Download as PDF, PPTX



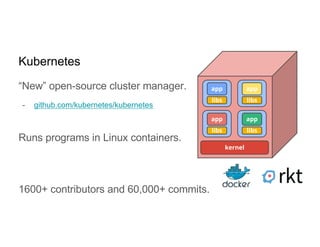





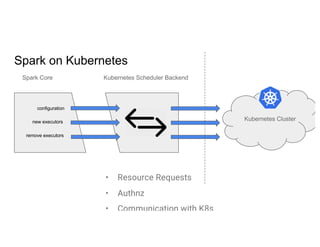
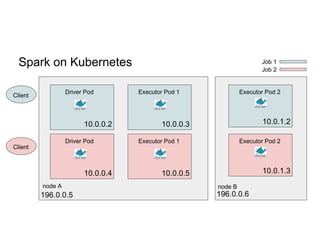
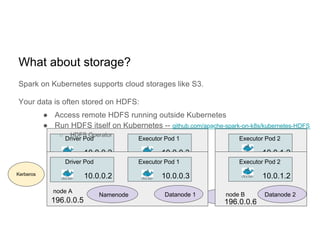



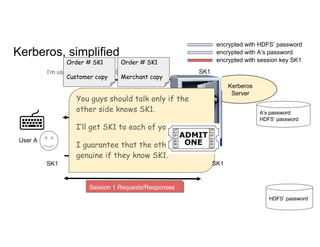

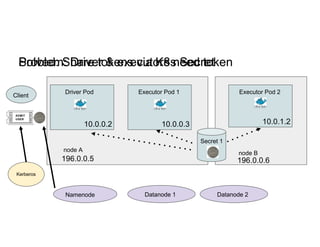

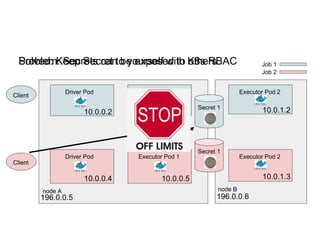



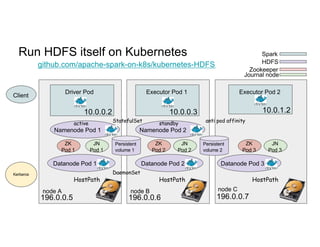
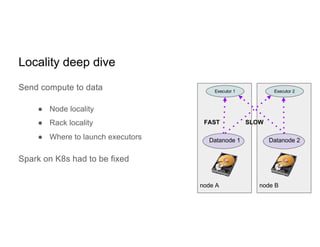
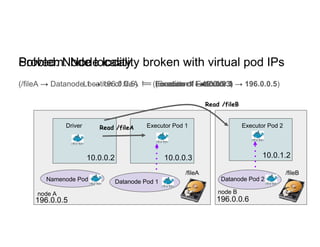
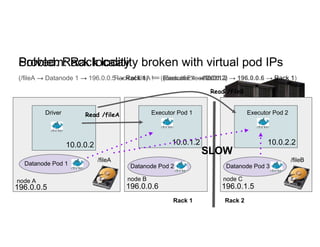

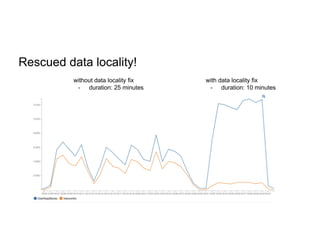


This document discusses running Apache Spark jobs on Kubernetes that access data from secure HDFS clusters. It begins with an introduction to Kubernetes and running big data workloads on it. It then demonstrates running a Spark job on Kubernetes that accesses a Kerberized HDFS cluster. The document delves into details of securing HDFS access and running HDFS itself on Kubernetes. It discusses how data locality was broken when running Spark on Kubernetes originally and how it was fixed to improve performance.




![[오픈소스컨설팅] EFK Stack 소개와 설치 방법](https://cdn.slidesharecdn.com/ss_thumbnails/elasticstack-210712042246-thumbnail.jpg?width=640&height=640&fit=bounds)






![[GuideDoc] Deploy EKS thru eksctl - v1.22_v0.105.0.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/guidedocdeployeksthrueksctl-v1-220715080545-0fb340c1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[pgday.Seoul 2022] PostgreSQL with Google Cloud](https://cdn.slidesharecdn.com/ss_thumbnails/pgday-postgresqlwithgooglecloud-221114013605-5def484f-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DSC Europe 22] Overview of the Databricks Platform - Petar Zecevic](https://cdn.slidesharecdn.com/ss_thumbnails/petarzecevic-databricksoverview-221130080703-c60d93de-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Spark Summit 2017 NA] Apache Spark on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkonkubernetespublic1-170929072840-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)





