Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
YF
Uploaded by
Yusuke Fujimoto
PPTX, PDF
521 views
Paper: Objects as Points(CenterNet)
4月22日の Data Driven Meetup で用いたスライドです。 論文URL: https://arxiv.org/abs/1904.07850
Technology
◦
Related topics:
Computer Vision Insights
•
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 17
2
/ 17
3
/ 17
4
/ 17
5
/ 17
6
/ 17
7
/ 17
8
/ 17
9
/ 17
10
/ 17
11
/ 17
12
/ 17
13
/ 17
14
/ 17
15
/ 17
16
/ 17
17
/ 17
More Related Content
PPTX
[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...
by
Deep Learning JP
PPTX
[DL輪読会]Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-...
by
Deep Learning JP
PPTX
[DL輪読会]GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution
by
Deep Learning JP
PDF
顕著性マップの推定手法
by
Takao Yamanaka
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
PPTX
モデル高速化百選
by
Yusuke Uchida
[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...
by
Deep Learning JP
[DL輪読会]Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-...
by
Deep Learning JP
[DL輪読会]GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution
by
Deep Learning JP
顕著性マップの推定手法
by
Takao Yamanaka
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
モデル高速化百選
by
Yusuke Uchida
What's hot
PDF
【DL輪読会】DINOv2: Learning Robust Visual Features without Supervision
by
Deep Learning JP
PDF
[DL輪読会]Estimating Predictive Uncertainty via Prior Networks
by
Deep Learning JP
PPTX
[DL輪読会]A closer look at few shot classification
by
Deep Learning JP
PPTX
Noisy Labels と戦う深層学習
by
Plot Hong
PPTX
ResNetの仕組み
by
Kota Nagasato
PDF
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
PDF
Jubatus Casual Talks #2 異常検知入門
by
Shohei Hido
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
PDF
最近のSingle Shot系の物体検出のアーキテクチャまとめ
by
Yusuke Uchida
PDF
機械学習システムのアーキテクチャアラカルト
by
BrainPad Inc.
PPTX
SuperGlue; Learning Feature Matching with Graph Neural Networks (CVPR'20)
by
Yusuke Uchida
PDF
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
PDF
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
PDF
Attentionの基礎からTransformerの入門まで
by
AGIRobots
PPTX
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
by
Deep Learning JP
PPTX
[DL輪読会]Live-Streaming Fraud Detection: A Heterogeneous Graph Neural Network A...
by
Deep Learning JP
PDF
Rでisomap(多様体学習のはなし)
by
Kohta Ishikawa
PDF
【メタサーベイ】Neural Fields
by
cvpaper. challenge
【DL輪読会】DINOv2: Learning Robust Visual Features without Supervision
by
Deep Learning JP
[DL輪読会]Estimating Predictive Uncertainty via Prior Networks
by
Deep Learning JP
[DL輪読会]A closer look at few shot classification
by
Deep Learning JP
Noisy Labels と戦う深層学習
by
Plot Hong
ResNetの仕組み
by
Kota Nagasato
画像認識モデルを作るための鉄板レシピ
by
Takahiro Kubo
Jubatus Casual Talks #2 異常検知入門
by
Shohei Hido
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
[DL輪読会]Focal Loss for Dense Object Detection
by
Deep Learning JP
最近のSingle Shot系の物体検出のアーキテクチャまとめ
by
Yusuke Uchida
機械学習システムのアーキテクチャアラカルト
by
BrainPad Inc.
SuperGlue; Learning Feature Matching with Graph Neural Networks (CVPR'20)
by
Yusuke Uchida
深層学習の不確実性 - Uncertainty in Deep Neural Networks -
by
tmtm otm
自己教師学習(Self-Supervised Learning)
by
cvpaper. challenge
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
Attentionの基礎からTransformerの入門まで
by
AGIRobots
【DL輪読会】An Image is Worth One Word: Personalizing Text-to-Image Generation usi...
by
Deep Learning JP
[DL輪読会]Live-Streaming Fraud Detection: A Heterogeneous Graph Neural Network A...
by
Deep Learning JP
Rでisomap(多様体学習のはなし)
by
Kohta Ishikawa
【メタサーベイ】Neural Fields
by
cvpaper. challenge
Similar to Paper: Objects as Points(CenterNet)
PPTX
[DL Hacks] Objects as Points
by
Deep Learning JP
PPTX
[DL輪読会]Objects as Points
by
Deep Learning JP
PDF
Object as Points
by
harmonylab
PDF
物体検知(Meta Study Group 発表資料)
by
cvpaper. challenge
PDF
CVPR 2019 report (30 papers)
by
ShunsukeNakamura17
PDF
IEEE ITSS Nagoya Chapter
by
Takayoshi Yamashita
PDF
DeepLearningDay2016Summer
by
Takayoshi Yamashita
PPTX
【ICLR2023】論文紹介: Image as Set of Points
by
Shoki Miyagawa
PPTX
[DL輪読会]End-to-End Object Detection with Transformers
by
Deep Learning JP
PDF
20180427 arXivtimes 勉強会: Cascade R-CNN: Delving into High Quality Object Det...
by
grafi_tt
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
PDF
これからのコンピュータビジョン技術 - cvpaper.challenge in PRMU Grand Challenge 2016 (PRMU研究会 2...
by
cvpaper. challenge
PDF
【DLゼミ】XFeat: Accelerated Features for Lightweight Image Matching
by
harmonylab
PDF
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
PDF
object detection with lidar-camera fusion: survey (updated)
by
Takuya Minagawa
PPTX
関西Cvprml勉強会2017.9資料
by
Atsushi Hashimoto
PPTX
Optim インターンシップ 機械学習による画像の領域分割
by
optim_internship
PDF
object detection with lidar-camera fusion: survey
by
Takuya Minagawa
PPTX
AIエッジコンテスト|1位 & 3位解法
by
Shuhei Yokoo
PPTX
輪講スライド20220903.pptx
by
nishimoto2
[DL Hacks] Objects as Points
by
Deep Learning JP
[DL輪読会]Objects as Points
by
Deep Learning JP
Object as Points
by
harmonylab
物体検知(Meta Study Group 発表資料)
by
cvpaper. challenge
CVPR 2019 report (30 papers)
by
ShunsukeNakamura17
IEEE ITSS Nagoya Chapter
by
Takayoshi Yamashita
DeepLearningDay2016Summer
by
Takayoshi Yamashita
【ICLR2023】論文紹介: Image as Set of Points
by
Shoki Miyagawa
[DL輪読会]End-to-End Object Detection with Transformers
by
Deep Learning JP
20180427 arXivtimes 勉強会: Cascade R-CNN: Delving into High Quality Object Det...
by
grafi_tt
Tutorial-DeepLearning-PCSJ-IMPS2016
by
Takayoshi Yamashita
これからのコンピュータビジョン技術 - cvpaper.challenge in PRMU Grand Challenge 2016 (PRMU研究会 2...
by
cvpaper. challenge
【DLゼミ】XFeat: Accelerated Features for Lightweight Image Matching
by
harmonylab
ICCV 2019 論文紹介 (26 papers)
by
Hideki Okada
object detection with lidar-camera fusion: survey (updated)
by
Takuya Minagawa
関西Cvprml勉強会2017.9資料
by
Atsushi Hashimoto
Optim インターンシップ 機械学習による画像の領域分割
by
optim_internship
object detection with lidar-camera fusion: survey
by
Takuya Minagawa
AIエッジコンテスト|1位 & 3位解法
by
Shuhei Yokoo
輪講スライド20220903.pptx
by
nishimoto2
More from Yusuke Fujimoto
PDF
Paper LT: Mask Scoring R-CNN
by
Yusuke Fujimoto
PPTX
Paper: Bounding Box Regression with Uncertainty for Accurate Object Detection
by
Yusuke Fujimoto
PPTX
Tensor コアを使った PyTorch の高速化
by
Yusuke Fujimoto
PPTX
Paper: seq2seq 20190320
by
Yusuke Fujimoto
PPTX
Paper: clinically accuratechestx-rayreport generation_noself
by
Yusuke Fujimoto
PPTX
論文LT会用資料: Attention Augmented Convolution Networks
by
Yusuke Fujimoto
Paper LT: Mask Scoring R-CNN
by
Yusuke Fujimoto
Paper: Bounding Box Regression with Uncertainty for Accurate Object Detection
by
Yusuke Fujimoto
Tensor コアを使った PyTorch の高速化
by
Yusuke Fujimoto
Paper: seq2seq 20190320
by
Yusuke Fujimoto
Paper: clinically accuratechestx-rayreport generation_noself
by
Yusuke Fujimoto
論文LT会用資料: Attention Augmented Convolution Networks
by
Yusuke Fujimoto
Paper: Objects as Points(CenterNet)
1.
DataDrivenDeveloperMeetup 【番外編好きな論文について語る会】#1 Objects as Points(CenterNet) (https://arxiv.org/abs/1904.07850) 2019/04/22 @fam_taro
2.
Agenda 1. なんでこの論文選んだの 2. これまでの検出モデルの課題 3.
CenterNet の特徴 4. この論文の工夫点 5. 個人的な感想 1
3.
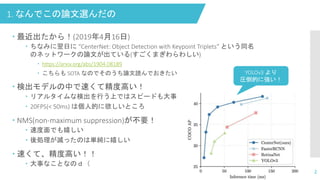
1. なんでこの論文選んだの 最近出たから!(2019年4月16日)
ちなみに翌日に “CenterNet: Object Detection with Keypoint Triplets” という同名 のネットワークの論文が出ている(すごくまぎわらわしい) https://arxiv.org/abs/1904.08189 こちらも SOTA なのでそのうち論文読んでおきたい 検出モデルの中で速くて精度高い! リアルタイムな検出を行う上ではスピードも大事 20FPS(< 50ms) は個人的に欲しいところ NMS(non-maximum suppression)が不要! 速度面でも嬉しい 後処理が減ったのは単純に嬉しい 速くて、精度高い!! 大事なことなのd( 2 YOLOv3 より 圧倒的に強い!
4.
2. これまでの検出モデルの課題 3 Object
detection by region classification RCNN とか Fast-RCNN 大体 2-stage detector 課題: 遅い Object detection with implicit anchors(暗黙的にアンカーを使うもの) 大体 1-stage detector -> 最近の速い検出モデルはこれ SSD, RetinaNet, YOLO(v3), M2Det … 候補ボックスを予め用意するもの(ボックス解像度・縦横比率等) 課題: Ground truth (教師ラベル) 作成時に、overlap の重なり具合を使う 人が決めたしきい値で foreground or not を決める 1物体に対し複数の Ground truth がありうる anchor について人が調整する必要がある 個人的課題 NMS が必要(大体10ms 必要 & 出力ボックスが多いと時間がかかる & 時間が固定じゃない)
5.
2. これまでの検出モデルの課題 4 Object
detection with implicit anchors(暗黙的にアンカーを使うもの) 課題: Ground truth (教師ラベル) 作成時に、overlap の重なり具合を使う
6.
2. これまでの検出モデルの課題 5 Object
detection by keypoint estimation heatmap 使って各点を直接求める方法 後述の CenterNet の推論時の流れを見るとイメージつかみやすいかも CornerNet: ボックスの左上と右下の2点のみ推定 ExtremeNet: 中心とボックスの角4点を推定 課題: keypoint detection 後に組み合わせを grouping する必要がある 遅い
7.
3. CenterNet の特徴 6
Backbone として DLA や Hourglass を利用 CornerNet でも利用されている DLA = Deep layers aggregation https://arxiv.org/pdf/1707.06484.pdf Detection においては以下2つのみ求める 物体の中心位置 ボックスサイズ 図: 左が元DLA、右がCenterNet用DLA
8.
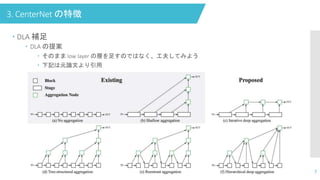
3. CenterNet の特徴 7
DLA 補足 DLA の提案 そのまま low layer の層を足すのではなく、工夫してみよう 下記は元論文より引用
9.
3. CenterNet の特徴
推論(予測)時の流れ 画像を Backbone ネットワーク(DLA や Hourglass)に入力 Key point heatmap を出力(下記はイメージ図) 論文中では 元画像サイズ(HxW) に対して (H/4, W/4) のサイズ 512x512 なら heatmap のサイズは 128x128(目が細かい) local peak を抽出 ある箇所について、周辺8個の値より大きい(以上)となる場所 そこを物体の中心とする! local peak でのボックスサイズと離散化誤差を予測 離散化誤差 = 元画像から heatmap にした際の誤差(微調整) 予測ボックス出力! NMS はしない(個人的に大事) heatmap 内の1マスに対する出力個数(検出時) クラス数 + 4(2: ボックスサイズ、2: 離散化誤差) 8 heatmapイメージ https://pythonspot.com/tag/heatmap/
10.
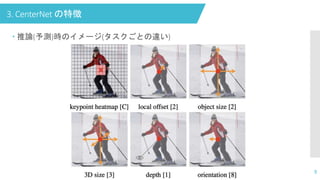
3. CenterNet の特徴
推論(予測)時のイメージ(タスクごとの違い) 9
11.
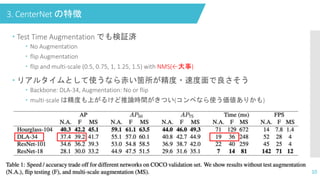
3. CenterNet の特徴
Test Time Augmentation でも検証済 No Augmentation flip Augmentation flip and multi-scale (0.5, 0.75, 1, 1.25, 1.5) with NMS(←大事) リアルタイムとして使うなら赤い箇所が精度・速度面で良さそう Backbone: DLA-34, Augmentation: No or flip multi-scale は精度も上がるけど推論時間がきつい(コンペなら使う価値ありかも) 10
12.
3. CenterNet の特徴
学習時の流れ 教師ラベル用 heatmap の作り方 処理前 処理後 実際の物体の中心 を低解像度化 -> 本論文では R=4 ガウシアンカーネルでなだらかな値にする 中心座標が頂点(=1) となる山を作るイメージ 同じクラスの違う物体で重なった場合は値が高い方を採用 σp は object size-adaptive standard deviation 多分データセット毎に出すべき値? 11
13.
3. CenterNet の特徴
学習時の loss 設計(それぞれ比率をかけて足したものが合計 loss) Heatmap の loss pixelwise logistic regression with focal loss(N は number of keypoints in image) 離散化誤差の loss ボックスサイズの loss ボックスサイズは scaling (最大値1にする) してないことに注意 12
14.
4. この論文の工夫点 13 Backbone(DLA・HourGlass)
を使う 離散化誤差の定義 物体の中心のみ求めれば良いというシンプルなネットワーク 他タスクへの応用(が簡単なネットワークを提案) 3D detection Human pose estimation Orientation(方向) Batch-normalization で cudnn を使わない(???) PyTorch のソースをいじって設定変更できる 実験時は使わない方が精度が上がったとのこと
15.
5. 個人的な所感 Backbone(DLA・HourGlass)
の貢献がすごい 今後もっと増えると思います Heatmap 路線の Detector はもっと増えそう? NMS を使わなくて良いのは個人的に嬉しい シンプル シンプルで精度高いのでふつくしい… 実装がとても参考になる とりあえず近いうちに検証します 14
16.
References Objects as
Points(https://arxiv.org/abs/1904.07850) CornerNet: Detecting Objects as Paired Keypoints(https://arxiv.org/abs/1808.01244) Deep Layer Aggregation(https://arxiv.org/abs/1707.06484) Deep layer aggregation. Cvpr2018(わかりすかったまとめスライド) https://www.slideshare.net/ShinichiroMurakami/deep-layer-aggregation-cvpr2018 15
17.
おわり 16 ありがとうございました
Download














![[DL輪読会]PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metr...](https://cdn.slidesharecdn.com/ss_thumbnails/181214dlpointnet-181214053349-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-...](https://cdn.slidesharecdn.com/ss_thumbnails/dlu8f2au8aadu4f1av2-170407001546-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution](https://cdn.slidesharecdn.com/ss_thumbnails/20220225akitarevised1-220225034636-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Estimating Predictive Uncertainty via Prior Networks](https://cdn.slidesharecdn.com/ss_thumbnails/estimatingpredictiveuncertaintyviapriornetworks-190628002736-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A closer look at few shot classification](https://cdn.slidesharecdn.com/ss_thumbnails/acloserlookatfew-shotclassification-190304034759-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Live-Streaming Fraud Detection: A Heterogeneous Graph Neural Network A...](https://cdn.slidesharecdn.com/ss_thumbnails/live-streamingfrauddetectionaheterogeneousgraphneuralnetworkapproach-220325040823-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL Hacks] Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/centernetpub-190627053219-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)
















