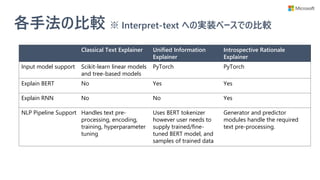
Google が 2018 年に発表した深層モデル BERT は、自然言語処理 (NLP) の多くのタスクでブレイクスルーを起こしました。性能面で進歩がある一方で、公平性に関するガイドラインが総務省から発表される等、産業界では解釈可能な AI を求める声が大きくなってきています。そこで本セッションでは、このギャップを埋めるために Microsoft Research が開発している、interpret-text と呼ばれる機械学習ライブラリをご紹介します。BERT を含む、様々な自然言語処理モデルを解釈するための 2 つの方法について解説し、簡単なデモをお見せします。
Deep Learning Digital Conference - connpass
https://dllab.connpass.com/event/178714/








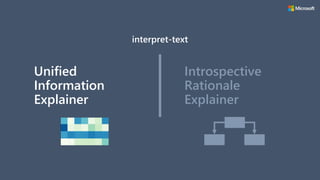
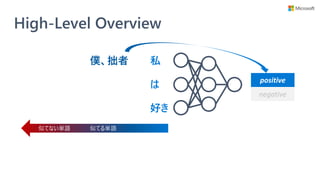
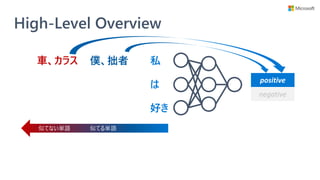
![Unified Information Explainer
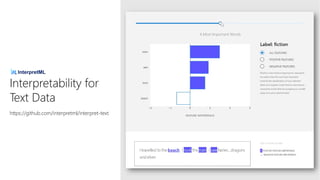
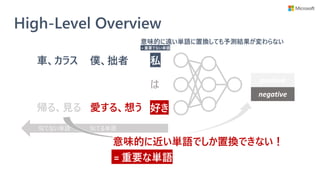
• Microsoft Research が ICML 2019 で
提案した state-of-the-art な解釈手法
• 情報理論の考え方がベース
• 学習済みモデルを解釈
• 特徴
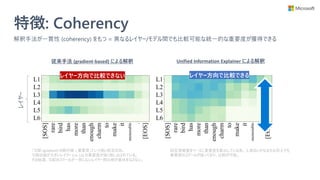
• レイヤー間やモデル間で一貫性のある解釈を獲得出来る
• 活性化関数やアーキテクチャに制約がなく、任意の DNN モデルに対して適用できる
• 現在 interpret-text としては BERT のみを実装済み
• 将来的に LSTM, RNN に対応予定
Towards A Deep and Unified Understanding of Deep Neural Models in NLP, Guan et al. [ICML 2019]](https://image.slidesharecdn.com/20200801interpret-text-200731231317/85/BERT-interpret-text-NLP-11-320.jpg)
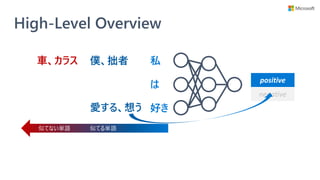
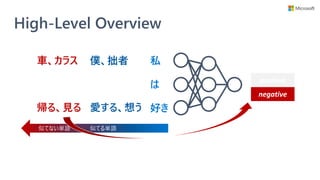

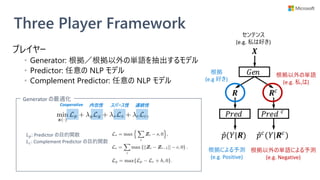
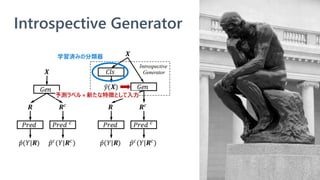
![Introspective Rationale Explainer
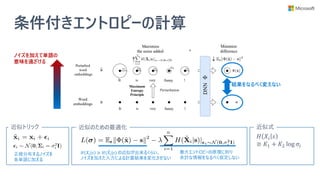
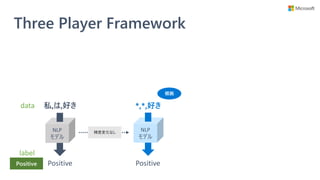
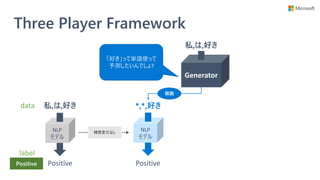
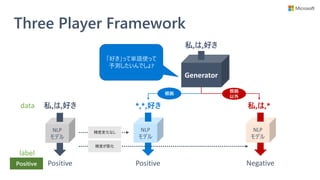
• モデル学習時に説明性を提供するモジュールも学
習するフレームワーク (Three Player Framework)
を提供
• 学習済みモデルへの解釈手法ではない
• 予測に不可欠な単語集合 (根拠) を選択できるモ
ジュールを、モデル学習時に一緒に獲得する
• 任意の NLP モデルに対して使える
• 別のモジュールで説明性を得るので、NLP モデル自体に
特に配慮が要らない
Rethinking Cooperative Rationalization: Introspective Extraction and Complement Control, Yu et al. [EMNLP 2019]
解釈用
モジュール
任意の
NLP モデル
解釈モジュールの
検証用モデル](https://image.slidesharecdn.com/20200801interpret-text-200731231317/85/BERT-interpret-text-NLP-23-320.jpg)








![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL Hacks]Pretraining-Based Natural Language Generation for Text Summarizatio...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspretraining-basednaturallanguagegenerationfortextsummarization-190422070150-thumbnail.jpg?width=640&height=640&fit=bounds)











