Download as PDF, PPTX








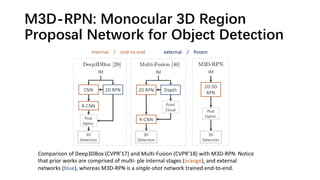





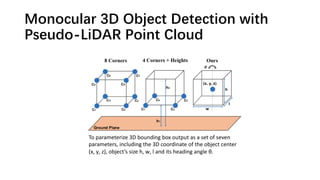




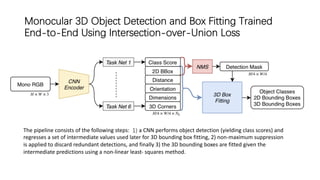


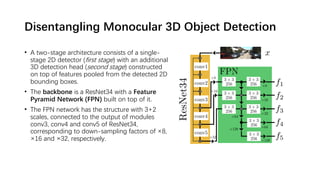
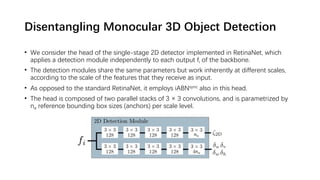

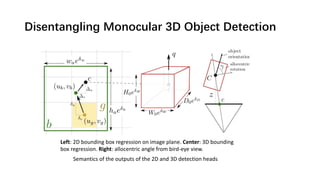









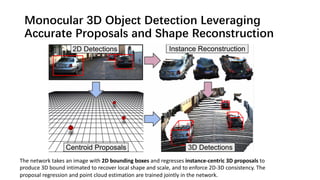
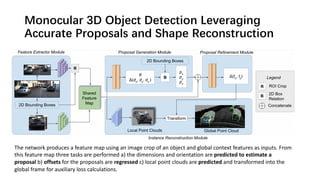




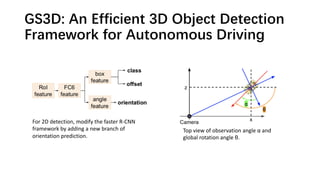


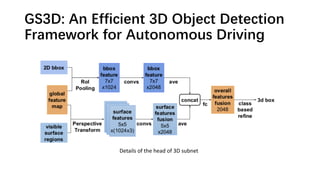


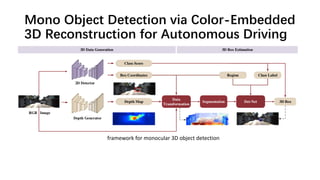

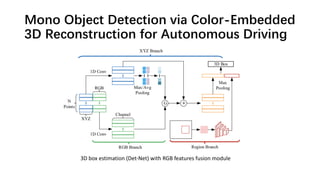



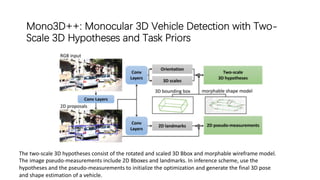

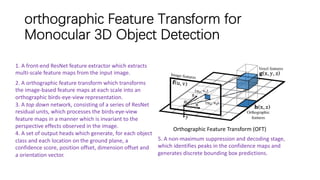
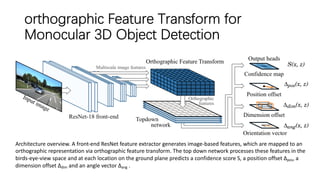


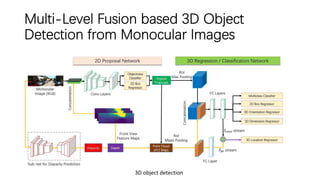


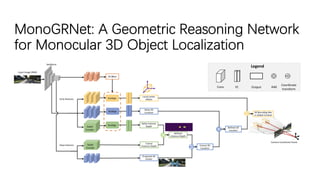

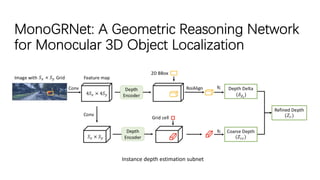
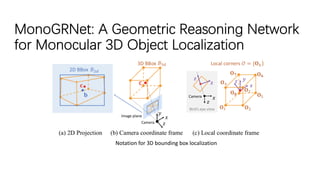
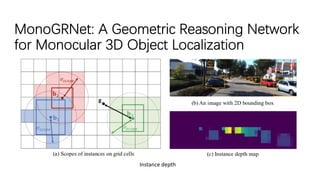



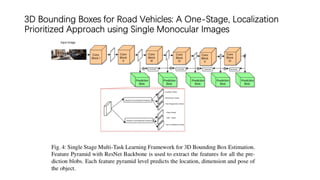



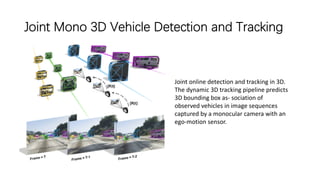


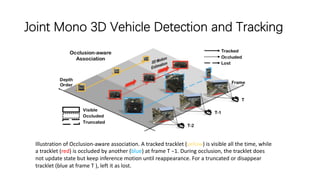



The document discusses advancements in monocular 3D object detection for autonomous driving, focusing on methods like m3d-rpn and pseudo-lidar point clouds to enhance detection accuracy from single 2D images. It emphasizes the importance of separating foreground and background in depth estimation, introducing innovative techniques for robust 3D object localization. The document also critiques existing evaluation metrics and proposes solutions to improve the performance of 3D detection systems.




















![[Mmlab seminar 2016] deep learning for human pose estimation](https://cdn.slidesharecdn.com/ss_thumbnails/mucdgsomrcs8cgkh9gsp-signature-54f17826ed7e29e13653ed835b10fabd79d8e26ac84412798c7e96ef7d109006-poli-160811023645-thumbnail.jpg?width=640&height=640&fit=bounds)























![[NS][Lab_Seminar_240611]Graph R-CNN.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240611graphr-cnn-240704112605-f42276be-thumbnail.jpg?width=640&height=640&fit=bounds)









































