Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
24,118 views
[DL輪読会] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
2017/8/28 Deep Learning JP: http://deeplearning.jp/seminar-2/
Technology
◦
Related topics:
Deep Learning
•
Read more
4
Save
Share
Embed
Embed presentation
Download
Downloaded 84 times
1
/ 29
2
/ 29
3
/ 29
4
/ 29
5
/ 29
6
/ 29
7
/ 29
8
/ 29
9
/ 29
10
/ 29
11
/ 29
12
/ 29
13
/ 29
14
/ 29
15
/ 29
16
/ 29
17
/ 29
18
/ 29
19
/ 29
20
/ 29
21
/ 29
22
/ 29
23
/ 29
24
/ 29
25
/ 29
26
/ 29
27
/ 29
28
/ 29
29
/ 29
More Related Content
PDF
最適輸送の計算アルゴリズムの研究動向
by
ohken
PDF
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
PDF
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
PDF
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
PDF
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
PPTX
【輪読会】Learning Continuous Image Representation with Local Implicit Image Funct...
by
Deep Learning JP
PDF
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
最適輸送の計算アルゴリズムの研究動向
by
ohken
SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜
by
SSII
深層学習によるHuman Pose Estimationの基礎
by
Takumi Ohkuma
組合せ最適化入門:線形計画から整数計画まで
by
Shunji Umetani
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
【輪読会】Learning Continuous Image Representation with Local Implicit Image Funct...
by
Deep Learning JP
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
What's hot
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PPTX
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
PDF
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
PPTX
[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation
by
Deep Learning JP
PPTX
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
PPTX
[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection
by
Deep Learning JP
PDF
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
PDF
【メタサーベイ】Video Transformer
by
cvpaper. challenge
PPTX
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
PDF
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
PDF
[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−
by
Deep Learning JP
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
PDF
SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向
by
SSII
PDF
Transformer メタサーベイ
by
cvpaper. challenge
PDF
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
PDF
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
PPTX
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
PDF
【DL輪読会】GAN-Supervised Dense Visual Alignment (CVPR 2022)
by
Deep Learning JP
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
【DL輪読会】言語以外でのTransformerのまとめ (ViT, Perceiver, Frozen Pretrained Transformer etc)
by
Deep Learning JP
【DL輪読会】Perceiver io a general architecture for structured inputs & outputs
by
Deep Learning JP
[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation
by
Deep Learning JP
畳み込みニューラルネットワークの高精度化と高速化
by
Yusuke Uchida
[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection
by
Deep Learning JP
機械学習モデルの判断根拠の説明(Ver.2)
by
Satoshi Hara
【メタサーベイ】Video Transformer
by
cvpaper. challenge
【DL輪読会】SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
by
Deep Learning JP
Skip Connection まとめ(Neural Network)
by
Yamato OKAMOTO
【DL輪読会】ViT + Self Supervised Learningまとめ
by
Deep Learning JP
[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−
by
Deep Learning JP
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
by
Deep Learning JP
SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向
by
SSII
Transformer メタサーベイ
by
cvpaper. challenge
Layer Normalization@NIPS+読み会・関西
by
Keigo Nishida
画像生成・生成モデル メタサーベイ
by
cvpaper. challenge
[DL輪読会]逆強化学習とGANs
by
Deep Learning JP
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
【DL輪読会】GAN-Supervised Dense Visual Alignment (CVPR 2022)
by
Deep Learning JP
Similar to [DL輪読会] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
PDF
夏のトップカンファレンス論文読み会 / Realtime Multi-Person 2D Pose Estimation using Part Affin...
by
Shunsuke Ono
PDF
CVPR2011 Festival PDF
by
Masafumi Noda
PDF
論文紹介:Deep Learning-Based Human Pose Estimation: A Survey
by
Toru Tamaki
PDF
CVPR2017勉強会 Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
by
Koichi Takahashi
PPTX
[DL輪読会]Whole-Body Human Pose Estimation in the Wild
by
Deep Learning JP
PDF
論文紹介:2D Pose-guided Complete Silhouette Estimation of Human Body in Occlusion
by
Toru Tamaki
PPTX
[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...
by
Deep Learning JP
PPTX
[DL輪読会]3D Human Pose Estimation @ CVPR’19 / ICCV’19
by
Deep Learning JP
PDF
20201010 personreid
by
Takuya Minagawa
PDF
【DL輪読会】Monocular real time volumetric performance capture
by
Deep Learning JP
PPTX
[DL輪読会]Human Pose Estimation @ ECCV2018
by
Deep Learning JP
PPTX
The 53th Computer Vision Study@ kantou by Takamitsu Omasa
by
WEBFARMER. ltd.
PDF
複数人物姿勢推定におけるKnowledge Distillationを用いた教師ラベル補正手法の提案
by
Naoki Kato
PPTX
DLゼミ: Ego-Body Pose Estimation via Ego-Head Pose Estimation
by
harmonylab
PDF
CVPR 2019 report (30 papers)
by
ShunsukeNakamura17
PPTX
CVPR Festival
by
Masafumi Noda
PDF
DeepPose: Human Pose Estimation via Deep Neural Networks
by
Shunta Saito
PPTX
2018 07 02_dense_pose
by
harmonylab
PDF
Object as Points
by
harmonylab
PDF
【DLゼミ】XFeat: Accelerated Features for Lightweight Image Matching
by
harmonylab
夏のトップカンファレンス論文読み会 / Realtime Multi-Person 2D Pose Estimation using Part Affin...
by
Shunsuke Ono
CVPR2011 Festival PDF
by
Masafumi Noda
論文紹介:Deep Learning-Based Human Pose Estimation: A Survey
by
Toru Tamaki
CVPR2017勉強会 Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
by
Koichi Takahashi
[DL輪読会]Whole-Body Human Pose Estimation in the Wild
by
Deep Learning JP
論文紹介:2D Pose-guided Complete Silhouette Estimation of Human Body in Occlusion
by
Toru Tamaki
[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...
by
Deep Learning JP
[DL輪読会]3D Human Pose Estimation @ CVPR’19 / ICCV’19
by
Deep Learning JP
20201010 personreid
by
Takuya Minagawa
【DL輪読会】Monocular real time volumetric performance capture
by
Deep Learning JP
[DL輪読会]Human Pose Estimation @ ECCV2018
by
Deep Learning JP
The 53th Computer Vision Study@ kantou by Takamitsu Omasa
by
WEBFARMER. ltd.
複数人物姿勢推定におけるKnowledge Distillationを用いた教師ラベル補正手法の提案
by
Naoki Kato
DLゼミ: Ego-Body Pose Estimation via Ego-Head Pose Estimation
by
harmonylab
CVPR 2019 report (30 papers)
by
ShunsukeNakamura17
CVPR Festival
by
Masafumi Noda
DeepPose: Human Pose Estimation via Deep Neural Networks
by
Shunta Saito
2018 07 02_dense_pose
by
harmonylab
Object as Points
by
harmonylab
【DLゼミ】XFeat: Accelerated Features for Lightweight Image Matching
by
harmonylab
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
[DL輪読会] Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
1.
Realtime Multi-Person 2D
Pose Estimation using Part Affinity Fields 東京⼤学⼤学院⼯学系研究科 技術経営戦略学専攻 松尾研究室 ⼤野峻典
2.
書誌情報 2 • 論⽂名:“Realtime Multi-Person
2D Pose Estimation using Part Affinity Fields” – https://arxiv.org/abs/1611.08050 • 著者:Zhe Cao, Tomas Simon, Shih-En Wei, Yaser Sheikh – The Robotics Institute, Carnegie Mellon University • 公開⽇:24 Nov 2016 • CVPR 2017 Oral • Slide • Video • ※ 特に断りが無い場合は, 上記論⽂, Slide, Videoから引⽤
3.
できること • 体の部位をリアルタイムに推定できる. • こんな感じ. 3
4.
Abstract • 画像中の複数⼈の2Dポーズを効率的に検出する⼿法の提案している. • ⼿法の特徴 –
Part Affinity Fields(PAFs):⾝体部位と個々⼈の関連付けを学習している. – ボトムアップ的アプローチ:画像全体中の⽂脈をエンコードし, ⼈数によらず, ⾼速・ ⾼精度を維持. – Sequential Prediction with Learned Spatial Context:CNNで予測を⾏うユニットを 繰り返す. – Jointly Learning Parts detection and Parts Association:部位の場所とその関連付け を共同で学習する • 結果 – COCO2016keypoints challengeで1位, MPII Multi-Person benchmarkにおいて効 率・精度ともにsota上回った. 4
5.
Introduction • 既存研究では, 複数⼈の絡む状況での個々⼈の⾝体部位検知は難しい問題として知られてき た. –
⼈数, スケールが不定 – ⼈同⼠のインタラクション – ⼈数に⽐例して計算量増加 • top-down的アプローチ:⼈の検知を⾏い, その後に個⼈の姿勢推定を⾏う. – ❌ ① 画像内の⼈の検知に失敗すると、姿勢推定できない – ❌ ② ⼈数に⽐例して計算量増加 • bottom-up的アプローチ:← 本論⽂はこっち. – ⭕ ①ʼ 上記①に対して, ロバスト. – ⭕ ②ʼ 計算量抑えうる – ❌ 既存の⼿法では, 他の体部位や⼈からのグローバルなコンテキスト情報を直接的には使えておらず, 部位のつなぎ合わせの推定の計算量がかかり, ⾮効率. • → 本論⽂では, ここを改善. • 本論⽂では, bottom-upアプローチで, 複数⼈のポーズ推定をSoTAの精度で達成. – Part Affinity Fields(PAFs)によって部位同⼠の関連度を表現:体部位の場所, 向きをエンコードした2 次元ベクトル. – 部位検知と関連度のボトムアップ的な表現を同時に推定することで, グローバルなコンテキストが⼗ 分エンコードできる. それにより, ⾼精度・⾼速を実現した. 5
6.
Method • Feed forward
network により, 体部位の位置の confidence map S (図b) と, ベクタで部分間の関連度をエンコードした affinity fields L (図c)を作成. – S = (S1, S2, …, SJ) で J個のconfidence mapsを持つ. J個の部位にそれぞれ対応. • Sj ∈ Rw×h, j ∈ {1…J} – L = (L1, L2, …, LC) で C個のベクタ持ち, それぞれ各部位ペアに対応. • Lc ∈ R w×h×2, c ∈ {1…C} • confidence mapとaffinity fieldsを元に, Bipartite Matching(2点間の関係 性計算)を⾏う(図d) 6 <⼊⼒から出⼒の流れ> ⼊⼒ 出⼒
7.
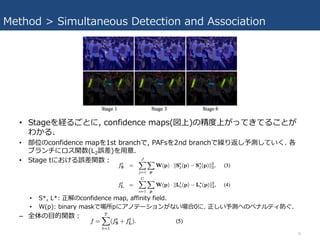
Method > Simultaneous
Detection and Association • 部位検知の confidence map と部位関係エンコードの affinity fields を同時に 予測. • 2つのブランチ; [図上] confidence mapを予測, [図下] affinity fieldsを予測. • 画像はまずConv層(VGG-19の最初10層で初期化)で処理され, 特徴マップFとし て, Stage1の⼊⼒になる. • Stage1で, 検知 confidence map S1 = ρ1(F)と, part affinity fieldsのセット L1 = Φ1(F)を⽣成する. (ρ, ΦはそれぞれのstageにおけるCNNs) • 前のStageの出⼒2つと元の特徴マップFがつなぎ合わされて次の⼊⼒になる. 7
8.
Method > Simultaneous
Detection and Association • Stageを経るごとに, confidence maps(図上)の精度上がってきてることが わかる. • 部位のconfidence mapを1st branchで, PAFsを2nd branchで繰り返し予測していく. 各 ブランチにロス関数(L2誤差)を⽤意. • Stage tにおける誤差関数: • S*, L*: 正解のconfidence map, affinity field. • W(p): binary maskで場所pにアノテーションがない場合0に. 正しい予測へのペナルティ防ぐ. – 全体の⽬的関数: 8
9.
Method > Confidence
Maps for Part Detection • 式5での評価のため, 正解のmap S*をアノテーションされた2Dキーポイン トから⽣成する. • 複数⼈いて, 各部位が⾒えるとき, 各部位j, ⼈kに対応するconfidence map のピークが存在すべき. • まず, 個々のconfidence maps S*j,k (正解値)を各⼈kに⽣成する. – xj,k∈R2を部位j⼈kの画像中の正解位置とすると, S*jkにおける各場所p∈R2は以下のよ うに定義される. • σ: ピークの広がり具合を調整する項 – ネットワークから予測される形式に合わせて, 全ての⼈に関してmapをあわせて, 各部 位に関する正解のconfidence mapは以下のようにかける. (maxオペレータ) 9
10.
Method > Confidence
Maps for Part Detection • Confidence mapsの平均を取るのでは無く、最⼤値を取るようにすること で、峰に近い場所が明確のままであれる。 • テスト時は、predictしたconfidence mapsを⽤いて、non-maximum suppressionを⾏うことで、体部位の予測位置を得る。 – (補⾜)Non-maximum suppression:閾値以上の割合で分布がかぶっている場合、 最も⾼いconfidence を持つ分布を残す. 10
11.
Method > Part
Affinity Fields for Part Association • 任意の⼈数の⼈に関して, 検知された部位同⼠をいかにつなげるか. (図a) – 中間点を取る? 複数⼈が近かったりするとうまくつなぎ合わせられない(図b) • 位置のみのエンコードで向き情報ないなど表現⼒の限界. • → Part affinity fields:位置情報, 向き情報を含んだ表現(図c) – 各limb(部位のつなぎ合わせ部分)に対して各2Dベクトル – 各limbは関連する部位をつなぐaffinity fieldを持つ. 11
12.
Method > Part
Affinity Fields for Part Association • ベクトル値の決め⽅ – xj1,k , xj2,k: ⼈kのlimb c における部位j1,j2の正解値とする. – Limb c上のpoint p達に関して, L*c,k(p)はj1からj2への単位ベクトルになる. Limb c外 のpoint pにおいては全てzeroベクトルに. 定式化すると以下. • v = (xj2,k-xj1,k) / || xj2,k-xj1,k ||2 (limbの向きの単位ベクトル) – Limb c上かどうかの判定は以下の式で定義. • 幅σlはピクセル距離, lc,kは部位間のユークリッド距離. 12
13.
Method > Part
Affinity Fields for Part Association • ネットワークから予測される形に合わせて全ての⼈に関してfieldsをあわせ てlimbごとのfieldを⽣成. (average) – nc(p):point p においてk peopleの中でゼロじゃないベクトルの数(limbが重なった場 合に平均取りたいため) • テスト時は, 対応するPAFの線積分を候補部位の位置を結ぶ線分に沿って計 算することで, 候補部位間の関連度を測る. (= 検出された部位を結ぶことで 作られる候補limbと, 予測されたPAF間の⼀致度を測る) – 具体的には, 2つの候補部位dj1とdj2に対して, 予測されたPAF Lcを部位間の線分に沿っ てサンプリングして, 部位の関連度のconfidenceを計測する. • p(u):2つの部位dj1とdj2をつなぐ位置 – 実⽤上は, ⼀定間隔のuの値を合計して積分を近似している. 13
14.
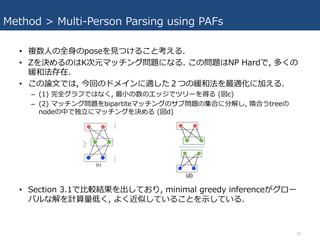
Method > Multi-Person
Parsing using PAFs • 各部位に関して複数検知される場所があり(複数⼈ or 偽陽性ゆえ), その 分可能なlimbのパターンが多く存在. • AF上の線積分計算により各候補limbにスコアをつける. 最適な組み合わせを ⾒つける問題は, NP-Hard問題であるK次元のマッチング問題に対応する. – → greedy 緩和法によって対処できる. – その理由は, PAFネットワークの受容野が⼤きいため, pair-wiseの関連度スコアが暗黙 にグローバルコンテキストをエンコードしているためと考えられる. (後述) • まず, 複数⼈の候補部位の集合を得る. – DJ = {dj m : for j ∈ {1…J}, m ∈{1…Nj} } • Nj: 部位jの候補数 • dj m ∈ R2: は部位jのm番⽬の検知候補. • 部位候補 dj1 mとdj2 nがつながっているか⽰す変数 z j1j2 mn ∈{0,1}を定義. – ゴールは, 可能な繋がりのうち最適な組み合わせを⾒つけること. – 以下Zはzの全組み合わせに関する集合. 14
15.
Method > Multi-Person
Parsing using PAFs • あるc番⽬のlimbにつながるj1とj2のペアを考える. – 式10で求めたcにおける重みが最⼤になるような⼆点間マッチングを⾏う. – Ecはlimb type cのマッチングの全体の重みで, Zcはlimb type cのZのサブセットで, Emnは部位dj1 mとdj2 n間のpart affinity (式10で定義) – 式13,14は, 2つのエッジがノードをシェアするのを防ぐ. (同じtypeの2つのlimbが部 位の共有を防ぐ.) Hungarian algorithmで最適解⾒つける. 15
16.
Method > Multi-Person
Parsing using PAFs • 複数⼈の全⾝のposeを⾒つけること考える. • Zを決めるのはK次元マッチング問題になる. この問題はNP Hardで, 多くの 緩和法存在. • この論⽂では, 今回のドメインに適した2つの緩和法を最適化に加える. – (1) 完全グラフではなく, 最⼩の数のエッジでツリーを得る (図c) – (2) マッチング問題をbipartiteマッチングのサブ問題の集合に分解し, 隣合うtreeの nodeの中で独⽴にマッチングを決める (図d) • Section 3.1で⽐較結果を出しており, minimal greedy inferenceがグロー バルな解を計算量低く, よく近似していることを⽰している. 16
17.
Method > Multi-Person
Parsing using PAFs • 2つの緩和法で, 最適化は以下のようにシンプルに分解される. • ゆえに, 各limb typeに対して, 式12-14(各limb cに対してjoint⾒つけるや つ)を使って, 独⽴に, limbの繋がり候補を得る. • 全てのlimb繋がり候補を持って, 同じ候補部位をシェアする繋がりを組みわ せて, 複数⼈の全⾝のposeを作る. 17
18.
Results • 複数⼈pose estimationの2つのベンチマーク –
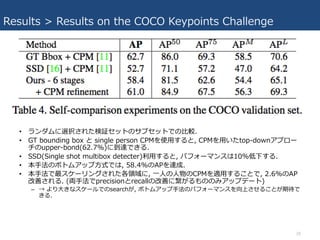
(1) MPII human multi-person dataset (25k images, 40k ppl, 410 human activities) – (2) the COCO 2016 keypoints challenge dataset • いろんな実世界の状況の画像を含んだデータセット • それぞれSotA. • 計算効率に関する考察も加えた(Fig10. 後述) 18
19.
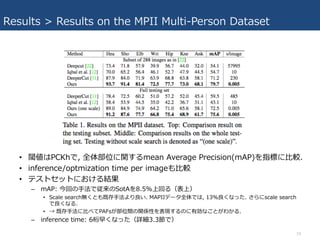
Results > Results
on the MPII Multi-Person Dataset • 閾値はPCKhで, 全体部位に関するmean Average Precision(mAP)を指標に⽐較. • inference/optmization time per imageも⽐較 • テストセットにおける結果 – mAP: 今回の⼿法で従来のSotAを8.5%上回る(表上) • Scale search無くとも既存⼿法より良い. MAPIIデータ全体では, 13%良くなった. さらにscale search で良くなる. • → 既存⼿法に⽐べてPAFsが部位間の関係性を表現するのに有効なことがわかる. – inference time: 6桁早くなった(詳細3.3節で) 19
20.
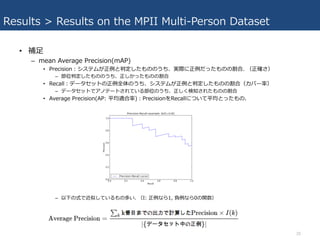
Results > Results
on the MPII Multi-Person Dataset • 補⾜ – mean Average Precision(mAP) • Precision:システムが正例と判定したもののうち、実際に正例だったものの割合. (正確さ) – 部位判定したもののうち、正しかったものの割合 • Recall:データセットの正例全体のうち、システムが正例と判定したものの割合(カバー率) – データセットでアノテートされている部位のうち、正しく検知されたものの割合 • Average Precision(AP: 平均適合率):PrecisionをRecallについて平均とったもの. – 以下の式で近似しているもの多い. (I: 正例なら1, 負例なら0の関数) 20
21.
Results > Results
on the MPII Multi-Person Dataset • 補⾜ – mean Average Precision(mAP):今回の場合 • mAP:全ての⼈の部位に対する平均のprecision。 – まず、複数体写っている画像に対してpose estimation実⾏。 – 最も⾼いPCKh閾値にもとづいて、estimateされたポイントをground truth(GT)に割り合ててく。 – GTに割り当てられなかった予測ポイントは、false positiveとして扱う。 – 各部位ごとにAverage Precision(AP)を計算。 – 全体の部位に関してAPの平均を取って、mAPになる。 – PCKh threshhold: • PCP:あるパーツの両端の部位の検出位置が、そのパーツの⻑さの半分よりも正解に近ければ 検出成功とする. • PCK:⼈物のbounding boxサイズの逆数を閾値として定義 • PCKh:Headセグメントの50%の⻑さを閾値として定義 21
22.
Results > Results
on the MPII Multi-Person Dataset • 異なるスケルトン構造の⽐較結果 – (6b) 全てのパターンつないだエッジ, (6c) 最⼩限のツリーエッジで整数リニアプログ ラミングでとかれるもの, (6d) 最⼩限のツリーエッジで貪欲アルゴリズムによってとか れるもの – → 最⼩限のエッジで、性能的には⼗分なことを⽰している. – (6d)のグラフが精度最も良くなっている.トレーニングの収束がはるかに容易になるた めと考えられる.(13 edges vs 91 edges) 22
23.
Results > Results
on the MPII Multi-Person Dataset • PCKh-0.5のしきい値の場合, PAFを使⽤した結果は, 中間点表⽰を利⽤した結果 より優れてる. (one-midpointより2.9%⾼く, two-midpointより2.3%⾼い) • ラベルをつけられていない⼈にマスクを使⽤した訓練で, True Positiveの予測に よる(不当な)ロス防ぐと, 2.3%精度改善できる. • 部位detectionのGround Truthを⽤いて, PAFsで予測⾏うと, mAP 88.3%. そ の場合Detectionにおける誤差が無いので, PCKh閾値によらず⼀定. • 部位connectionのGround Truthを⽤いて, detectだけ⾏うケースでは, mAP 81.6%. – → PAFによるconnection判定と, Ground Truth使⽤でほとんど精度が変わらない. (79.4% vs 81.6%) . PAFが, ⾮常に⾼い精度で検出できること⽰している. • (b) stageごとのmAPの⽐較, 精度上がっていることがわかる. 23
24.
Results > Results
on the COCO Keypoints Challenge • 10万⼈以上の⼈物, 100万以上のkeypoints. • COCOでの評価では, object keypoint similarity (OKS) を定義し, 10個の OKS閾値でのmean average precision (AP) を使⽤する. – OKSは, 物体認識におけるIoUと同じ役割. – ⼈のスケールと, GT位置と予測値の差, の両⽅を⽤いて計算される. • 表3: top teamとの⽐較. • ⽐較的⼩さいスケールの⼈(APM)に於いては, top-downアプローチの⼿法 に精度負けてる. – 理由: 本⼿法では, 他よりはるかに⼤きいスケールで, 画像内の全ての⼈々を⼀⻫に扱わ ないといけない. ⇔ top-downアプローチでは, ⼈を検知してその⼈ごとに切り取って 拡⼤して扱えるので, ⼩さいスケールによる影響が⽐較的値作なる. 24
25.
補⾜: IoU • 引⽤:
http://www.pyimagesearch.com/2016/11/07/intersection- over-union-iou-for-object-detection/ 25
26.
Results > Results
on the COCO Keypoints Challenge • ランダムに選択された検証セットのサブセットでの⽐較. • GT bounding box と single person CPMを使⽤すると, CPMを⽤いたtop-downアプロー チのupper-bond(62.7%)に到達できる. • SSD(Single shot multibox detecter)利⽤すると, パフォーマンスは10%低下する. • 本⼿法のボトムアップ⽅式では, 58.4%のAPを達成. • 本⼿法で最スケーリングされた各領域に, ⼀⼈の⼈物のCPMを適⽤することで, 2.6%のAP 改善される. (両⼿法でprecisionとrecallの改善に繋がるもののみアップデート) – → より⼤きなスケールでのsearchが, ボトムアップ⼿法のパフォーマンスを向上させることが期待で きる. 26
27.
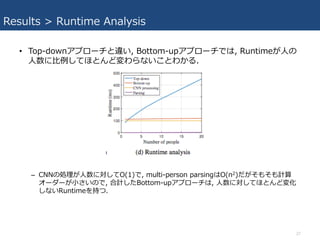
Results > Runtime
Analysis • Top-downアプローチと違い, Bottom-upアプローチでは, Runtimeが⼈の ⼈数に⽐例してほとんど変わらないことわかる. – CNNの処理が⼈数に対してO(1)で, multi-person parsingはO(n2)だがそもそも計算 オーダーが⼩さいので, 合計したBottom-upアプローチは, ⼈数に対してほとんど変化 しないRuntimeを持つ. 27
28.
Discussion • 画像内の⼈物理解において, 複数⼈物の2次元姿勢⼤事. •
今回の⼯夫 – 1. 部位の位置と, ⽅向の両⽅を符号化する表現 – 2. 部位検出と関係性を共同で学ぶアーキテクチャ – 3. greedyアルゴリズムにより⼈の数が増えても計算量抑え, 精度⼗分. • 代表的な失敗事例 28
29.
実装 • C++:https://github.com/CMU-Perceptual-Computing-Lab/openpose • Caffe:https://github.com/ZheC/Realtime_Multi- Person_Pose_Estimation •
PyTorch:https://github.com/tensorboy/pytorch_Realtime_Multi- Person_Pose_Estimation (train未実装) 29
Download







![Method > Simultaneous Detection and Association
• 部位検知の confidence map と部位関係エンコードの affinity fields を同時に
予測.
• 2つのブランチ; [図上] confidence mapを予測, [図下] affinity fieldsを予測.
• 画像はまずConv層(VGG-19の最初10層で初期化)で処理され, 特徴マップFとし
て, Stage1の⼊⼒になる.
• Stage1で, 検知 confidence map S1 = ρ1(F)と, part affinity fieldsのセット L1
= Φ1(F)を⽣成する. (ρ, ΦはそれぞれのstageにおけるCNNs)
• 前のStageの出⼒2つと元の特徴マップFがつなぎ合わされて次の⼊⼒になる.
7](https://image.slidesharecdn.com/realtimemultipersonposeestimation1-170907054459/85/DL-Realtime-Multi-Person-2D-Pose-Estimation-using-Part-Affinity-Fields-7-320.jpg)


















![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/20190517hrnet-190517005504-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]The Neural Process Family−Neural Processes関連の実装を読んで動かしてみる−](https://cdn.slidesharecdn.com/ss_thumbnails/20190415dlhacks-190422075753-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]逆強化学習とGANs](https://cdn.slidesharecdn.com/ss_thumbnails/irlgans-171128063119-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Whole-Body Human Pose Estimation in the Wild](https://cdn.slidesharecdn.com/ss_thumbnails/20200731wholebodyhumanposeestimationinthewildkuboshizuma-200804012445-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023voxelposekuboshizuma-201023025841-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]3D Human Pose Estimation @ CVPR’19 / ICCV’19](https://cdn.slidesharecdn.com/ss_thumbnails/190816dlseminar3dhpe-190816032821-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Human Pose Estimation @ ECCV2018](https://cdn.slidesharecdn.com/ss_thumbnails/180928dlseminarposeestimationeccv2018-180928031032-thumbnail.jpg?width=640&height=640&fit=bounds)




























