[DL輪読会]Estimating Predictive Uncertainty via Prior Networks
1.
1
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
Estimating Predictive Uncertainty via Prior Networks
Hirono Okamoto, Matsuo Lab
2.
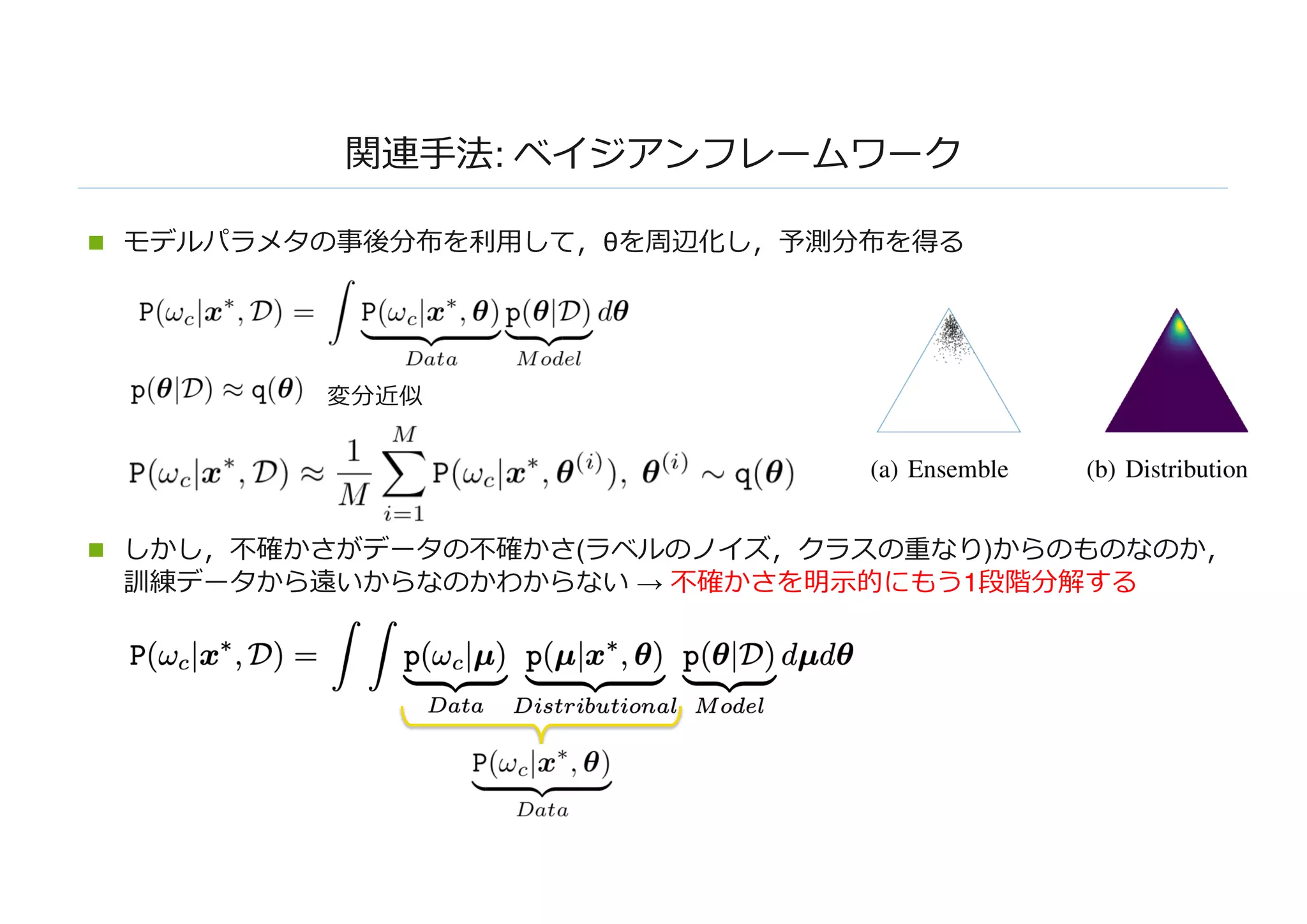
書誌情報: Estimating PredictiveUncertainty via Prior Networks
n NIPS 2018 accepted
n 著者: Andrey Malinin, Mark Gales (ケンブリッジ⼤学)
n 概要:
n 不確かさには三つの種類があり,データの不確かさ,モデルの不確かさ,分布の不確かさが存在する
n その中でも,分布の不確かさが⼤きいものが,Out of Distributionであると仮定した
n 分布の不確かさの違いを提案⼿法で推定し,OoDを検知する
あるデータの不確かさは
三つの不確かさで構成される
(a)はどのクラスに属すか⾃信をもって
予測している
(b)はどのクラスに属すかわからないという
意味で不確かさが⼤きいが,OODではない
(c)はどのような確率になるかすらわからない
ことを⽰しているため,OODである
カテゴリカル分布のパラメタμの分布の不確かさの違い
3.
背景: 異常検知の基本的な2つの問題設定
n 1:⼀つのカテゴリの正常クラスのサンプルのみ訓練データとして与えられ,新しくサンプル
が与えられたときに異常サンプルかどうかを分類する.
n 2: 複数のカテゴリの正常クラスのサンプルのみ訓練データとして与えられ,新しいカテゴリ
のサンプルが与えられたときに異常サンプルかどうかを分類する
この論⽂では2を解いている
訓練データ(すべて正常データ) テストデータ
正常 異常
訓練データ(すべて正常データで⽝カテゴリと⿃カテゴリが存在する) テストデータ
正常 異常
4.
背景: 不確かさには三つの種類がある
n 三つの不確かさを定義する
n(1) Model uncertainty: 訓練データが与えられたときのモデルパラメタを推定するときの不確かさ
n 訓練データが増加すれば減る
n (2) Data uncertainty: 避けられない不確かさ
n Ex) クラスの重なり,ラベルのノイズ
n known-unknown: モデルはデータを理解しているが,分類するのが難しい
n (3) Distributional uncertainty: 訓練データとテストデータの分布のミスマッチからくる不確かさ
n unknown-unknown: モデルはテストデータが理解できず,⾃信をもって予測することが困難
n active learningの指標にも使える
n 論⽂の貢献
n これまでのアプローチでは,これらの不確かさを混合してしまっていたため,不確かさの獲得が
不⼗分であることを述べた
n 提案⼿法であるPrior Networks(PNs)はdistributional uncertaintyを扱うことが可能で,OODの検出
に有効であることを⽰した
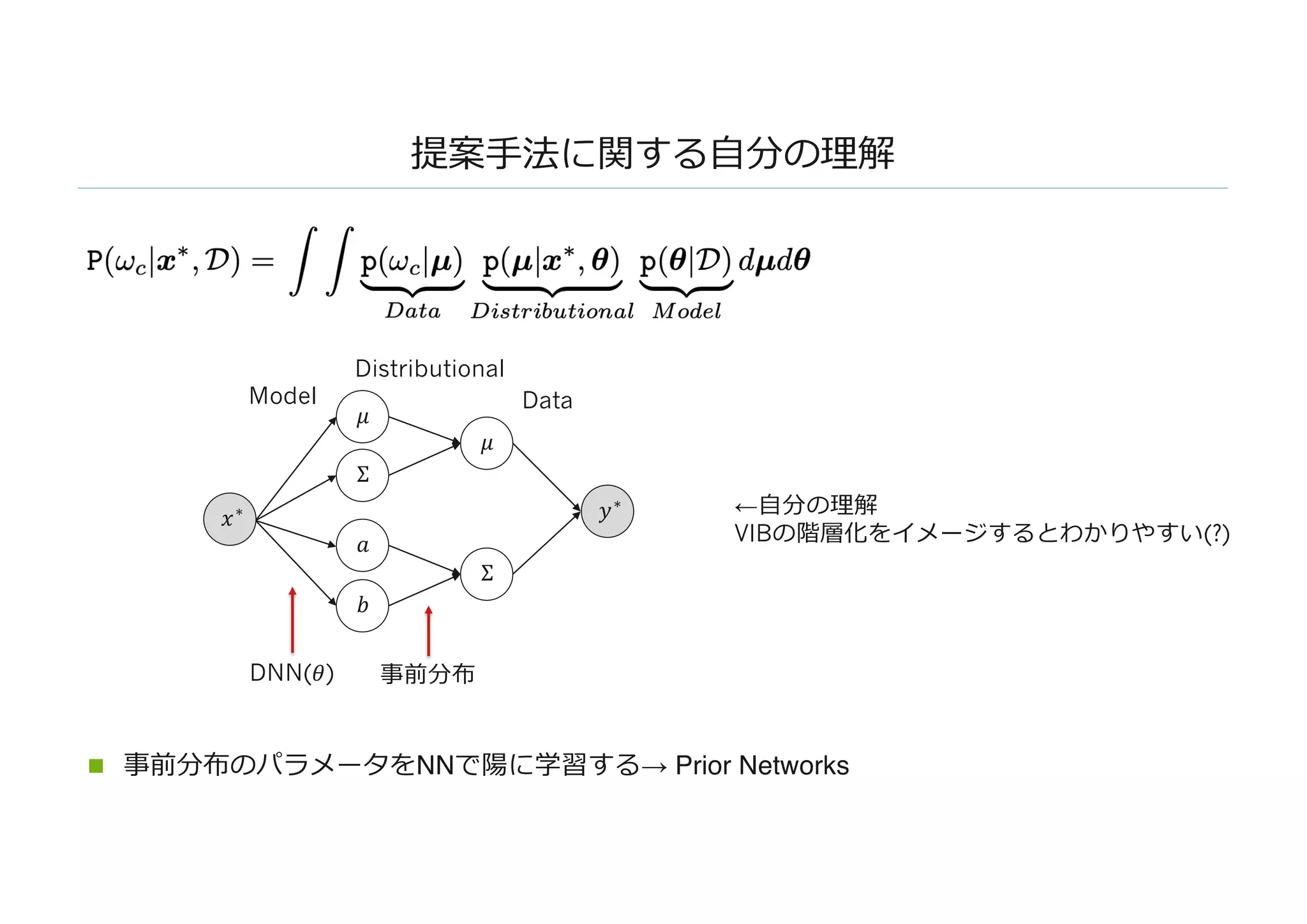
提案⼿法: Prior Networks
n分布の違いによる不確かさをニューラルネットワークを使った事前分布(Prior)で表現する
n 事前分布はディリクレ分布で,そのハイパラをNNで表現する
n μを周辺化すると普通のソフトマックス分類の式が導かれる
𝑥∗
𝑦∗
𝛼 𝜇
[0, 1, 0][0.05, 0.9, 0.05]
8.
提案⼿法: Prior Networksの学習⽅法
nIn distributionのときは尖った分布に近づけたい
n はハイパラとして, とする
n Out of distributionのときは平たい分布に近づけたい
n すべてのクラスで とする
n ただし,OODはデータとして⼊⼿できないので,
合成データか適当な他のデータセットを使う
n →イケてない…
PNsPNs
平たい分布
尖った分布 OoDのときIDのとき
9.
評価⼿法: 不確かさを定量的に図る4つの指標
n Max.P:ソフトマックス値の最⼤値を利⽤
n ソフトマックス値の最⼤値が⼩さいことを不確かさの⼤きさとしている
n Ent: 予測分布のエントロピーを利⽤
n M.I: ラベル y とパラメータθの相互情報量を利⽤
n D.Ent: 微分エントロピーの利⽤
n μのエントロピーを測る.ディリクレ分布がflatになるときに最⼤化する
10.
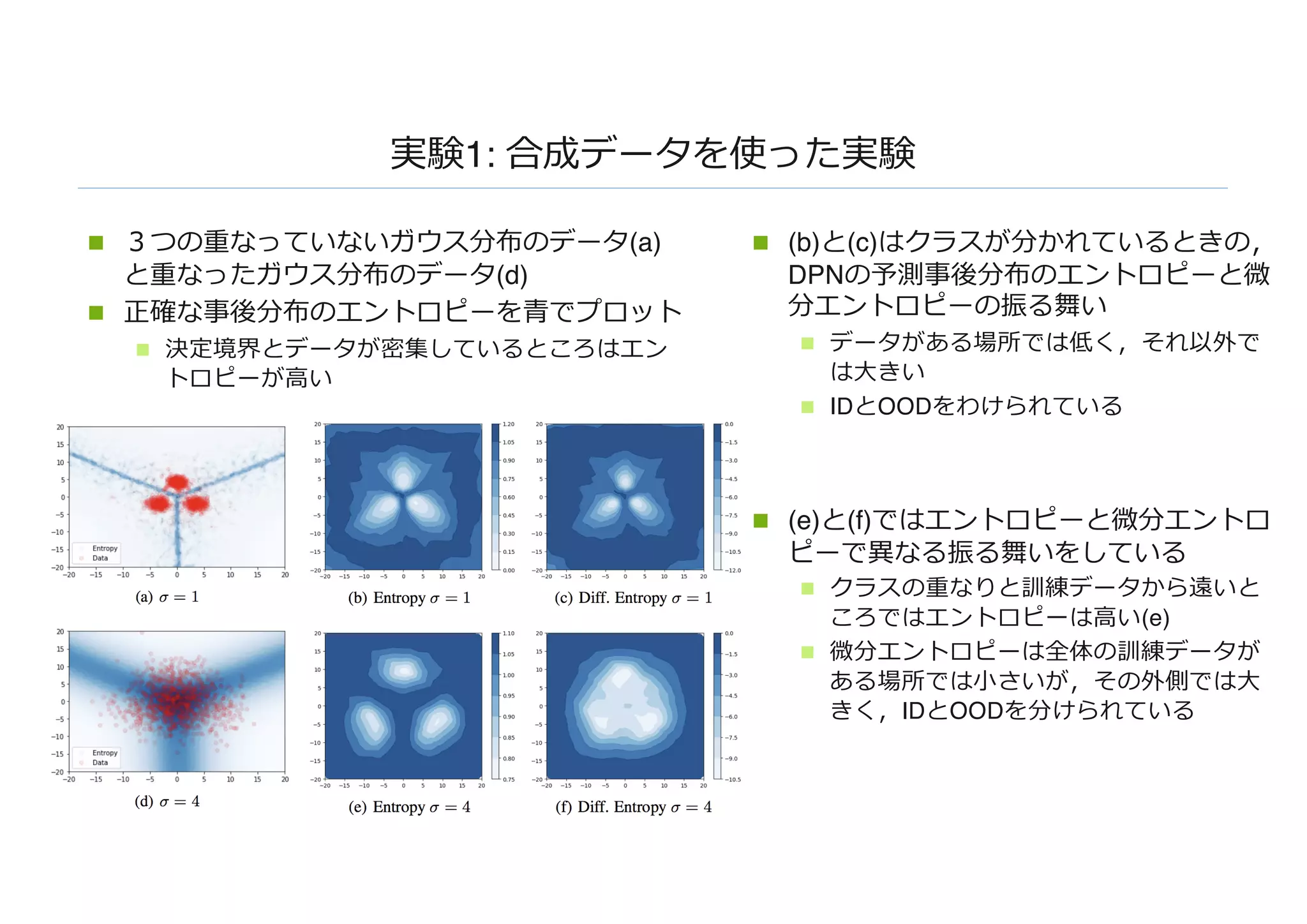
実験1: 合成データを使った実験
n 3つの重なっていないガウス分布のデータ(a)
と重なったガウス分布のデータ(d)
n正確な事後分布のエントロピーを⻘でプロット
n 決定境界とデータが密集しているところはエン
トロピーが⾼い
n (b)と(c)はクラスが分かれているときの,
DPNの予測事後分布のエントロピーと微
分エントロピーの振る舞い
n データがある場所では低く,それ以外で
は⼤きい
n IDとOODをわけられている
n (e)と(f)ではエントロピーと微分エントロ
ピーで異なる振る舞いをしている
n クラスの重なりと訓練データから遠いと
ころではエントロピーは⾼い(e)
n 微分エントロピーは全体の訓練データが
ある場所では⼩さいが,その外側では⼤
きく,IDとOODを分けられている
11.
実験2: データセット
n データセット
nIn distribution(ID)
n MNIST
n CIFAR-10
n Out of distribution(OoD)
n Omniglot
n SVHN
n LSUN
n TinyImageNet (TIM)
n Dirichlet Prior Network (DPN) に対する⽐較⼿法
n 普通のDNN
n ソフトマックスの最⼤値やエントロピーを利⽤すれば,不確かさを⼀応求めることができる
n Monte-Carlo Dropout (MCDP)
n モデルのパラメータθの分布が求まるので,これとyの相互情報量を不確かさの指標とすることができる
あるデータセットを正常(In distribution)とし,
それ以外のデータセットは異常(Out of distribution)とする
12.
実験2: 評価⼿法について
n AUROC(areaunder an ROC curve)とAUPR (area under a PR curve)を使う
図・表 引⽤︓http://www.randpy.tokyo/entry/roc_auc
AUROC
偽陽性率
真陽性率
13.
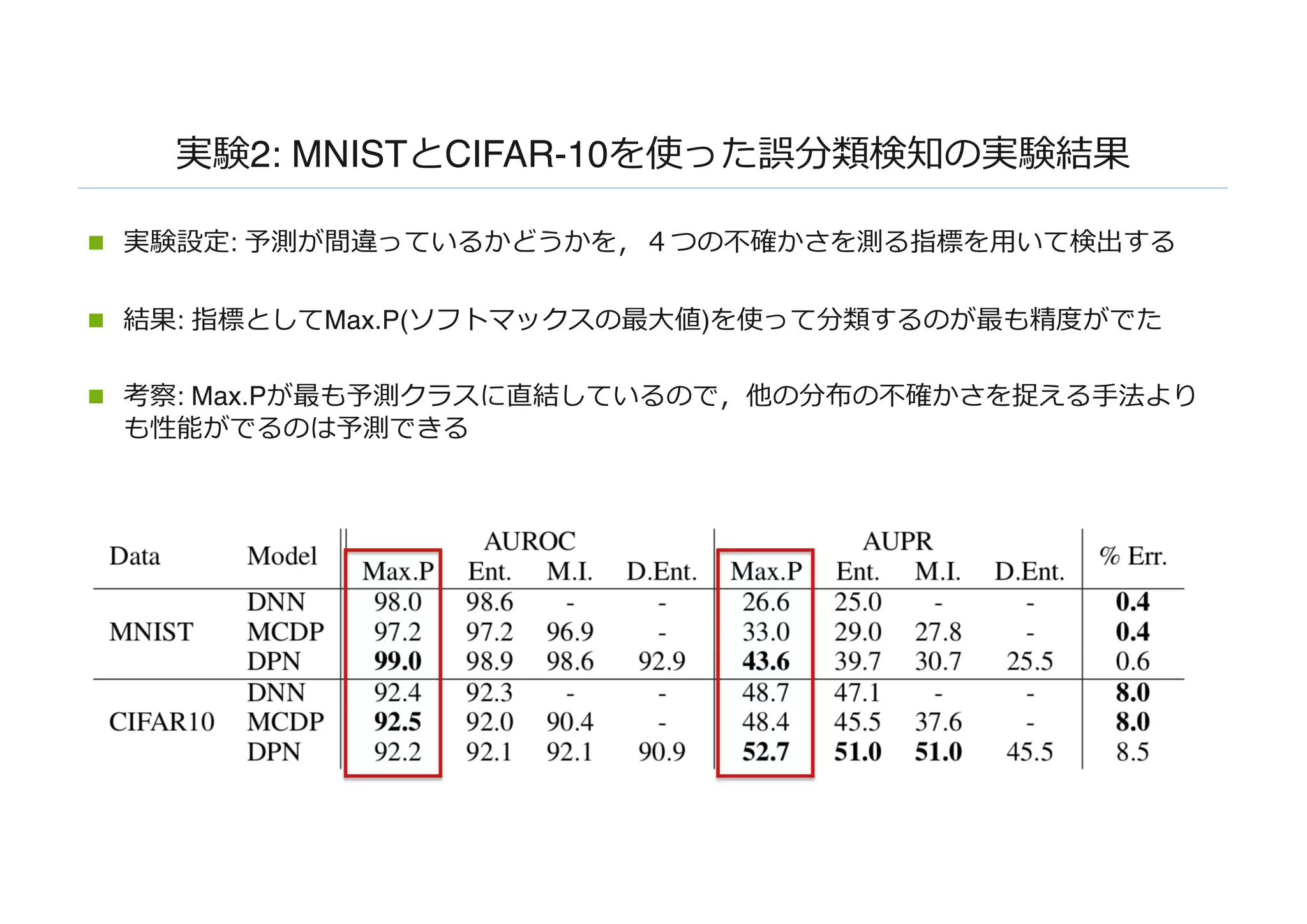
実験2: MNISTとCIFAR-10を使った誤分類検知の実験結果
n 実験設定:予測が間違っているかどうかを,4つの不確かさを測る指標を⽤いて検出する
n 結果: 指標としてMax.P(ソフトマックスの最⼤値)を使って分類するのが最も精度がでた
n 考察: Max.Pが最も予測クラスに直結しているので,他の分布の不確かさを捉える⼿法より
も性能がでるのは予測できる
14.
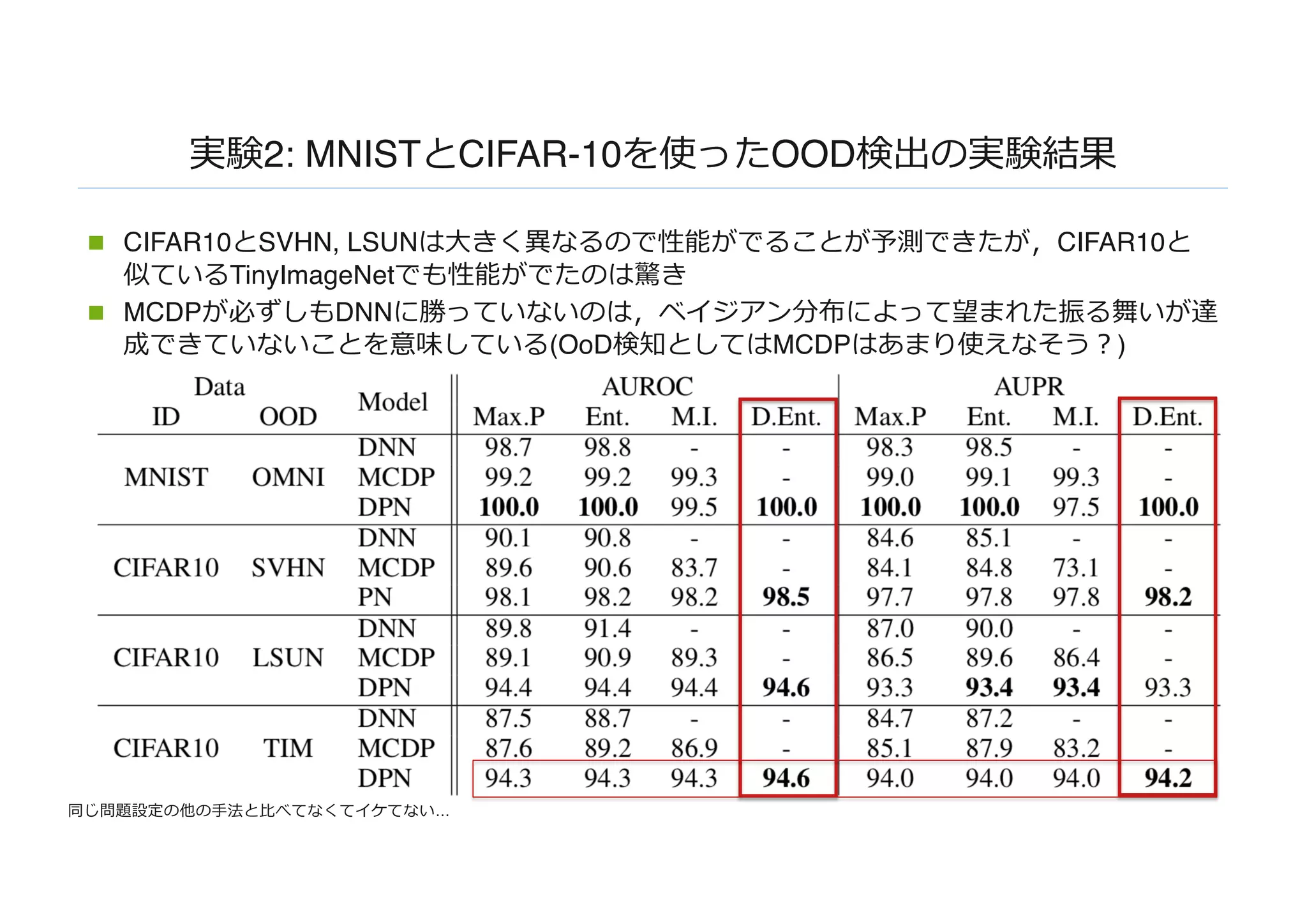
実験2: MNISTとCIFAR-10を使ったOOD検出の実験結果
n CIFAR10とSVHN,LSUNは⼤きく異なるので性能がでることが予測できたが,CIFAR10と
似ているTinyImageNetでも性能がでたのは驚き
n MCDPが必ずしもDNNに勝っていないのは,ベイジアン分布によって望まれた振る舞いが達
成できていないことを意味している(OoD検知としてはMCDPはあまり使えなそう︖)
同じ問題設定の他の⼿法と⽐べてなくてイケてない…
15.
結論・今後の課題
n まとめ
n 予測分散を利⽤したこれまでの研究の限界を⽰し,DistributionalUncertaintyを利⽤してOODを検
出することに成功した
n 新規⼿法Prior Networks(PNs)を提案し,3つの不確かさを別々に扱うことができた
n DPNはMC Dropoutや普通のDNNを使った⽅法よりもdistributional uncertaintyを正確に推定するこ
とができた
n Differential entropyは特にどのクラスに属すかが不明瞭なときに,OODの検出として最も良い指標
であった
n 今後の研究
n 他のCVタスク,NLP,機械翻訳,⾔語認知,強化学習にも応⽤する
n 回帰タスクのためのPrior Networksを開発する
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Estimating Predictive Uncertainty via Prior Networks
Hirono Okamoto, Matsuo Lab](https://image.slidesharecdn.com/estimatingpredictiveuncertaintyviapriornetworks-190628002736/75/DL-Estimating-Predictive-Uncertainty-via-Prior-Networks-1-2048.jpg)



![提案⼿法: Prior Networks
n 分布の違いによる不確かさをニューラルネットワークを使った事前分布(Prior)で表現する
n 事前分布はディリクレ分布で,そのハイパラをNNで表現する
n μを周辺化すると普通のソフトマックス分類の式が導かれる
𝑥∗
𝑦∗
𝛼 𝜇
[0, 1, 0][0.05, 0.9, 0.05]](https://image.slidesharecdn.com/estimatingpredictiveuncertaintyviapriornetworks-190628002736/75/DL-Estimating-Predictive-Uncertainty-via-Prior-Networks-7-2048.jpg)






![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]A Simple Unified Framework for Detecting Out-of-Distribution Samples a...](https://cdn.slidesharecdn.com/ss_thumbnails/20181005misono2-181009052706-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Deep Learning 第15章 表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearning15-180601023904-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Energy-based generative adversarial networks](https://cdn.slidesharecdn.com/ss_thumbnails/energy-basedgenerativeadversarialnetworks-171030102253-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]DropBlock: A regularization method for convolutional networks](https://cdn.slidesharecdn.com/ss_thumbnails/dlyokota20190222-190222002832-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Attentive neural processes](https://cdn.slidesharecdn.com/ss_thumbnails/attentiveneuralprocesses-181225051145-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DLHacks]StyleGANとBigGANのStyle mixing, morphing](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks0805-190815052222-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Bayesian Uncertainty Estimation for Batch Normalized Deep Networks](https://cdn.slidesharecdn.com/ss_thumbnails/190719dlver2-190719035734-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Ensemble Distribution Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/ensembledistributiondistillation-200110020132-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)



















