Download as PDF, PPTX



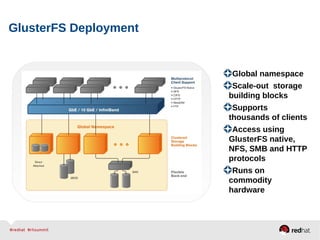


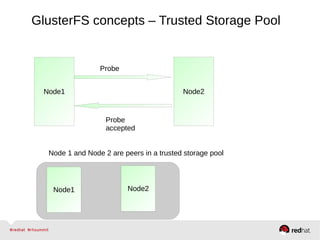
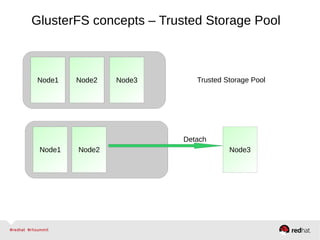
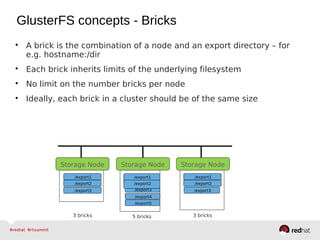

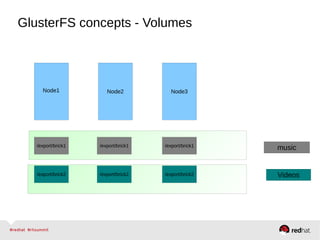



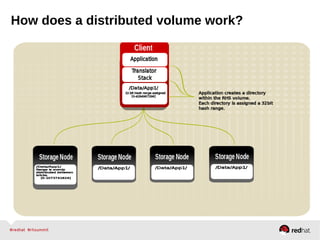
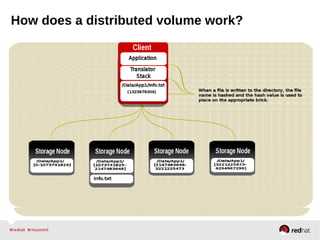
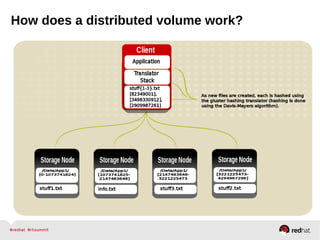

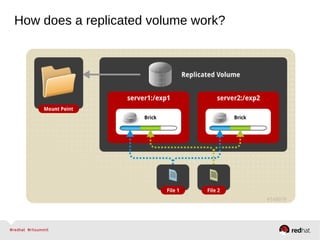
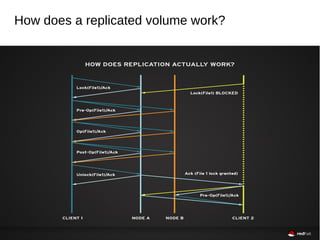

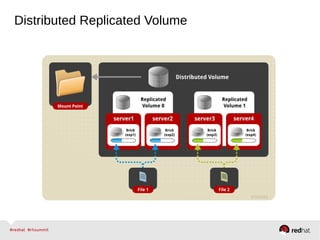


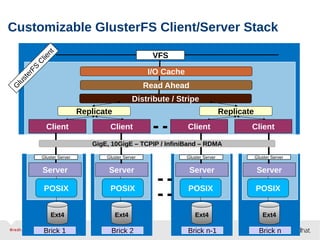


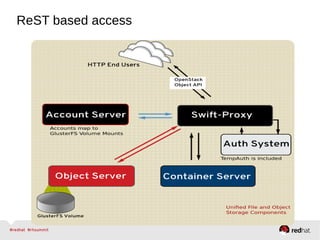
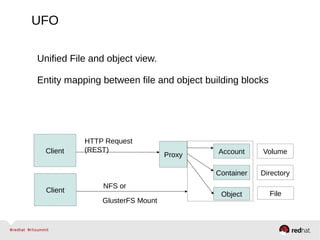
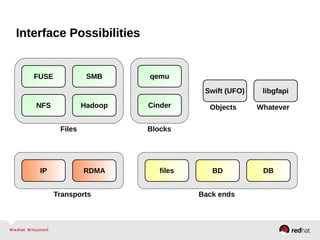
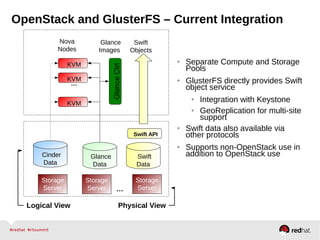
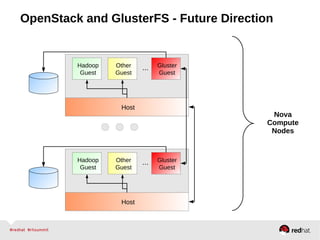





GlusterFS is an open-source networked file system that provides scalable, distributed storage for OpenStack. It aggregates disk storage from multiple servers into a single global namespace that is accessible from anywhere. GlusterFS uses a distributed hashing technique to spread files across servers and can be configured for replication or erasure coding for redundancy. It integrates with OpenStack components like Swift, Cinder, and Glance to provide block, object, and file-level storage services for virtual machines. Future integration plans include a Cinder-like file service (FaaS) and support for Windows and NFS shares.






































![[OpenStack Day in Korea] Keynote#2 - Bringing OpenStack to the Enterprise Dat...](https://cdn.slidesharecdn.com/ss_thumbnails/koreaopenstackdubuque20140218r7-140218091223-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




































































