is an open-source distributed storage platform that provides file, block, and object storage in a single unified system. It uses a distributed storage component called RADOS that provides reliable and scalable storage through data replication and erasure coding across commodity hardware. Higher-level services like RBD provide virtual block devices, RGW provides S3-compatible object storage, and CephFS provides a distributed file system.












![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)








































