Download as PDF, PPTX



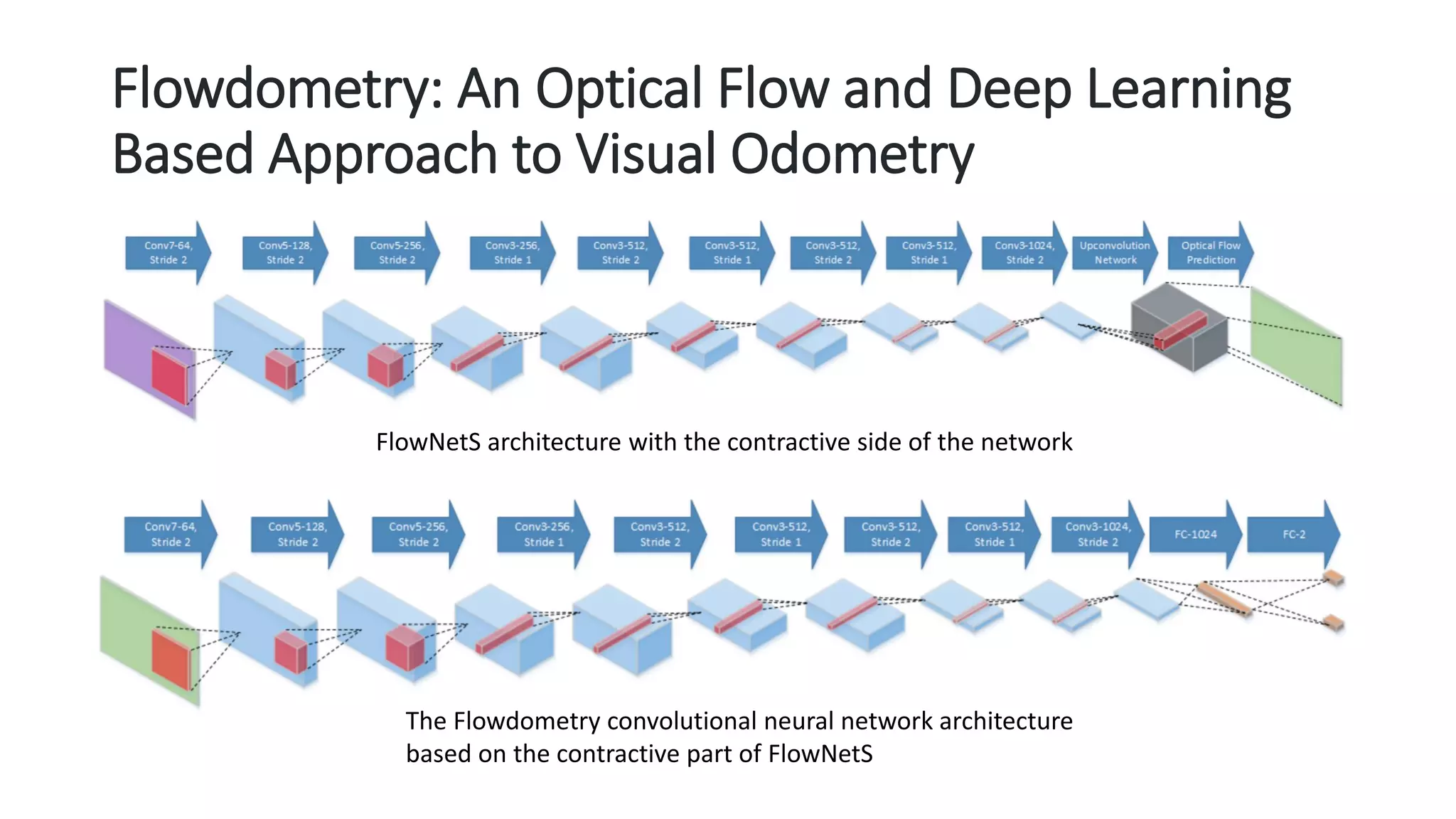
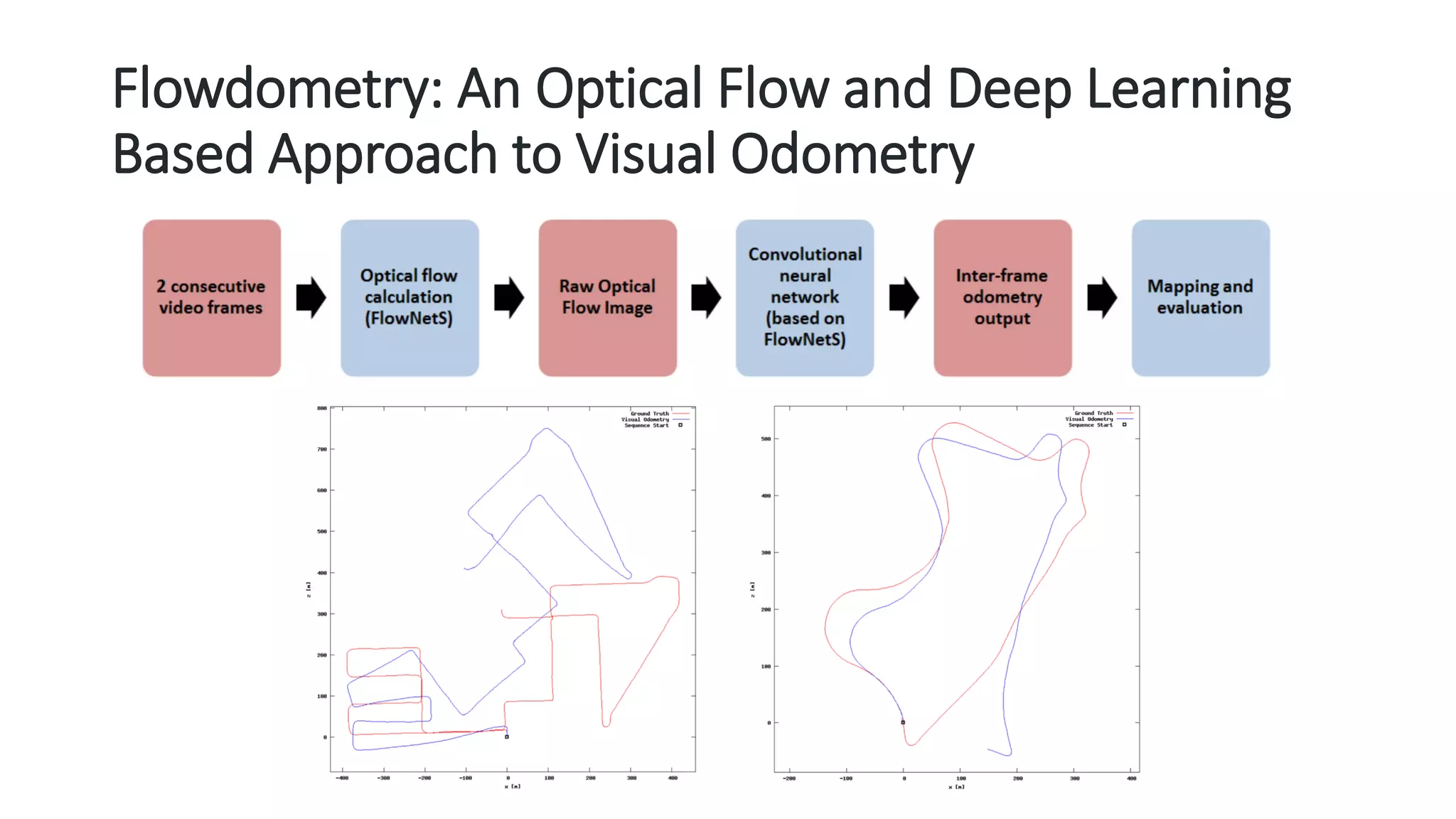





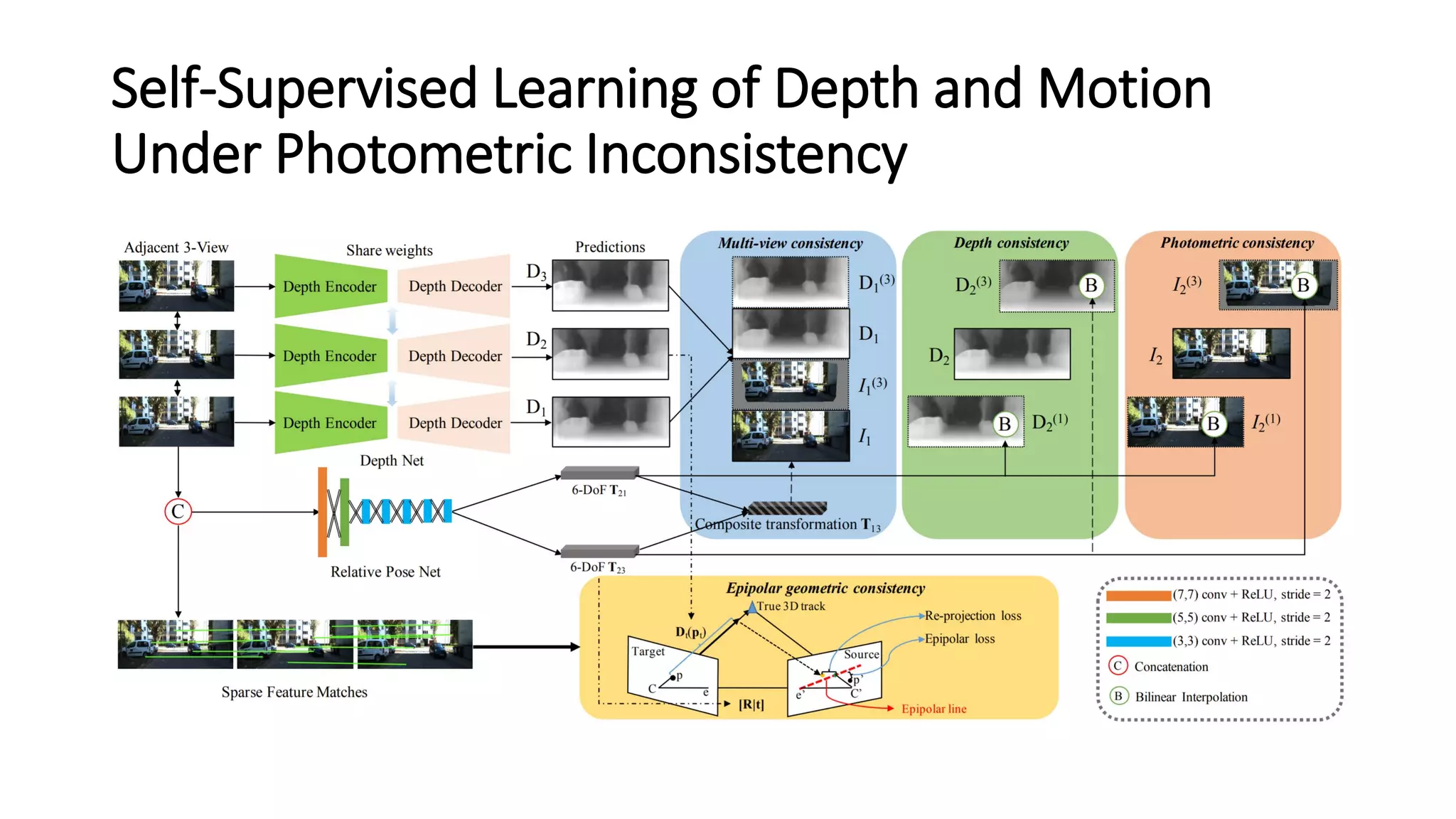
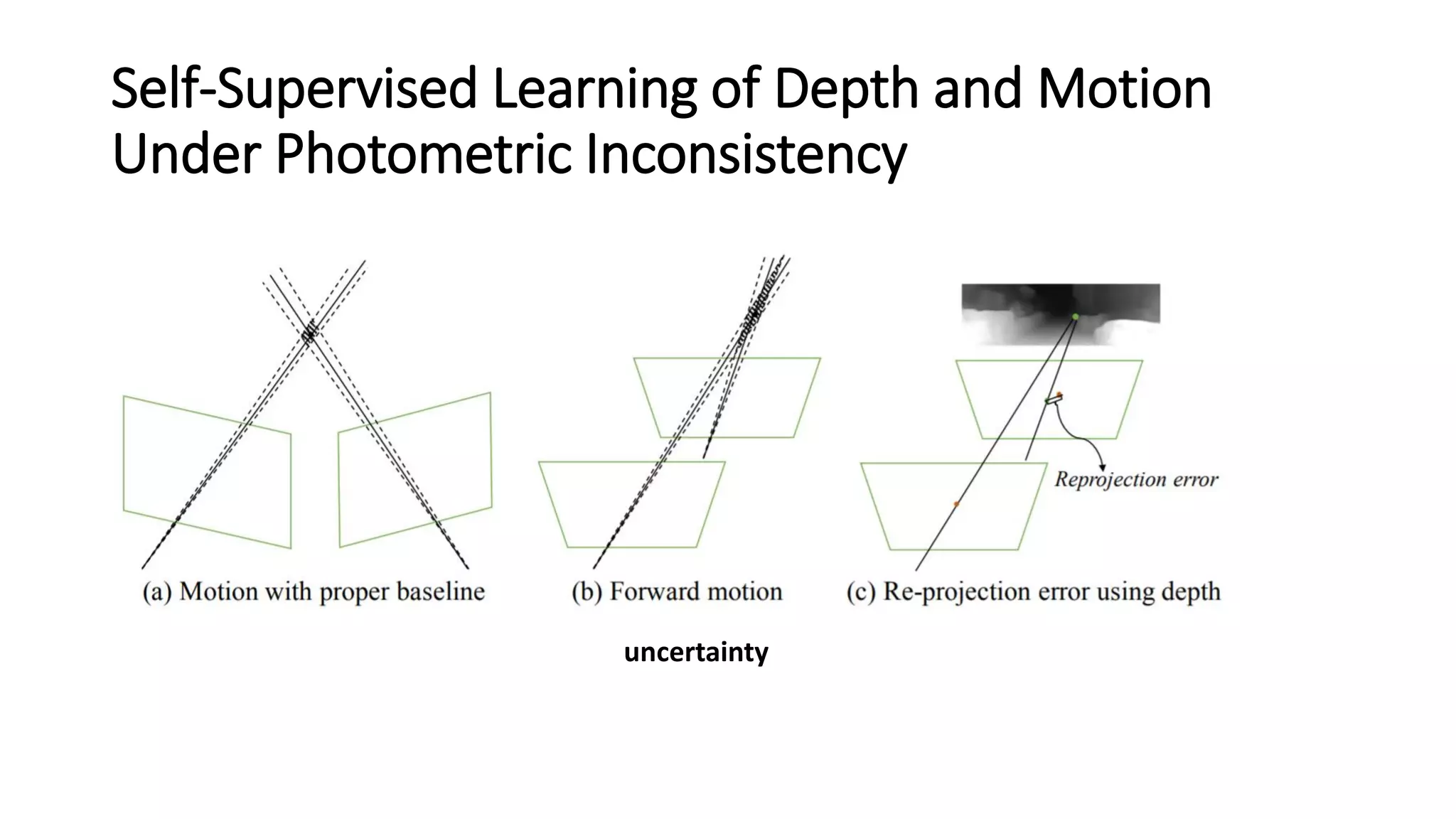
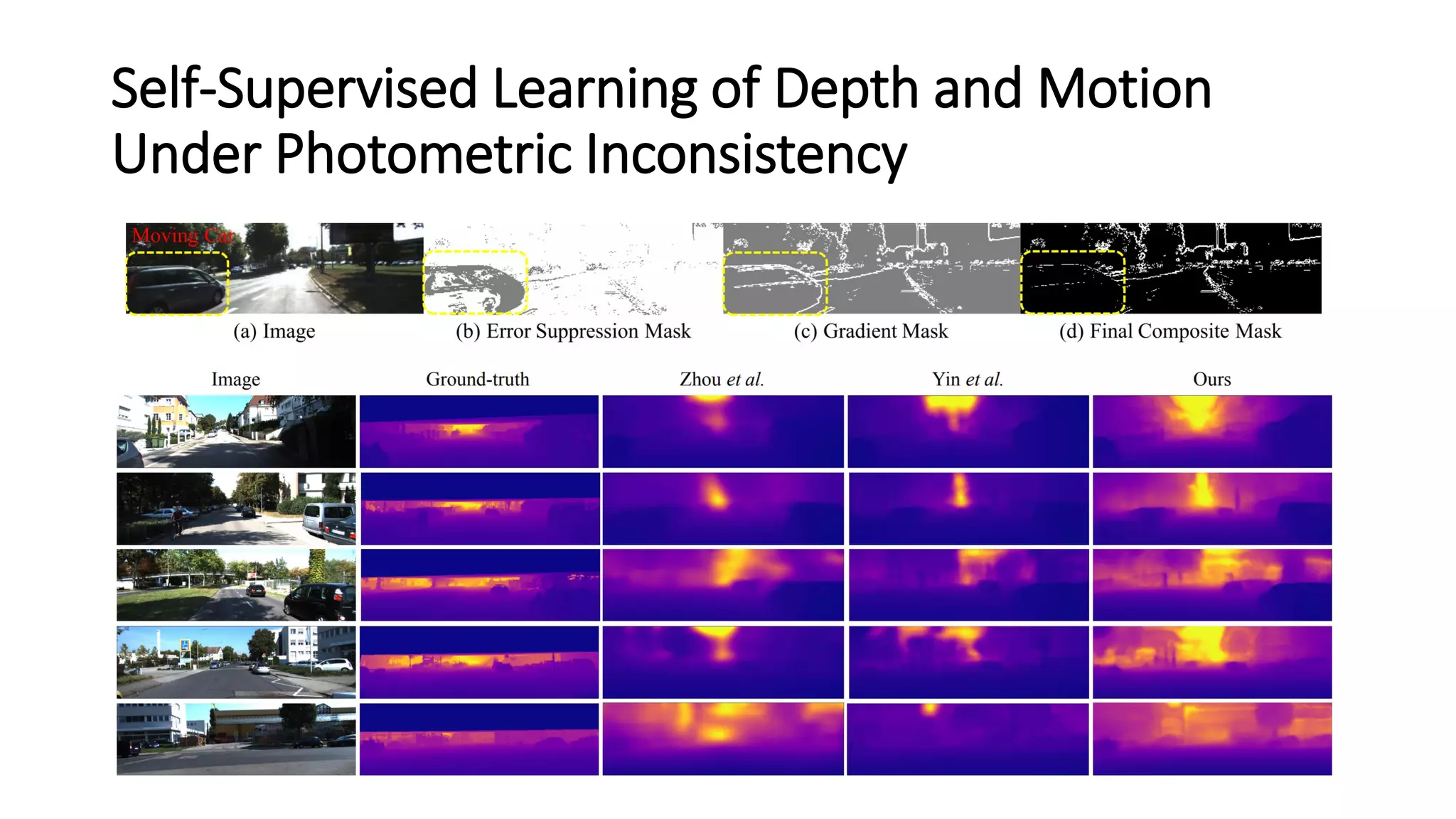


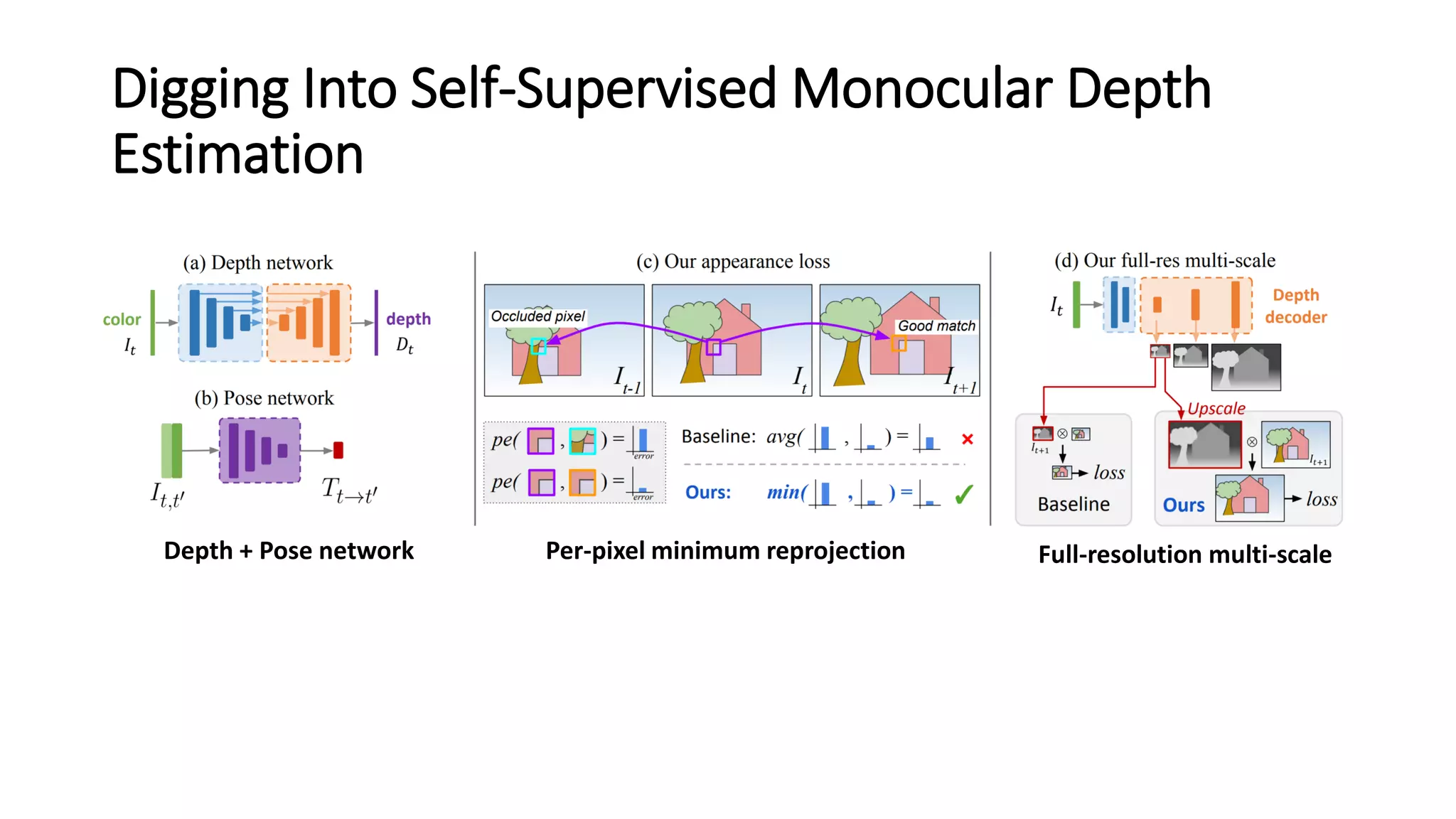


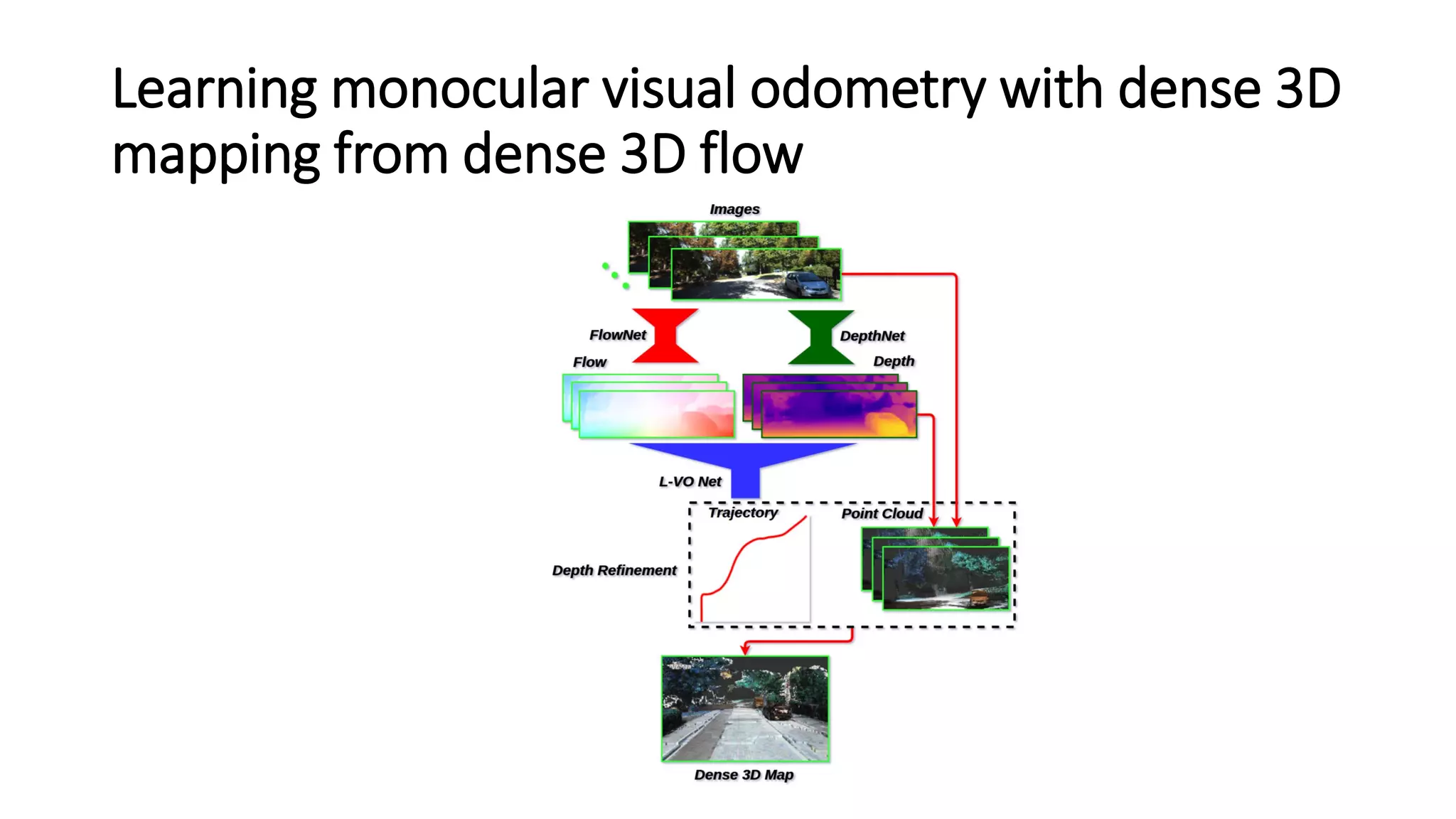
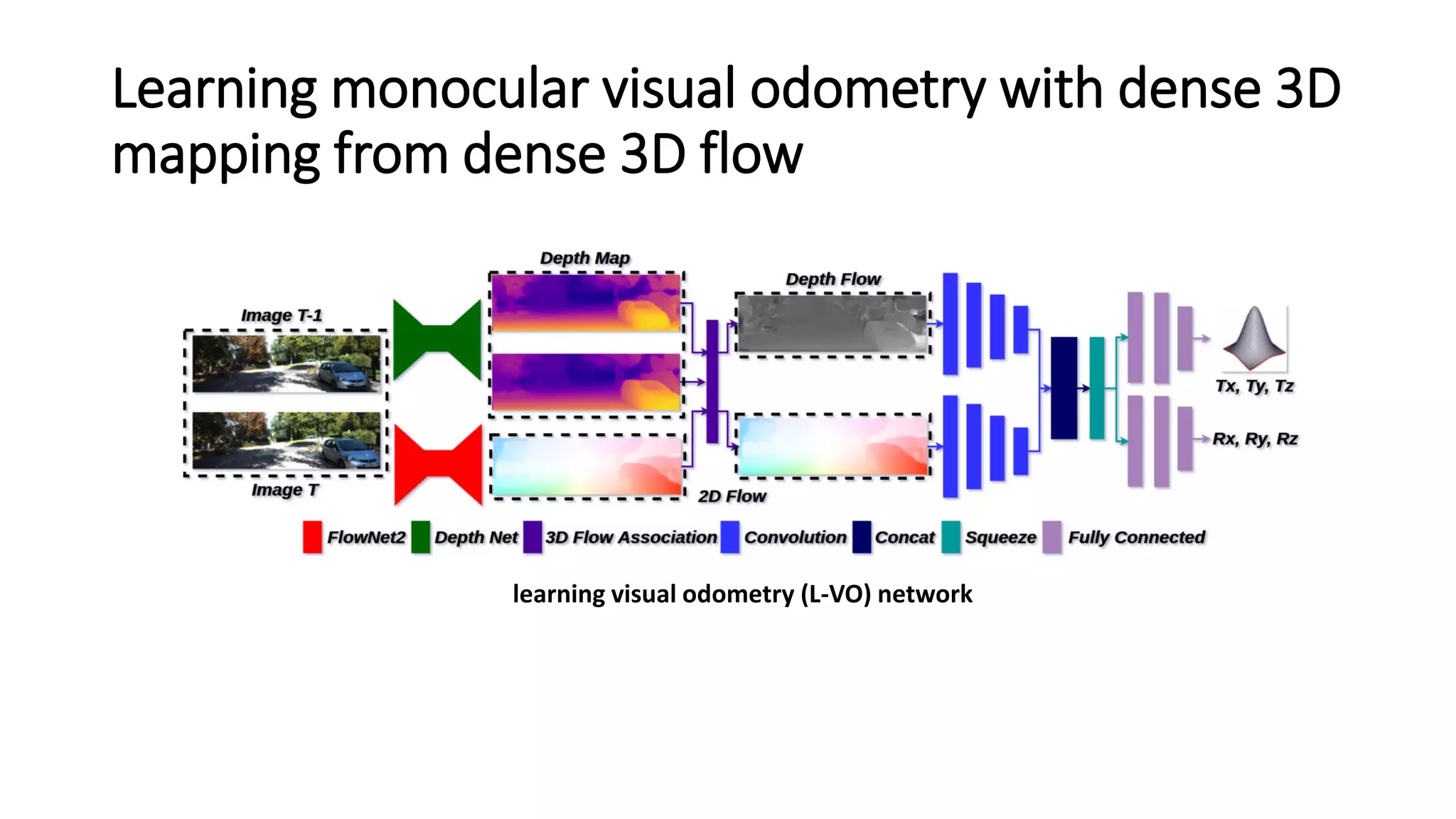
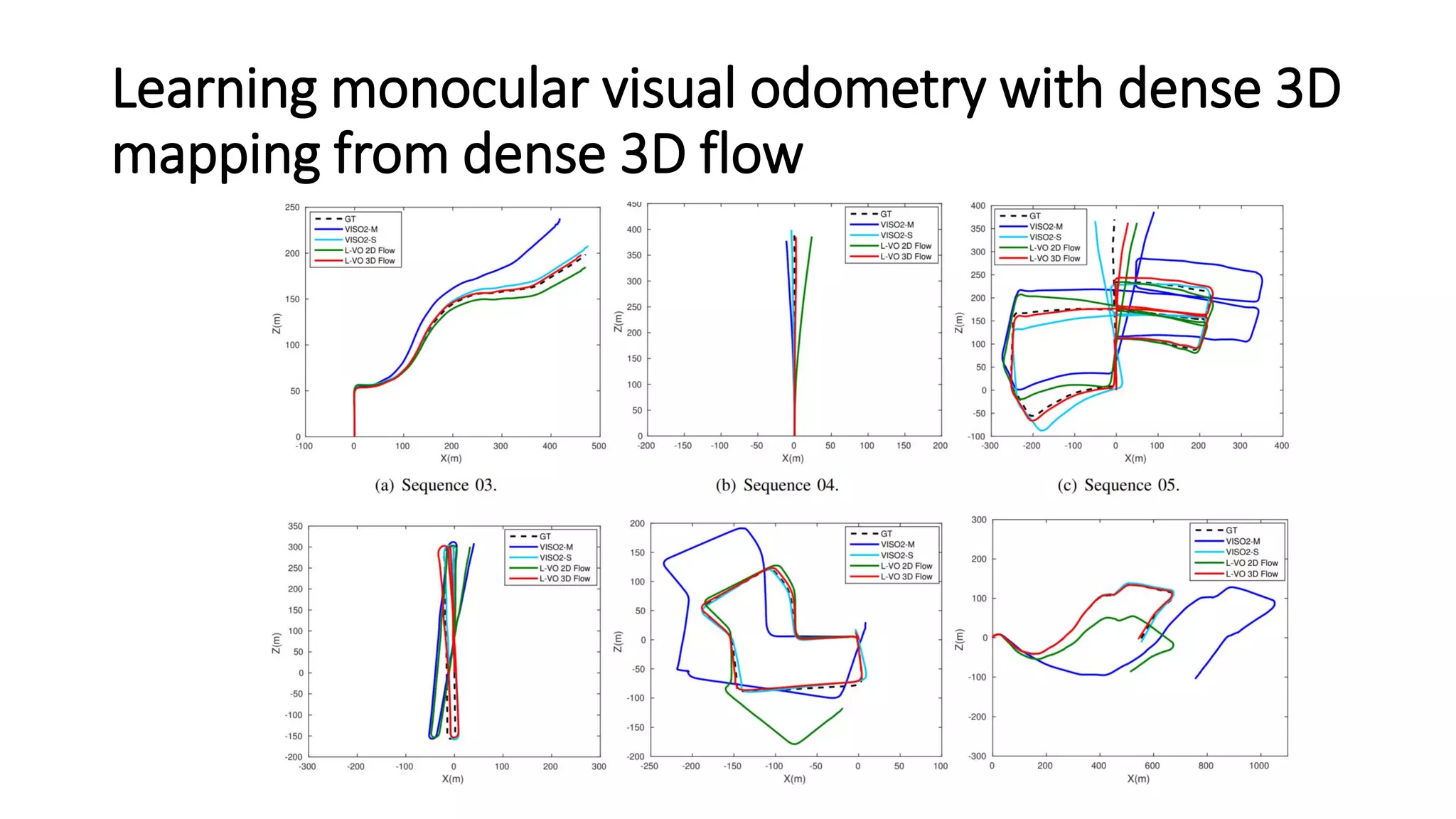


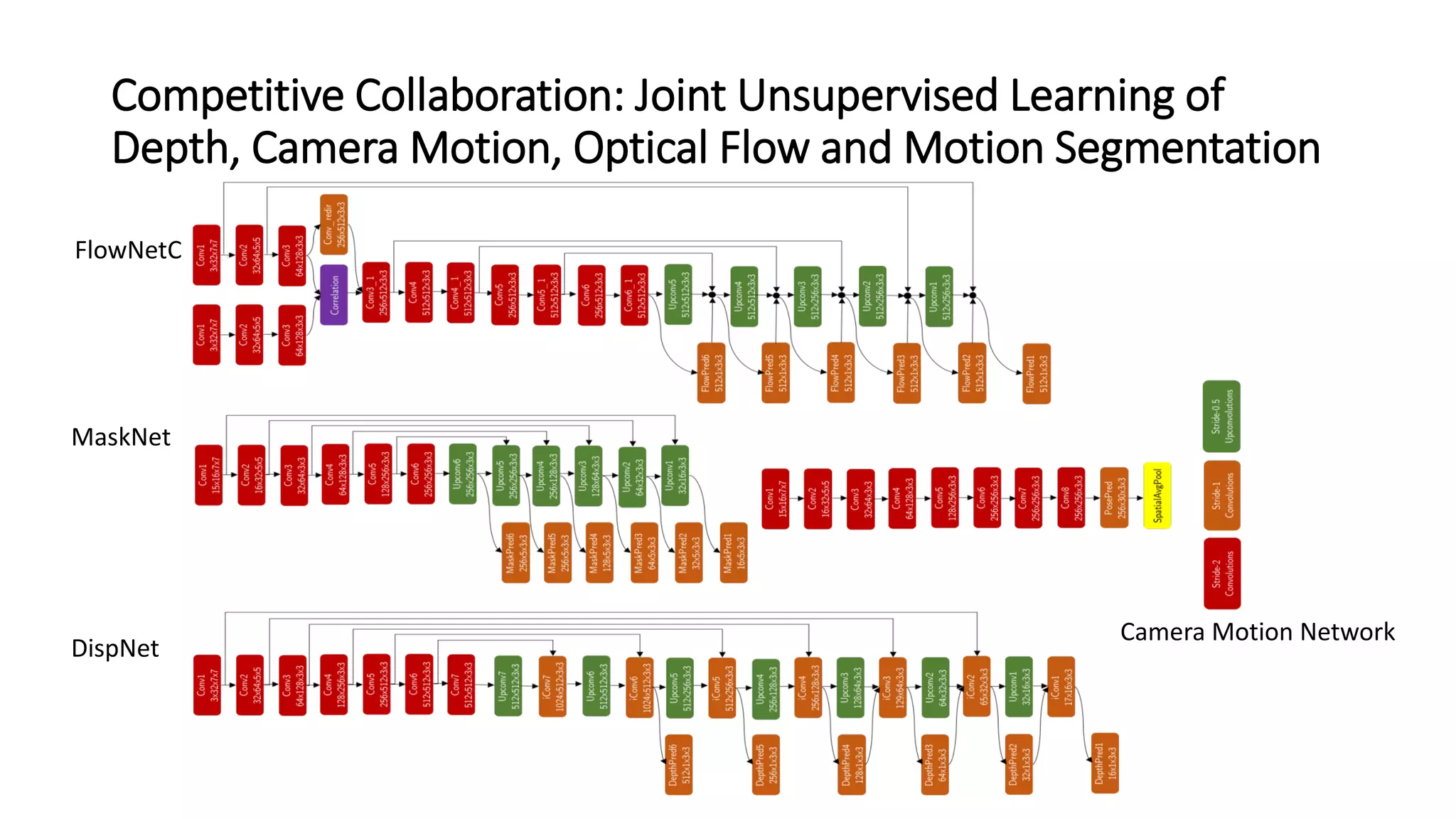



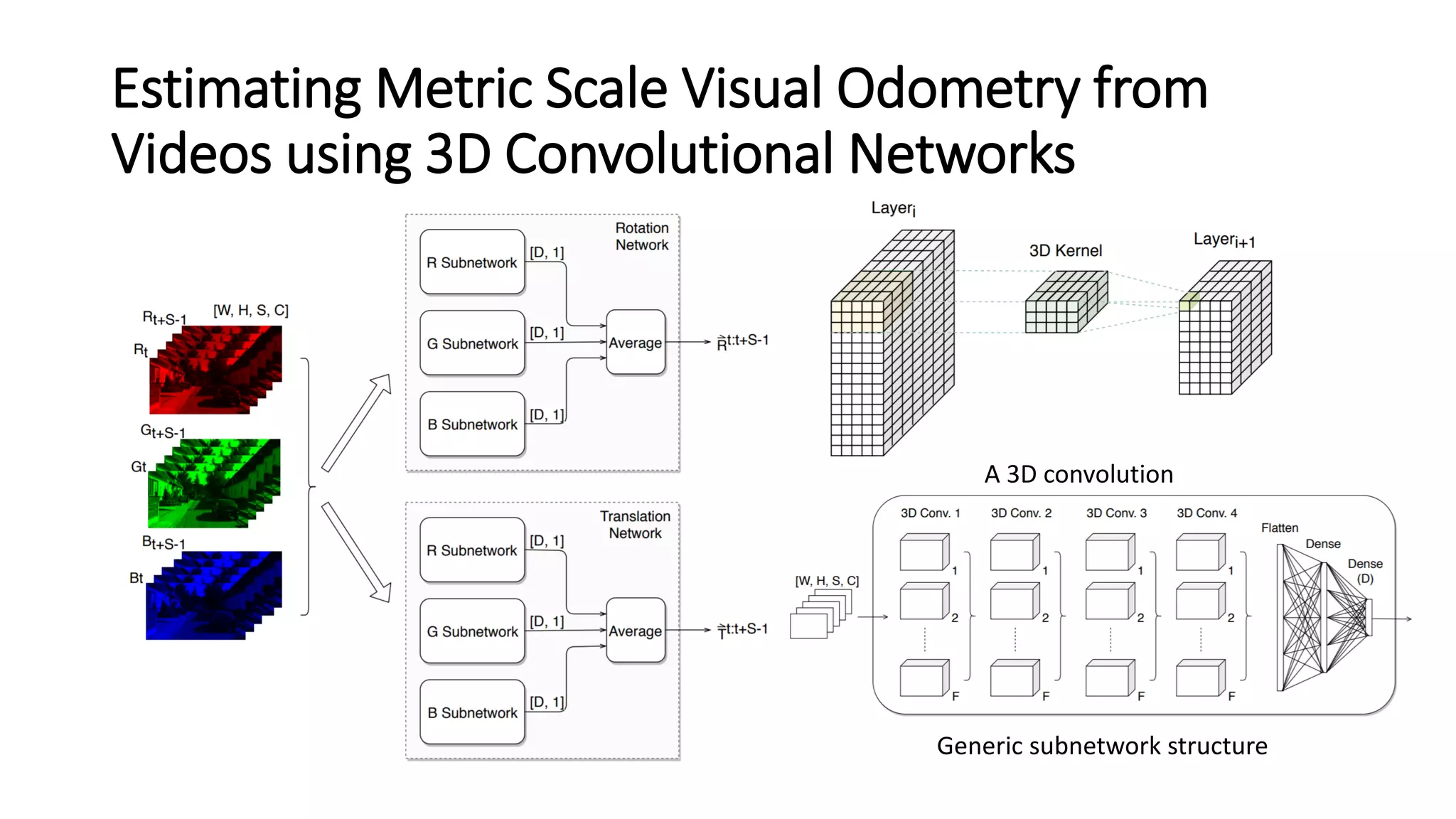
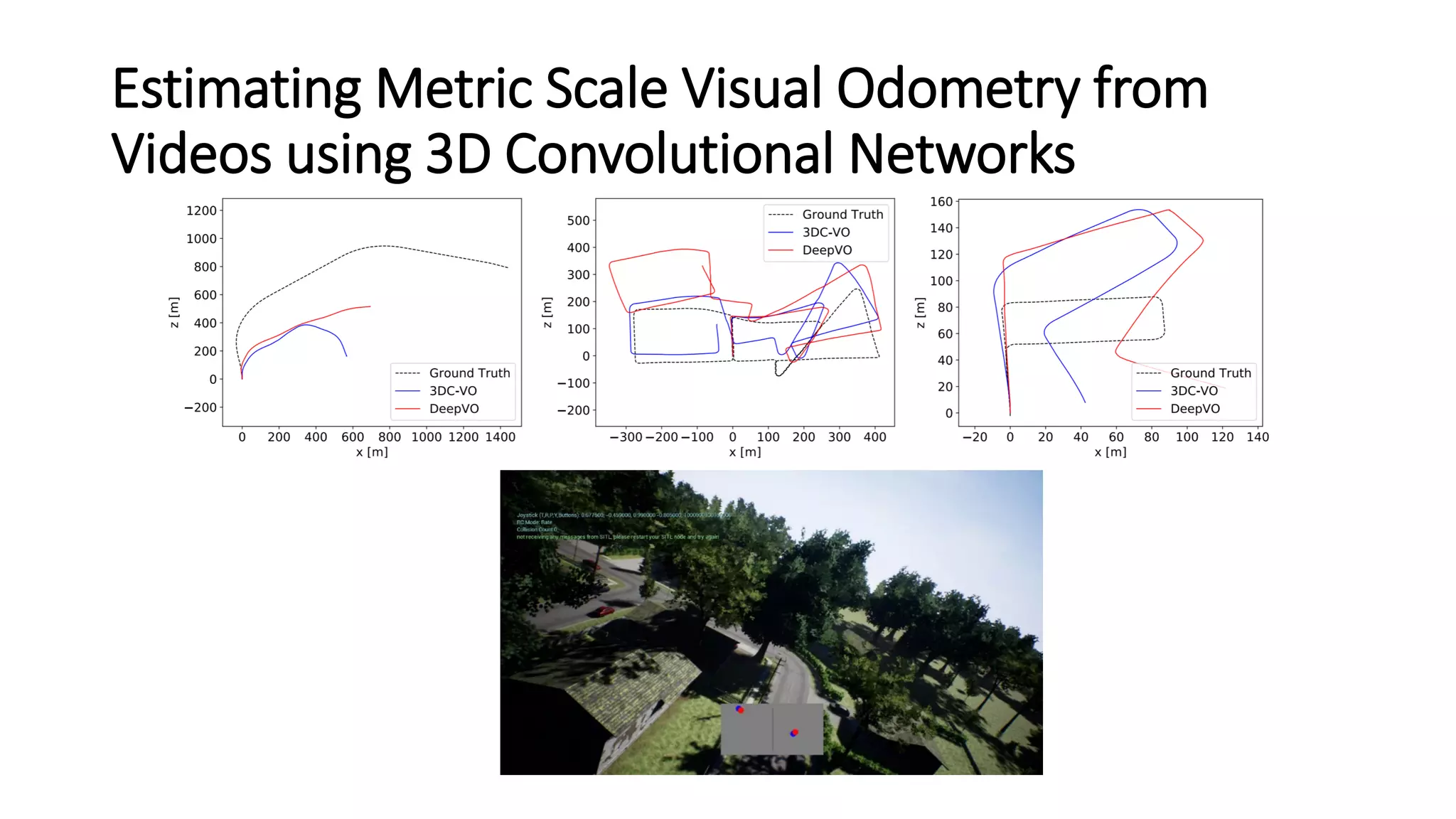

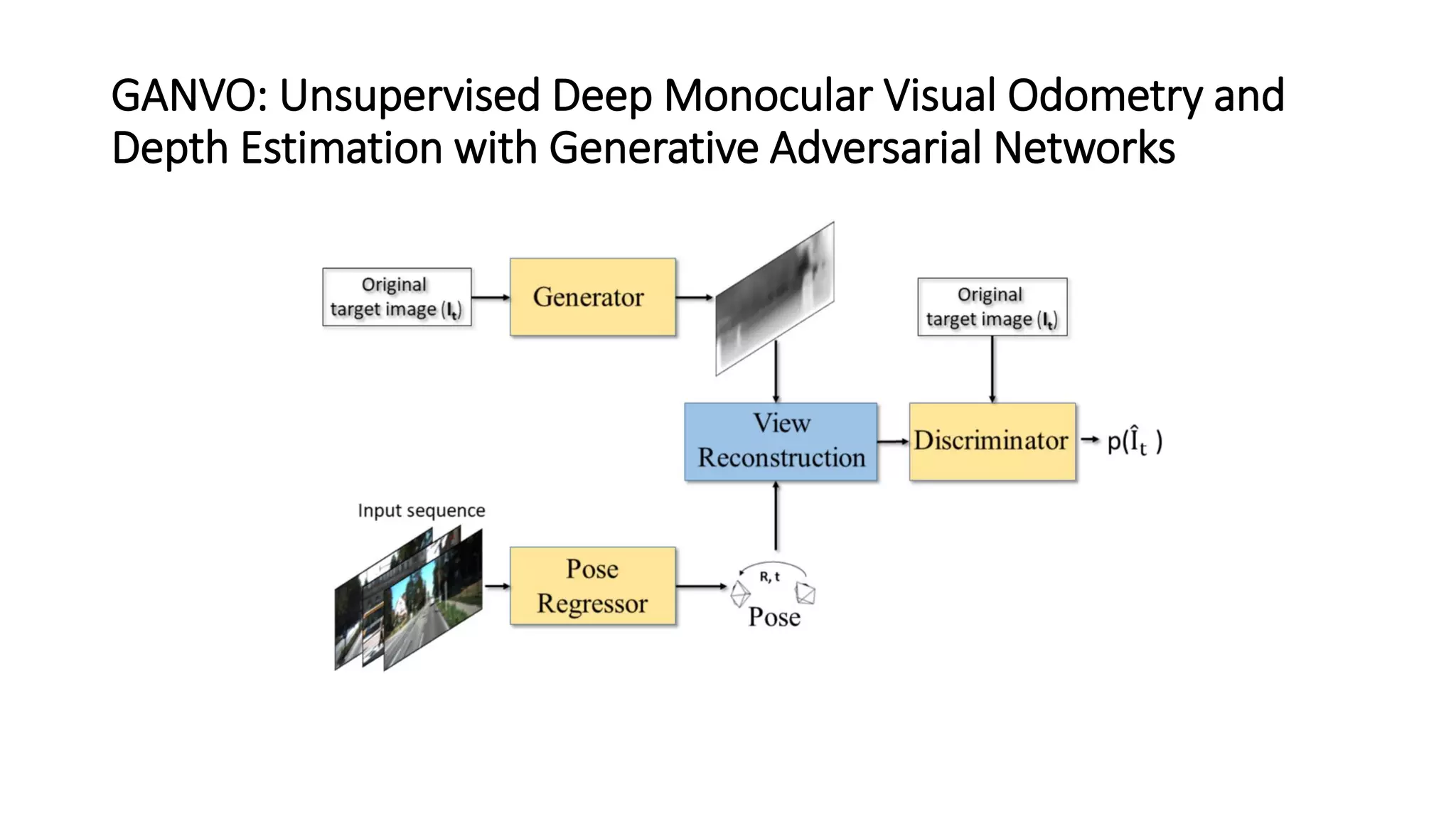
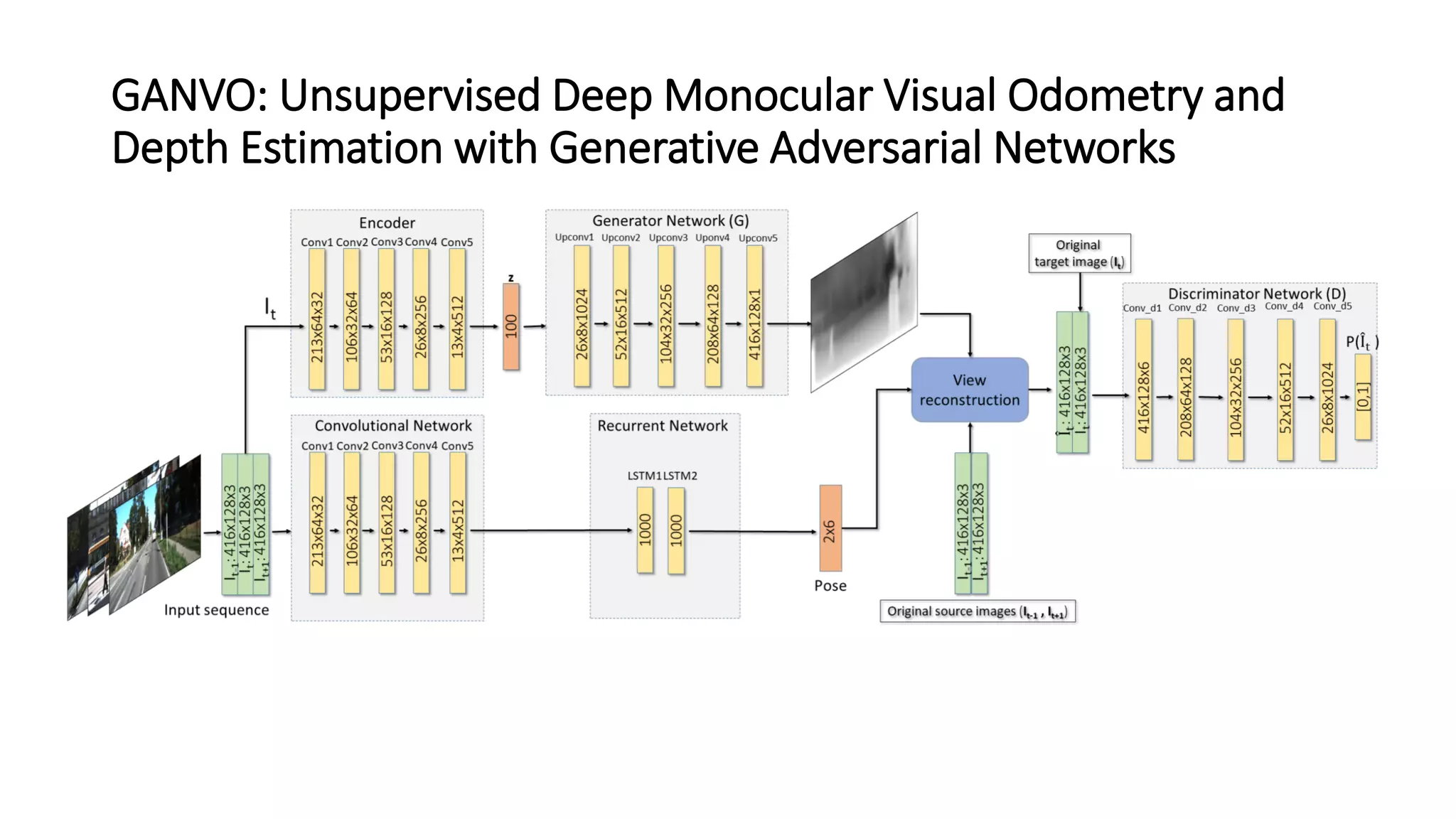




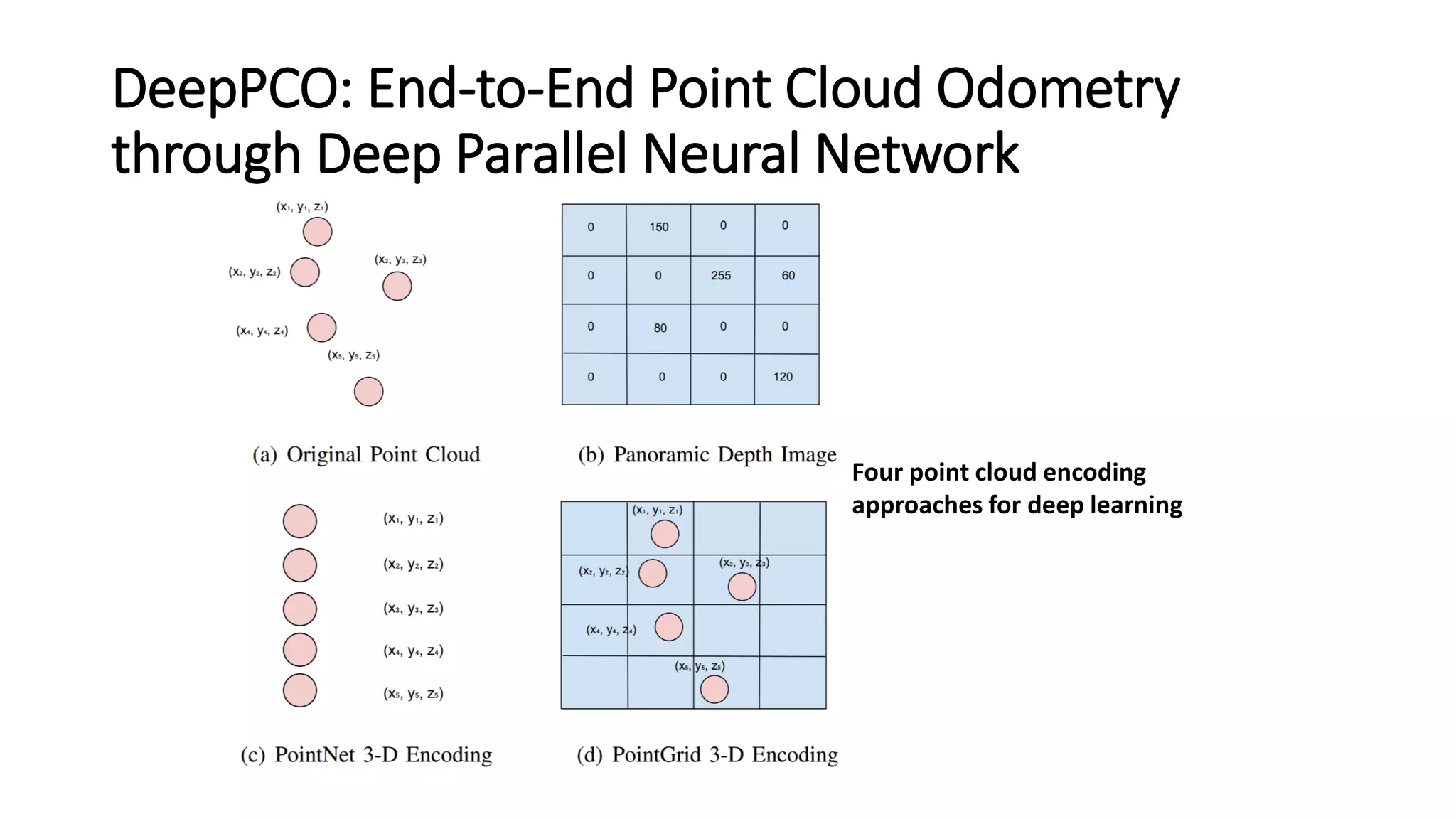
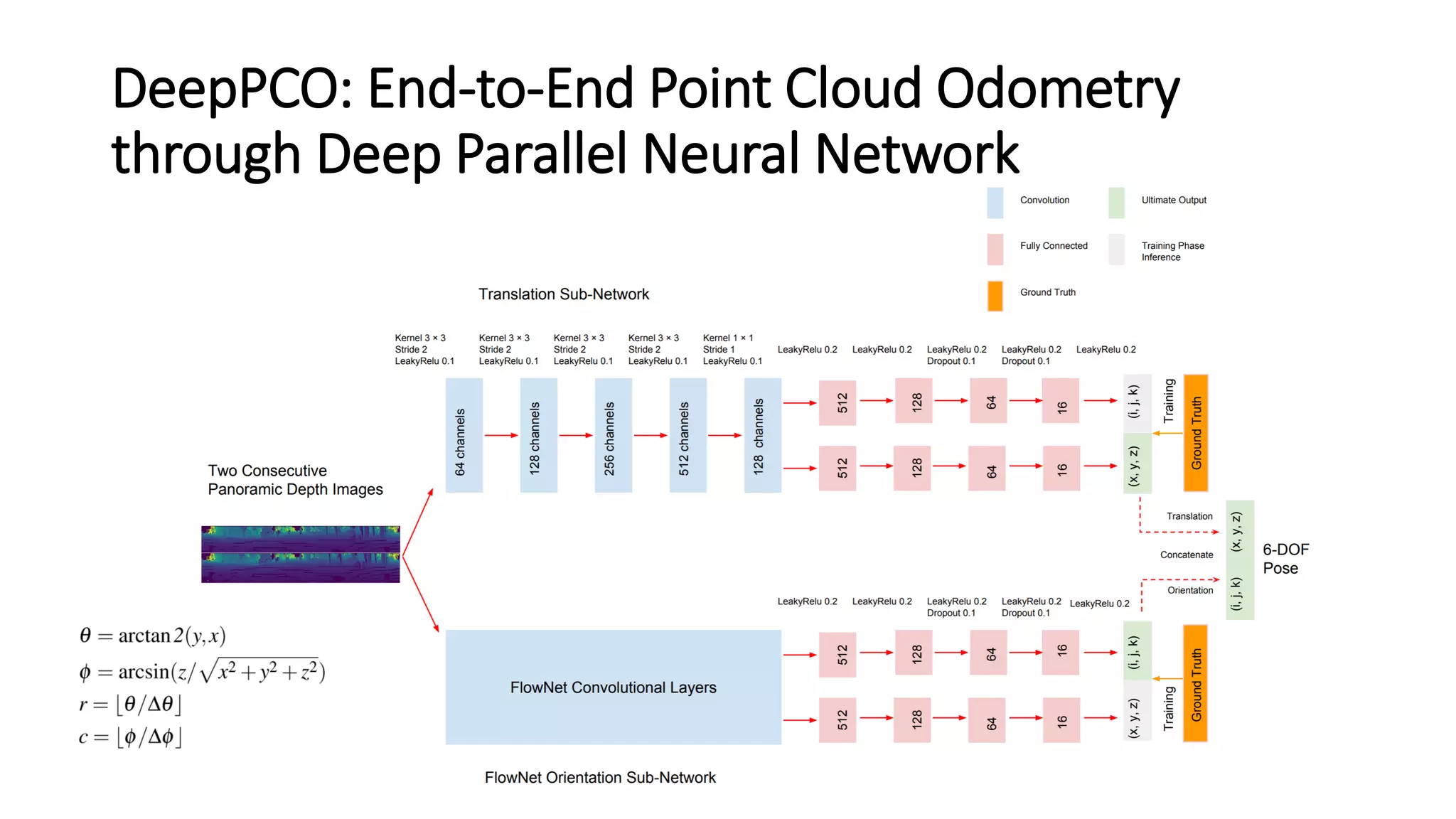




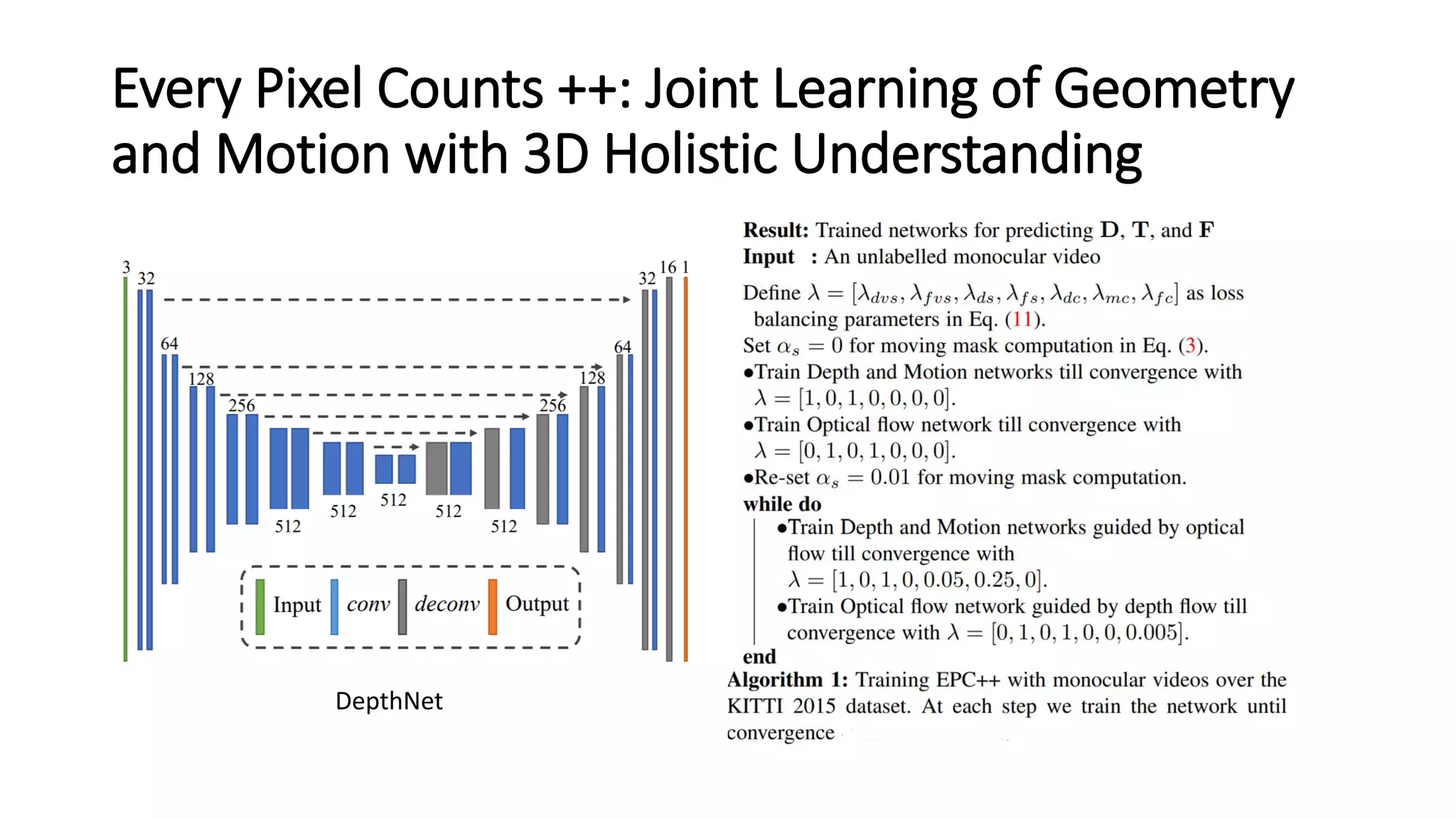
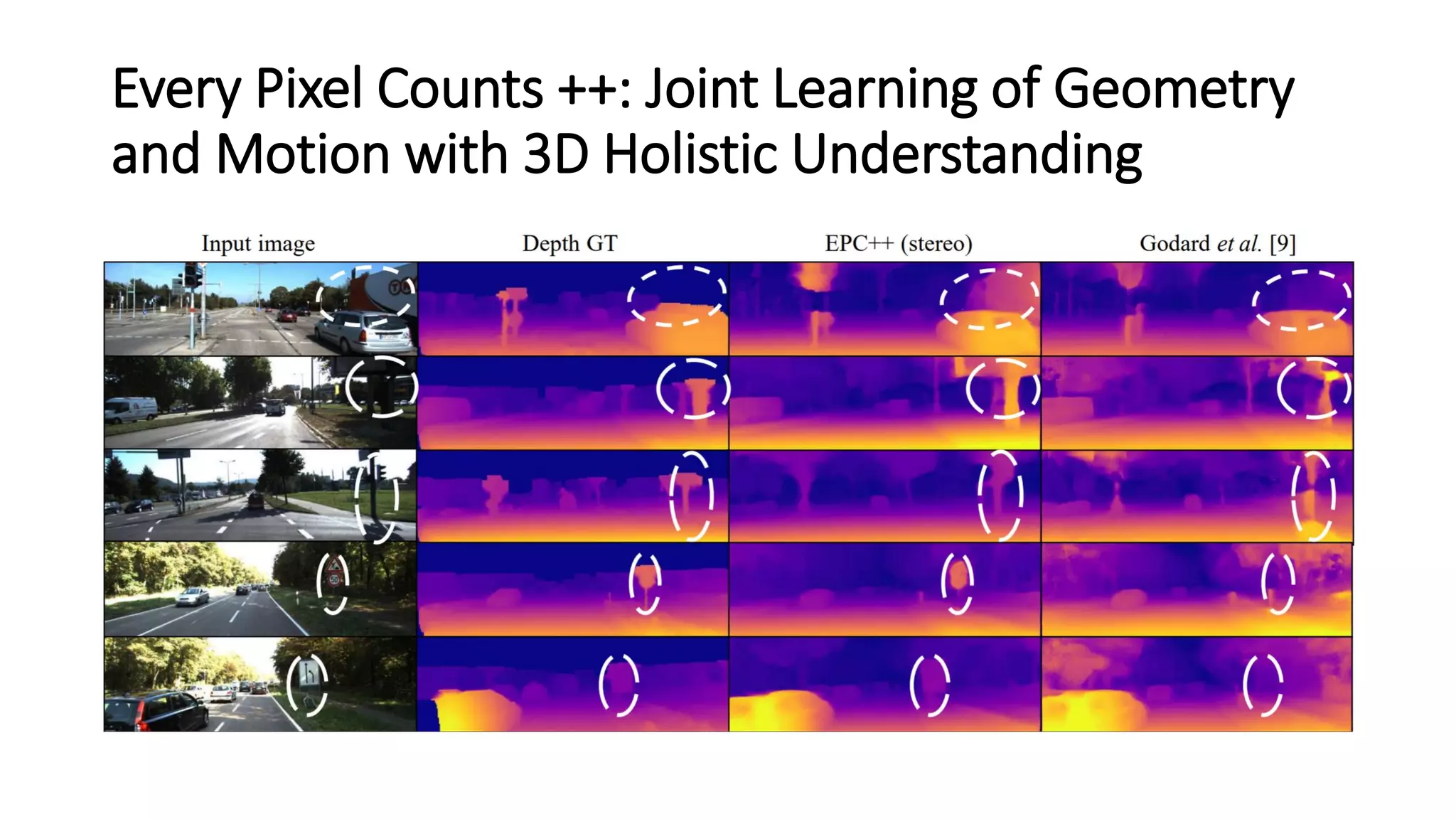
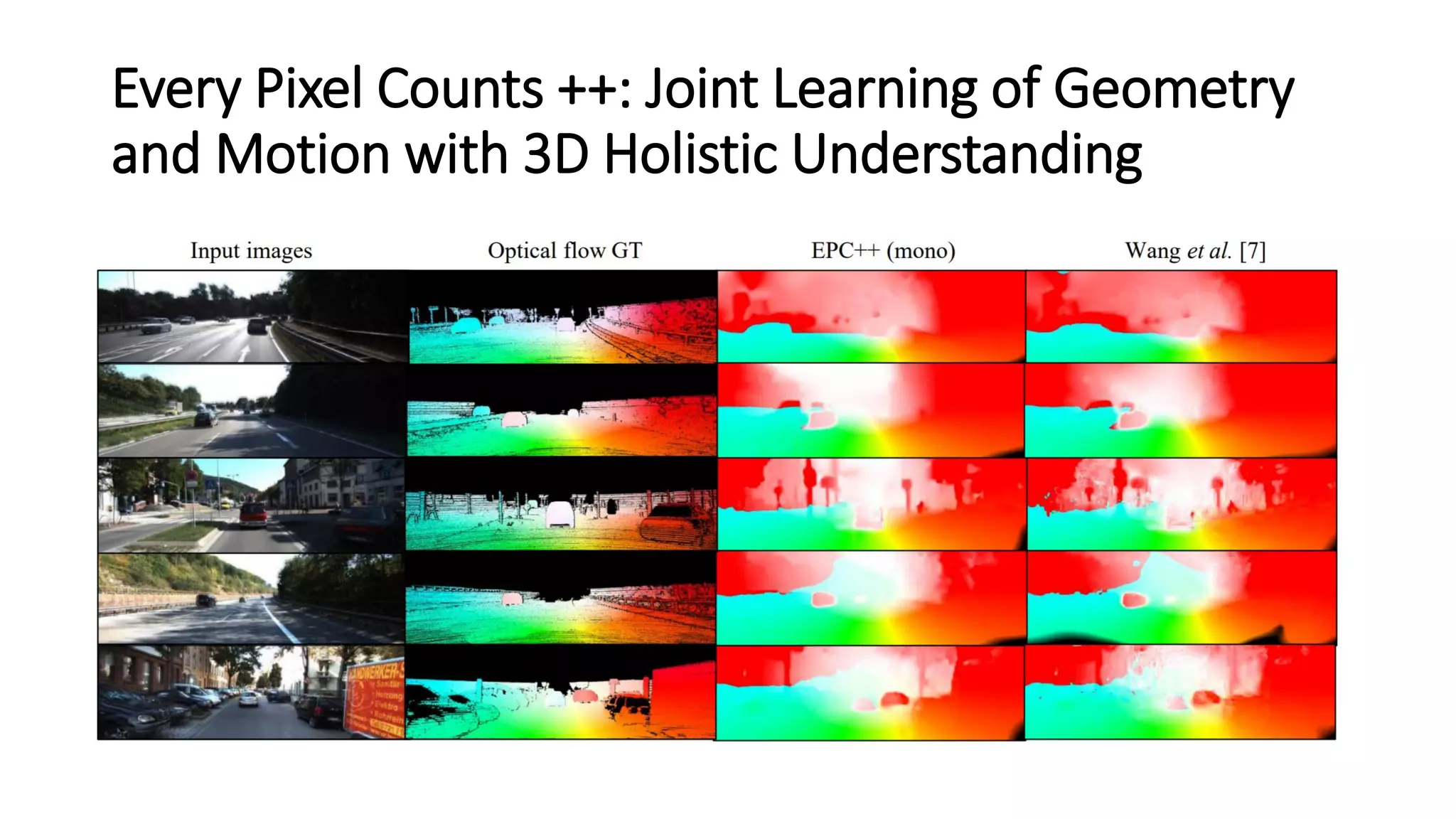
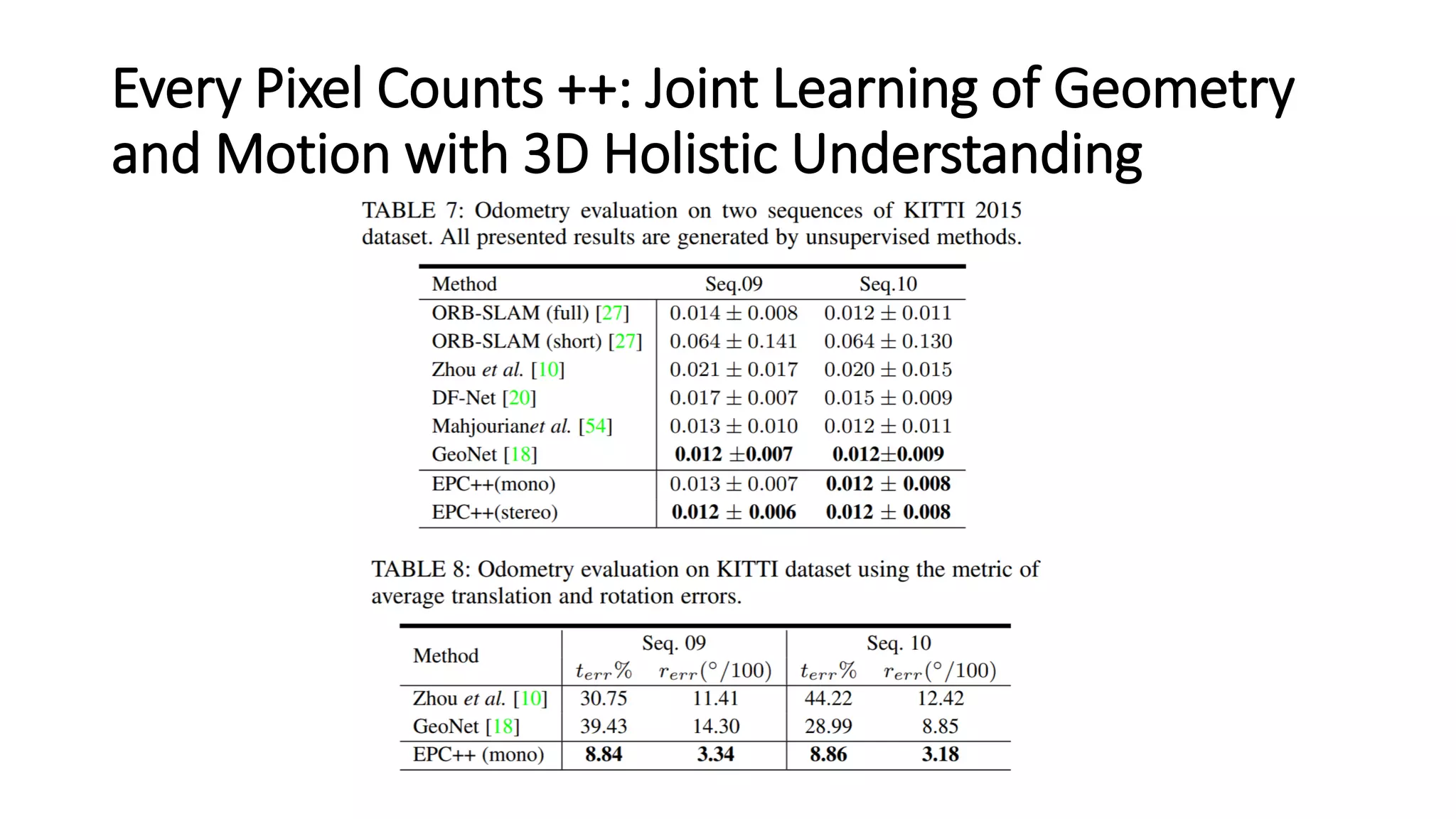


The document outlines various advancements in visual odometry and depth estimation using deep learning techniques, specifically focusing on self-supervised and unsupervised learning approaches. Key methods discussed include Flowdometry, a system that utilizes optical flow for visual odometry, and several frameworks like competitive collaboration and GANVO, which improve localization and mapping from unlabelled data. Overall, these innovations aim to enhance accuracy and robustness in camera motion estimation and 3D mapping within real-world environments.

































![論文読み会@AIST (Deep Virtual Stereo Odometry [ECCV2018])](https://cdn.slidesharecdn.com/ss_thumbnails/dvsoslideshare-181104042256-thumbnail.jpg?width=640&height=640&fit=bounds)





















































