Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
PPTX, PDF
4,942 views
[DL輪読会]End-to-End Object Detection with Transformers
2020/05/29 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
9
Save
Share
Embed
Embed presentation
Download
Downloaded 44 times
1
/ 31
2
/ 31
3
/ 31
4
/ 31
5
/ 31
6
/ 31
7
/ 31
8
/ 31
9
/ 31
10
/ 31
11
/ 31
12
/ 31
13
/ 31
14
/ 31
15
/ 31
16
/ 31
17
/ 31
18
/ 31
19
/ 31
20
/ 31
21
/ 31
22
/ 31
23
/ 31
24
/ 31
25
/ 31
26
/ 31
27
/ 31
28
/ 31
29
/ 31
30
/ 31
31
/ 31
More Related Content
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
PDF
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
PDF
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
PDF
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
by
MasanoriSuganuma
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
PPTX
Semi supervised, weakly-supervised, unsupervised, and active learning
by
Yusuke Uchida
PPTX
モデル高速化百選
by
Yusuke Uchida
PPTX
[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation
by
Deep Learning JP
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
実装レベルで学ぶVQVAE
by
ぱんいち すみもと
RAFT: Recurrent All-Pairs Field Transforms for Optical Flow
by
MasanoriSuganuma
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
Semi supervised, weakly-supervised, unsupervised, and active learning
by
Yusuke Uchida
モデル高速化百選
by
Yusuke Uchida
[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation
by
Deep Learning JP
What's hot
PDF
最適輸送の解き方
by
joisino
PDF
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
PDF
Deep Learningによる超解像の進歩
by
Hiroto Honda
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PPTX
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
PPTX
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
PPTX
[DL輪読会]Graph R-CNN for Scene Graph Generation
by
Deep Learning JP
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PDF
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
PPTX
[DL輪読会]Object-Centric Learning with Slot Attention
by
Deep Learning JP
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
PDF
【チュートリアル】コンピュータビジョンによる動画認識
by
Hirokatsu Kataoka
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PDF
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
PDF
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
by
SSII
PPTX
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
PDF
CVPR 2019 速報
by
cvpaper. challenge
PPTX
論文紹介: Fast R-CNN&Faster R-CNN
by
Takashi Abe
PPTX
モデルアーキテクチャ観点からの高速化2019
by
Yusuke Uchida
最適輸送の解き方
by
joisino
[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
by
Deep Learning JP
Deep Learningによる超解像の進歩
by
Hiroto Honda
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
by
Deep Learning JP
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
[DL輪読会]Graph R-CNN for Scene Graph Generation
by
Deep Learning JP
GAN(と強化学習との関係)
by
Masahiro Suzuki
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
[DL輪読会]Object-Centric Learning with Slot Attention
by
Deep Learning JP
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
by
SSII
【チュートリアル】コンピュータビジョンによる動画認識
by
Hirokatsu Kataoka
Transformer メタサーベイ
by
cvpaper. challenge
[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...
by
Deep Learning JP
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
by
SSII
これからの Vision & Language ~ Acadexit した4つの理由
by
Yoshitaka Ushiku
CVPR 2019 速報
by
cvpaper. challenge
論文紹介: Fast R-CNN&Faster R-CNN
by
Takashi Abe
モデルアーキテクチャ観点からの高速化2019
by
Yusuke Uchida
Similar to [DL輪読会]End-to-End Object Detection with Transformers
PPTX
2020 08 05_dl_DETR
by
harmonylab
PDF
物体検知(Meta Study Group 発表資料)
by
cvpaper. challenge
PDF
DeepLearningDay2016Summer
by
Takayoshi Yamashita
PDF
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
PDF
IEEE ITSS Nagoya Chapter
by
Takayoshi Yamashita
PDF
CVPR2018論文紹介「Pseudo Mask Augmented Object Detection」
by
諒介 荒木
PDF
Efficient Det
by
TakeruEndo
PDF
【2015.05】cvpaper.challenge@CVPR2015
by
cvpaper. challenge
PDF
人が注目する箇所を当てるSaliency Detectionの最新モデル UCNet(CVPR2020)
by
Shintaro Yoshida
PPTX
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東)
by
Tenki Lee
PDF
【2016.02】cvpaper.challenge2016
by
cvpaper. challenge
PDF
Domain Adaptive Faster R-CNN for Object Detection in the Wild 論文紹介
by
Tsukasa Takagi
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
PDF
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monoc...
by
Kazuyuki Miyazawa
PPTX
[DL輪読会]Objects as Points
by
Deep Learning JP
PDF
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
PPTX
Paper: Objects as Points(CenterNet)
by
Yusuke Fujimoto
PPTX
[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection
by
Deep Learning JP
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
SSD: Single Shot MultiBox Detector (ECCV2016)
by
Takanori Ogata
2020 08 05_dl_DETR
by
harmonylab
物体検知(Meta Study Group 発表資料)
by
cvpaper. challenge
DeepLearningDay2016Summer
by
Takayoshi Yamashita
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
IEEE ITSS Nagoya Chapter
by
Takayoshi Yamashita
CVPR2018論文紹介「Pseudo Mask Augmented Object Detection」
by
諒介 荒木
Efficient Det
by
TakeruEndo
【2015.05】cvpaper.challenge@CVPR2015
by
cvpaper. challenge
人が注目する箇所を当てるSaliency Detectionの最新モデル UCNet(CVPR2020)
by
Shintaro Yoshida
CVPR2018 pix2pixHD論文紹介 (CV勉強会@関東)
by
Tenki Lee
【2016.02】cvpaper.challenge2016
by
cvpaper. challenge
Domain Adaptive Faster R-CNN for Object Detection in the Wild 論文紹介
by
Tsukasa Takagi
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monoc...
by
Kazuyuki Miyazawa
[DL輪読会]Objects as Points
by
Deep Learning JP
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
by
harmonylab
Paper: Objects as Points(CenterNet)
by
Yusuke Fujimoto
[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection
by
Deep Learning JP
Deep Learningの基礎と応用
by
Seiya Tokui
SSD: Single Shot MultiBox Detector (ECCV2016)
by
Takanori Ogata
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
[DL輪読会]End-to-End Object Detection with Transformers
1.
DEEP LEARNING JP [DL
Seminar] End-to-End Object Detection with Transformers Hiromi Nakagawa ACES, Inc. https://deeplearning.jp
2.
• 著者:Nicolas Carion,
Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko – Facebook AI • Published:arXiv @ 2020/05/26 – (Submitted to ECCV2020?) • 概要 – 物体検出を直接集合予測タスクと見なしてTransformerを導入するDETRを提案 • DETR:DEtection TRansformer – NMS等の複雑な後処理パイプラインなしに従来手法に匹敵する精度/速度を実現 – 物体検出(Object Detection)以外にPanoptic Segmentationのタスクでも同様に精度を確認 – ソースコード:https://github.com/facebookresearch/detr 2 Overview
3.
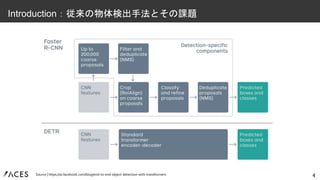
• さまざまな物体検出のアプローチが存在するが、いずれも物体のbboxとクラスの集合の予測 タスクを直接は解けておらず、以下を回帰・分類する代理タスクを間接的に解いている – Proposals:
Faster RCNN, etc – Anchors: Focal Loss, etc – Window centers: CenterNet, etc • これらの手法は、NMS(Non Maximum Suppression)のような、 重複した検出結果を除去する後処理によって精度が大きく影響される • Transformerを用いて最終的な集合を直接予測する End-to-Endなアプローチを提案、パイプラインを単純化し精度を改善 3 Introduction:従来の物体検出手法とその課題 Source | https://towardsdatascience.com/non-maximum-suppression-nms-93ce178e177c
4.
4 Introduction:従来の物体検出手法とその課題 Source | https://ai.facebook.com/blog/end-to-end-object-detection-with-transformers
5.
Proposed Method
6.
6 参考:Transformer & DETR
Transformer
7.
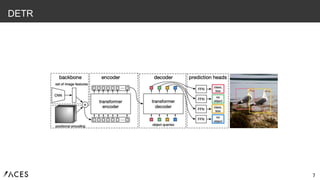
7 DETR
8.
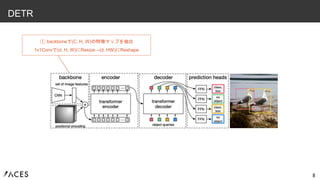
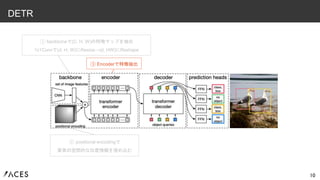
8 DETR ① backboneで(C, H,
W)の特徴マップを抽出 1x1Convで(d, H, W)にResize→(d, HW)にReshape
9.
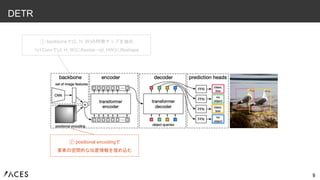
9 DETR ① backboneで(C, H,
W)の特徴マップを抽出 1x1Convで(d, H, W)にResize→(d, HW)にReshape ② positional encodingで 要素の空間的な位置情報を埋め込む
10.
10 DETR ① backboneで(C, H,
W)の特徴マップを抽出 1x1Convで(d, H, W)にResize→(d, HW)にReshape ② positional encodingで 要素の空間的な位置情報を埋め込む ③ Encoderで特徴抽出
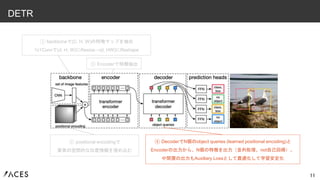
11.
11 DETR ① backboneで(C, H,
W)の特徴マップを抽出 1x1Convで(d, H, W)にResize→(d, HW)にReshape ② positional encodingで 要素の空間的な位置情報を埋め込む ③ Encoderで特徴抽出 ④ DecoderでN個のobject queries (learned positional encoding)と Encoderの出力から、N個の特徴を出力(並列処理、not自己回帰)。 中間層の出力もAuxiliary Lossとして最適化して学習安定化
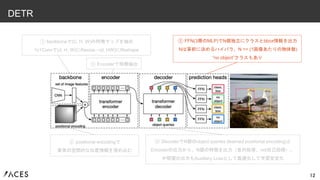
12.
12 DETR ① backboneで(C, H,
W)の特徴マップを抽出 1x1Convで(d, H, W)にResize→(d, HW)にReshape ② positional encodingで 要素の空間的な位置情報を埋め込む ③ Encoderで特徴抽出 ⑤ FFN(3層のMLP)でN個独立にクラスとbbox情報を出力 Nは事前に決めるハイパラ、N >> (1画像あたりの物体数) “no object”クラスもあり ④ DecoderでN個のobject queries (learned positional encoding)と Encoderの出力から、N個の特徴を出力(並列処理、not自己回帰)。 中間層の出力もAuxiliary Lossとして最適化して学習安定化
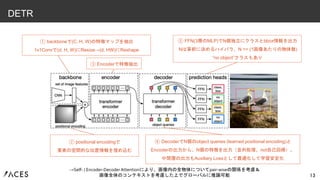
13.
13 DETR →Self- / Encoder-Decoder
Attentionにより、画像内の全物体についてpair-wiseの関係を考慮& 画像全体のコンテキストを考慮した上でグローバルに推論可能 ① backboneで(C, H, W)の特徴マップを抽出 1x1Convで(d, H, W)にResize→(d, HW)にReshape ② positional encodingで 要素の空間的な位置情報を埋め込む ③ Encoderで特徴抽出 ⑤ FFN(3層のMLP)でN個独立にクラスとbbox情報を出力 Nは事前に決めるハイパラ、N >> (1画像あたりの物体数) “no object”クラスもあり ④ DecoderでN個のobject queries (learned positional encoding)と Encoderの出力から、N個の特徴を出力(並列処理、not自己回帰)。 中間層の出力もAuxiliary Lossとして最適化して学習安定化
14.
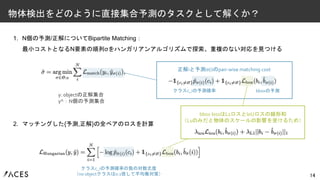
1. N個の予測/正解についてBipartite Matching: 最小コストとなるN要素の順列σをハンガリアンアルゴリズムで探索、重複のない対応を見つける 2.
マッチングした{予測,正解}の全ペアのロスを計算 14 物体検出をどのように直接集合予測のタスクとして解くか? y: objectの正解集合 y^:N個の予測集合 正解iと予測σ(i)のpair-wise matching cost クラスc_iの予測確率 bboxの予測 クラスc_iの予測確率の負の対数尤度 (no objectクラスは0.1倍して不均衡対策) bbox lossはL1ロスとIoUロスの線形和 (L1のみだと物体のスケールの影響を受けるため)
15.
Experiments
16.
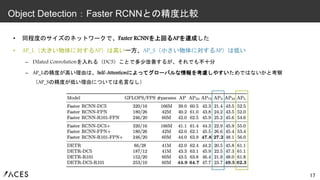
• Object Detectionの検証 –
Dataset:COCO 2017 – Benchmark:Faster RCNN • Faster RCNN*+:オリジナルのFaster RCNNにはない最適化テクニックやロスなどを追加したもの – Backbone:ResNet50 or ResNet101 – Dilated Convolutionにより特徴マップの解像度を大きくしたversionも実験 (小さい物体の検出精度が上がる代わりに、パラメータ数・推論速度が増加する) – スケールやクロップのDataAugmentationなども利用 – ベースとなるモデルは300エポックの学習にV100 x 16台 @ 3日間(バッチサイズ = 4 x 16 = 64) • Panoptic Segmentationの検証 – Object Detectionだけでなく、ヘッドを付け加えるだけでSegmentationのタスクにも拡張できることを示す 16 実験設定
17.
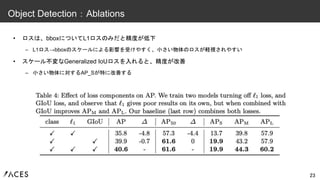
• 同程度のサイズのネットワークで、Faster RCNNを上回るAPを達成した •
AP_L(大きい物体に対するAP)は高い一方、AP_S(小さい物体に対するAP)は低い – Dilated Convolutionを入れる(DC5)ことで多少改善するが、それでも不十分 – AP_Lの精度が高い理由は、Self-Attentionによってグローバルな情報を考慮しやすいためではないかと考察 (AP_Sの精度が低い理由については名言なし) 17 Object Detection:Faster RCNNとの精度比較
18.
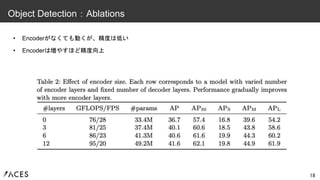
• Encoderがなくても動くが、精度は低い • Encoderは増やすほど精度向上 18 Object
Detection:Ablations
19.
• EncoderのAttentionを可視化 • Encoderの時点で既にある程度インスタンスが分割されている →これによりDecoderによる詳細な位置検出が単純化され、精度改善に寄与していると考えられる 19 Object
Detection:Ablations
20.
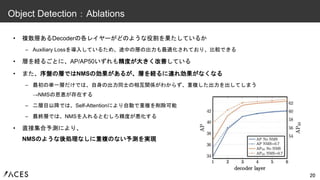
• 複数層あるDecoderの各レイヤーがどのような役割を果たしているか – Auxiliary
Lossを導入しているため、途中の層の出力も最適化されており、比較できる • 層を経るごとに、AP/AP50いずれも精度が大きく改善している • また、序盤の層ではNMSの効果があるが、層を経るに連れ効果がなくなる – 最初の単一層だけでは、自身の出力同士の相互関係がわからず、重複した出力を出してしまう →NMSの恩恵が存在する – 二層目以降では、Self-Attentionにより自動で重複を削除可能 – 最終層では、NMSを入れるとむしろ精度が悪化する • 直接集合予測により、 NMSのような後処理なしに重複のない予測を実現 20 Object Detection:Ablations
21.
• Encoder同様に、DecoderのAttentionを可視化 • インスタンスを分離していたEncoderと異なり、足や頭などのより局所的な、物体の境界を注視している –
Encoderでインスタンスを分離することで、Decoderは境界のみを注視すれば良い用に役割分担できていると推察 21 Object Detection:Ablations
22.
• Positional Encodingの種類や有無にもいろいろ •
入れなかったり、各Attention層に都度入れずに最初の入力時だけ入れるような仕様だと、精度が下がる 22 Object Detection:Ablations
23.
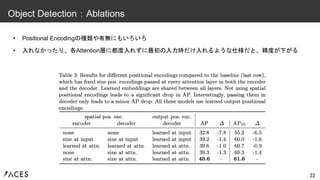
• ロスは、bboxについてL1ロスのみだと精度が低下 – L1ロス→bboxのスケールによる影響を受けやすく、小さい物体のロスが軽視されやすい •
スケール不変なGeneralized IoUロスを入れると、精度が改善 – 小さい物体に対するAP_Sが特に改善する 23 Object Detection:Ablations
24.
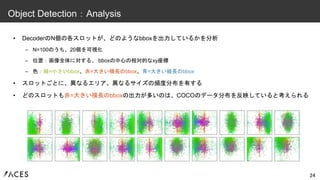
• DecoderのN個の各スロットが、どのようなbboxを出力しているかを分析 – N=100のうち、20個を可視化 –
位置:画像全体に対する、 bboxの中心の相対的なxy座標 – 色:緑=小さいbbox、赤=大きい横長のbbox、青=大きい縦長のbbox • スロットごとに、異なるエリア、異なるサイズの頻度分布を有する • どのスロットも赤=大きい横長のbboxの出力が多いのは、COCOのデータ分布を反映していると考えられる 24 Object Detection:Analysis
25.
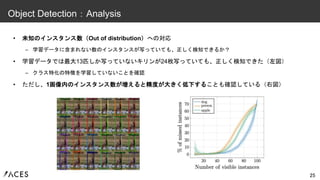
• 未知のインスタンス数(Out of
distribution)への対応 – 学習データに含まれない数のインスタンスが写っていても、正しく検知できるか? • 学習データでは最大13匹しか写っていないキリンが24枚写っていても、正しく検知できた(左図) – クラス特化の特徴を学習していないことを確認 • ただし、1画像内のインスタンス数が増えると精度が大きく低下することも確認している(右図) 25 Object Detection:Analysis
26.
• DETRの性能をPanoptic Segmentationのタスクでも検証 •
Faster RCNN→Mask RCNNのように、DETRもヘッドをいじることで同タスクに拡張可能 26 Panoptic Segmentation
27.
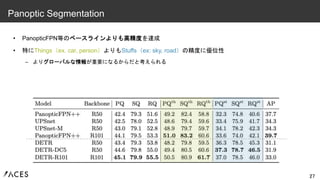
• PanopticFPN等のベースラインよりも高精度を達成 • 特にThings(ex.
car, person)よりもStuffs(ex: sky, road)の精度に優位性 – よりグローバルな情報が重要になるからだと考えられる 27 Panoptic Segmentation
28.
• 定性的結果 28 Panoptic Segmentation
29.
Conclusion
30.
• 物体検出を直接集合予測タスクと見なしてTransformerを導入するDETRを提案 – Self-
/ Encoder-Decoder Attentionにより、画像内の全物体についてpair-wiseの関係を考慮 &画像全体のコンテキストを考慮した上でグローバルに推論可能 • NMS等の複雑な後処理パイプラインなしに従来手法に匹敵する精度/速度を実現 – Encoderはインスタンスレベルの分離を、Decoderは物体の境界を注視していることを確認 – Decoderを積み重ねてSelf-Attentionを効かせることで、重複を自動で除去できるようになっている • 物体検出(Object Detection)以外にPanoptic Segmentationのタスクでも効果を確認 • 初期的な検証のため課題も存在するが、物体検出の新たなアプローチを切り開いた – グローバルな情報を集約できることから、大きい物体には強いが、小さい物体ではベースラインに劣る 30 まとめ
31.
• Transformerというと自然言語のイメージが強いが、物体検出のタスクを直接集合予測のタスクとして 定式化して、既存の重複予測等の課題を解決したのは鮮やか • 小物体の精度などは、局所的な注意やマルチスケールなど、既存の技術を拡張して普通に克服されそう •
一方、クラス数が増えても精度を保てるか、学習効率への影響などは気になる(例:Bipartite matching) • Proposal、Anchor、Center-based等に続く 新たなトレンドとなるか – 先日出たYOLOv4の図で言うと左上らへんにあたる (同じV100なので比較可能と推察) – Transformerが深いせいか、 現状速度的な優位性はあまりなさそう。今後に期待 31 感想 Source |YOLOv4: Optimal Speed and Accuracy of Object Detection
Download
![DEEP LEARNING JP
[DL Seminar]
End-to-End Object Detection with Transformers
Hiromi Nakagawa ACES, Inc.
https://deeplearning.jp](https://image.slidesharecdn.com/200529dlseminardetr-200529061512/85/DL-End-to-End-Object-Detection-with-Transformers-1-320.jpg)
![DEEP LEARNING JP
[DL Seminar]
End-to-End Object Detection with Transformers
Hiromi Nakagawa ACES, Inc.
https://deeplearning.jp](https://image.slidesharecdn.com/200529dlseminardetr-200529061512/75/DL-End-to-End-Object-Detection-with-Transformers-1-2048.jpg)





















![[DL輪読会]Few-Shot Unsupervised Image-to-Image Translation](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminarfunit-190517005148-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Graph R-CNN for Scene Graph Generation](https://cdn.slidesharecdn.com/ss_thumbnails/graphr-cnnforscenegraphgenerationkobayashi1130-181130001547-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Object-Centric Learning with Slot Attention](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0717-200717023021-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)





















