Downloaded 13 times










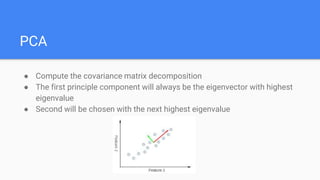


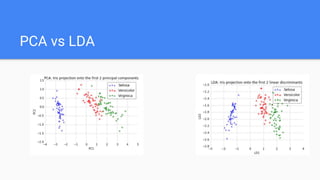



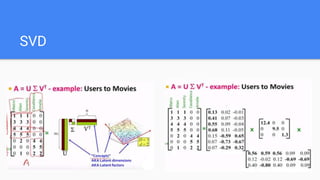



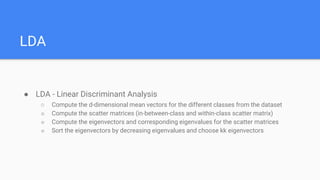
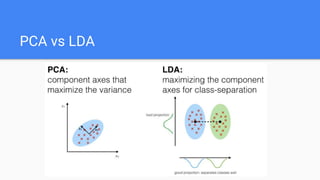

The document provides an overview of dimensionality reduction techniques, including PCA, SVD, and LDA. PCA uses linear projections to reduce dimensions while preserving variance in the data. It computes eigenvectors of the covariance matrix. SVD is similar to PCA but works directly with the data matrix rather than the covariance matrix. LDA aims to maximize class separability during dimensionality reduction for classification tasks. It computes within-class and between-class scatter matrices. While PCA maximizes variance, LDA maximizes class discrimination.






























![[Webinar] Following the Agile Footprint - zekeLabs](https://cdn.slidesharecdn.com/ss_thumbnails/followingtheagilefootprint-webinar-200130092825-thumbnail.jpg?width=640&height=640&fit=bounds)




































