Downloaded 50 times
![cvpaper.challenge
Twitter@CVPaperChalleng
http://www.slideshare.net/cvpaperchallenge
MAILTO: cvpaper.challenge[at]gmail[dot]com](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-1-2048.jpg)
![Haoyu Ren, Ze-Nian Li, “Object Detection Using Generalization and Efficiency Balanced Co-occurrence
Features”, in ICCV, 2015.
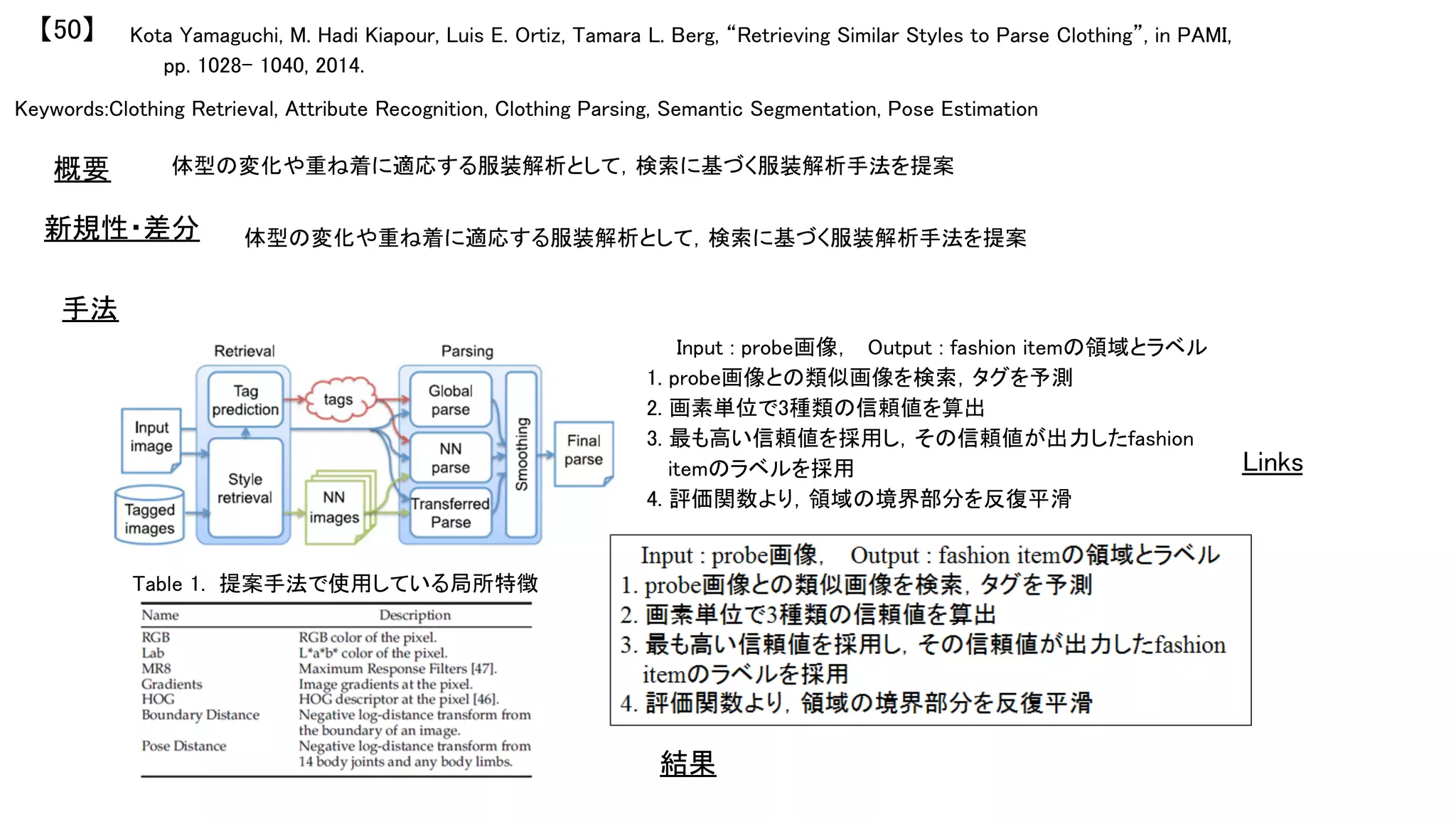
【1】
Keywords: Co-occurrence Features, Generalization and Efficiency Balanced (GEB) framework for Boosting
新規性・差分
手法
結果
概要
Haar-lke特徴,Local Binary Pattern (LBP), HOGに関する共起
特徴を用いるが,効果的な弱識別器の学習として
Generalization and Efficiency Balanced (GEB)フレームワークを
提案し,ブースティングに活用する.
共起特徴量を用いたブースティングのための弱識別器学習法
を提案することで,高精度かつ高効率な物体検出方法を提供
する.共起特徴量は背景ノイズや姿勢,照明変動などに影響を
受けるが,それらを解決.
CoHaar, CoLBP, CoHOGを構築.
Co-Haar: Haar特徴の重みは全体で0になるように調整.x,y方向に勾配も量子化し
て共起させる.
CoLBP: 右図を参考にして,クラスタを作成する.2つのクラスタの組み合わせによ
り共起特徴を構成.
CoHOGはWatanabe[Watanabe+, 2009]論文を参考.
基本的にはReal AdaBoostをベースにしているが,共起特徴に特化するためにオフ
セットの位置を考慮した重み付けや効率化のパラメータを設けている.
下図はINRIA person datasetでの実験結果である.共起
特徴統合の精度はmiss rateが15%であった.GEB
+AllCoFeatureの結果はCaltech pedestrian datasetにてエ
ラー率が24%であった.
Links
論文
http://www.cv-foundation.org/openaccess/content_iccv_2015/
papers/Ren_Object_Detection_Using_ICCV_2015_paper.pdf
著者 http://www.sfu.ca/~hra15/](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-2-2048.jpg)









![Chao Ma, Jia-Bin Huang, Xiaokang Yang, Ming-Hsuan Yang, “Hierarchical Convolutional Features for Visual
Tracking”, in ICCV, 2015.
【11】
Keywords: Object Tracking
新規性・差分
手法
結果
概要
CNNの上位層と下位層を組み合わせてオンライン学習を実行
する.
上位層と下位層を組み合わせて,さらにLinear Correlation
Filtersベースのオンライン学習を実行することにより,最先端の
精度を実現.
Fine-tuningなしのVGG3,4,5層目の最後の特徴量を利用(左下図).全結合層では
なく畳み込み層の特徴マップを用いることで位置情報を求め,さらに上位層から特
徴を取り出すことで抽象化された意味を結合できる.物体位置はこれらの特徴マッ
プから推定する.特徴マップの可視化は(右下図).
オンライン学習にLinear correlation filtersを適用する.
下の表はstate-of-the-artとの比較である.各タスクにおいて良好な性能を示した.ここで,計算時間の
45%はCNNのforwardに要している.AlexNetとVGGNetの比較や,Hypercolumns[Hariharan+, CVPR2015]
の特徴マップとも比較した.
Links
論文
プロジェクト
https://sites.google.com/site/jbhuang0604/publications/cf2
コード https://github.com/jbhuang0604/CF2](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-12-2048.jpg)










![Yang Cao, Changhu Wang, Zhiwei Li, Liqing Zhang, Lei Zhang, “Spatial-Bag-of-Features”, in CVPR, 2010.
【22】
Keywords: Bag-of-features
新規性・差分
手法
結果
概要
BoFの改良版であるSpatial Pyramid Matching [Lazebnik+,
CVPR2006]では,空間的な階層構造を形成して特徴を取得し
ていたが,画像の変換に弱いという特徴があった.それを,ヒス
トグラム変換,並進や回転への不変性をもたせて改良を行っ
た.
従来法としてはSpatial Pyramid Matching [Lazebnik+,
CVPR2006]があげられるが,スケールの変動や並進,回転に
は弱いという特徴があった.本稿ではその問題を改善した.
主に下図に示す通りである.
右図がOxford 5K datasetに対する結
果である.オリジナルのBoFをベース
(58.5%)として,すべての統合モデル
は64.4%にまで向上した.
Links
論文
http://ieeexplore.ieee.org/xpl/login.jsp?
tp=&arnumber=5540021&url=http%3A%2F%2Fieeexplore.ieee.org
%2Fiel5%2F5521876%2F5539770%2F05540021.pdf%3Farnumber
%3D5540021
Slide http://sglab.kaist.ac.kr/~sungeui/IR/Slides/DG_Yu_1.pdf](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-23-2048.jpg)
![Y. LeCun, L. Bottou, Y. Bengio, P. Haffner, “Gradient-Based Learning Applied to Document Recognition”, in
Proceedings of the IEEE, 1998
【23】
Keywords: Convolutional Neural Networks (CNN)
新規性・差分
手法
結果
概要
Convotlutional Neural Networks (CNN)の提案論文.それまで
の流れとは対照的に画像の局所的な畳み込み=>プーリングを
繰り返し,全結合とすることで文字認識に対して精度が向上す
ることを明らかにした.MNISTデータセットに対して99%以上の
認識率を達成.
入力,畳み込み,プーリング,全結合層を経て出力層へつなが
る一連の流れは,現在までのネットワーク構造に受け継がれる
こととなる.
下記にネットワーク構造を示す.LeNet-5と称される.
・入力層:32x32
・畳み込み1:28x28x6 (特徴マップサイズx特徴マップサイズxカーネル数)
・プーリング1:14x14x6
・畳み込み2:10x10x16
・プーリング2:5x5x16
・全結合1:120
・全結合2:84
・出力:10 (0 - 9までの数字に対応)
文字認識用のデータセットであるMNISTデータセットに対して実験を行った結果,
99.2%の精度で認識できることが判明した.なお,現在の最高性能は0.23% [
Ciresan et al. CVPR 2012]である.LeNet-5はCaffemodelやTensorFlowなどでも入
手可能である.
Links
論文 http://yann.lecun.com/exdb/publis/pdf/lecun-98.pdf
プロジェクト http://yann.lecun.com/exdb/lenet/
MNIST dataset http://yann.lecun.com/exdb/mnist/
Caffe MNIST tutorial
http://caffe.berkeleyvision.org/gathered/examples/mnist.html](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-24-2048.jpg)


![Andreas Veit, Tomas Matera, Lukas Neumann, Jiri Matas, Serge Belongie, “COCO-Text: Dataset and
Benchmark for Text Detection and Recognition in Natural Images”, in arXiv: 1601.07140, 2016.
【26】
Keywords: Text Detection, Dataset
新規性・差分
手法
結果
概要
もともとは物体検出や画像キャプショニングのタスクが含まれ
ていたMS COCOデータセットに対して文字検出のタスクを追加
した.自然なシーン(in the wild)に対して文字領域の検出やそ
の文字の内容を当てる.
MSCOCOに文字のアノテーションを付加したが,その数は
63,000の画像に対して173,000のアノテーションが含まれる.
COCOデータセットでは,他のデータセットと比較すると
・画像に対する詳細なラベル付けがされている
・画像キャプショニングのアノテーションが十分にされている
・画像に出現する文字の領域や種類(手書き・機械のプリント文字)のバリエーショ
ンが豊富
という利点を持つ.これらの利点を最大限活かすためにもCOCOデータセットに対
して文字検出のタスクを増やした.
アノテーションの内容としては,
・bounding box ・読みやすい/読みにくい ・カテゴリ:機械プリント/手書き/その他
・英語か非英語 ・UTF8 string
比較する手法(OCR algorithms)は以下の3種類を用いた.(が,製品であるので匿
名化して下記の表にA, B, Cにて表記)
・Google ・TextSpotter ・VGG [Jaderberg+, IJCV2015]
文字検出の正解は正解矩形とのIoUが50%以上の時とした.各アノテーションの項
目を当てる.結果としては下表に示す.
Links
論文
http://vision.cornell.edu/se3/wp-content/uploads/
2016/01/1601.07140v1.pdf
プロジェクト http://vision.cornell.edu/se3/coco-text/](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-27-2048.jpg)










![Elliot J. Crowley, Omkar M. Parkhi, Andrew Zisserman, “Face Painting: querying art with photos”, in BMVC,
2015.
【37】
Keywords: Painting Retrieval, Face Recognition
新規性・差分
手法
結果
概要
顔画像においてクエリ画像から類似する絵画(自画像?)を検
索する問題.油絵,インク,watercolorなどのペイントやスタイル
に関しても考慮する.
(1) 表現方法としてFisher VectorsやConvolutional Neural
Networks (CNN)を比較
(2) 新規にデータセットを提案
(3) 画像検索におけるreverse problemを解決
右図が提案手法の流れである.あらかじ
め特徴量を計算し,クエリと比較することで
絵画検索システムを構築.
CNNの表現方法としては
VGG Face Descriptor [Parkhi+,
BMVC2015]を用いる.VGG Face
DescriptorはVGGNet-16をベースにして顔
画像を学習させたネットワークである.
あらかじめ計算した特徴との距離を比較す
るが,(i) L2距離 (ii) 識別性に優れた次元
削減 (iii) 学習による識別器を考慮する.
データの構成や結果については右の
表に示す通りである.顔の検出につ
いてはDPMを適用.顔の表現には
Fisher VectorかCNNの全結合層を用
いる.次元圧縮に関してはPCAで128
次元に削減,識別器はSVMを用い
る.CNN L2 distanceがもっとも精度が
高い.
Links
論文 http://www.bmva.org/bmvc/2015/papers/paper065/paper065.pdf
概要 http://www.bmva.org/bmvc/2015/papers/paper065/abstract065.pdf
プロジェクト http://www.robots.ox.ac.uk/~vgg/research/face_paint/
デモ http://zeus.robots.ox.ac.uk/facepainting/index?error=face](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-38-2048.jpg)

![Seyoung Park and Song-Chun Zhu , “Attributed Grammars for Joint Estimation of Human Attributes, Part and
Pose ”, in ICCV, 2015.
【39】
Keywords:
新規性・差分
手法
結果
概要
・パーツ毎にattributeを推定し,その統計量から頑健な
attribute推定をしている.姿勢・attributeともにCNNベースで学
習し,モデルを構築している.Pople Datasetにおいて80.20[%]
の精度でattribute推定を可能としている.
・パーツからattibuteを推定している
・階層構造やand-or graphでattribute推定をしている
・Part Relation modelとPart Appearance model
を定義し,CNNベースで姿勢推定する.
そして,各パーツからAttribute relation model,
attribute appearance modelを推定している.
・
Links
論文 :
http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/
Park_Attributed_Grammars_for_ICCV_2015_paper.pdf
プロジェクト :http://seypark.github.io/pages/jointattr.html](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-40-2048.jpg)
![Georgia Gkioxari, Ross Girshick and Jitendra Malik , “Actions and Attributes from Wholes and Parts ”, in
ICCV, 2015.
【40】
Keywords:
新規性・差分
手法
結果
概要
姿勢推定からの行動と属性を認識する課題.姿勢推定はDeep
Learning版のposeletを提案している.実験ではPASCAL VOC
2012において行動認識し,82.6[%]の精度を出している.また
People datasetに対して属性認識した結果,89.5[%]の精度となっ
ている.
・従来手法では一枚絵から行動・属性推定していたが,そこに
姿勢推定を付加することで精度向上を図っている.その姿勢推
定は,poseletのDeep Learning版を提案している.
1.R-CNNで人物検出
2.Deep版 poselet(DeepParts)で姿勢推定
3.姿勢毎にCNN特徴を抽出し,行動・属性を推定
左図が行動・属性の認識結果の一例
・行動認識:82.6[%](PASCAL VOC 2012)
Simonyan&ZissermanのVGGNet 16&19Layerには及ばなかったものの,劣らない
性能を出している
・属性認識:89.5[%] (People Dataset)
CVPR2014で提案されたPANDAよりも10[%]近い精度向上
Links
論文 :
http://www.cv-foundation.org/openaccess/content_iccv_2015/papers/
Gkioxari_Actions_and_Attributes_ICCV_2015_paper.pdf](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-41-2048.jpg)
![Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun, “Delving Deep into Rectifiers: Surpassing Human-Level
Performance on ImageNet Classification”, in ICCV, 2015.
【41】
Keywords: Parametric ReLU
新規性・差分
手法
結果
概要
Parametric Rectified Linear Unit (PReLU)の提案論文.活性化
関数であるReLUをさらに一般化し,マイナスの方向にも勾配を
持たせる.
計算の複雑性は変えず,精度を大幅に向上させる仕組みを考
案したこと.
Deeperモデルに対しても収束するモデルを考案した.
活性化関数を式(1)のように定義した.a_iはnegative方向への勾配を調整する働き
を持つ.a_iの値が低い時,Leaky ReLU [Maas+, ICML2013]と同等になる.PReLU
では,学習に応じてa_iの値をupdateすることで収束を適応的にする.これはchain
ruleに従い,実際の勾配更新は式(4)のmomentumによる.初期値としてはa_i=0.25
を採用.
左表はLReLUとPReLUの比較である.LReLU(a_i=0.25)の時よりもPReLUにより係
数を適応的に更新した方が精度が高くなることが確認できる.
ILSVRCのテストセットに対して4.94%のtop-5 error rateを達成(右表).その結果,人
間(5.1%)よりも高い精度で識別することができた.なお,提案手法は3つのモデル
(19層, 22層, 22層(カーネル多))を組み合わせてアーキテクチャを構成した.
Links
論文
http://research.microsoft.com/en-us/um/people/kahe/
publications/iccv15imgnet.pdf
著者ページ
http://research.microsoft.com/en-us/um/people/kahe/
解説記事 http://qiita.com/shima_x/items/8a2f001621dfcbdac028](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-42-2048.jpg)
![Alessandro Giusti, et al., “Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots”,
in ICRA, 2016.
【42】
Keywords: Drone, UAV, DNN, Forest Trails 手法
結果
概要
森の中での道案内をドローンが行うという論文.進行方向に対
して3方向(直進,右左折)をナビゲートする.結果的に人間の案
内能力を超えたということが判明.IROS Workshop, AAAI16
video competition, ICRA16採択.下図が問題設定を示す.
ドローンにマウントされたカメラから進行方向に対して前方の映像を取得する.順
路を3方向(直進,右左折)で教示することで,森からの抜け道まで案内可能.
学習時には3台のヘッドマウントカメラ (視野は30度ごと)から教示画像を取得する.
3方向のうちどの方向が歩けるかかつ正しい道であるかの教師ラベルを与えてお
く.
DNNは10層の構造である(論文中図5参照).入力は101x101 [pixels]のRGB画像
(101x101x3)で全結合層は1層で200ニューロン,出力層は3ニューロン(3方向が対
応)である.学習には17,119枚の画像を使用,90epoch,学習率の初期値は0.005か
らスタートして1epochごとに x0.95.
下図は精度である.比較手法はIttiらのSaliencyを特徴としてSVM識別(Saliency),
[12]の手法,2人の人間と比較した.道が見えない場合や開けている環境で道が広
い場合に失敗しやすい傾向にあった.今後精度を向上させるにはドローンカメラの
解像度をあげることがあげられる.
Links
論文
http://ieeexplore.ieee.org/stamp/stamp.jsp?
tp=&arnumber=7358076
プロジェクト(データセットあり)
http://people.idsia.ch/~giusti/forest/web/
YouTube https://www.youtube.com/watch?v=umRdt3zGgpU](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-43-2048.jpg)

![Tian Lan, Yuke Zhu, Amir Roshan Zamir and Silvio Savarese, “Action Recognition by Hierarchical Mid-level
Action Elements ”, in ICCV, 2015.
【44】
Keywords:
新規性・差分
手法
結果
概要
fine-grainedよりも更に細かいfiner-grainedとして,mid-level
action elements(MAEs)を提案している.MAEsは背景差分から
行動に関連する部分をセグメントし,複数の時空間解像度で行
動を表現する.
従来の行動認識では,複数の動作が含まれていた.それをよ
り詳細に捉えるfiner-grainedを課題として提案している.それを
複数の視点から解決している.例えば,”take food from
fridge”では,詳細に書くと
・冷蔵庫の開け閉め
・物体
・トマトを拭く
となる.
【Action Proposals: Hierarchical Spatiotemporal Segments 】
初めに,unsupervisedに時空間のセグメンテーションをする.ビデオから行動や身
体部位,物体などを自動で学習する.
具体的には2010年に提案された”Category independent object proposals”を用い
ており,セグメンテーション候補を複数出して結合することで,頑健なセグメントを可
能にしている.それを時系列にプーリングし,階層的に分割している
Links
論文 :
http://www.cv-
foundation.org/
openaccess/
content_iccv_2015/
papers/
Lan_Action_Recognition_
UCF-Sportsで83.6[%] (iDT: 79.2[%]),Hollywood2で66.3[%] (iDT: 63.0[%])](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-45-2048.jpg)



![Shuiwang Ji, Wei Xu, Ming Yang, “3D Convolutional Neural Networks for Human Action Recognition”,
PAMI2013, VOL. 35, NO. 1, pp.221-231.
【48】
Keywords: 3DCNN
新規性・差分
手法
結果
概要 行動認識のための3次元 CNNモデルの提案.また3次元CNNの性能向上のための,モデル正則との組み合わせ
方法を提案している.実験結果では公開データセットでの優れた性能を実証した.TRECVIDデータのベースライン
の手法の認識性能を上回った.
3次元CNNの提案
3次元の畳み込みを行うことにより時系列および,外観特
徴をそれぞれ抽出する.提案したアーキテクチャでは,隣
接する入力フレームからの情報の複数のチャネルを生成
し,各チャネルごとに畳み込みとサブサンプリングを行う.
すべてのチャネルからの情報を組み合わせた結果を最終
的な特徴表現とする.
KTHでの行動認識精度
Links
論文ページ:
http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6165309
著者ページ:
http://www.eecs.wsu.edu/~sji/
(上)行動認識のための3D CNN
アーキテクチャ
[ 構成 ]1層 : ハードワイヤード層,
3層 : 畳み込み層, 2層 : サブサン
プリング層, 1層 : 最終的な結合層
連続フレームから複数の特徴の抽
出 : 動き特徴を抽出するために,
同一の3次元カーネルは入力映像
内の3次元キューブへ重複される.
色分けはそれぞれの重み共有を
示しているが,出力結果ではその
重みを共有しない.](https://image.slidesharecdn.com/201602deepsurvey2016-160307024810/75/2016-02-cvpaper-challenge2016-49-2048.jpg)






cvpaper.challengeにて2016年2月にサーベイした論文のまとめです. Computer Visionの"今"をまとめています. cvpaper.challenge2016は産総研,東京電機大,筑波大学,東京大学,慶應義塾大学のメンバー約30名で構成されています. 2015年はCVPR2015の全602論文を読破し,PRMUにて論文調査からアイディア考案,論文化までをカバーする「DeepSurvey」を提案しました. 2016年は「1000本超の読破」と「コンピュータビジョンの上位会議への投稿」を目標に活動しております. Twitterで論文情報を随時アップしてます. Twitter: https://twitter.com/CVpaperChalleng 質問コメント等がありましたらメールまで. Mail : cvpaper.challenge@gmail.com



















































![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)














