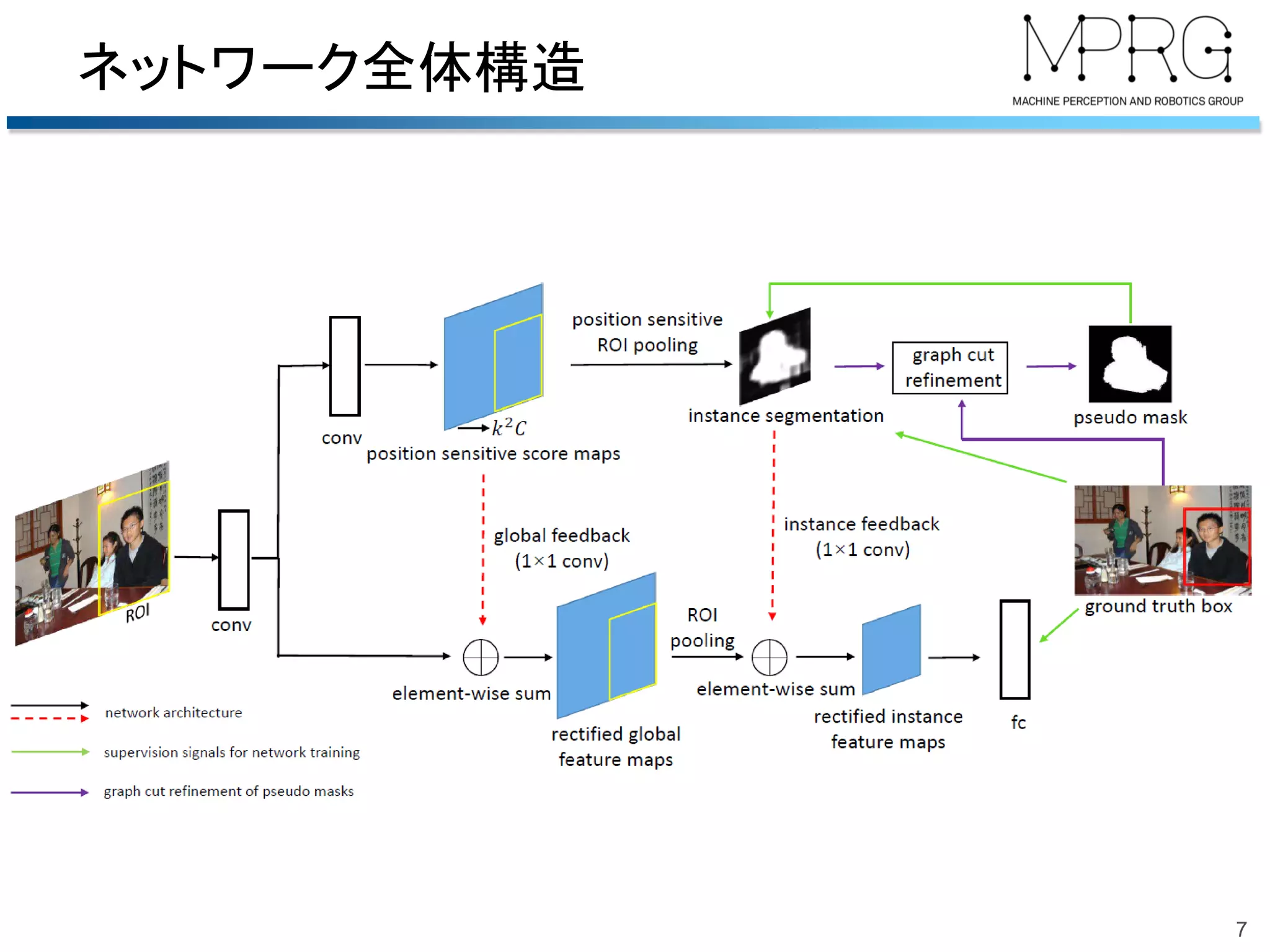
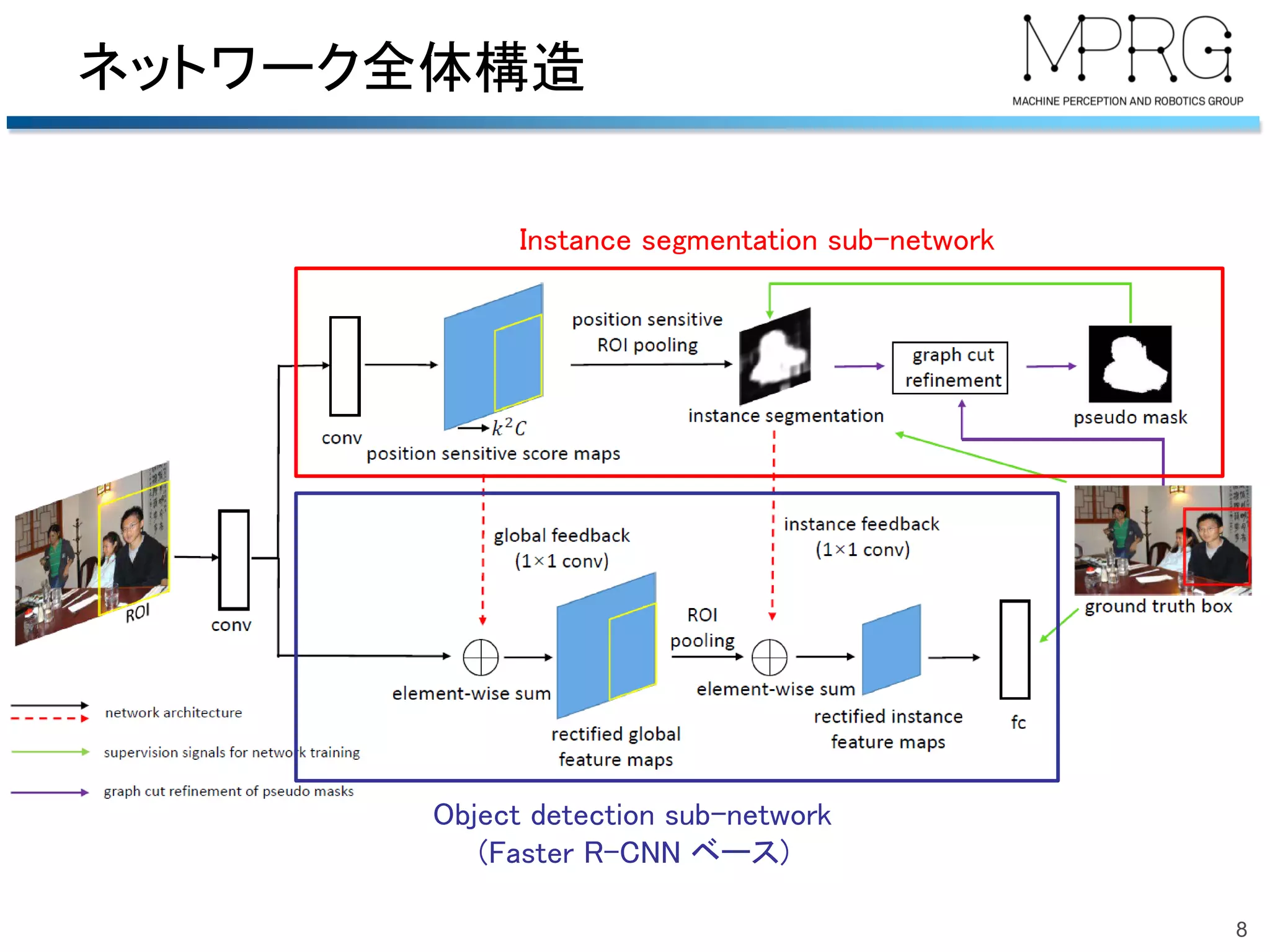
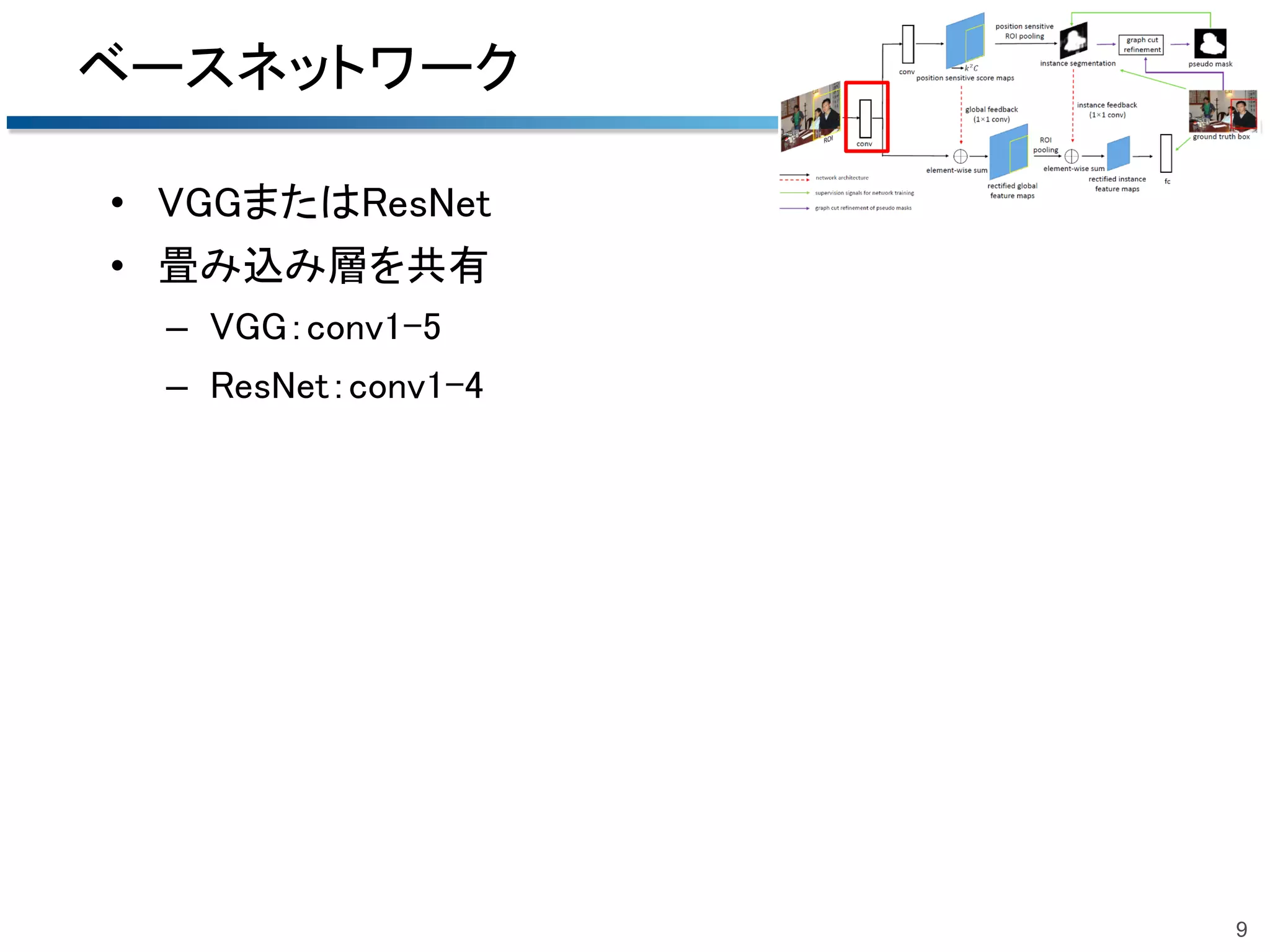
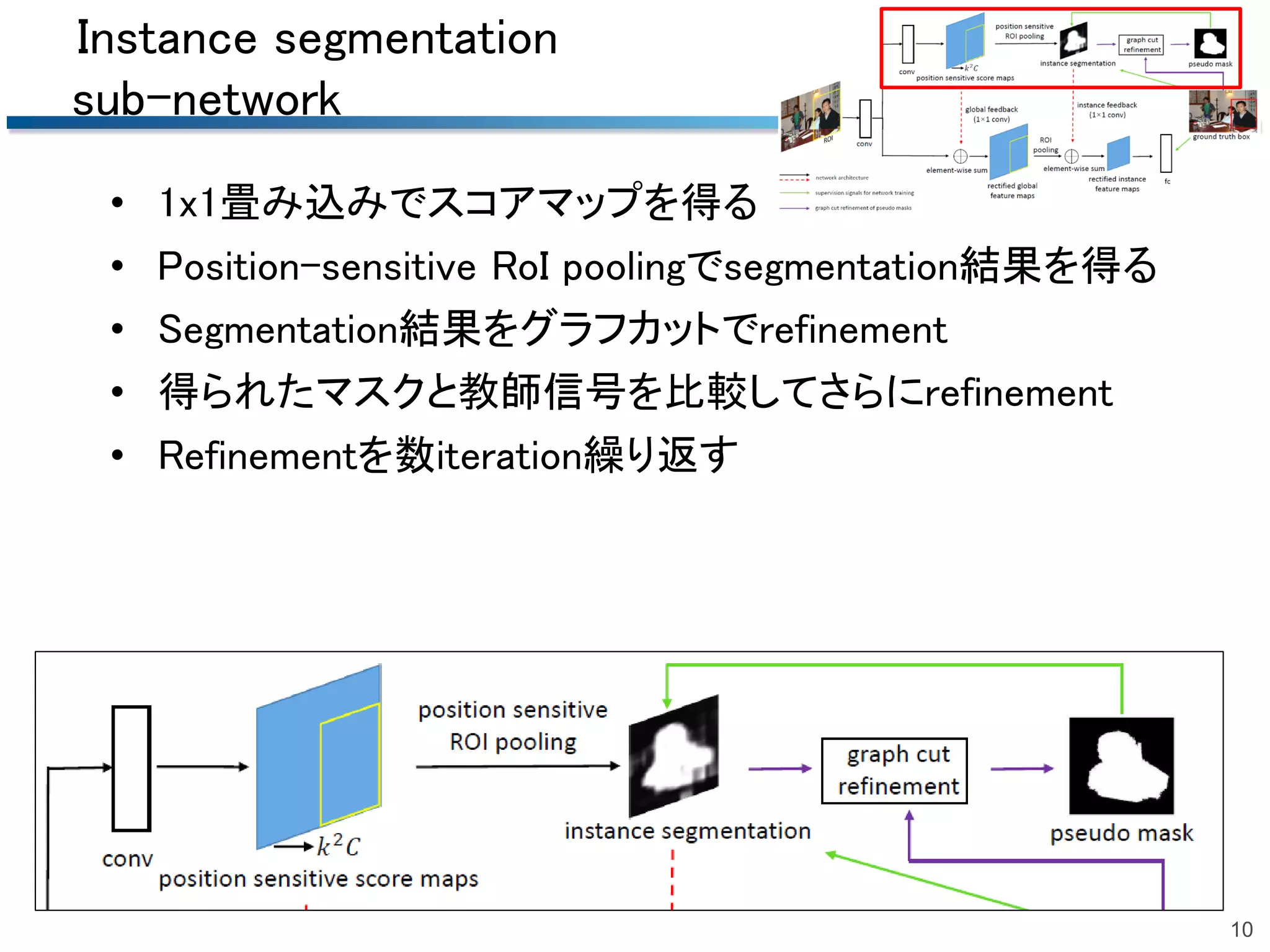
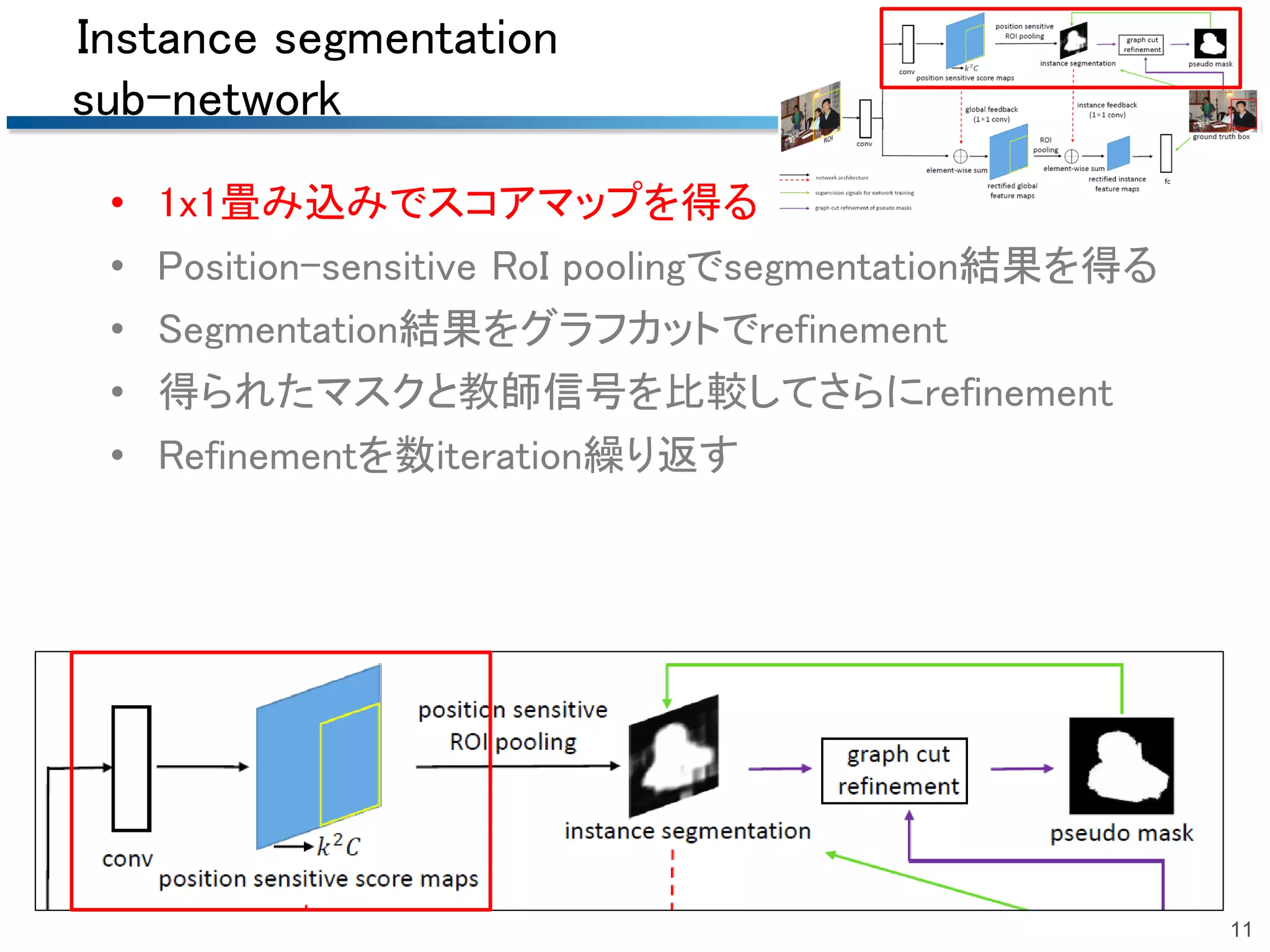
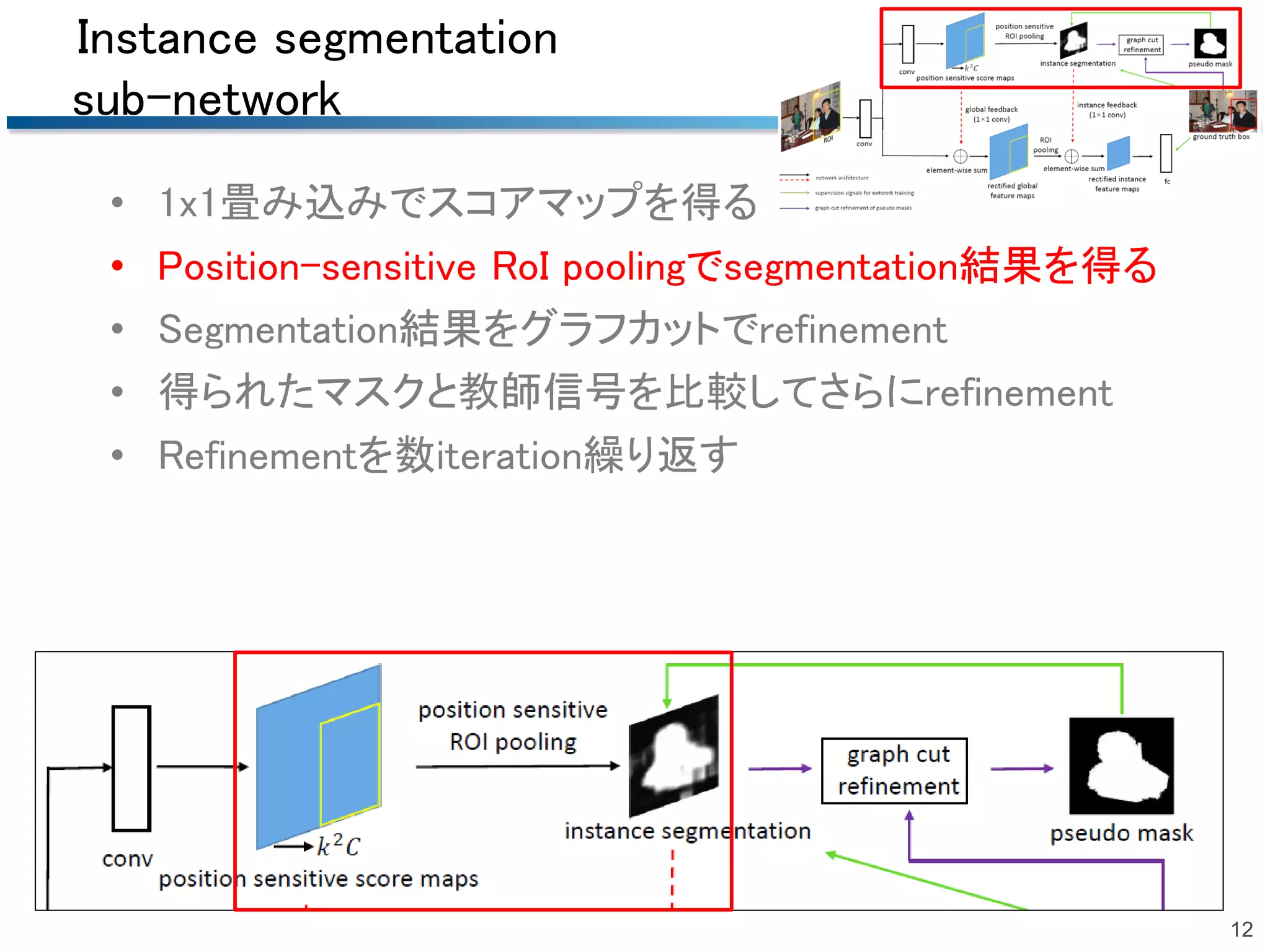
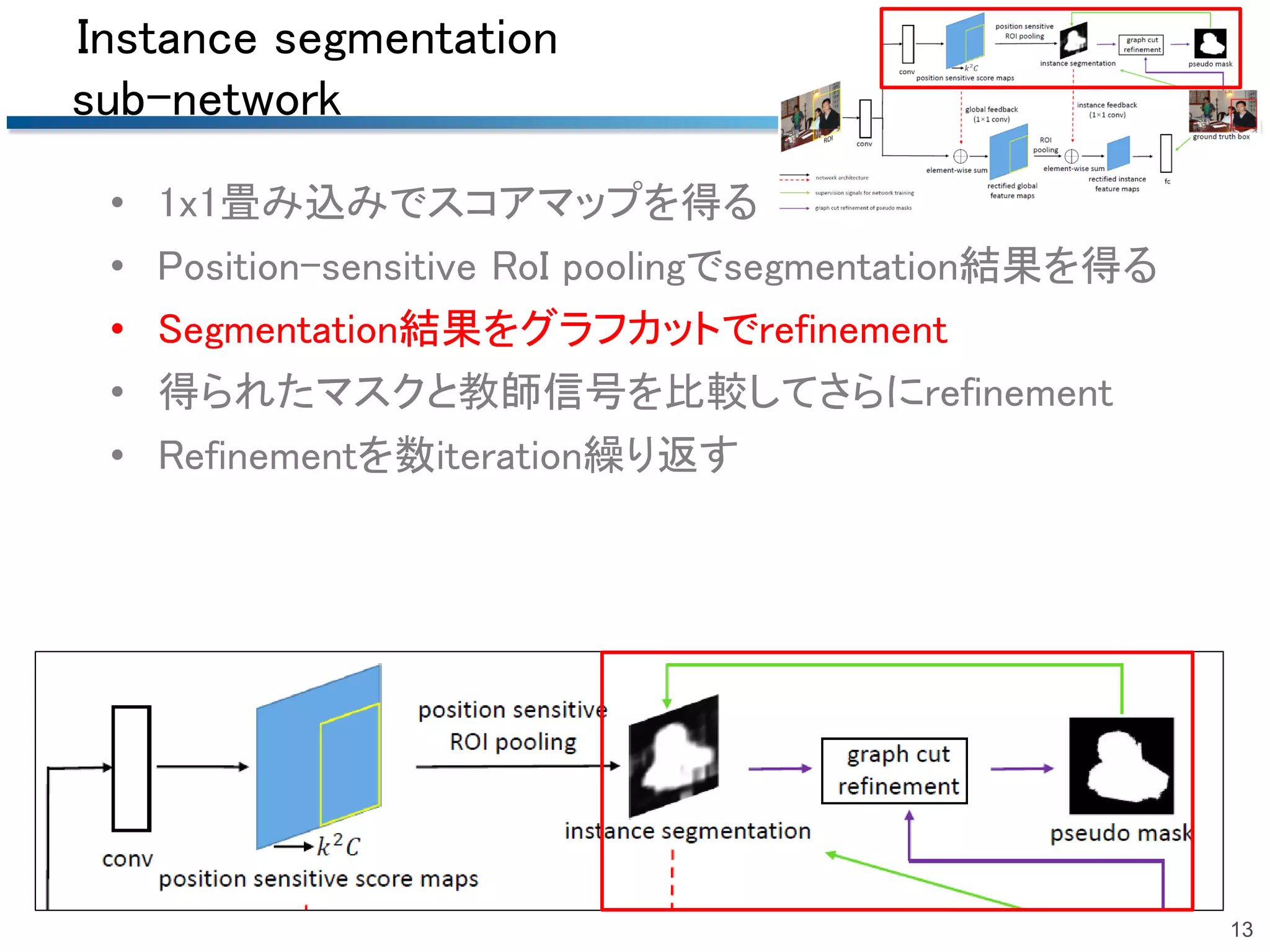
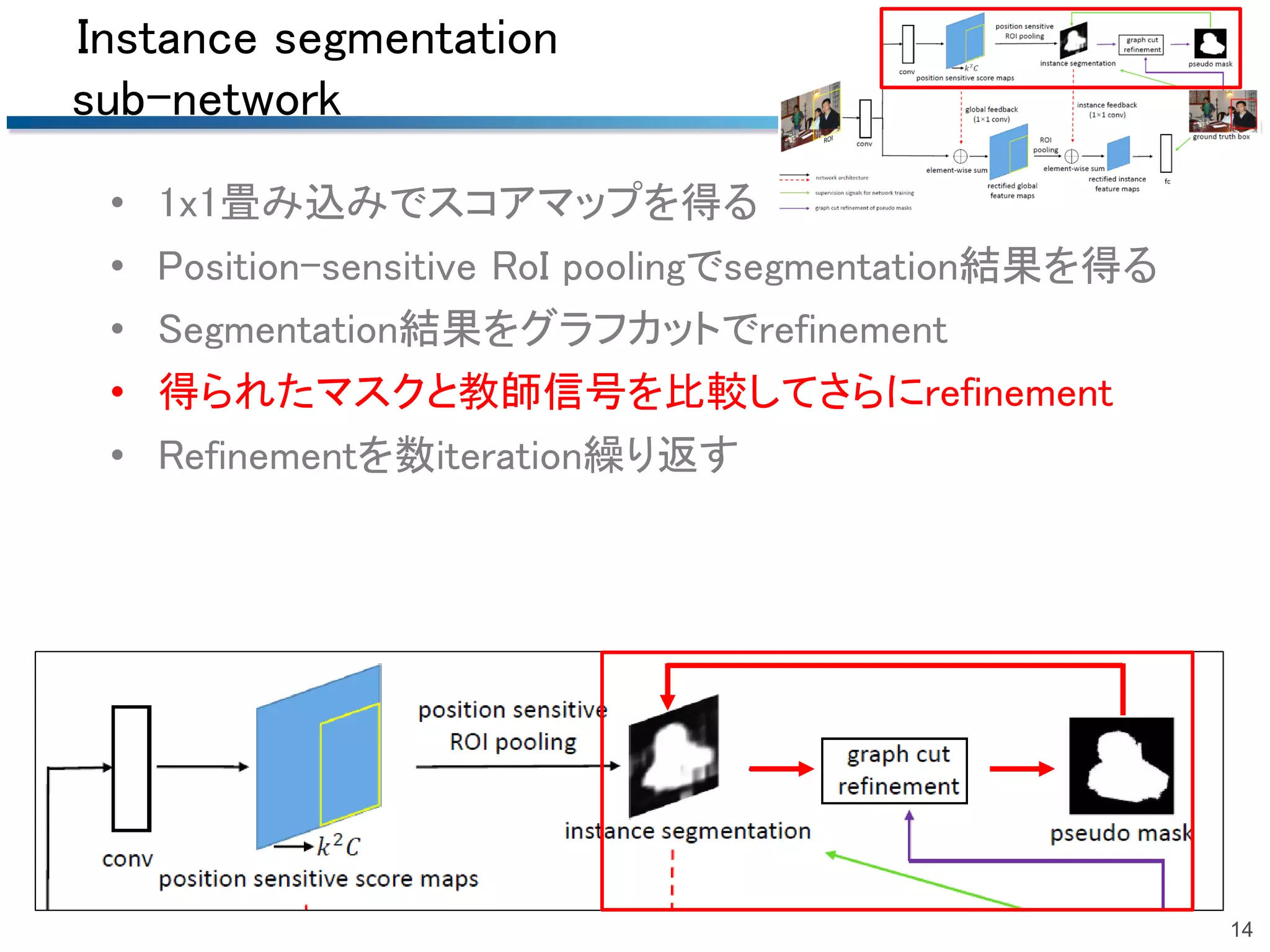
2018/06/23 第51回名古屋CV・PRML勉強会@中部大学名古屋キャンパスでの発表資料です.精読はしていませんので大枠だけです. 概要:Bounding boxでの物体検出でグラフカットを用いて擬似的なマスク(セグメンテーション)のrefinementを行う手法.
![CVPR2018論文紹介
Pseudo Mask Augmented Object Detection
Xiangyun Zhao[Northwestern Univ.], Shuang Liang[Tongji Univ.]
and Yichen Wei[MS Research]
中部大学大学院 工学研究科 情報工学専攻 博士前期過程
荒木 諒介
2018/06/23 第51回 名古屋CV・PRML勉強会@中部大学名古屋キャンパス](https://image.slidesharecdn.com/pseudomaskaugmentedobjectdetection-180623034957/75/CVPR2018-Pseudo-Mask-Augmented-Object-Detection-1-2048.jpg)


















![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Geometric Unsupervised Domain Adaptation for Semantic Segmentation](https://cdn.slidesharecdn.com/ss_thumbnails/20220121gudalin-220121050547-thumbnail.jpg?width=640&height=640&fit=bounds)













