Download as PDF, PPTX




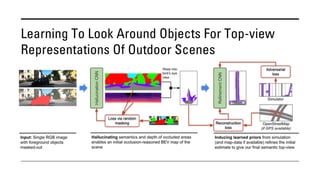


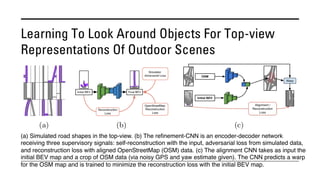



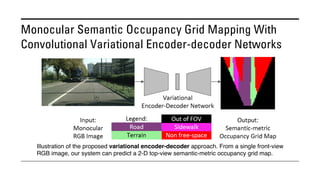
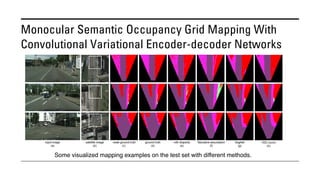
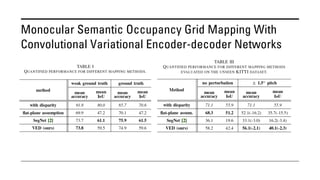

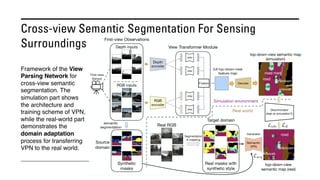




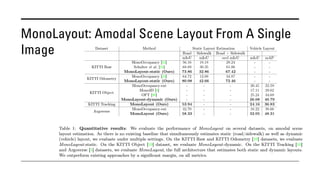


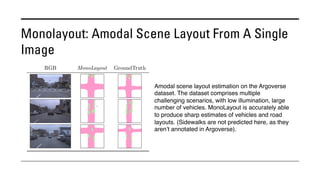



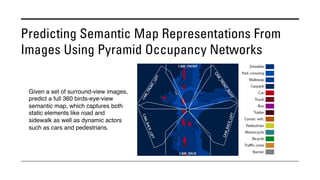
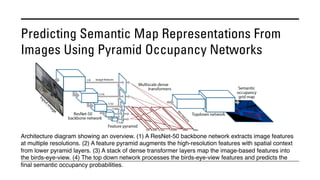
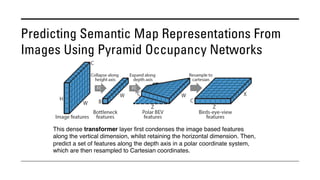

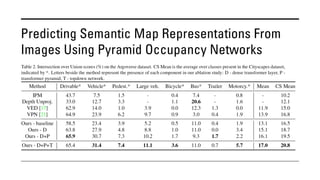

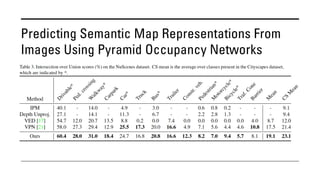


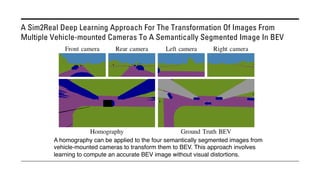

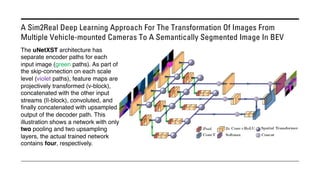
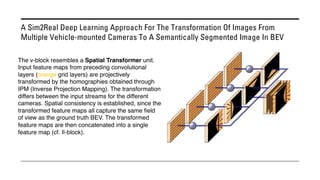
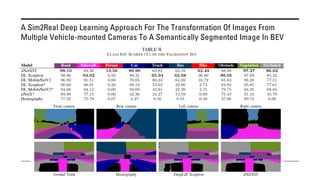


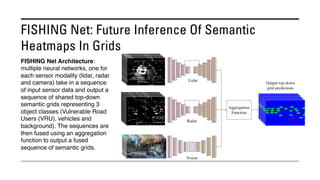

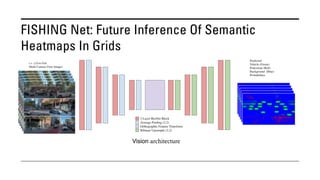
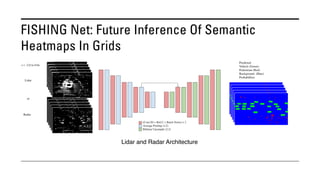

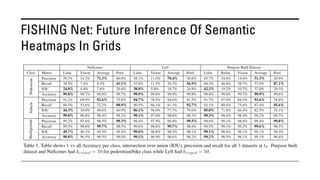
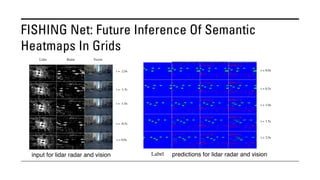

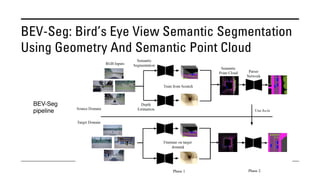














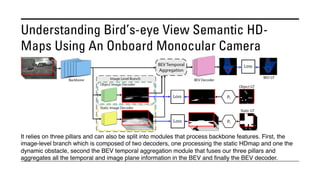
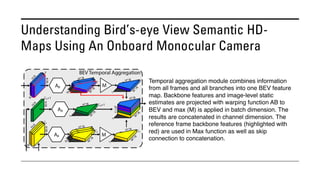





The document outlines various methods for bird's-eye view (BEV) semantic segmentation and scene representation using neural networks. Key techniques include monocular semantic occupancy grid mapping, cross-view semantic segmentation, and the Monolayout approach, which predicts amodal layouts from single images. Additionally, it discusses a 'sim2real' deep learning approach for transforming multi-camera images into semantically segmented BEV representations, as well as frameworks for future inference of semantic heatmaps using sensor data aggregation.





![[論文解説]Unsupervised monocular depth estimation with Left-Right Consistency](https://cdn.slidesharecdn.com/ss_thumbnails/unsupervisedmonoculardepthestimation-170809092538-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]representation learning via invariant causal mechanisms](https://cdn.slidesharecdn.com/ss_thumbnails/2021910representationlearningviainvariantcausalmechanisms-210910032836-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Human Pose Estimation @ ECCV2018](https://cdn.slidesharecdn.com/ss_thumbnails/180928dlseminarposeestimationeccv2018-180928031032-thumbnail.jpg?width=640&height=640&fit=bounds)



![[CVPR2020読み会@CV勉強会] 3D Packing for Self-Supervised Monocular Depth Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/202007043dpackingforself-supervisedmonoculardepthestimation-200704035538-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/pvrcnn-200311050009-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]High-Quality Self-Supervised Deep Image Denoising](https://cdn.slidesharecdn.com/ss_thumbnails/high-qualityself-superviseddeepimagedenoising-200501014639-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [SS1] Transformer x Computer Visionの 実活用可能性と展望 〜 TransformerのCompute...](https://cdn.slidesharecdn.com/ss_thumbnails/ss1-01-210607043349-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2021 [OS3-01] 設備や環境の高品質計測点群取得と自動モデル化技術](https://cdn.slidesharecdn.com/ss_thumbnails/os3-02-210605062048-thumbnail.jpg?width=640&height=640&fit=bounds)



























































