Downloaded 12 times



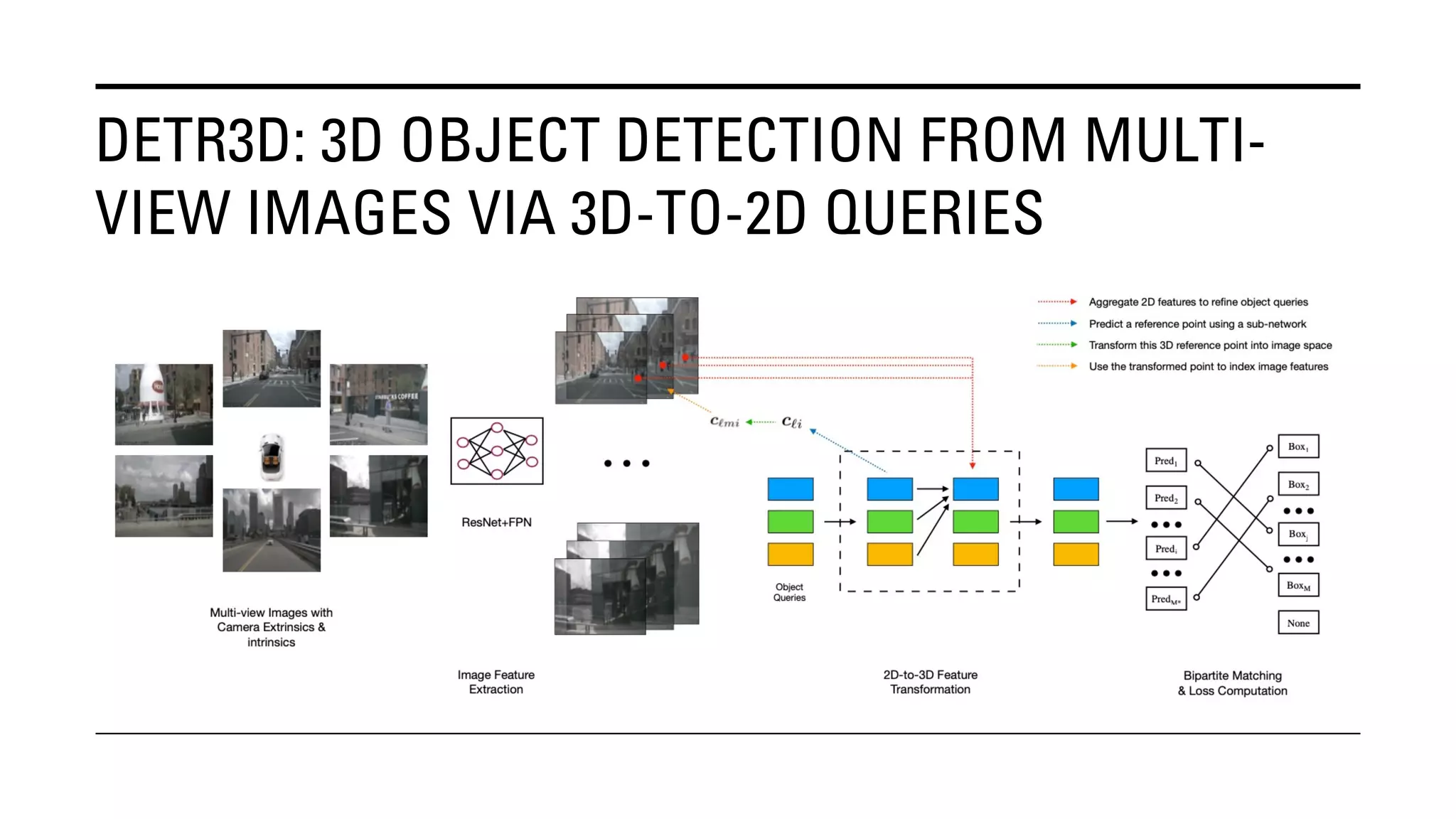

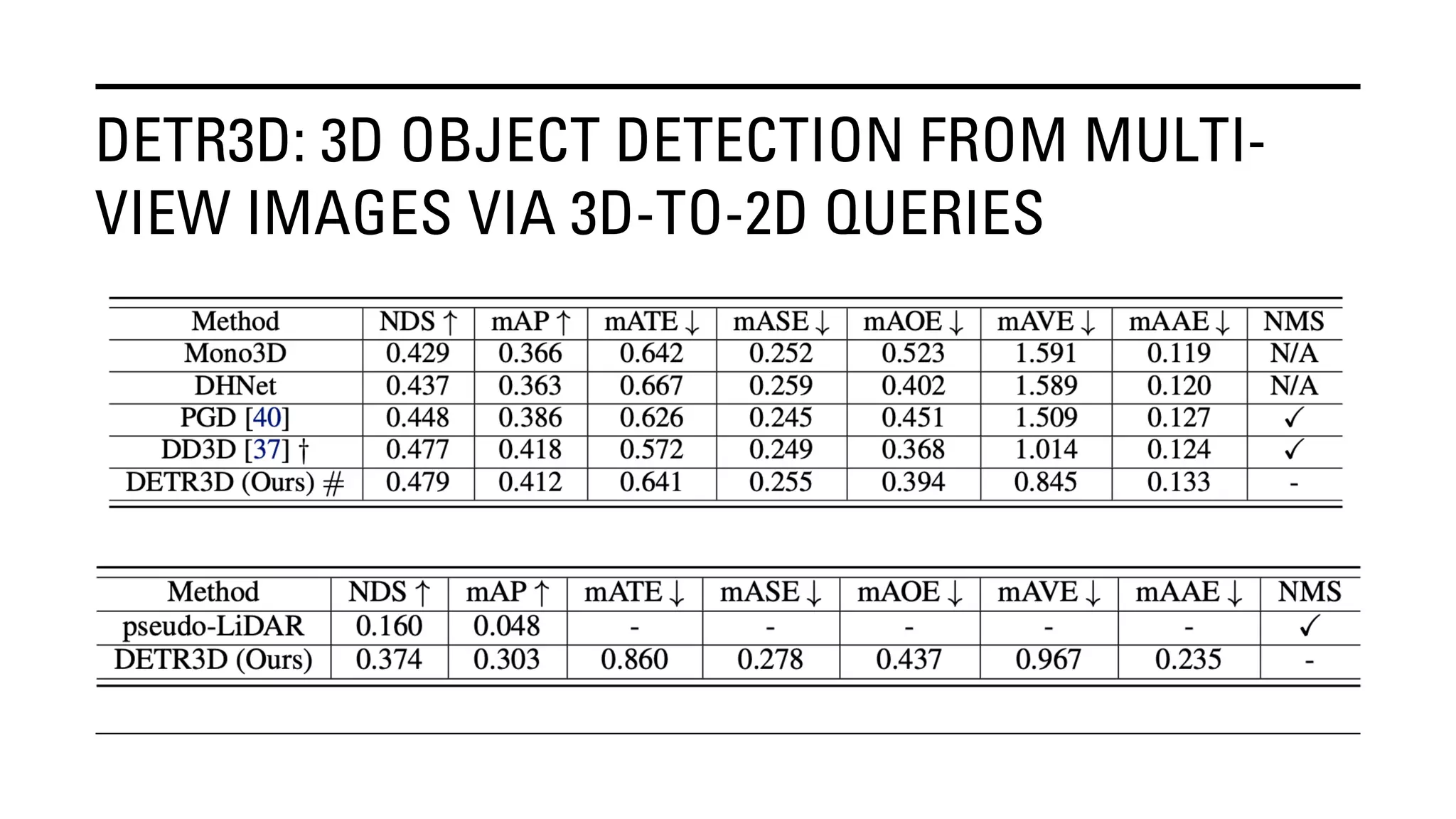

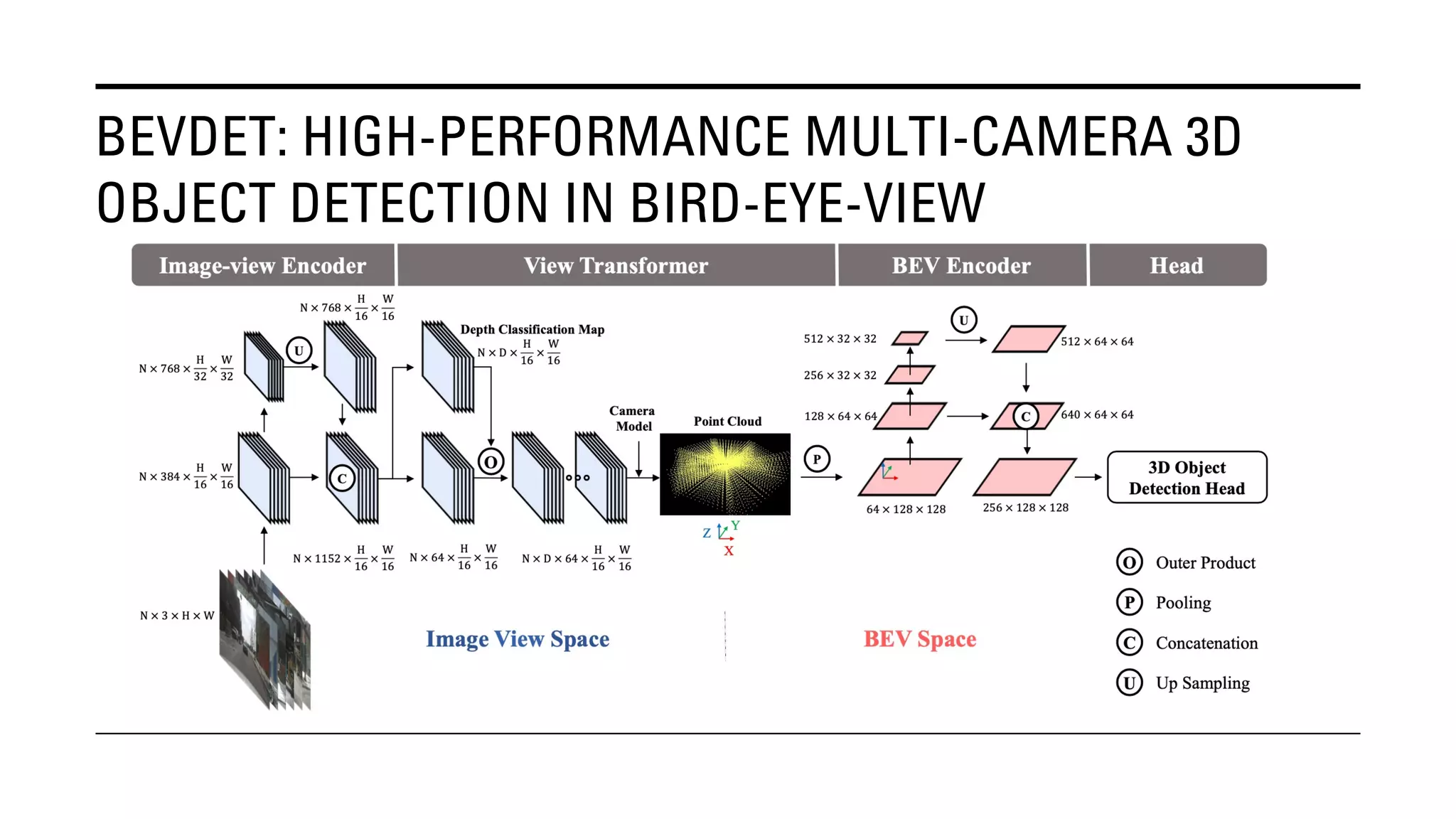
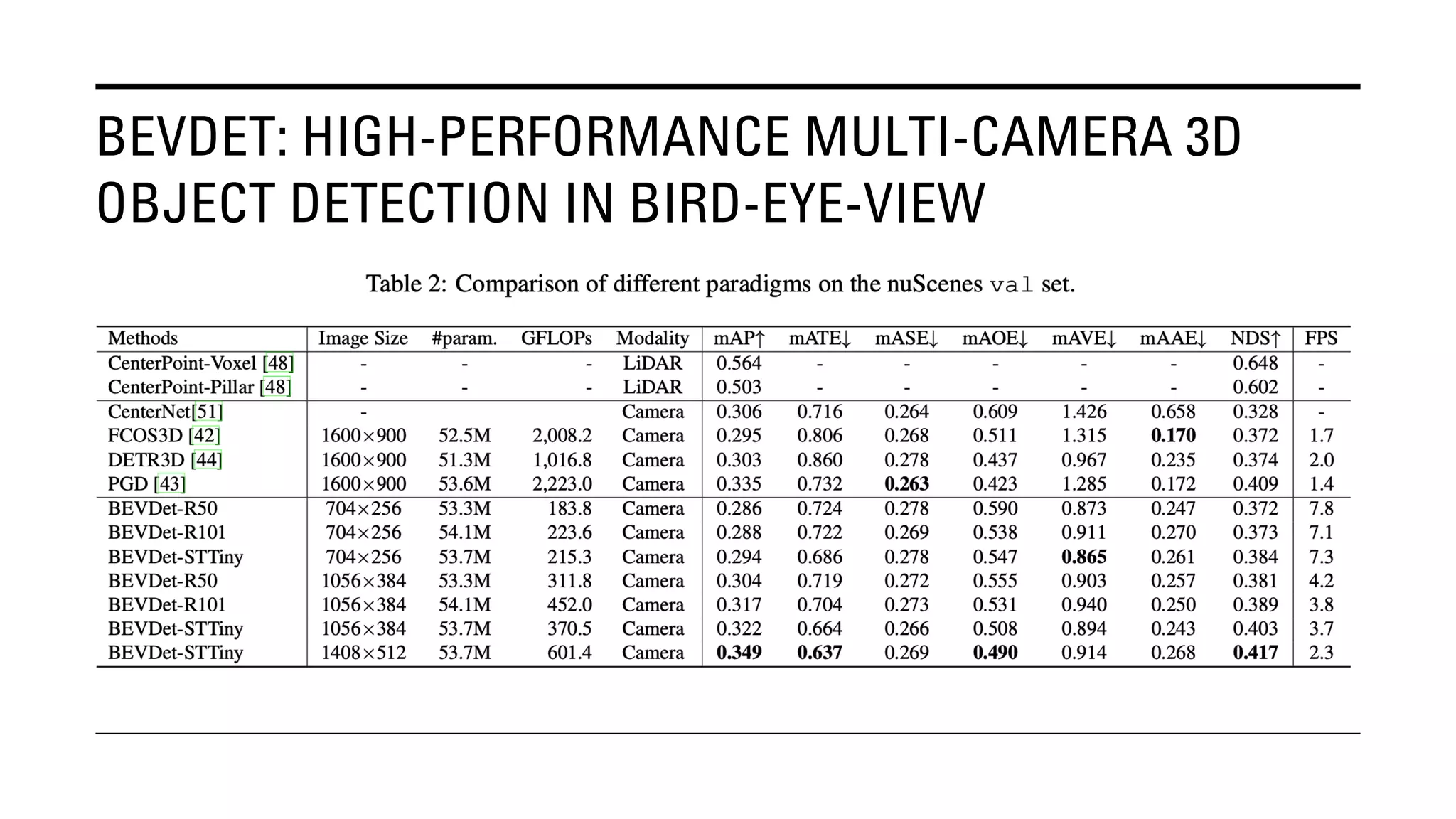

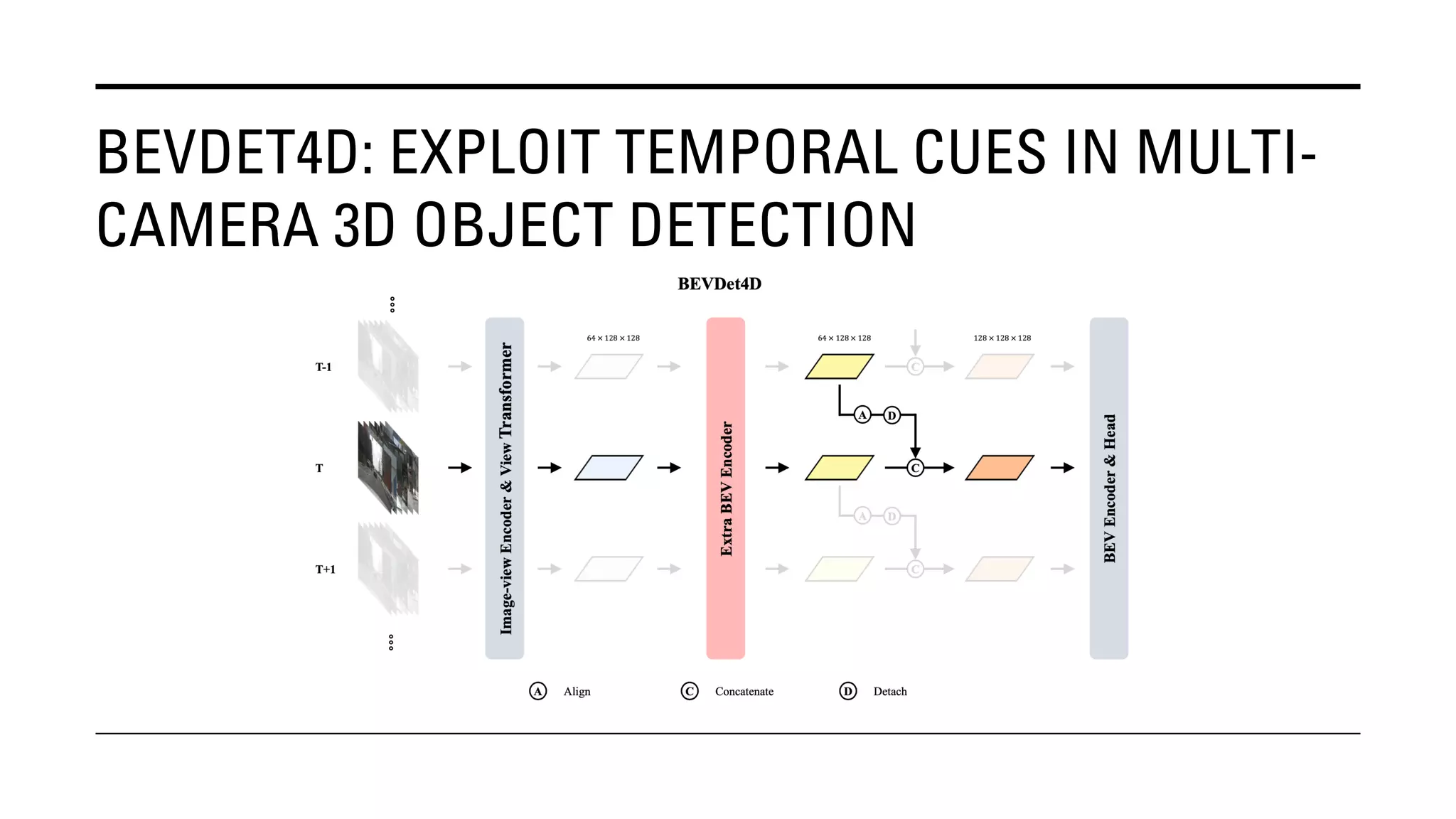
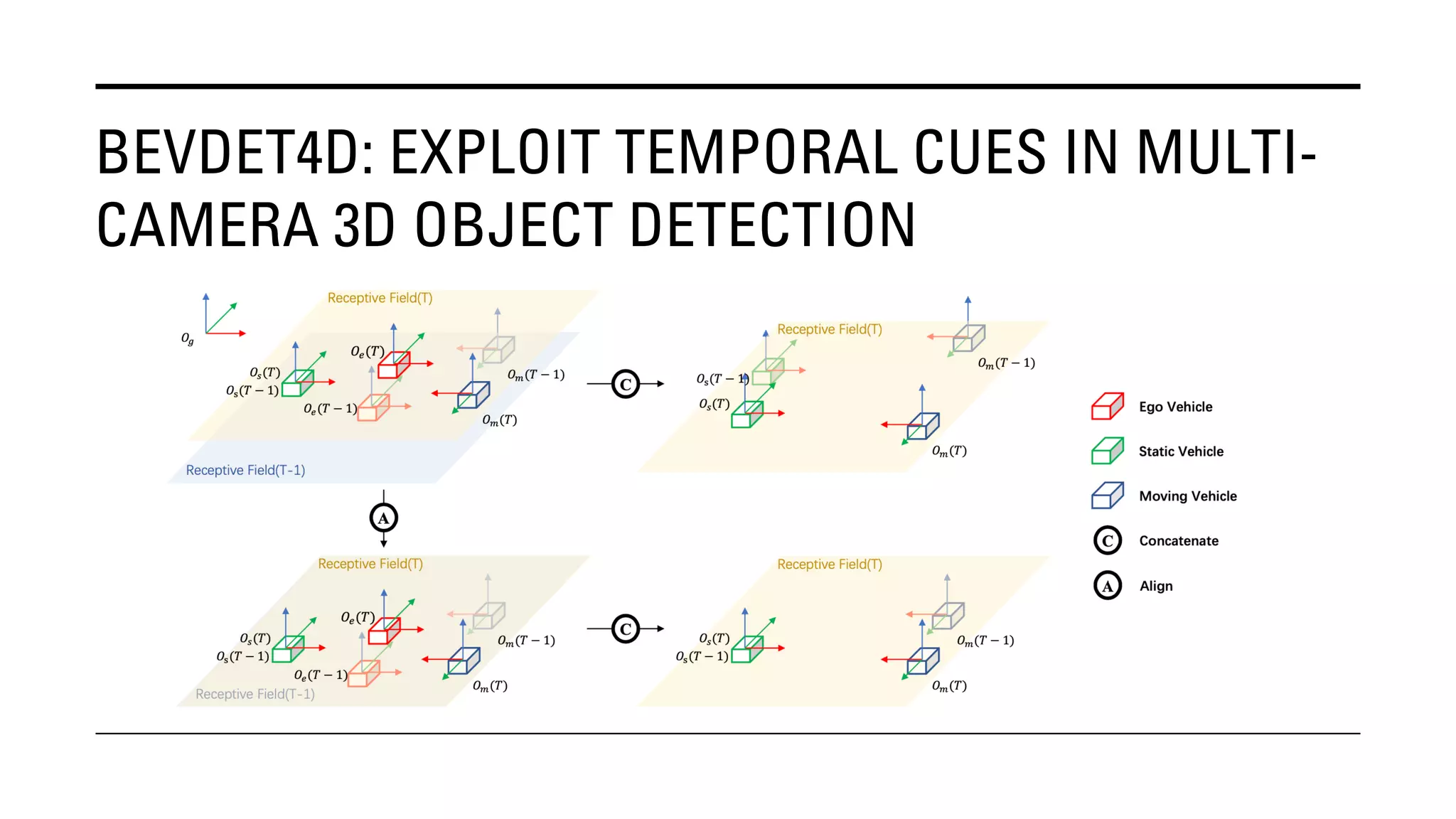
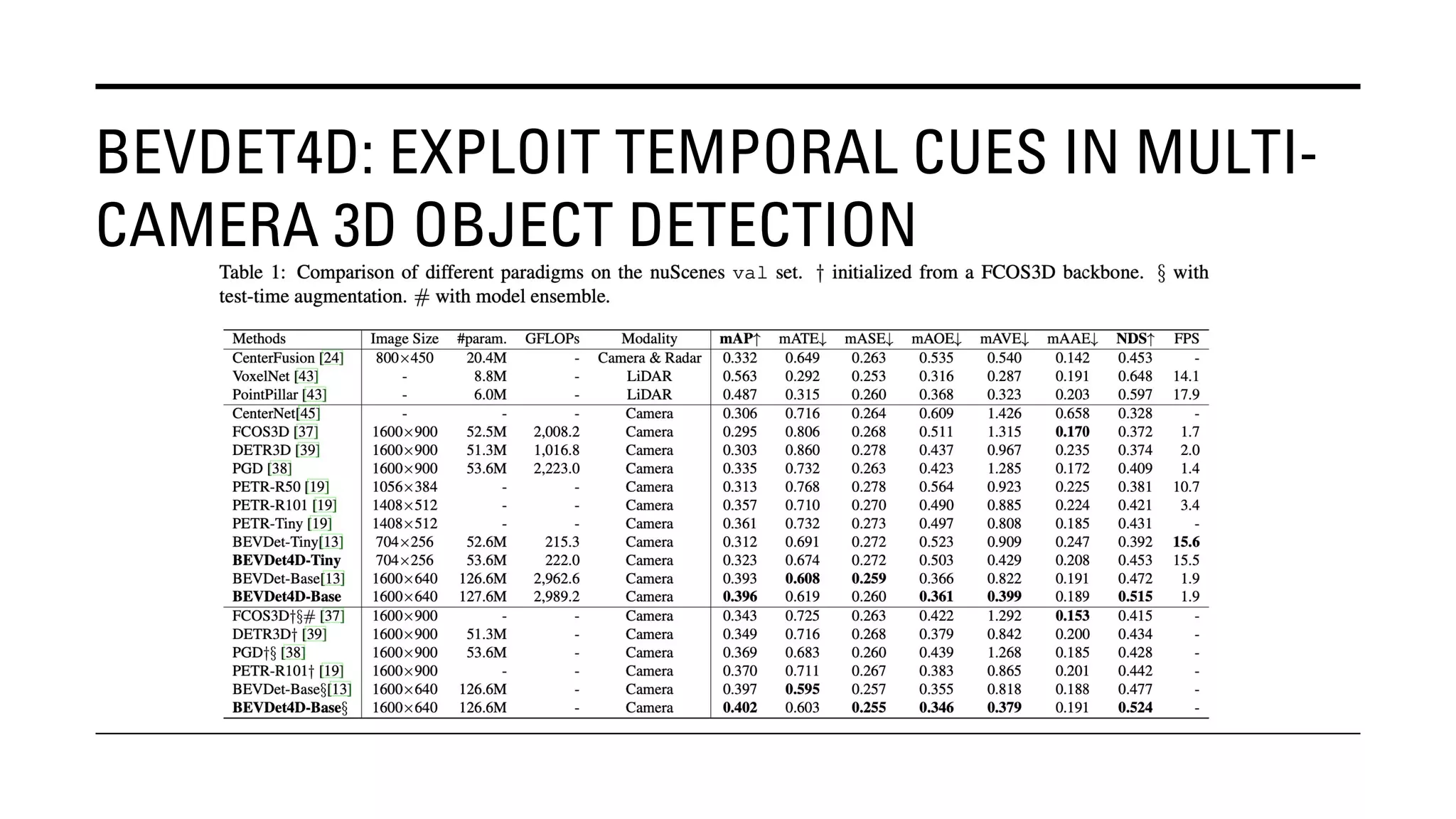
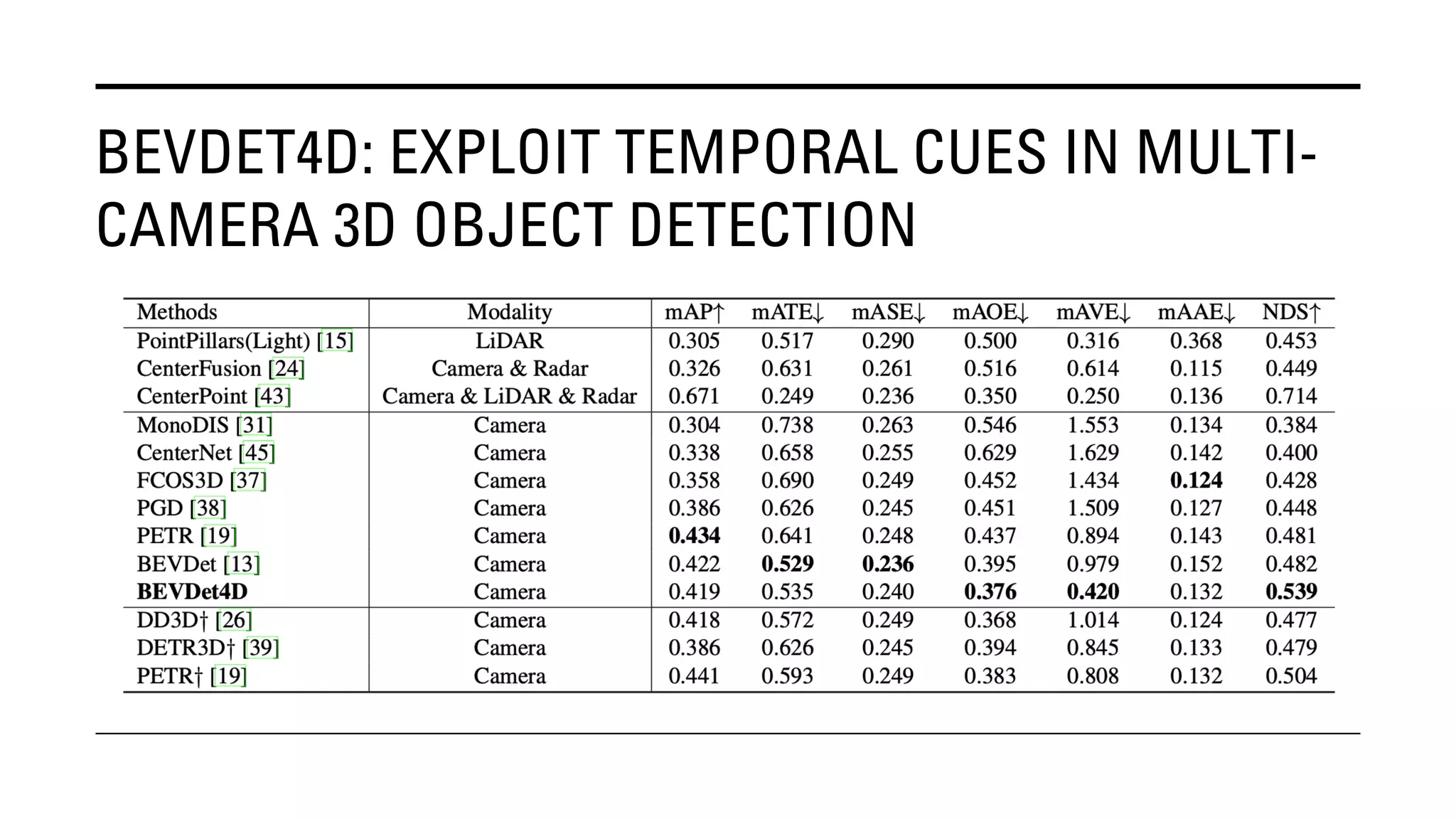

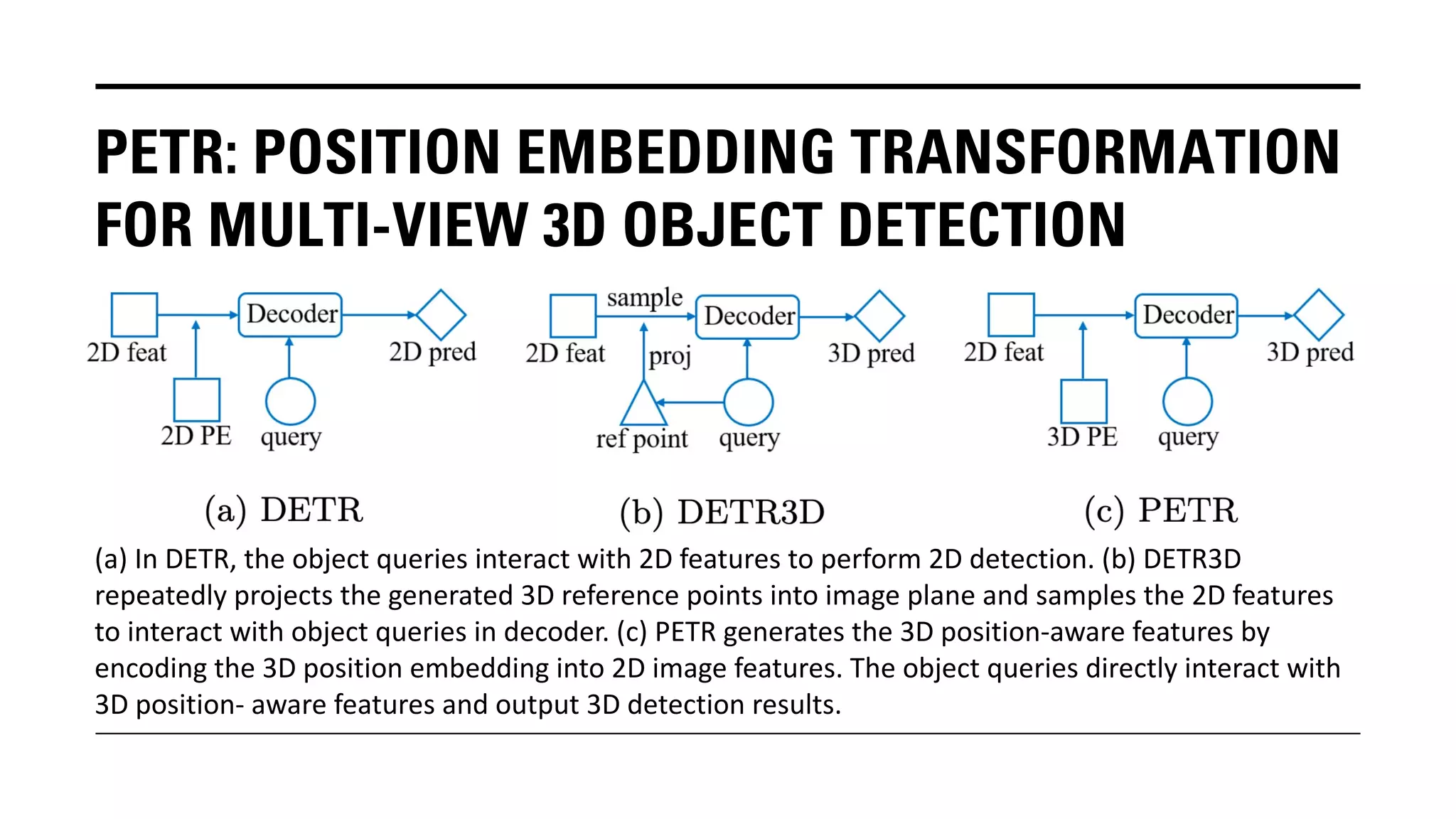
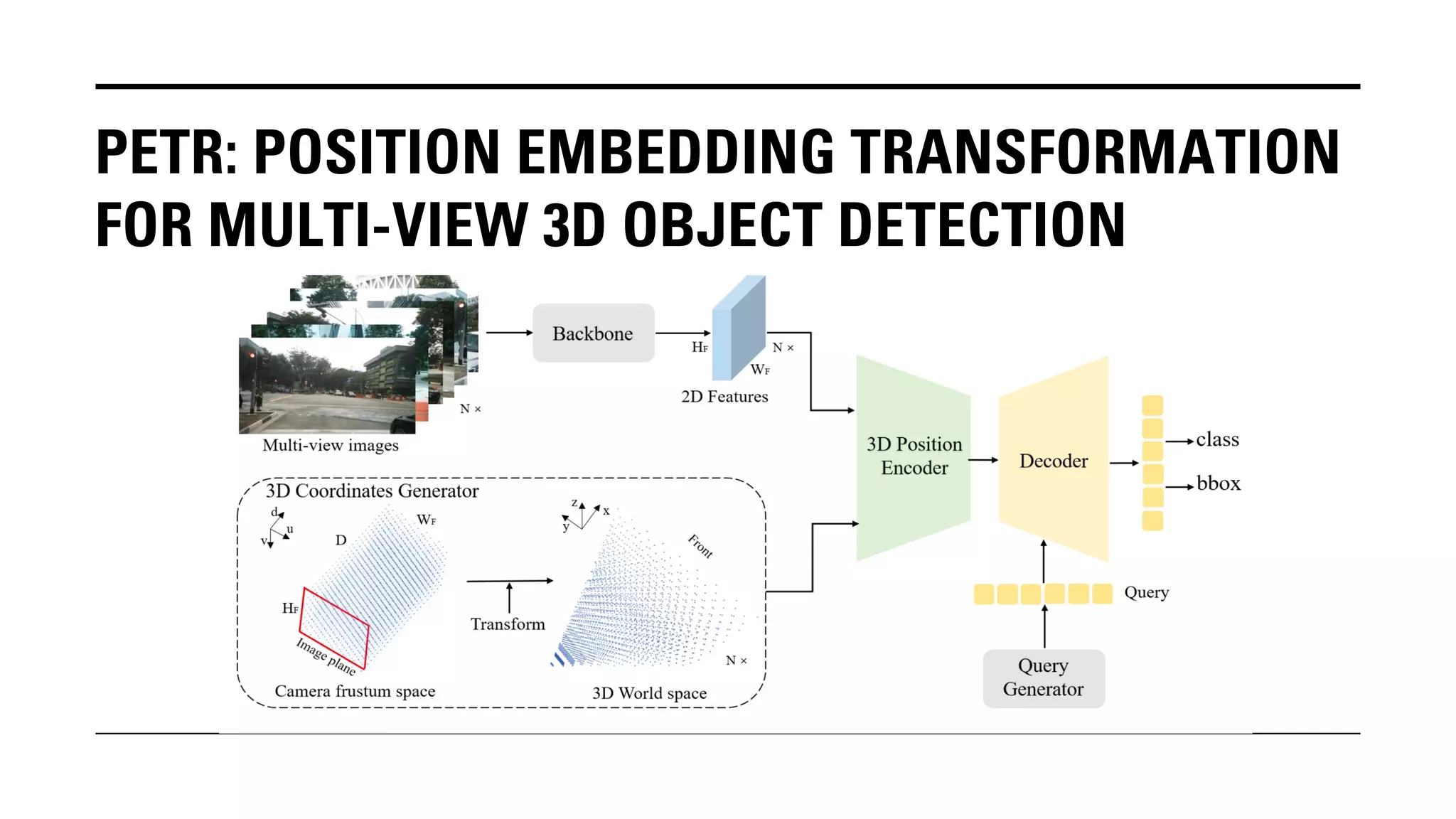
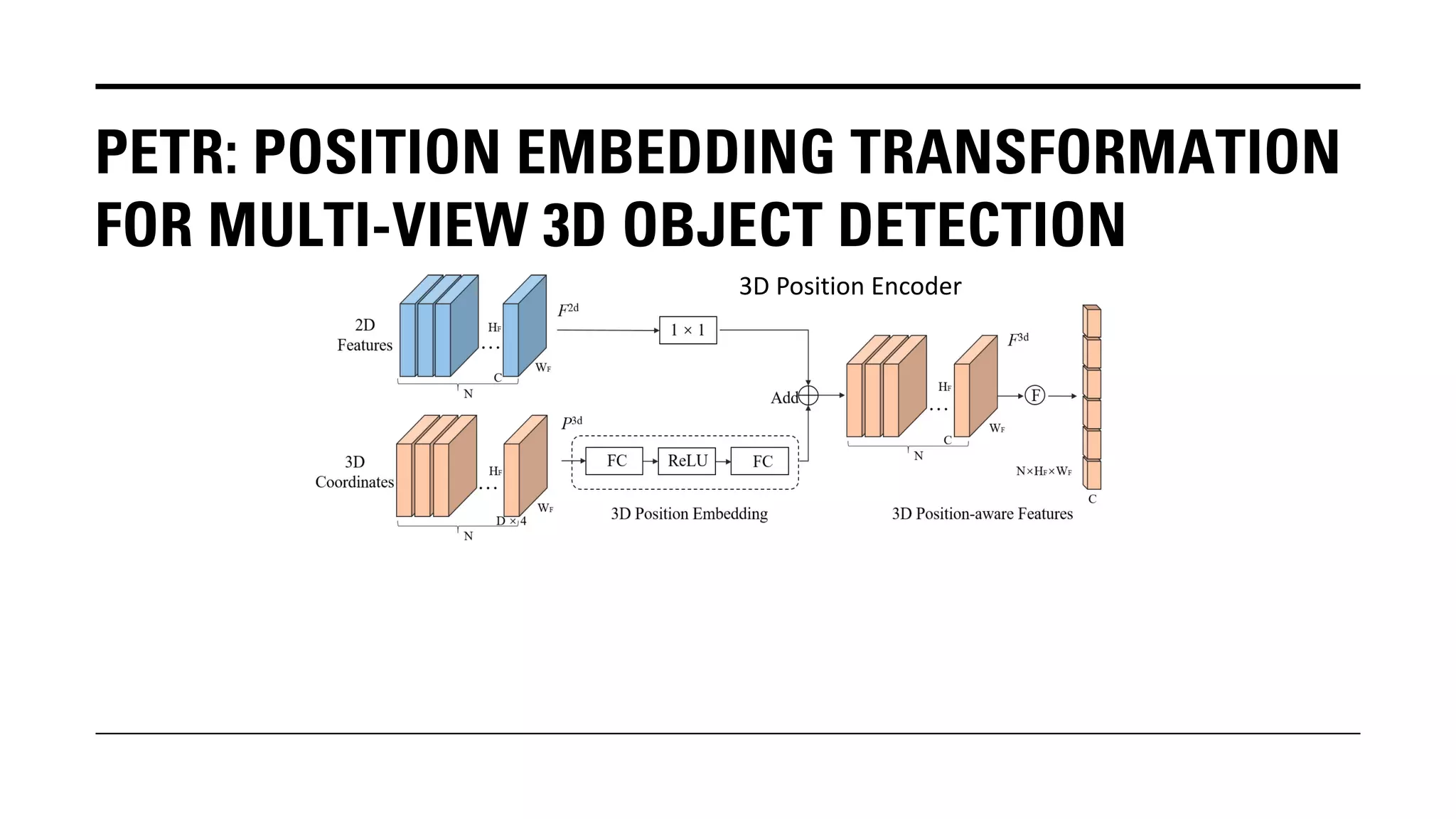

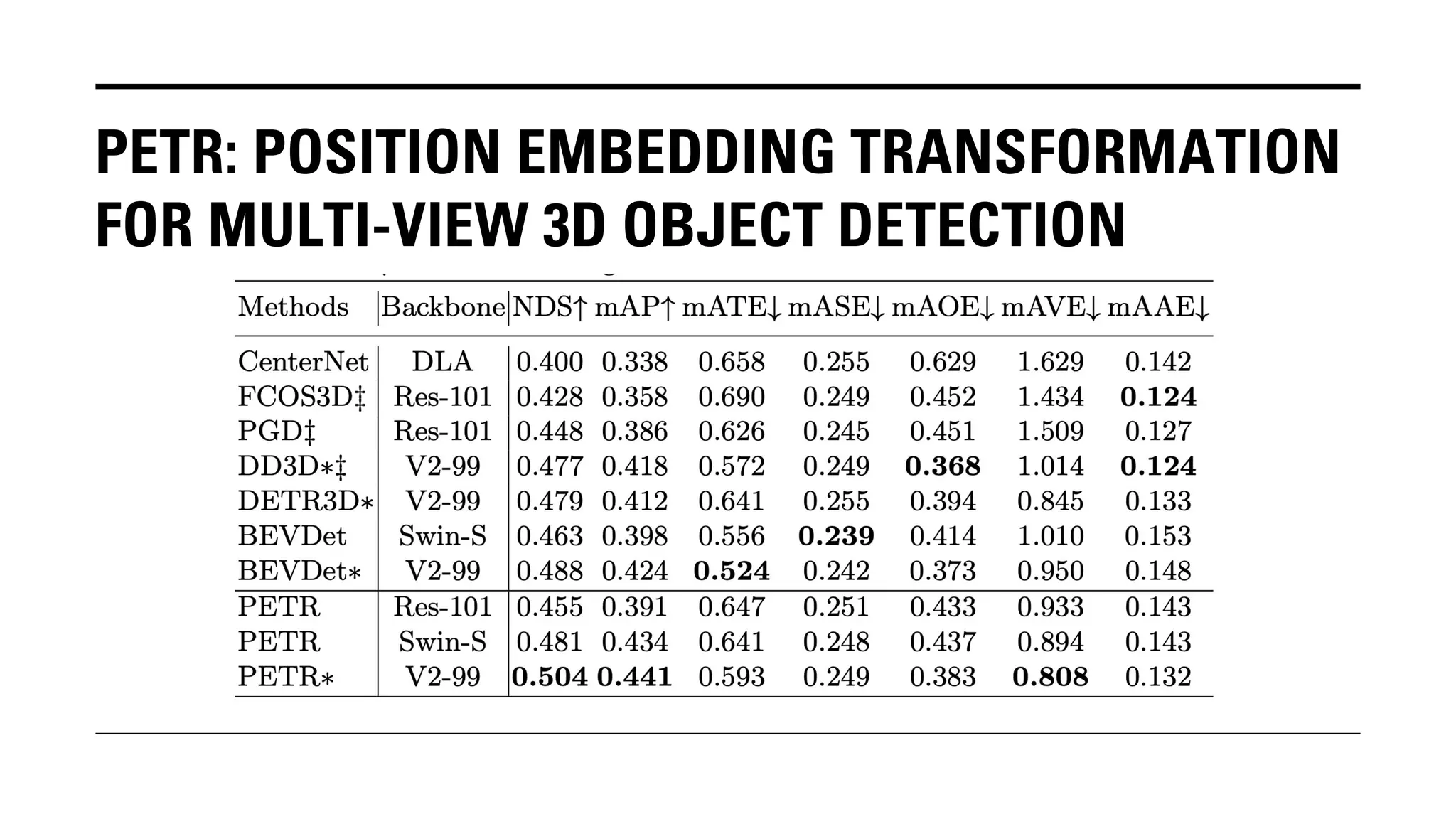
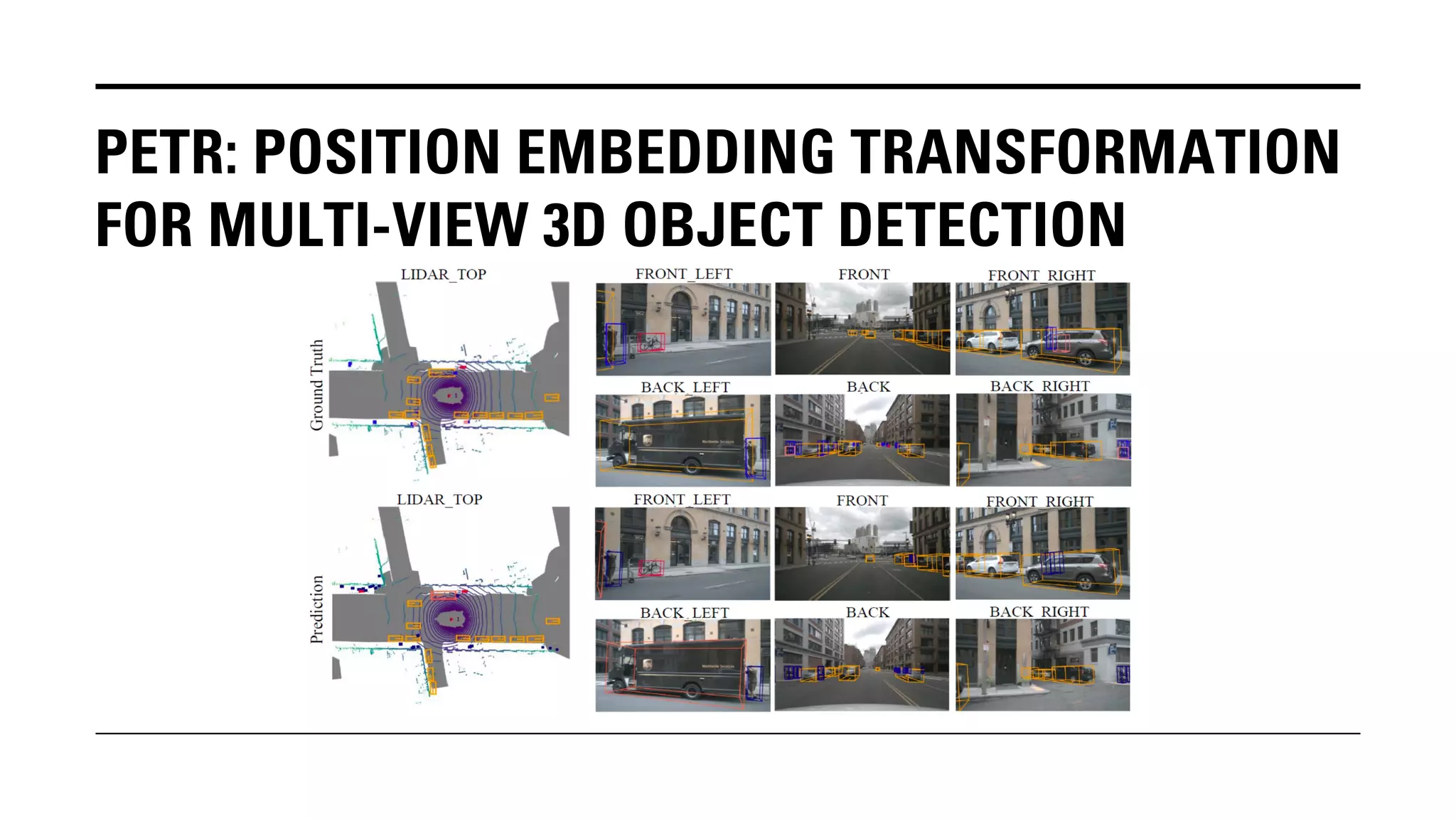

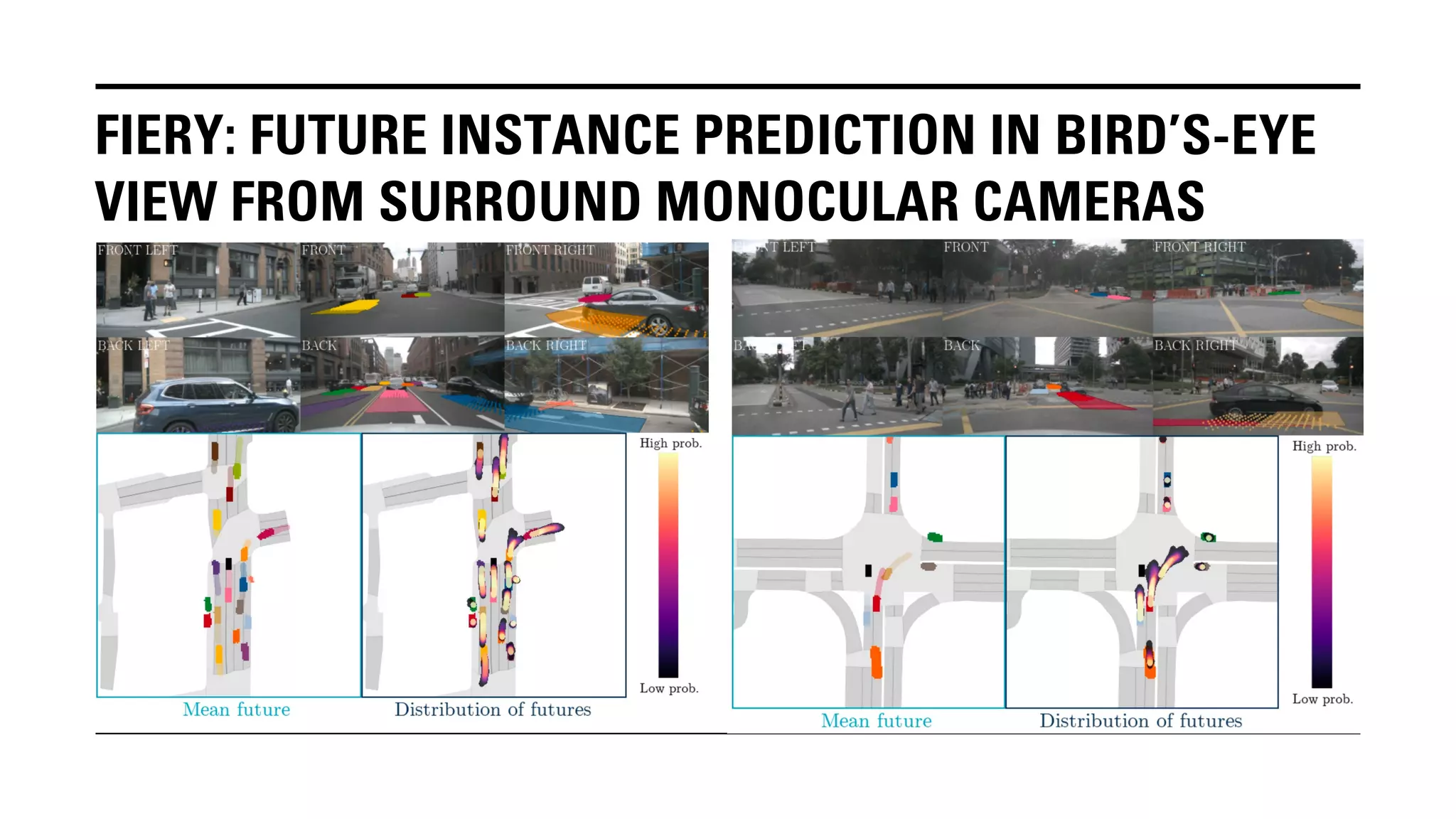
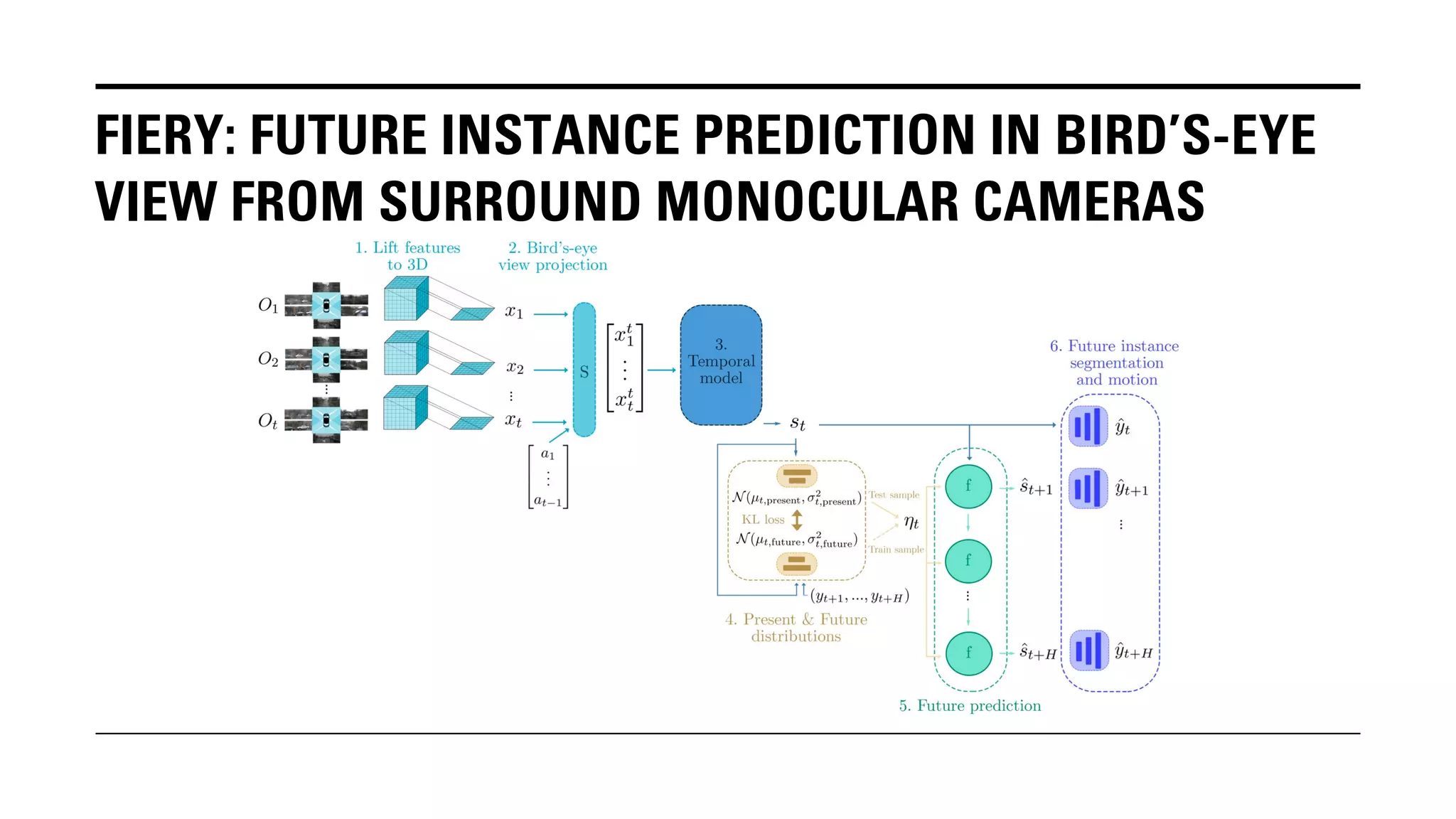
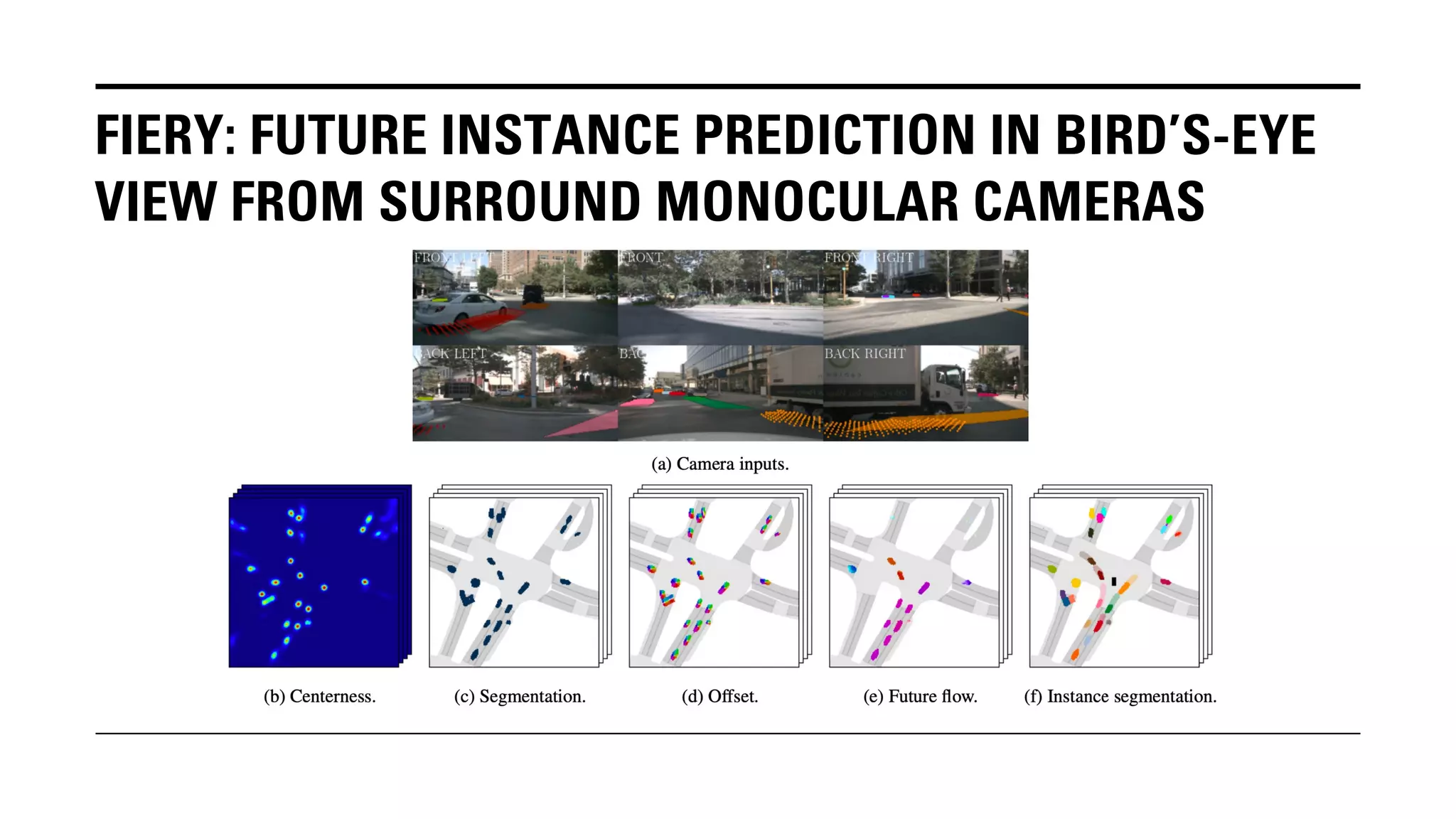




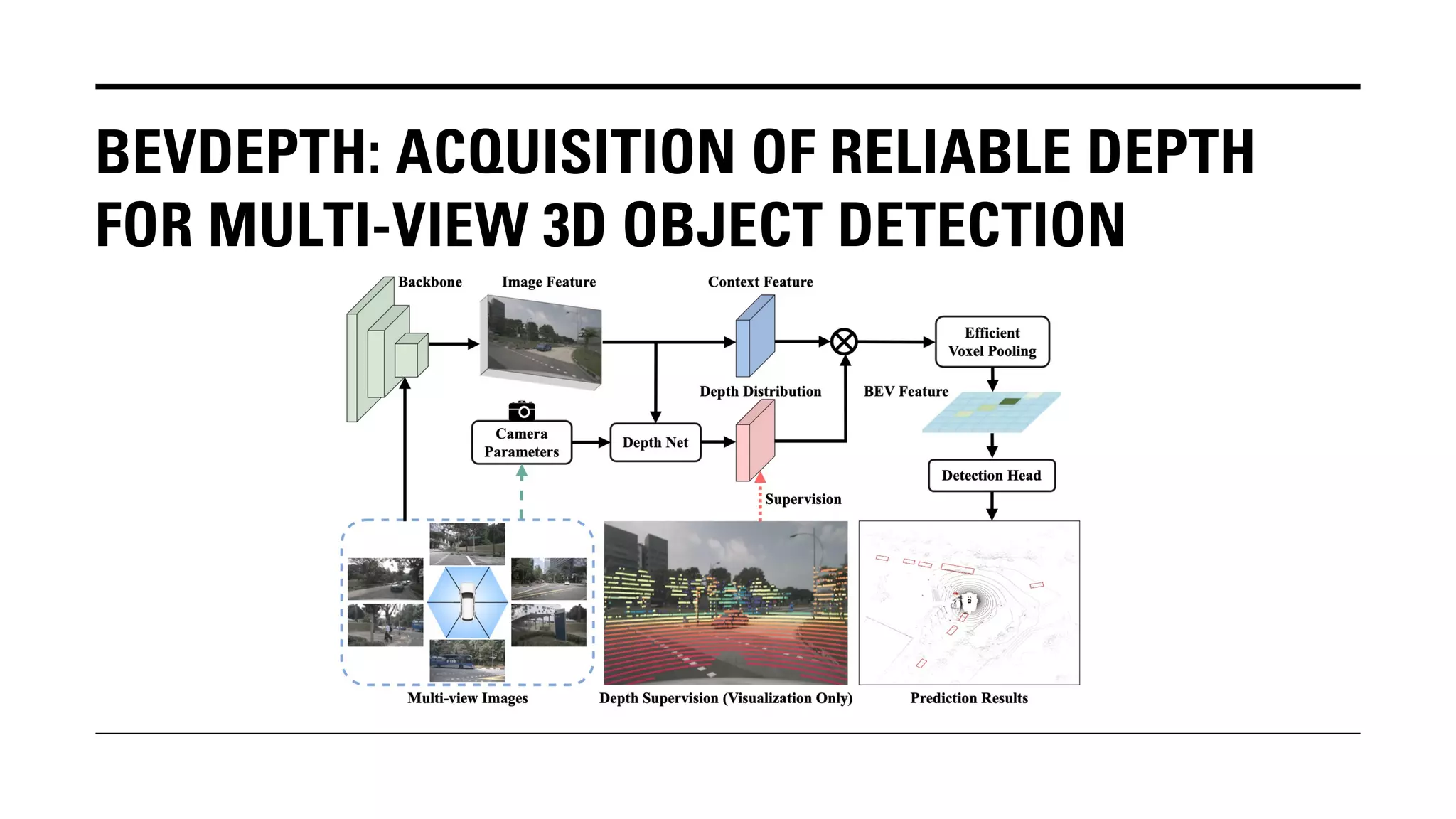
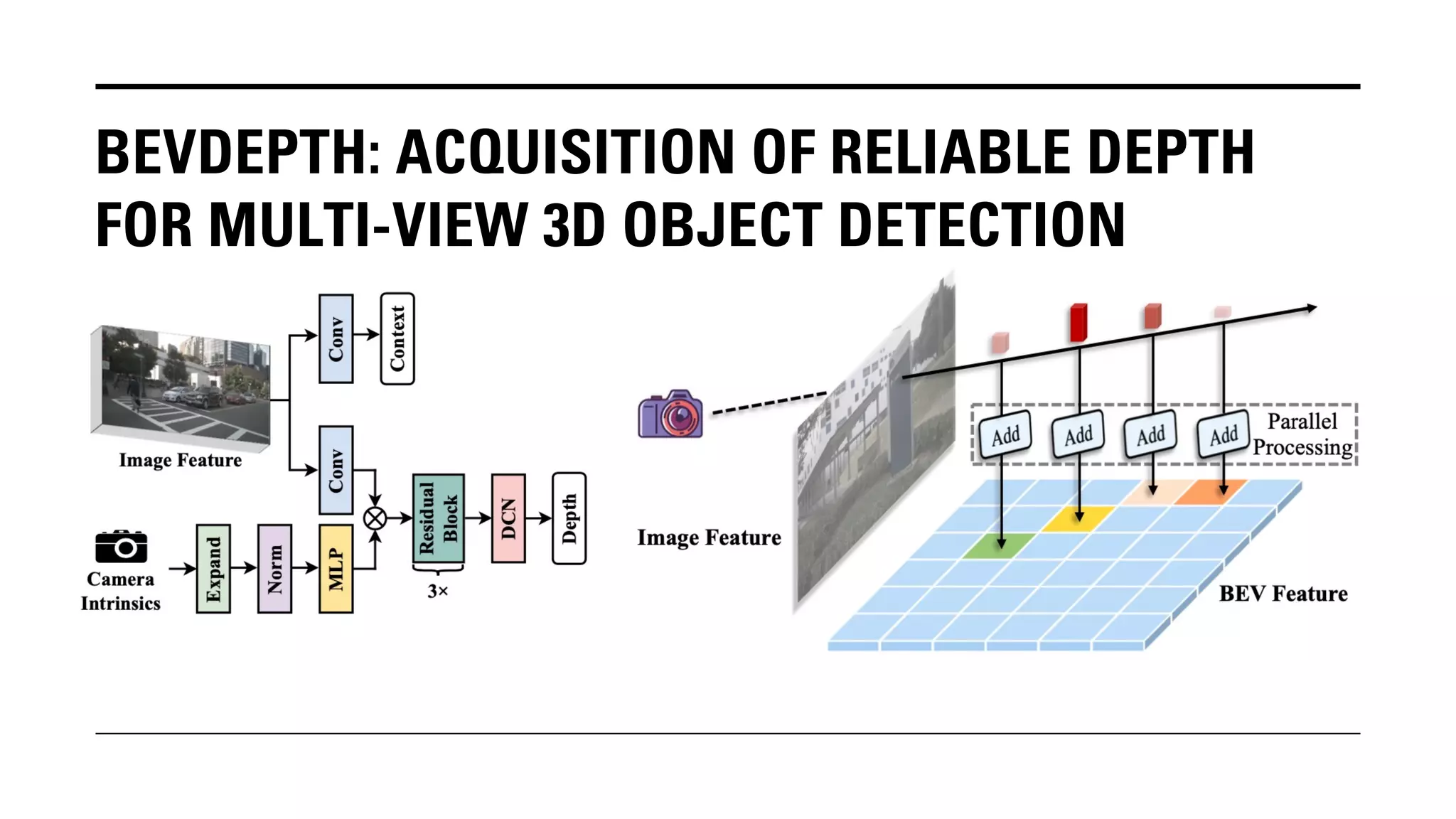
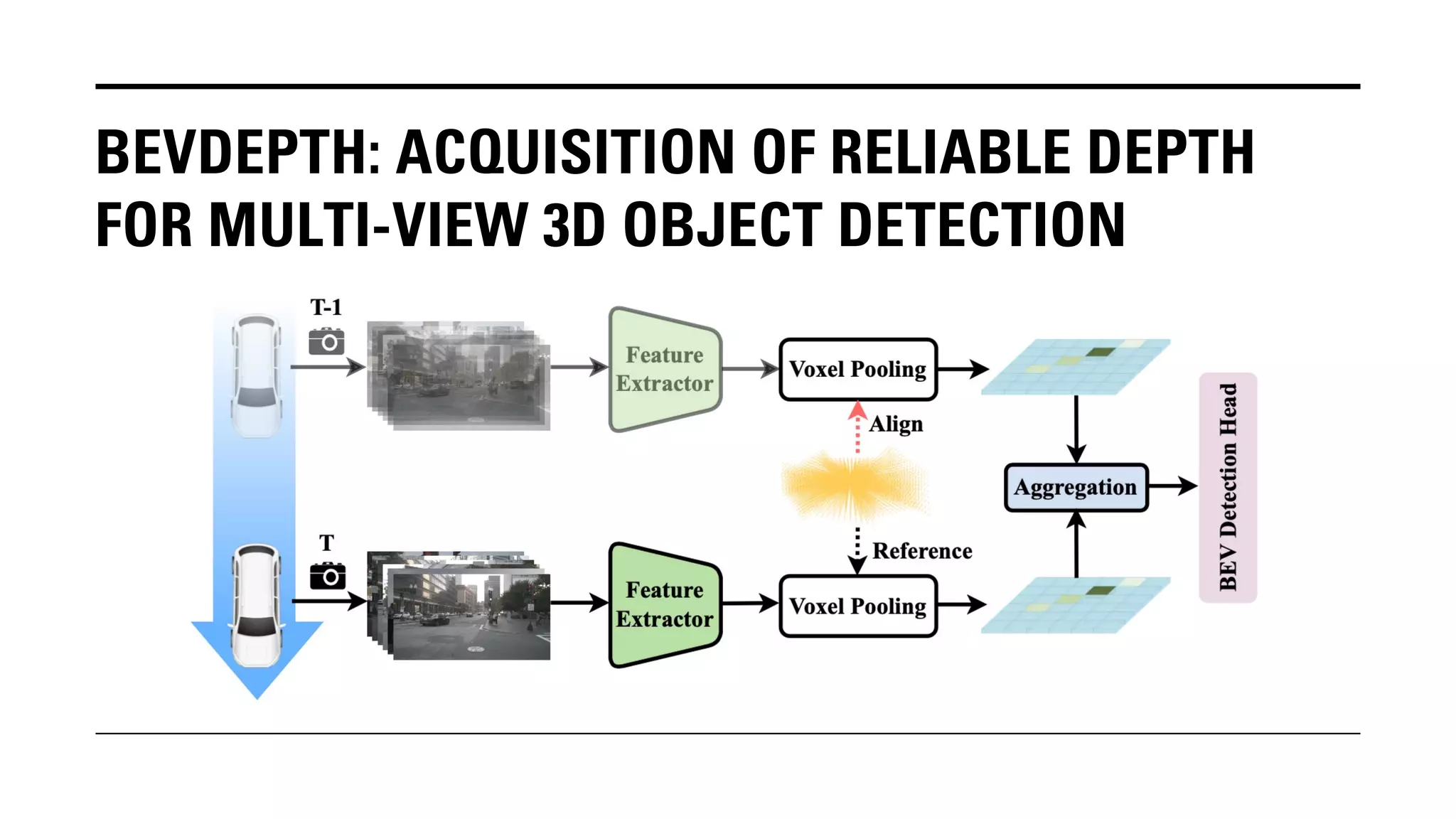
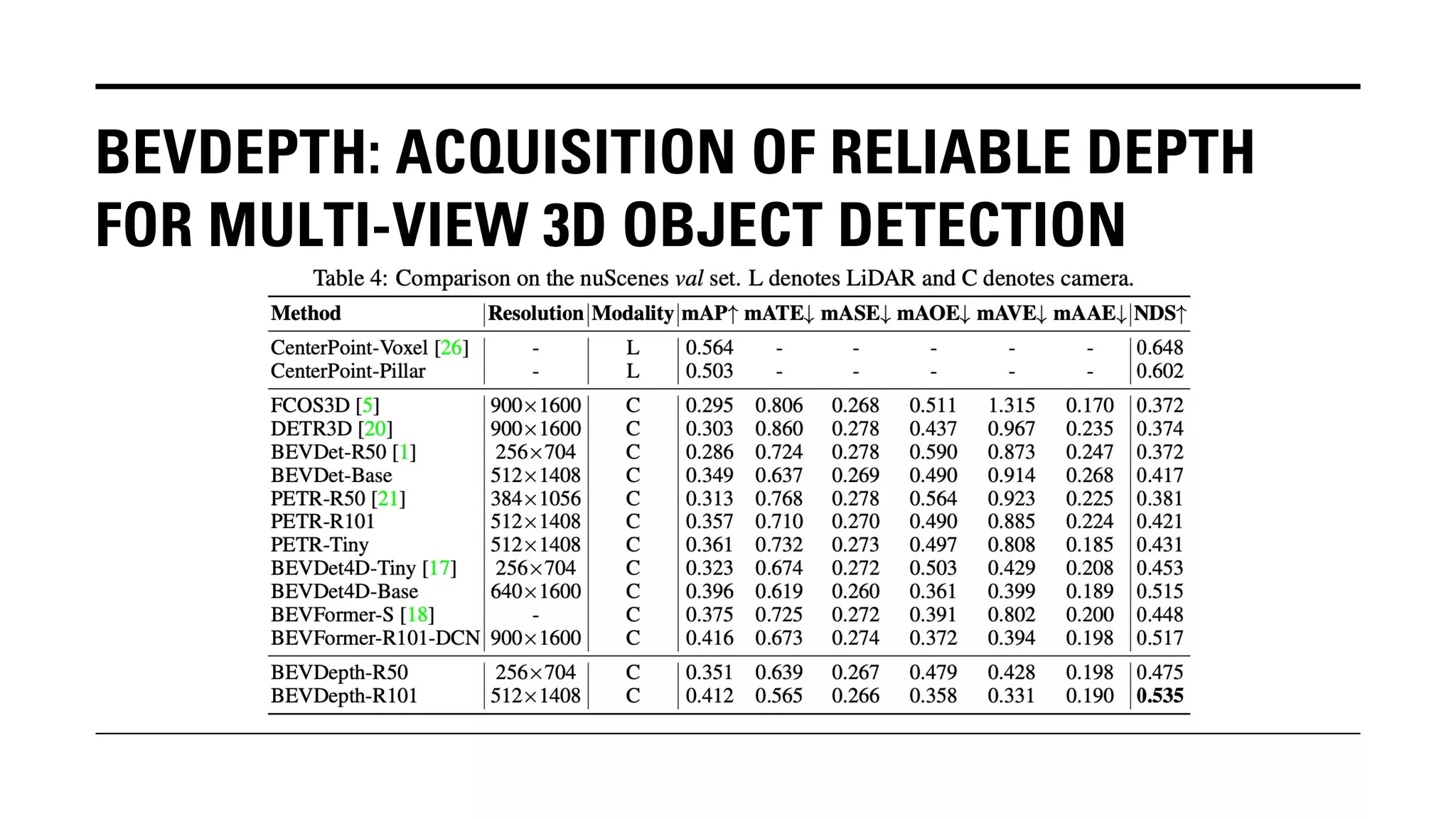
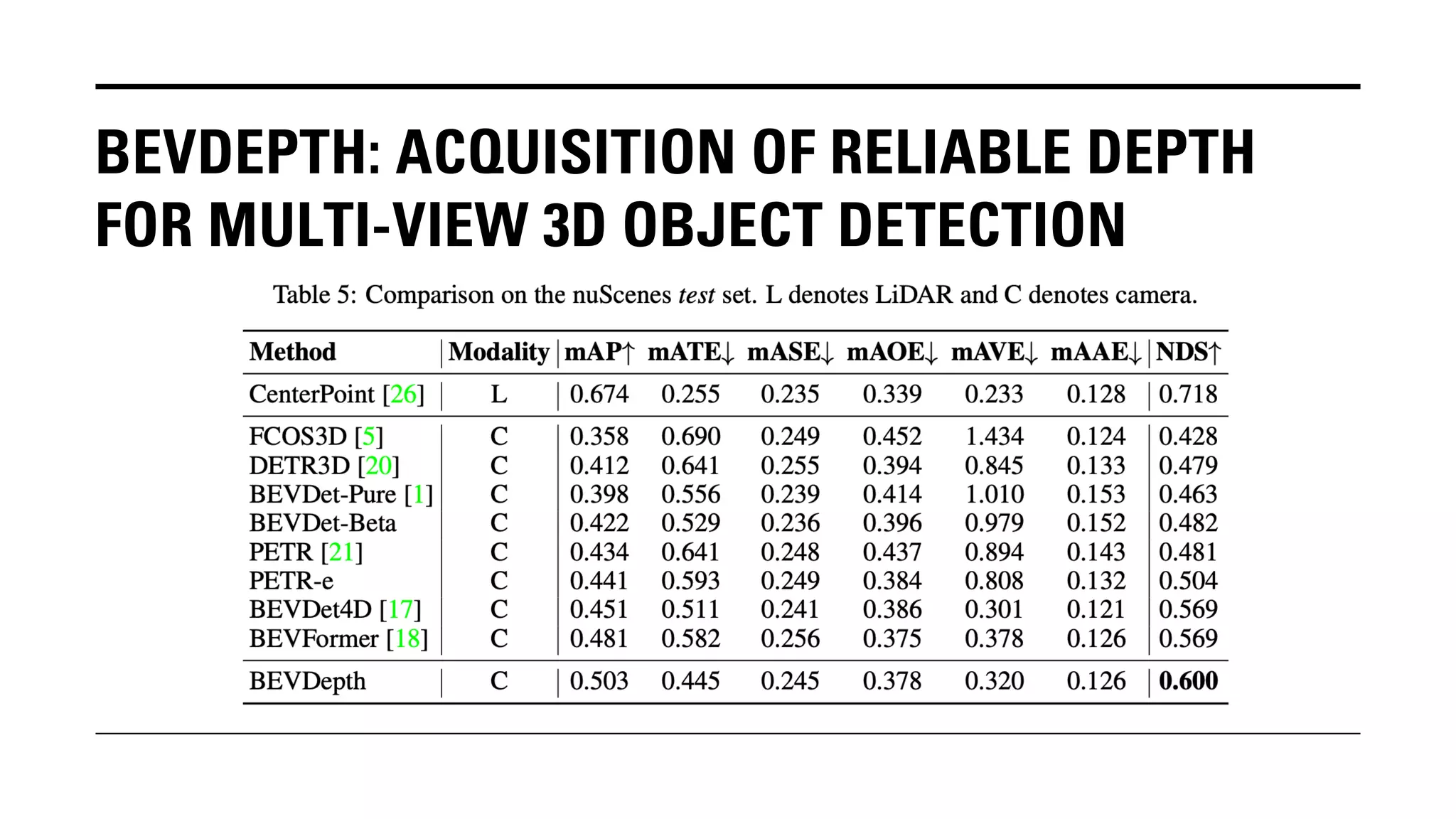


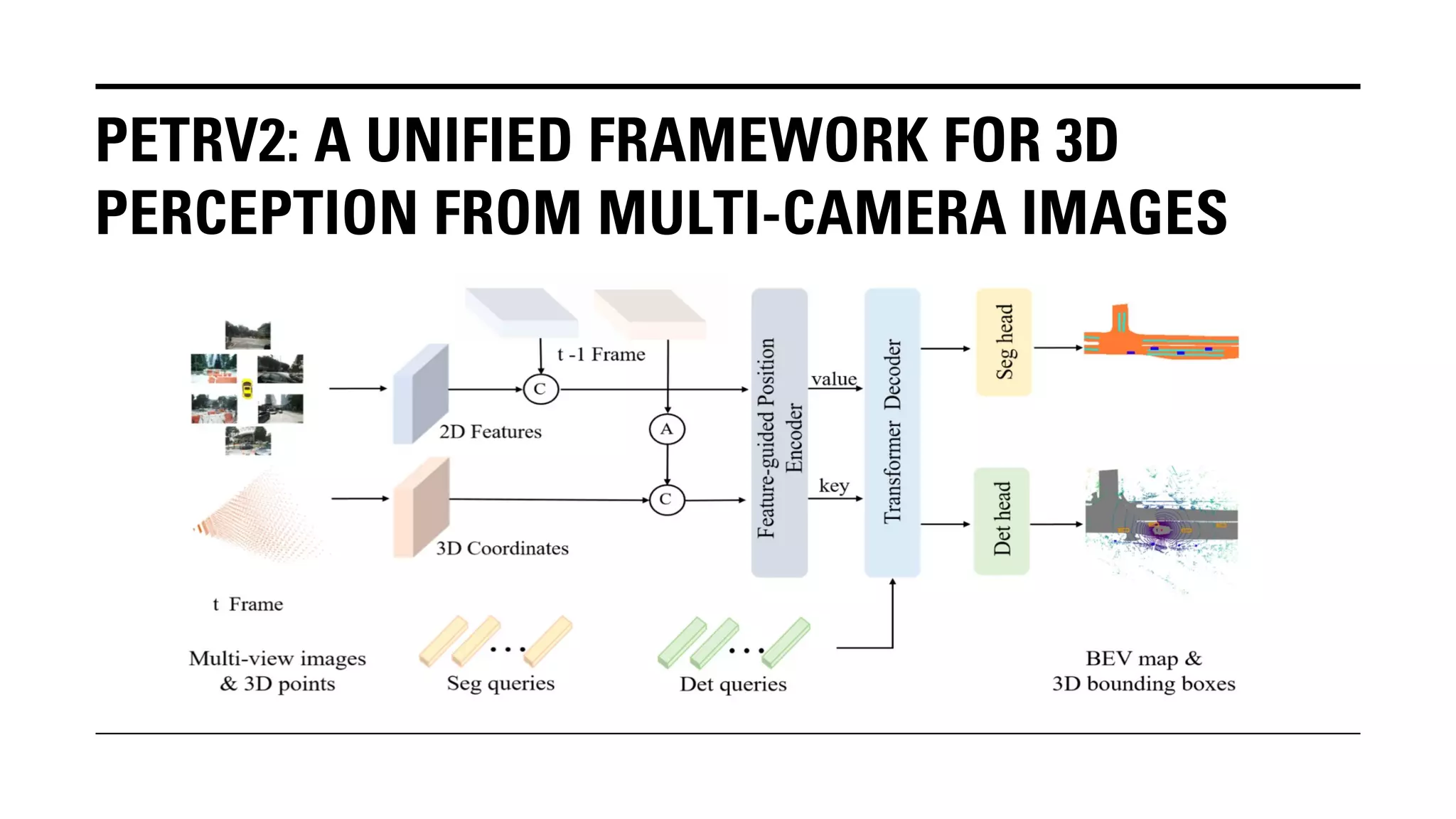
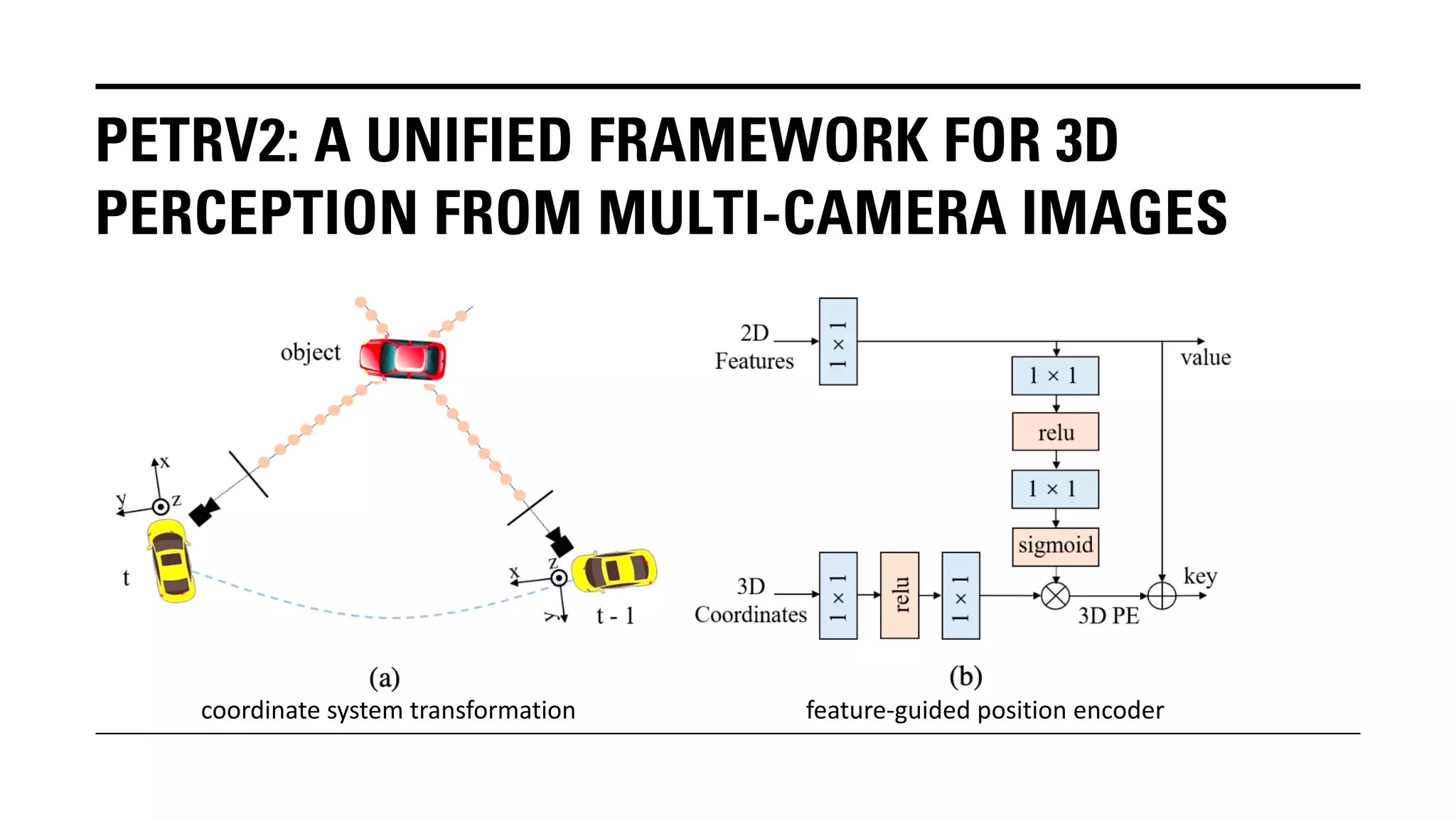



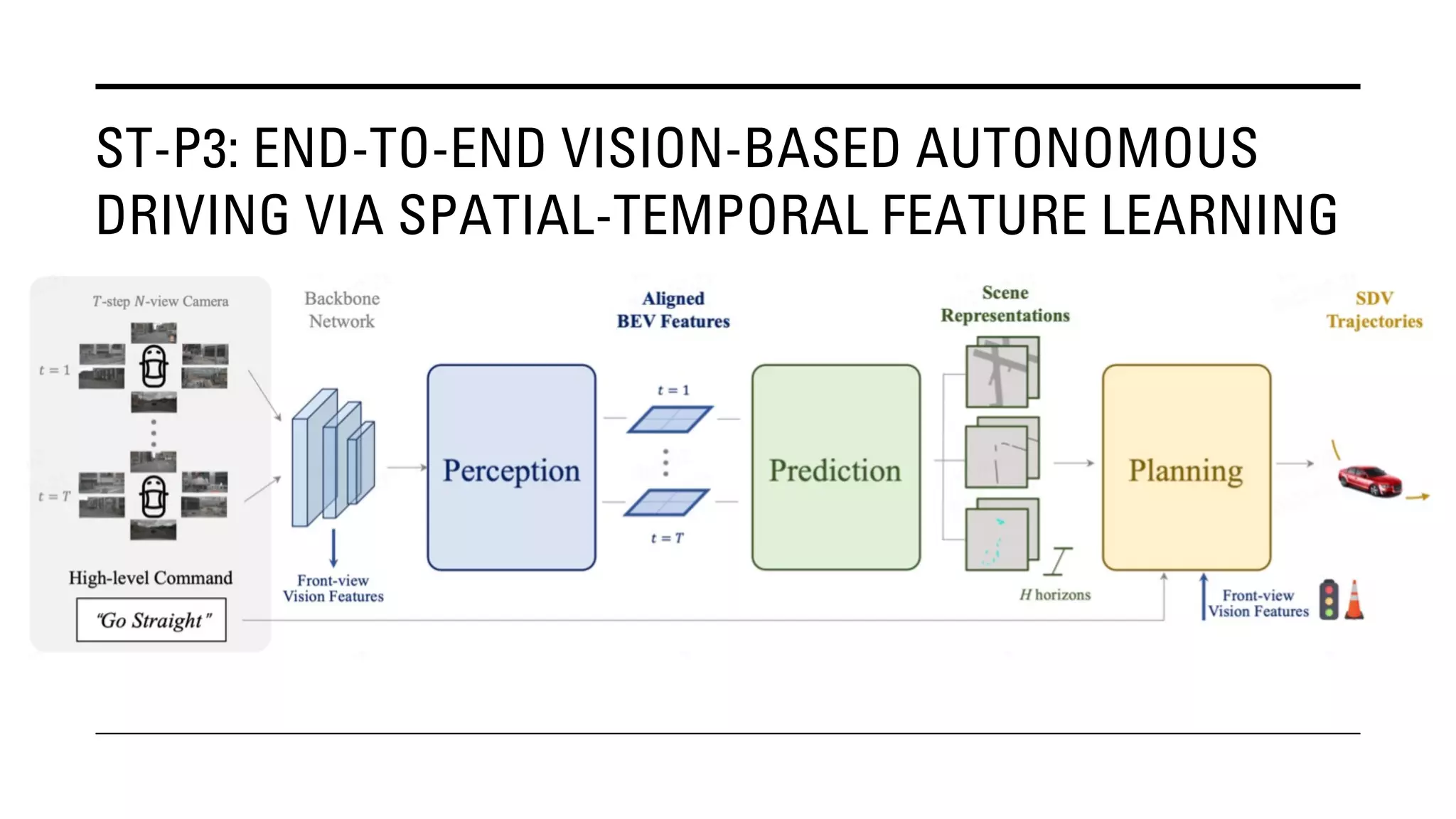
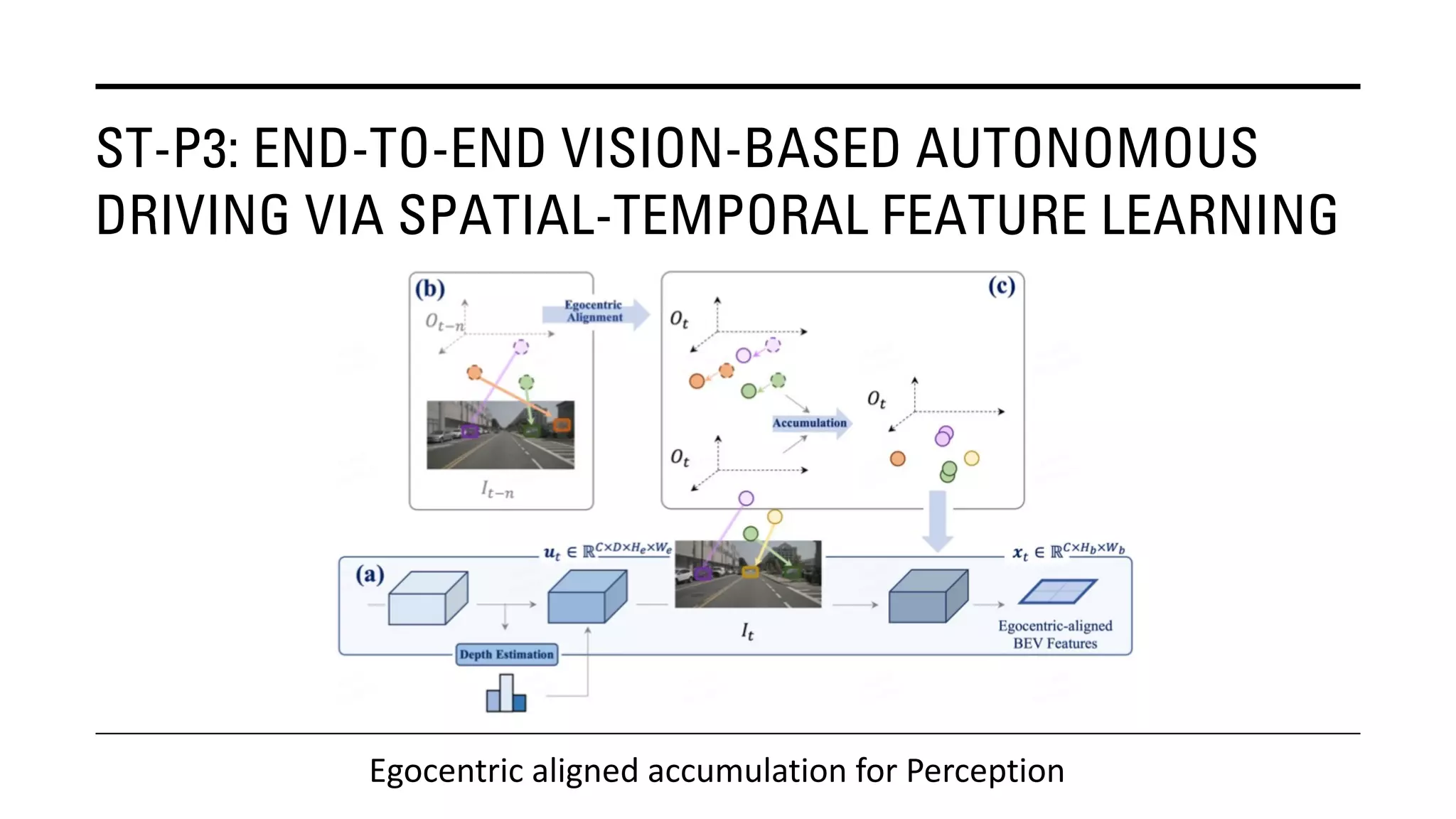
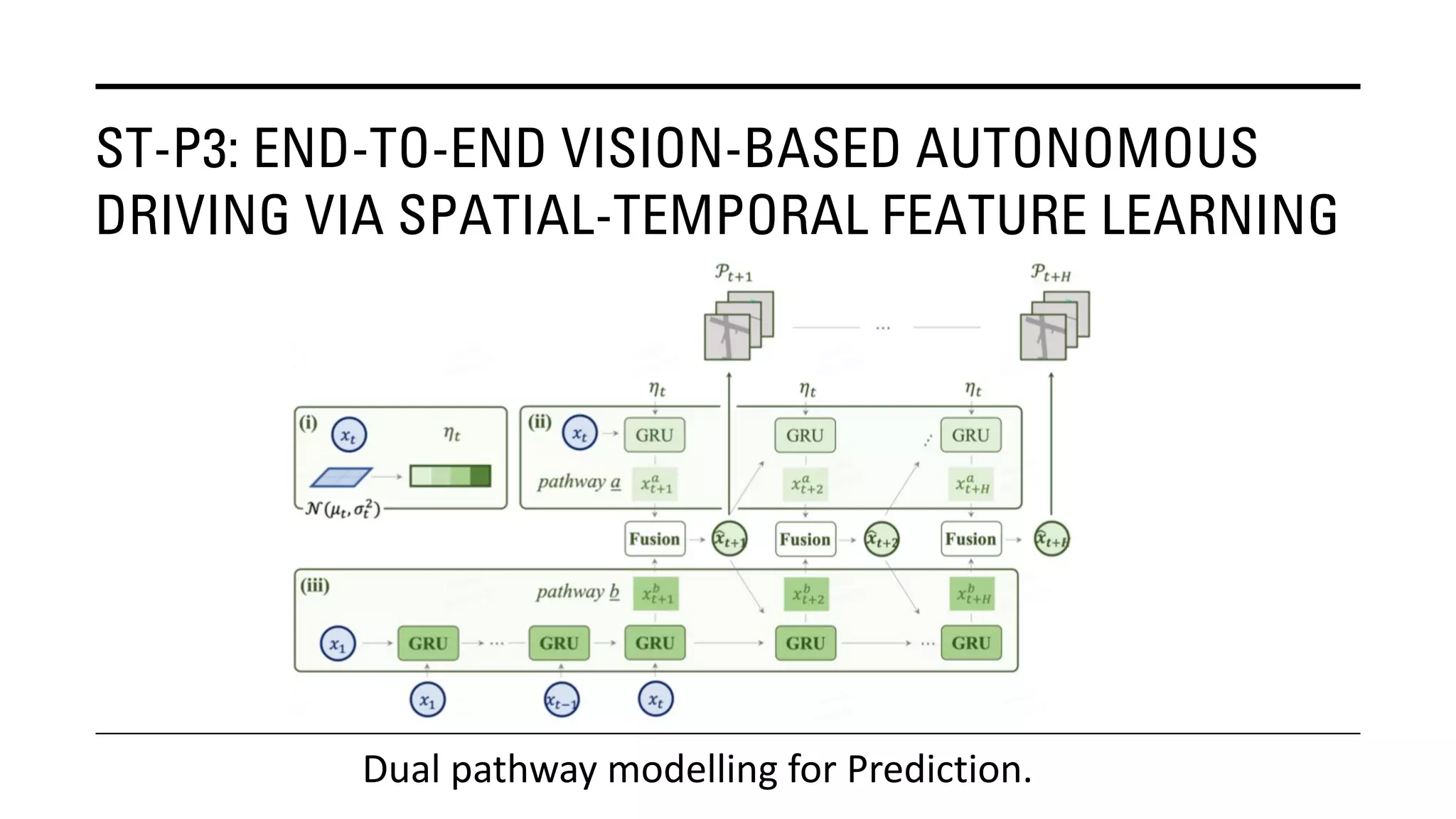
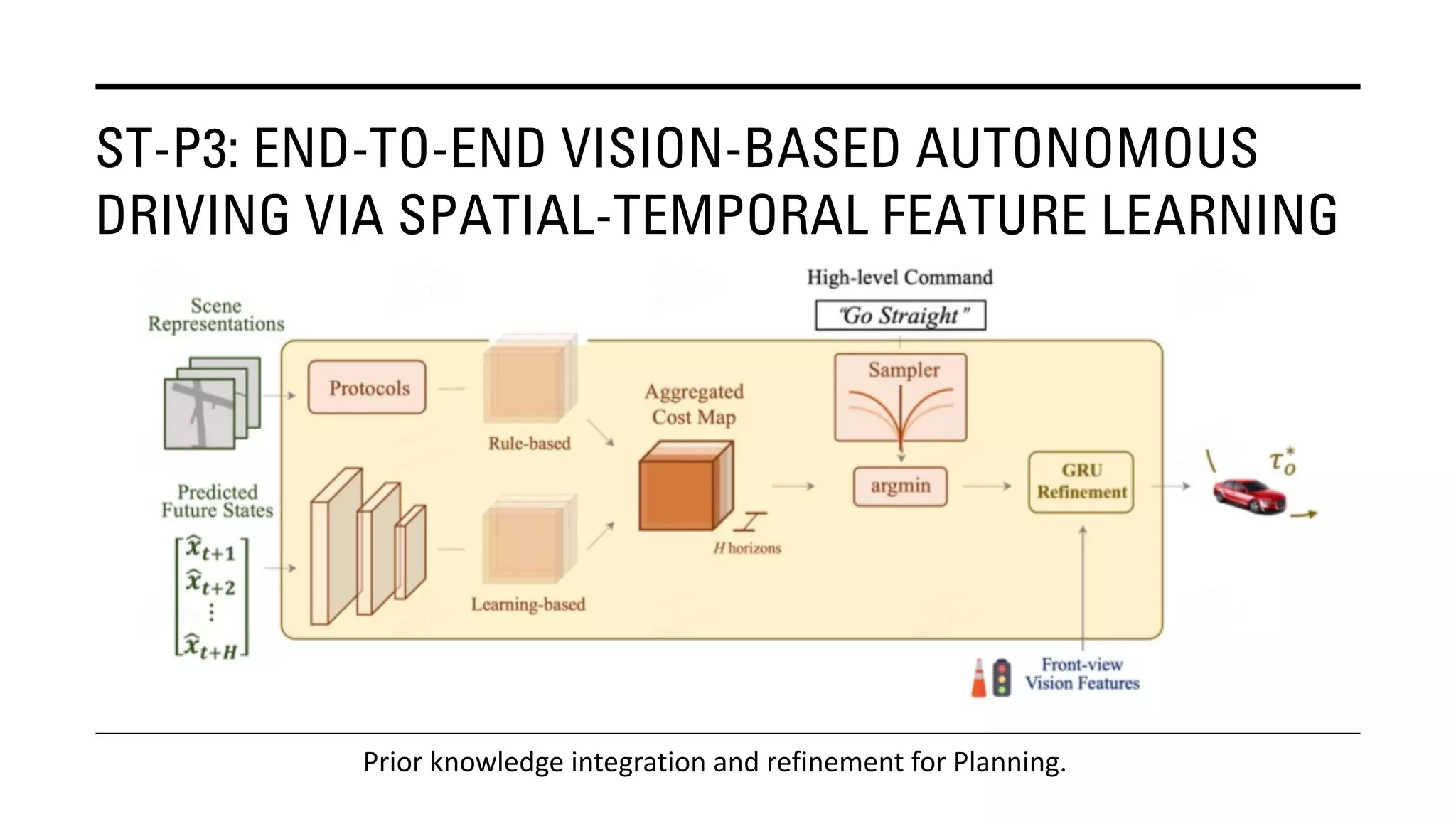
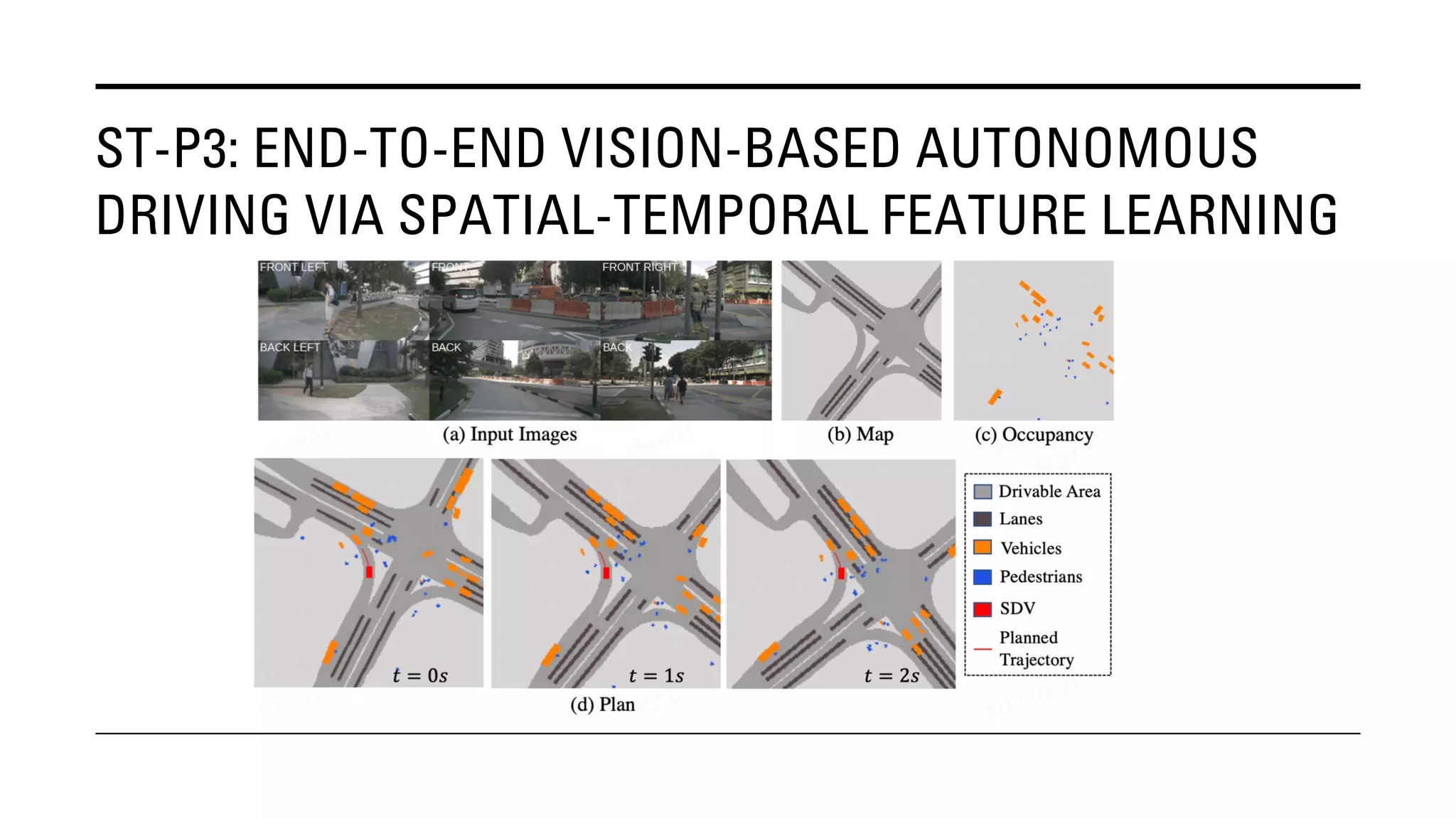
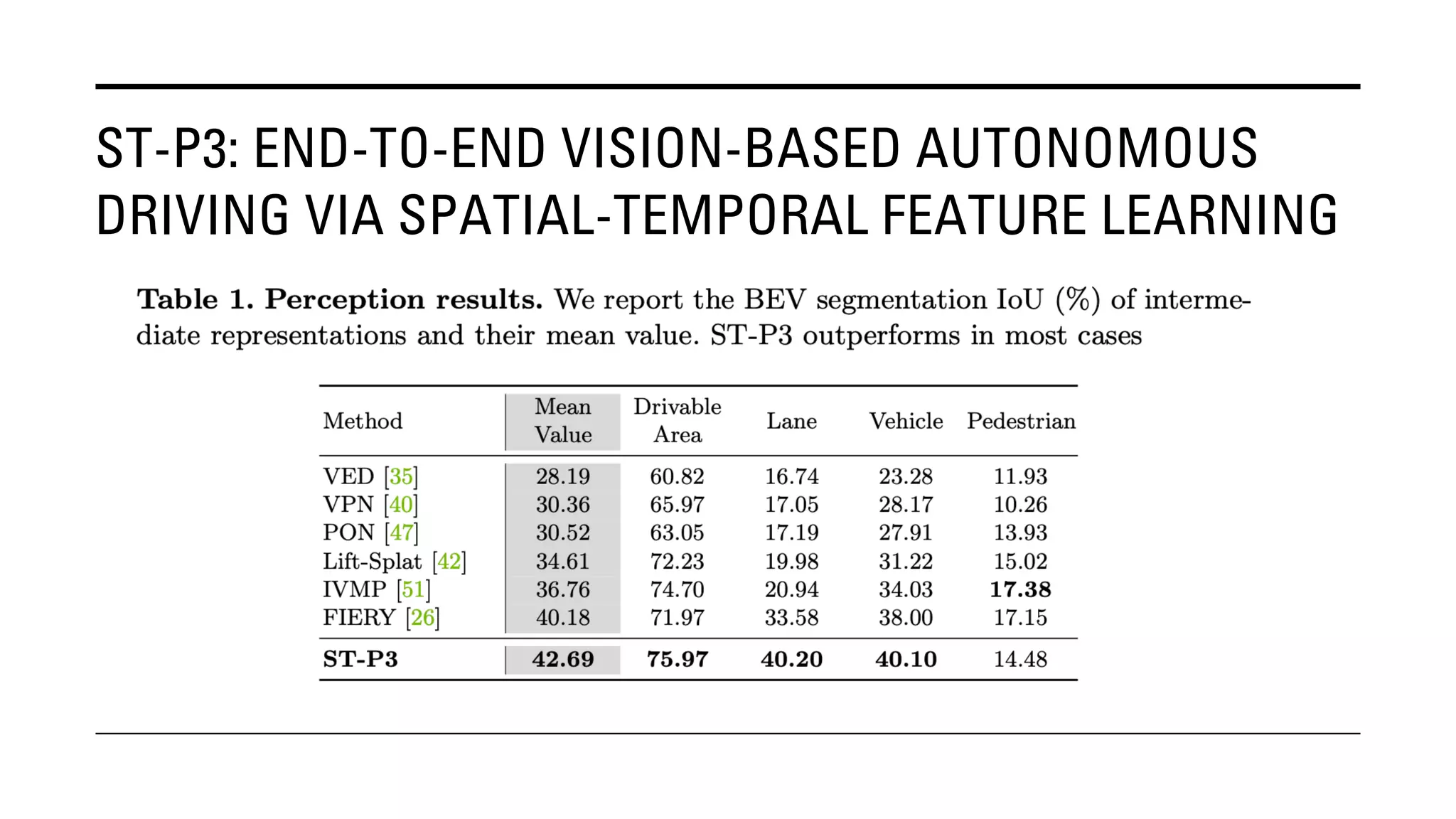
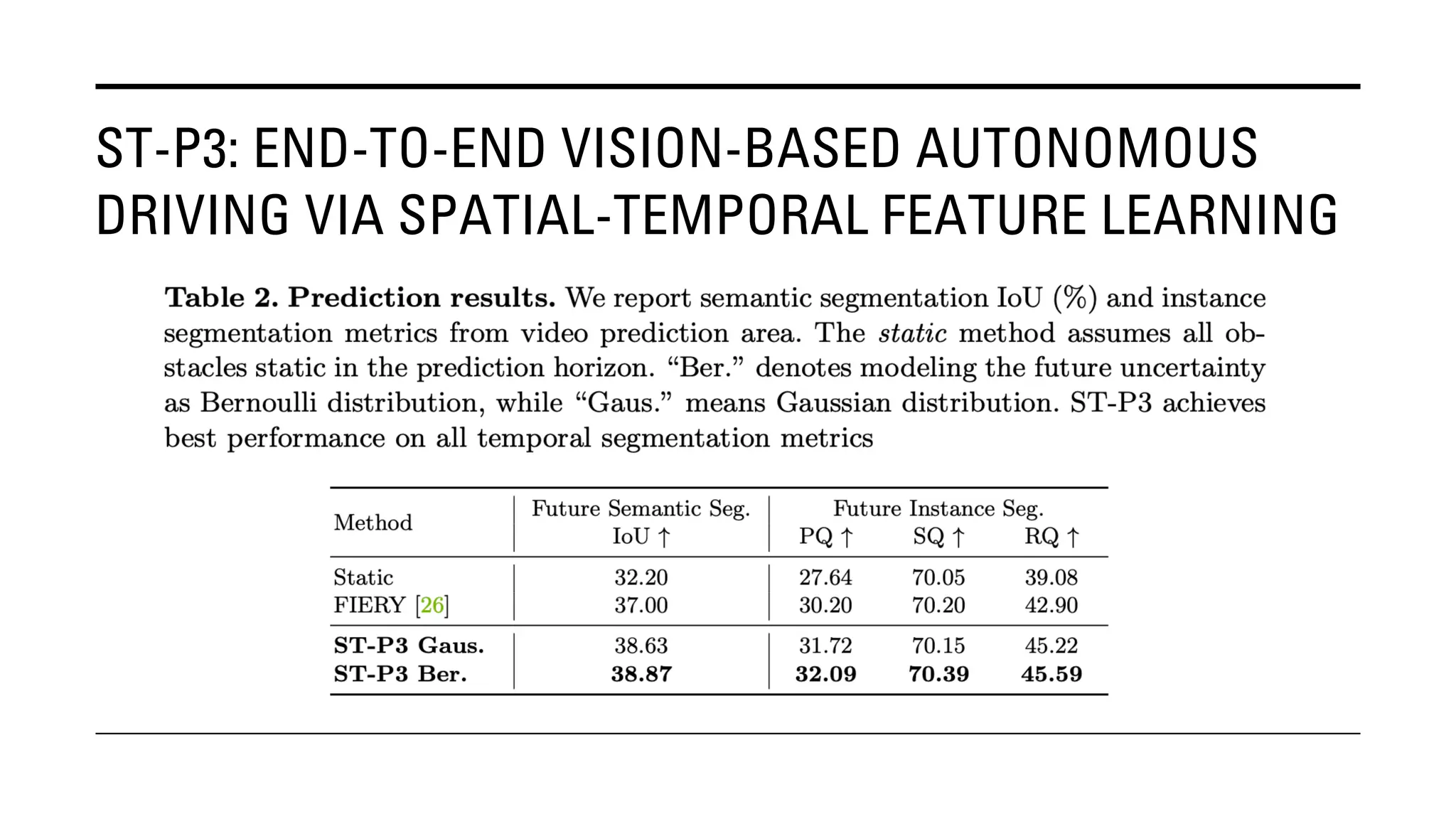



The document outlines Yu Huang's research on 3D object detection from multi-view images for autonomous vehicles. It describes several methods including: DETR3D, which uses 3D object queries to link 3D positions to multi-view images; BEVDet, which detects 3D objects in bird's-eye view; BEVDet4D, which exploits temporal cues; PETR, which encodes 3D position information; FIERY, which predicts future instances; BEVDepth, which estimates reliable depth; PETRv2, which provides a unified framework; and ST-P3, which uses spatial-temporal feature learning for perception, prediction and planning. The research aims to advance 3D object detection capabilities for autonomous














![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)






































































