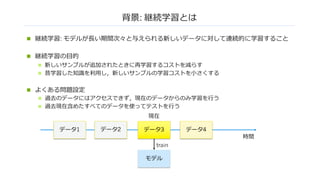
背景: 継続学習とは
n 継続学習:モデルが⻑い期間次々と与えられる新しいデータに対して連続的に学習すること
n 継続学習の⽬的
n 新しいサンプルが追加されたときに再学習するコストを減らす
n 昔学習した知識を利⽤し,新しいサンプルの学習コストを⼩さくする
n よくある問題設定
n 過去のデータにはアクセスできず,現在のデータからのみ学習を⾏う
n 過去現在含めたすべてのデータを使ってテストを⾏う
データ1 データ3
モデル
データ4
train
時間
現在
データ2
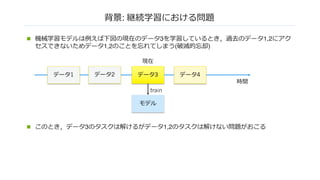
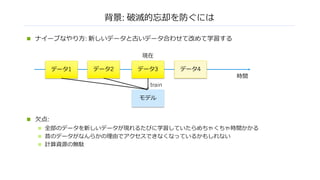
背景: 破滅的忘却を防ぐには
n ナイーブなやり⽅:新しいデータと古いデータ合わせて改めて学習する
n ⽋点:
n 全部のデータを新しいデータが現れるたびに学習していたらめちゃくちゃ時間かかる
n 昔のデータがなんらかの理由でアクセスできなくなっているかもしれない
n 計算資源の無駄
データ3
モデル
train
時間
現在
データ1 データ2 データ4
破滅的忘却を防ぐためのアプローチ例
n 昔の知識を失わないようにパラメタをupdateする
n Learningwithout Forgetting
n Overcoming catastrophic forgetting in neural networks
n variational continual learning
n タスクが増えたときモデル構造を追加する
n Progressive Neural Networks
n 部分的に昔のサンプルを使う,もしくは⽣成サンプルを使って学習する
n iCaRL: Incremental Classifier and Representation Learning
n Continual Learning with Deep Generative Replay
n Continual Unsupervised Representation Learning
7.
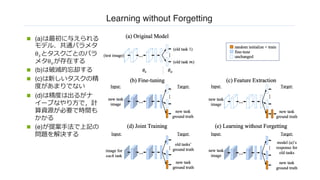
Learning without Forgetting
n(a)は最初に与えられる
モデル.共通パラメタ
θ!とタスクごとのパラ
メタθ"が存在する
n (b)は破滅的忘却する
n (c)は新しいタスクの精
度があまりでない
n (d)は精度は出るがナ
イーブなやり⽅で,計
算資源が必要で時間も
かかる
n (e)が提案⼿法で上記の
問題を解決する
8.
Learning without Forgetting
nロス: distillation loss + cross entropy loss + weight decay
n 1項⽬は⼊⼒を新しいデータとして,昔のパラメタをつかった
出⼒に現在のパラメタの出⼒を近づけようとする項
n 利点: 昔のデータを利⽤する必要がない
9.
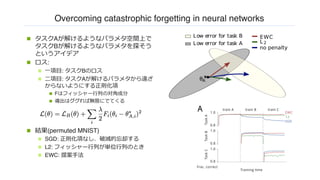
Overcoming catastrophic forgettingin neural networks
n タスクAが解けるようなパラメタ空間上で
タスクBが解けるようなパラメタを探そう
というアイデア
n ロス:
n ⼀項⽬: タスクBのロス
n ⼆項⽬: タスクAが解けるパラメタから遠ざ
からないようにする正則化項
n Fはフィッシャー⾏列の対⾓成分
n 導出はググれば無限にでてくる
n 結果(permuted MNIST)
n SGD: 正則化項なし.破滅的忘却する
n L2: フィッシャー⾏列が単位⾏列のとき
n EWC: 提案⼿法
10.
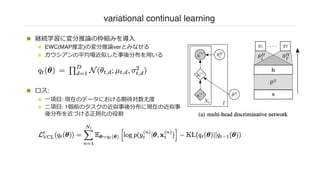
variational continual learning
n継続学習に変分推論の枠組みを導⼊
n EWC(MAP推定)の変分推論verとみなせる
n ガウシアンの平均場近似した事後分布を⽤いる
n ロス:
n ⼀項⽬: 現在のデータにおける期待対数尤度
n ⼆項⽬: 1個前のタスクの近似事後分布に現在の近似事
後分布を近づける正則化の役割
11.
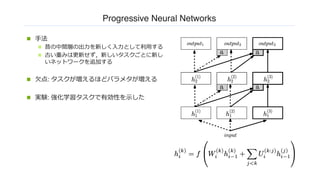
Progressive Neural Networks
n⼿法
n 昔の中間層の出⼒を新しく⼊⼒として利⽤する
n 古い重みは更新せず,新しいタスクごとに新し
いネットワークを追加する
n ⽋点: タスクが増えるほどパラメタが増える
n 実験: 強化学習タスクで有効性を⽰した
12.
iCaRL: Incremental Classifierand Representation Learning
n 問題設定:
n 新しいクラスのデータが次々と追加される
n 過去のデータをクラスごとにいくつか保持
n クラスごとに平均に近いサンプルを保持
n ロス:
n 現在のデータ: 普通にcrossentropy loss
n 過去のデータ: distillation loss
n 前のデータの出⼒に現在の出⼒を近づけようと
する正則化の役割
13.
iCaRL: Incremental Classifierand Representation Learning
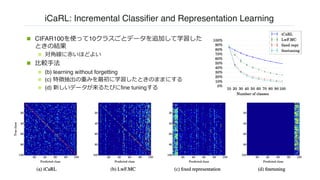
n CIFAR100を使って10クラスごとデータを追加して学習した
ときの結果
n 対⾓線に⾚いほどよい
n ⽐較⼿法
n (b) learning without forgetting
n (c) 特徴抽出の重みを最初に学習したときのままにする
n (d) 新しいデータが来るたびにfine tuningする
14.
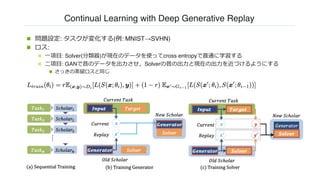
Continual Learning withDeep Generative Replay
n 問題設定: タスクが変化する(例: MNIST→SVHN)
n ロス:
n ⼀項⽬: Solver(分類器)が現在のデータを使ってcross entropyで普通に学習する
n ⼆項⽬: GANで昔のデータを出⼒させ,Solverの昔の出⼒と現在の出⼒を近づけるようにする
n さっきの蒸留ロスと同じ
15.
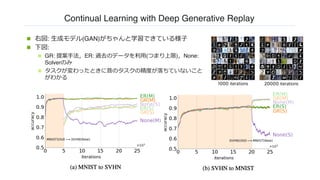
Continual Learning withDeep Generative Replay
n 右図: ⽣成モデル(GAN)がちゃんと学習できている様⼦
n 下図:
n GR: 提案⼿法,ER: 過去のデータを利⽤(つまり上限),None:
Solverのみ
n タスクが変わったときに昔のタスクの精度が落ちていないこと
がわかる
16.
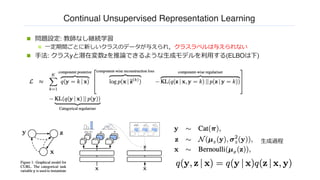
Continual Unsupervised RepresentationLearning
n 問題設定: 教師なし継続学習
n ⼀定期間ごとに新しいクラスのデータが与えられ,クラスラベルは与えられない
n ⼿法: クラスyと潜在変数zを推論できるような⽣成モデルを利⽤する(ELBOは下)
⽣成過程
17.
Continual Unsupervised RepresentationLearning
n ⼿法続き: Dynamic expansion
n ELBOの閾値を決め,それを下回ったら新しいクラスのデータとする
n 新しいクラスのパラメタは既存のクラスのパラメタのうち⼀番確率が⾼いものを初期値として利
⽤し,改めて新しいデータで学習する
n ⼿法続き: mixture generative replay
n Deep Generative Relayのように,過去のサンプルを⽣成し,現在のデータと⼀緒に学習すること
で破滅的忘却を防ぐ
右図はだんだんいろんなクラスのデータを
サンプリングできるようになっている様⼦






![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)











![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)





































