Download as PDF, PPTX





























The document discusses the role of large-scale foundation models in autonomous driving, focusing on various models like large-scale language models, visual language models, diffusion models, and neural radiance fields. It outlines their applications in simulation, world modeling, data annotation, and decision-making processes for driving. The conclusion highlights the advanced capabilities these models provide, emphasizing their integration and potential for enhancing autonomous driving technologies.
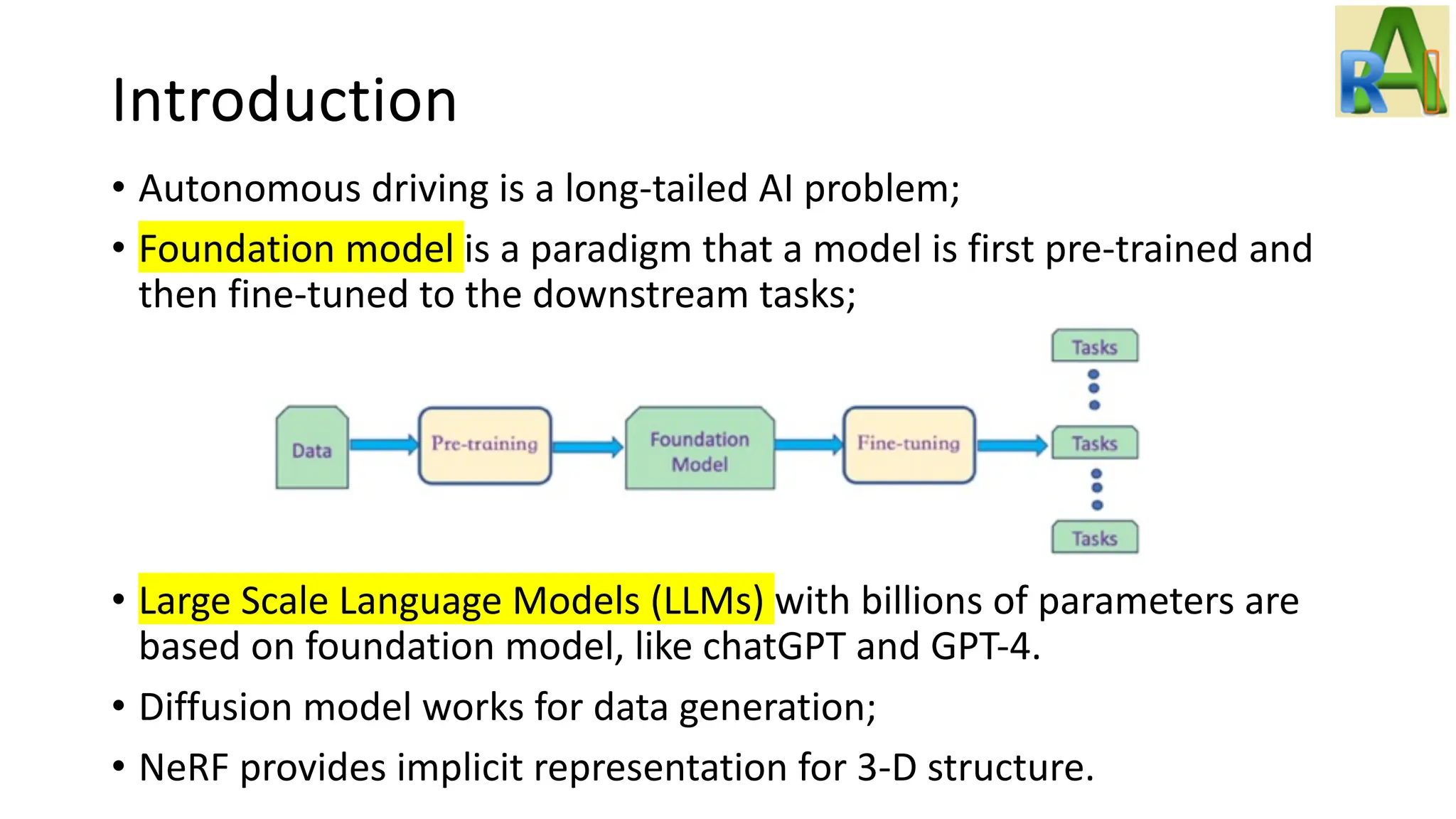
The presentation introduces foundation models for autonomous driving, emphasizing large-scale language models (LLMs) like chatGPT and GPT-4, alongside diffusion models and NeRF.
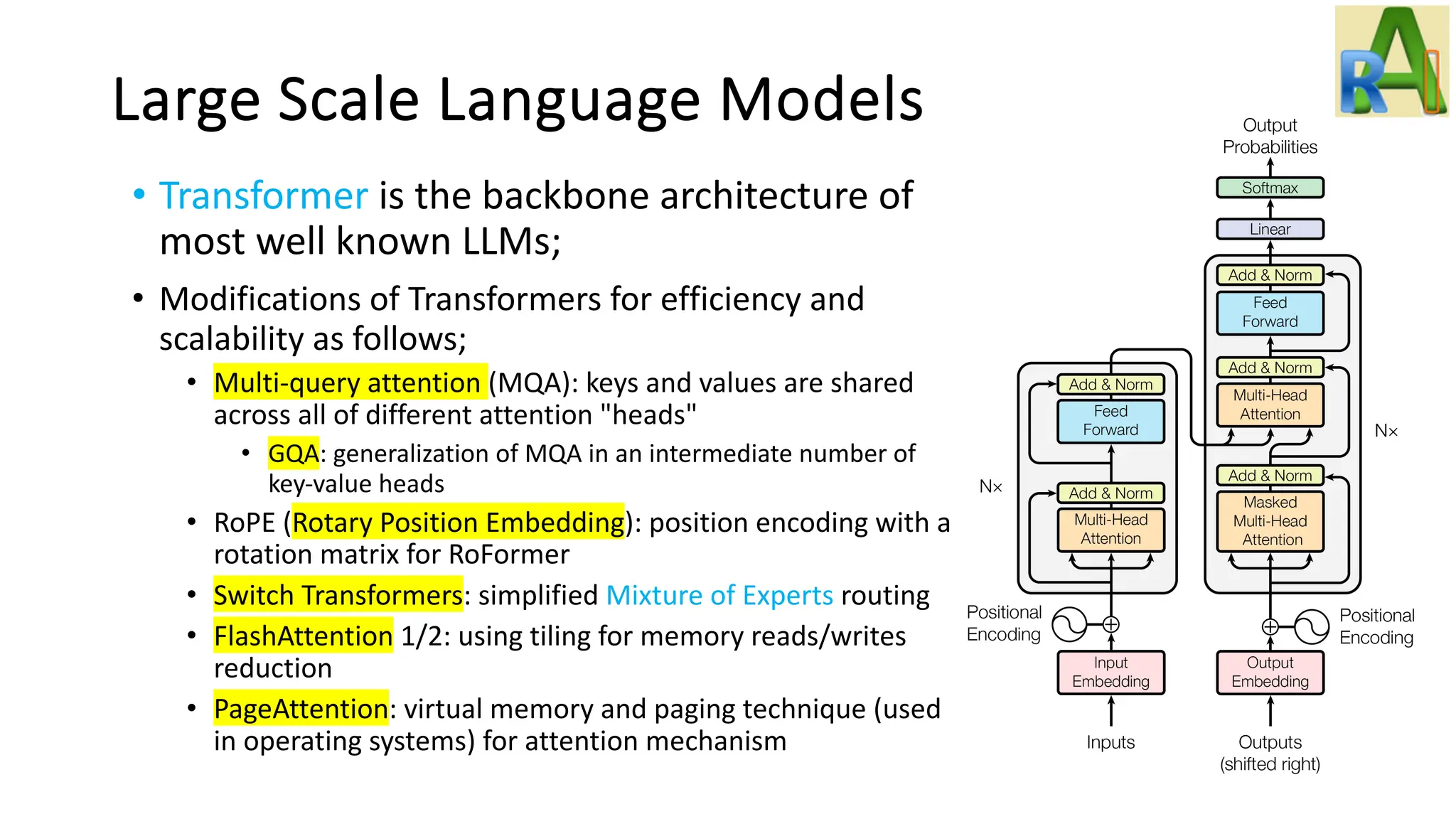
Discusses the architecture and efficiency of LLMs, focusing on training techniques, platforms like DeepSpeed and Megatron-LM, and challenges like hallucination and explainability.
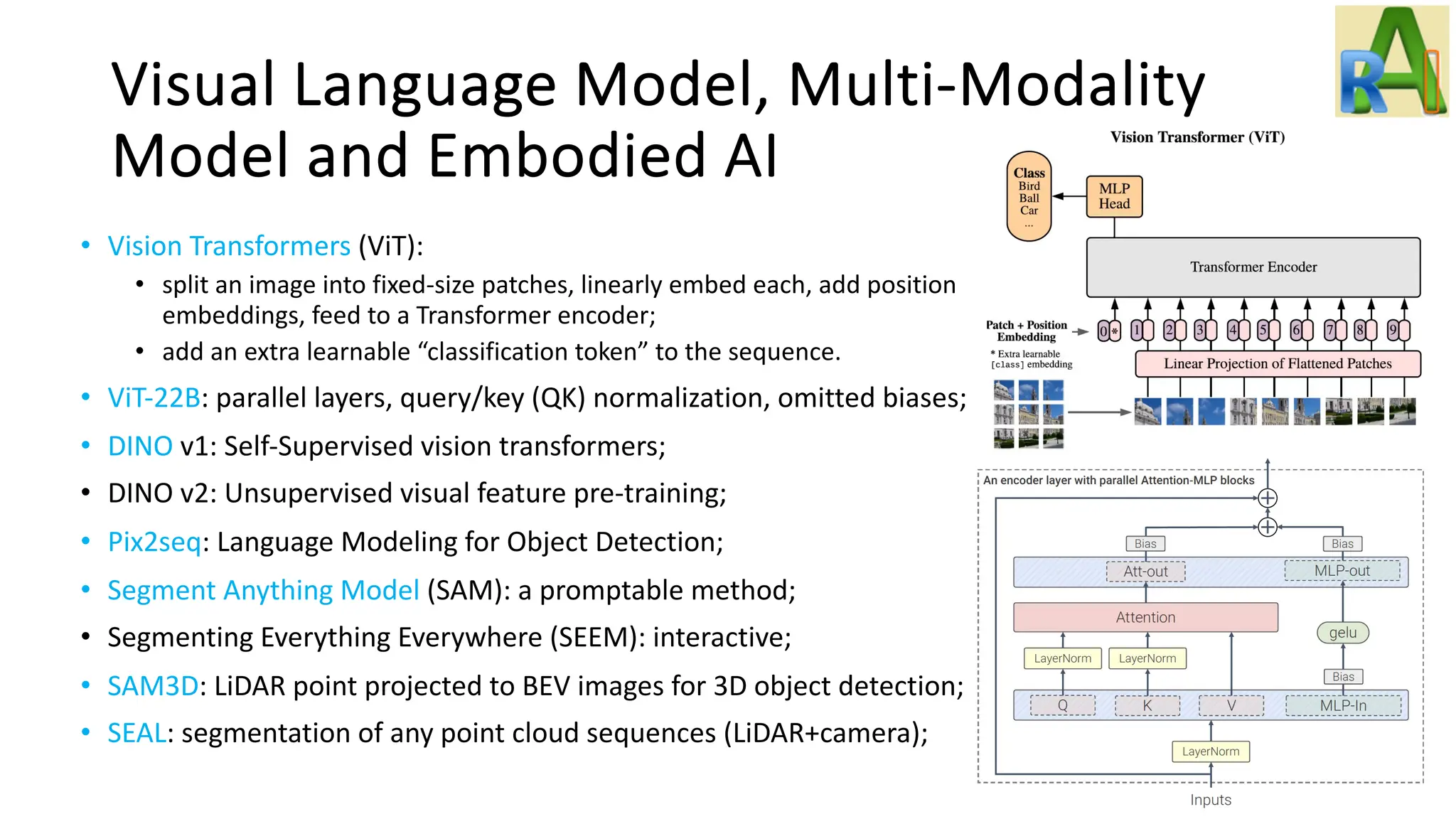
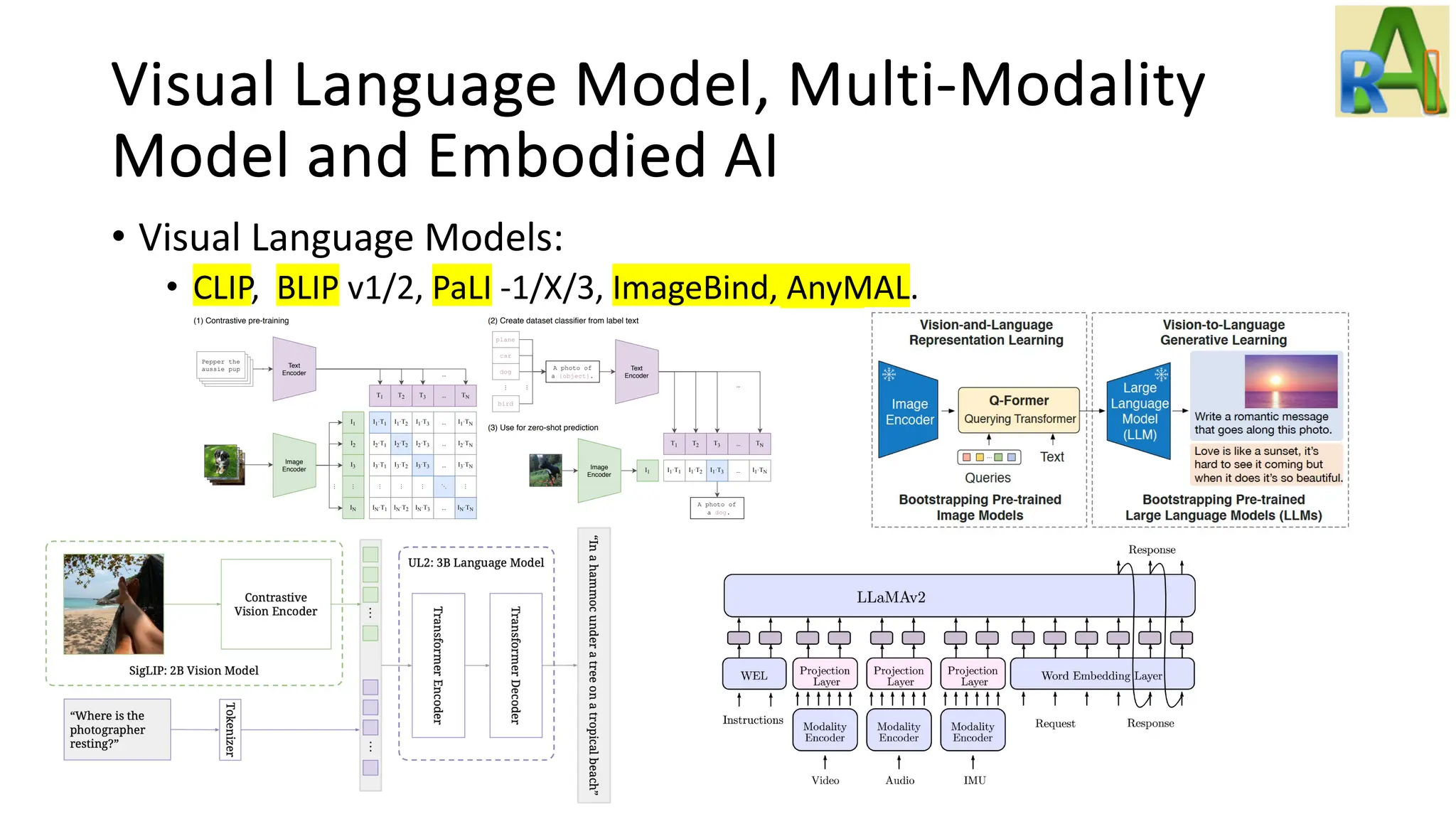
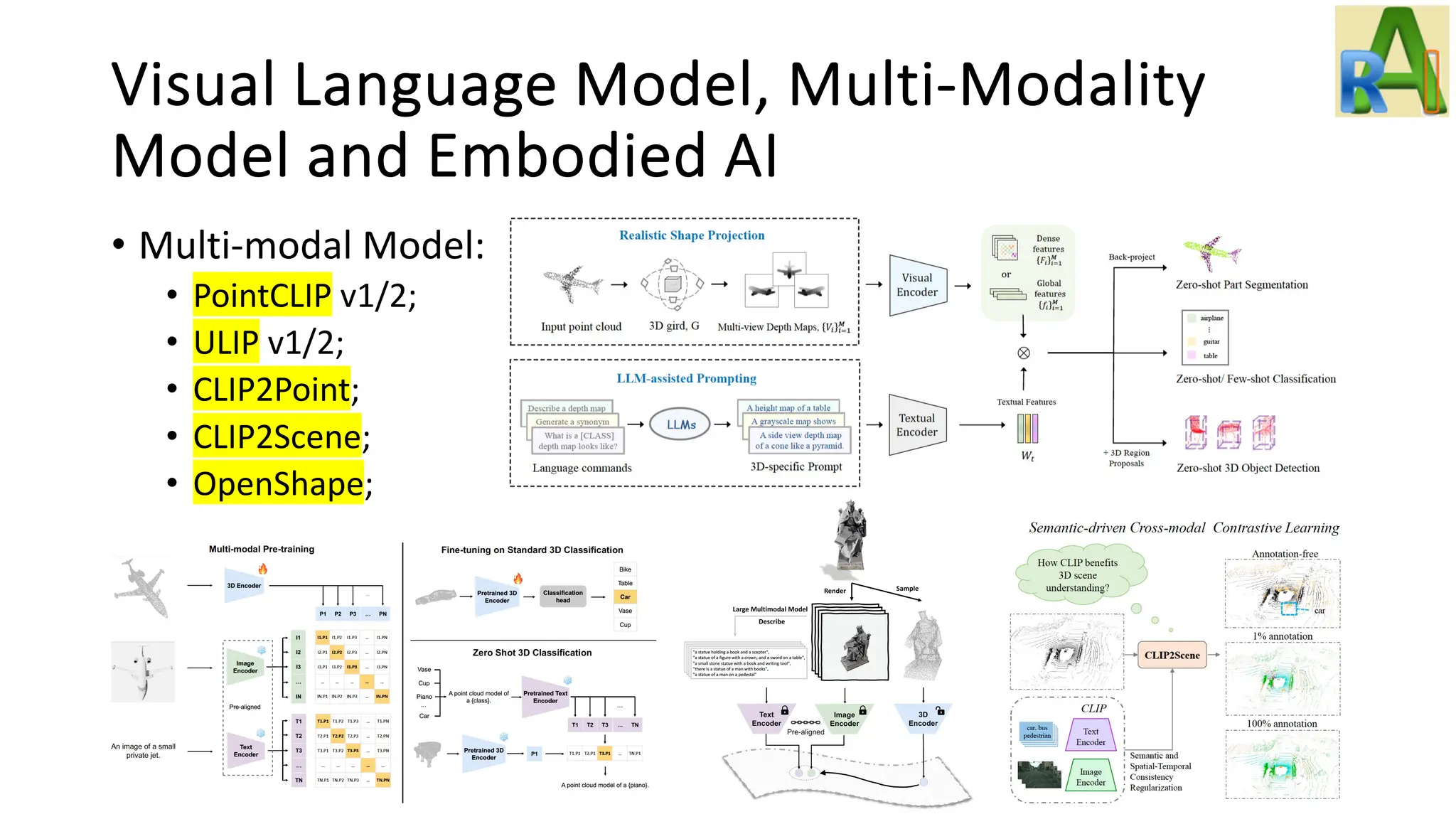
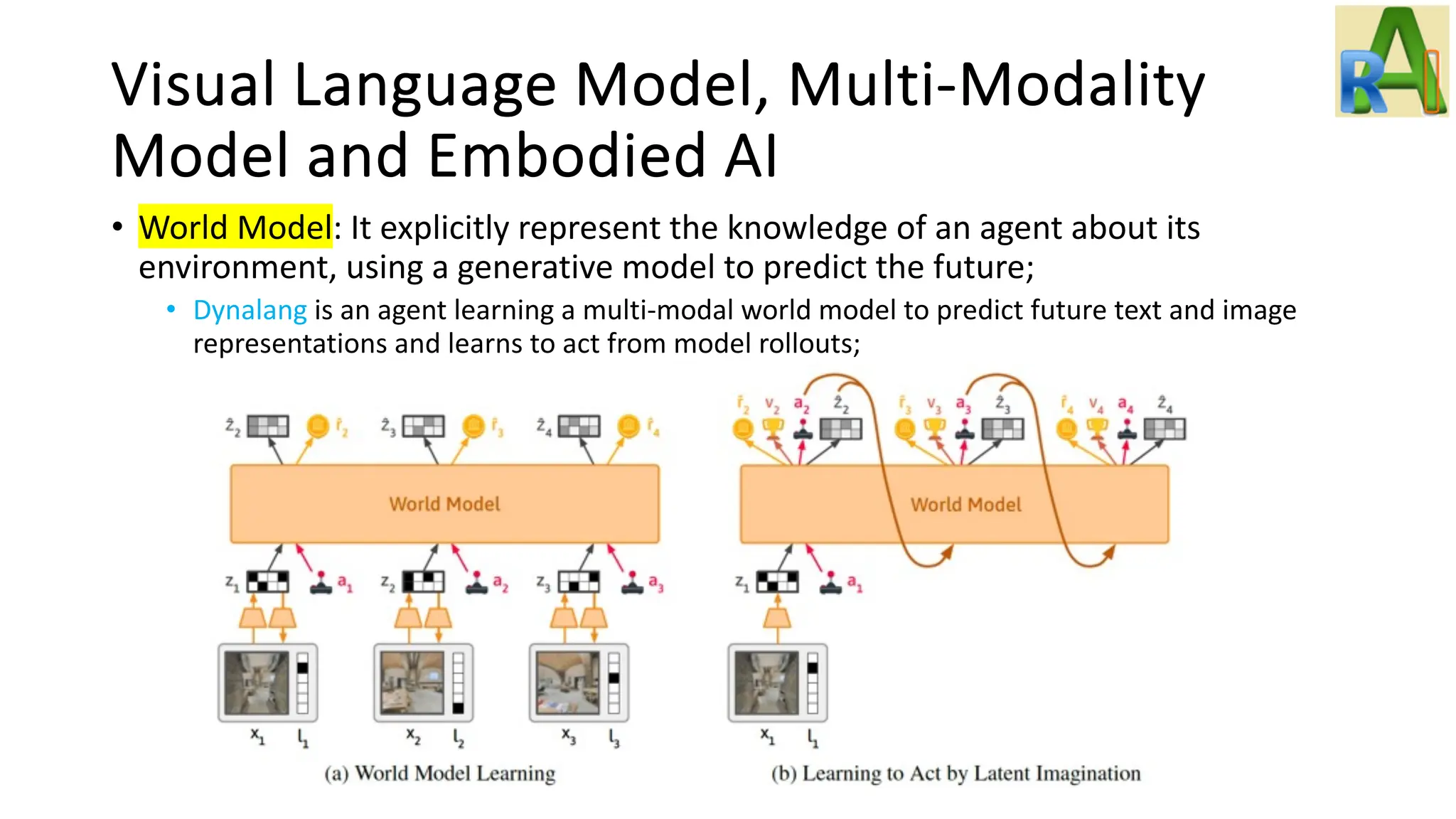
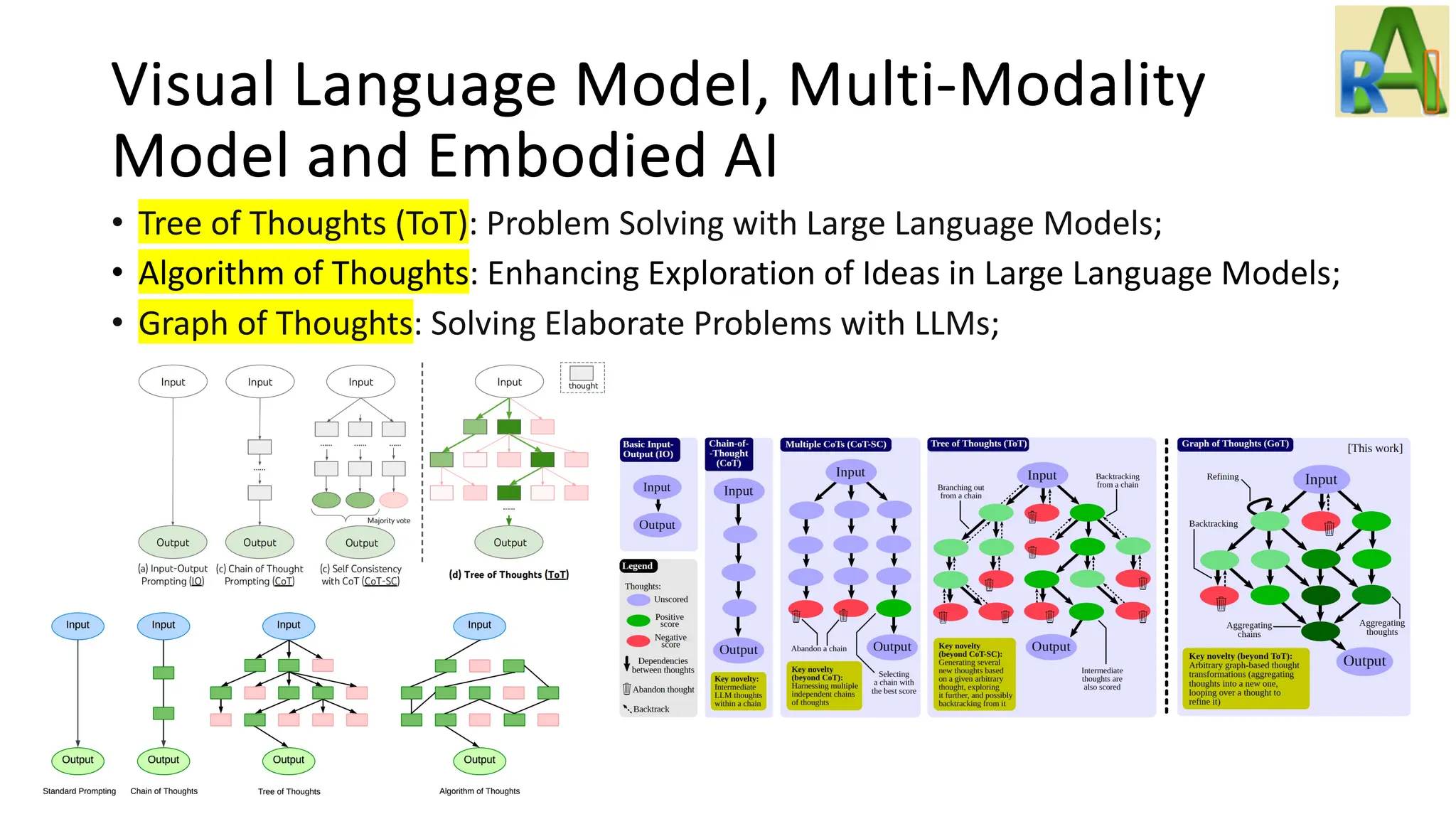
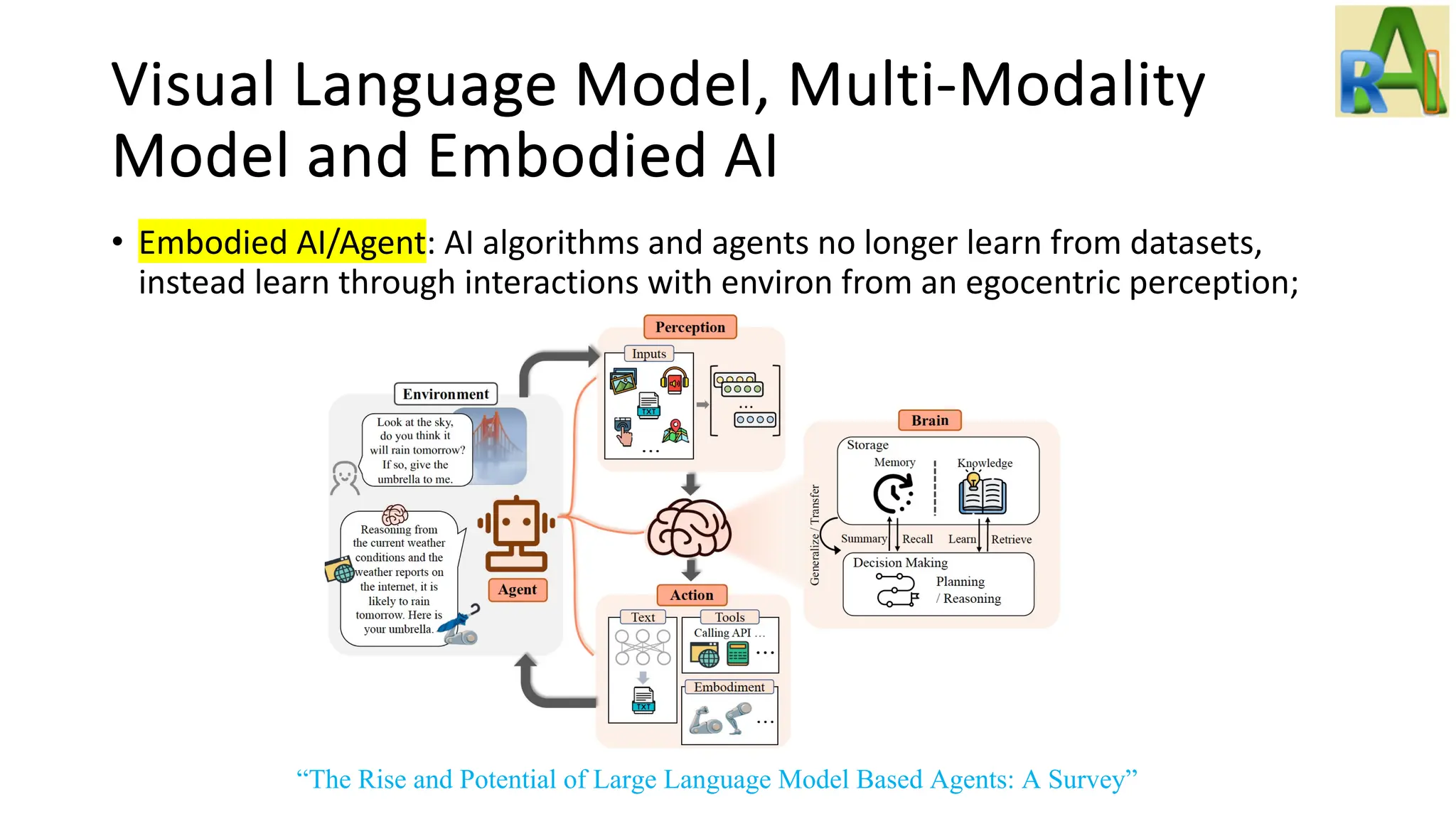
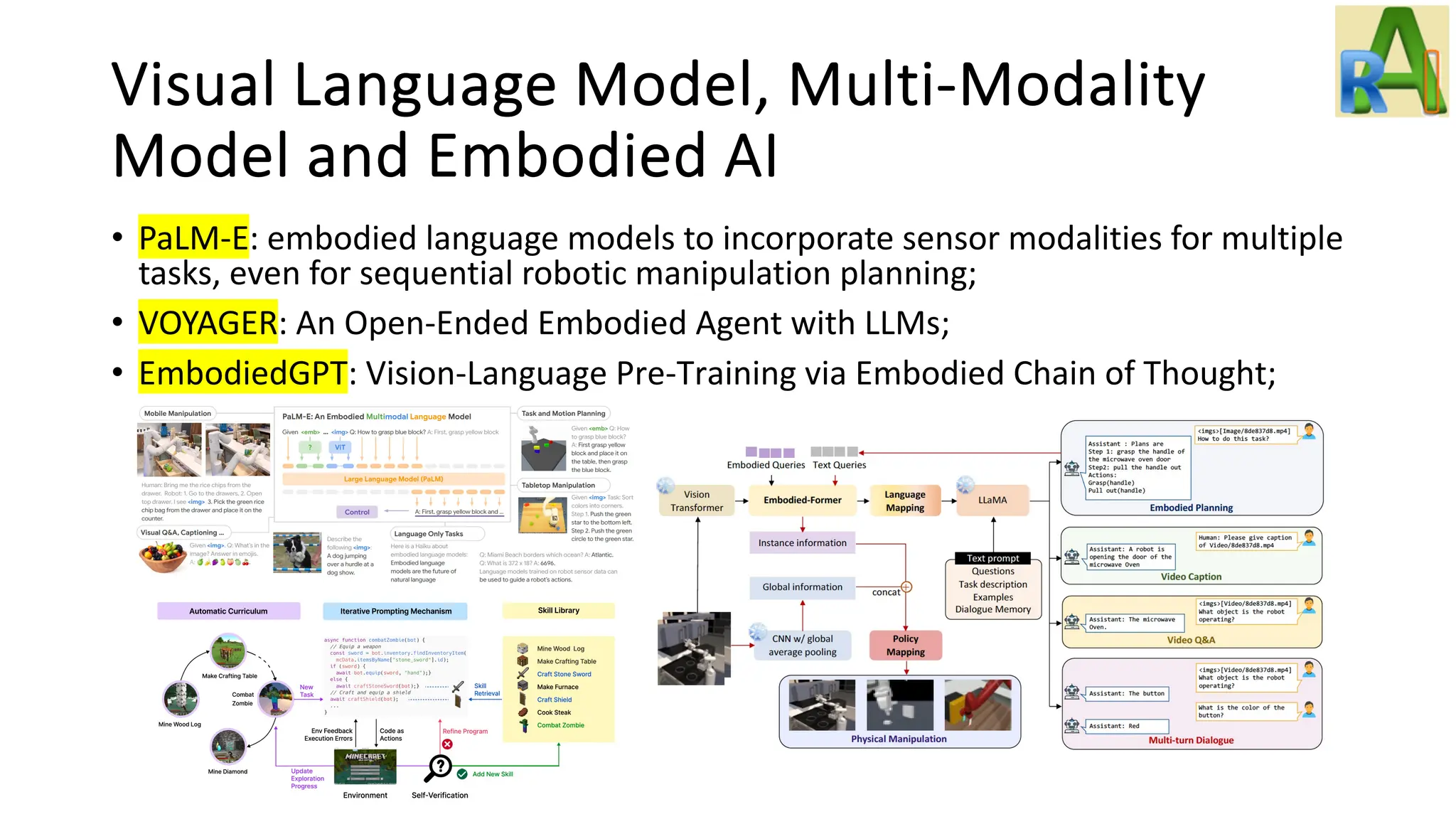
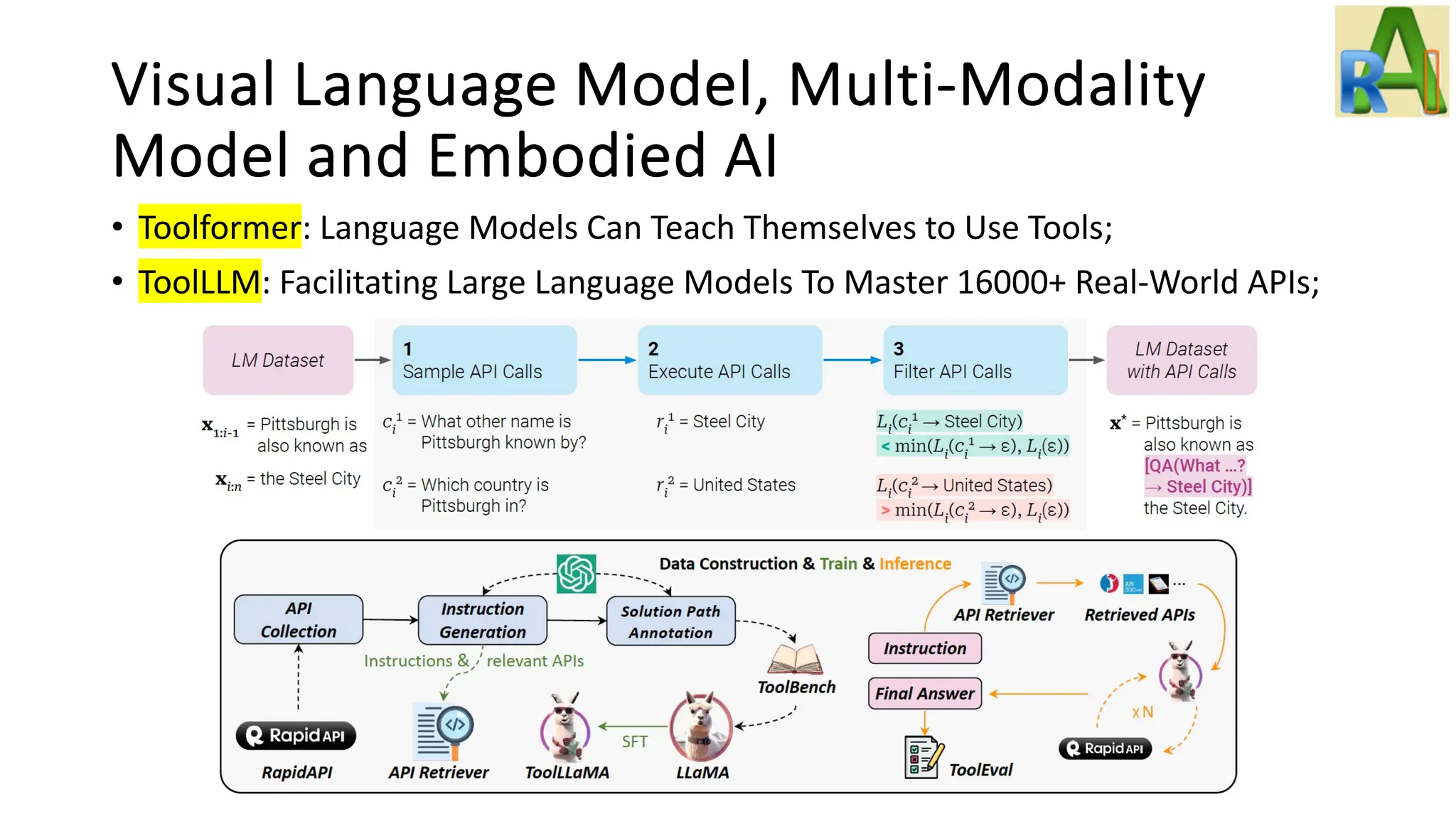
Explores advancements in visual language models and embodied AI, including ViTs, CLIP, multi-modal models, and agents capable of learning through environment interactions.
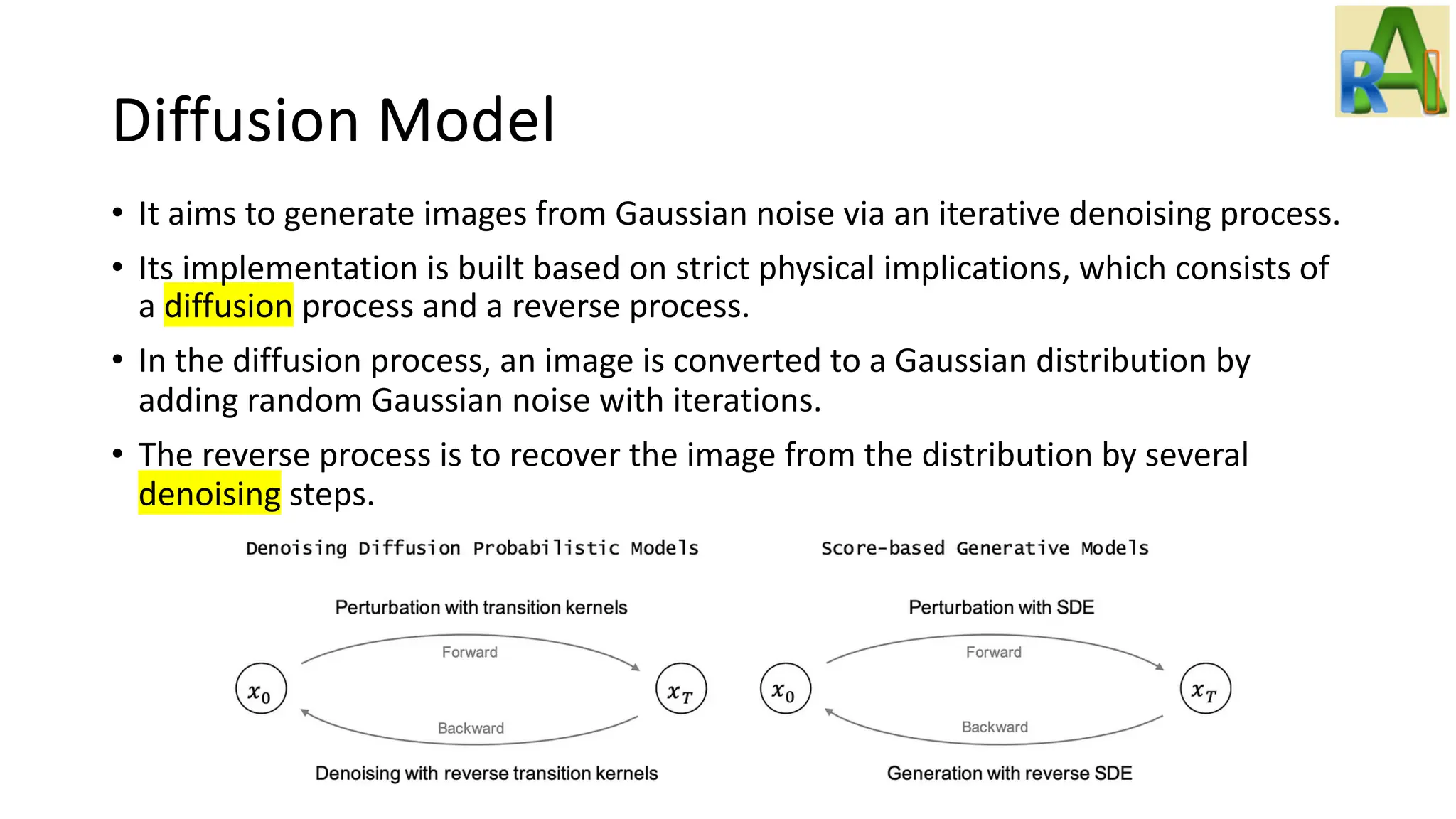
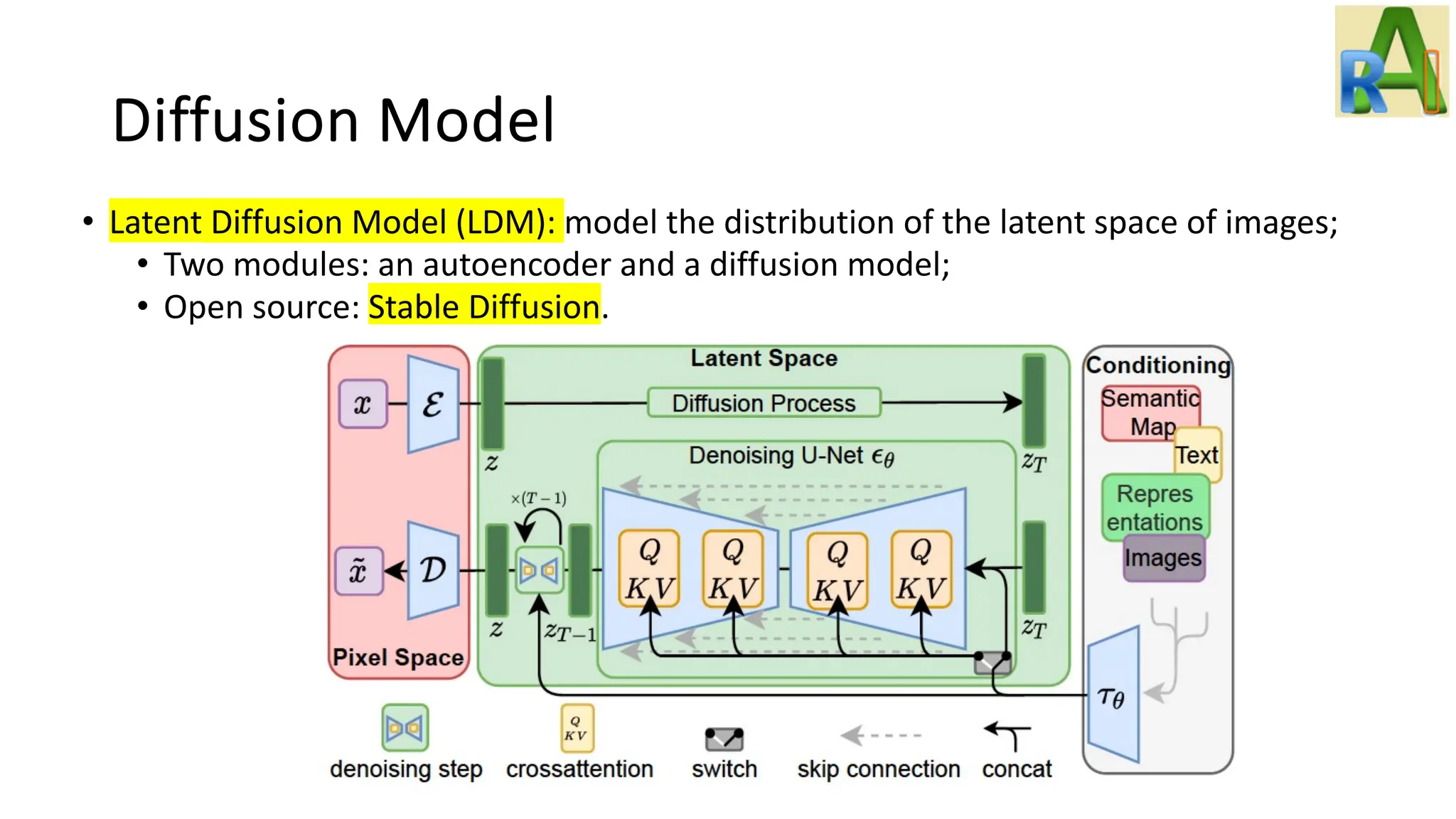
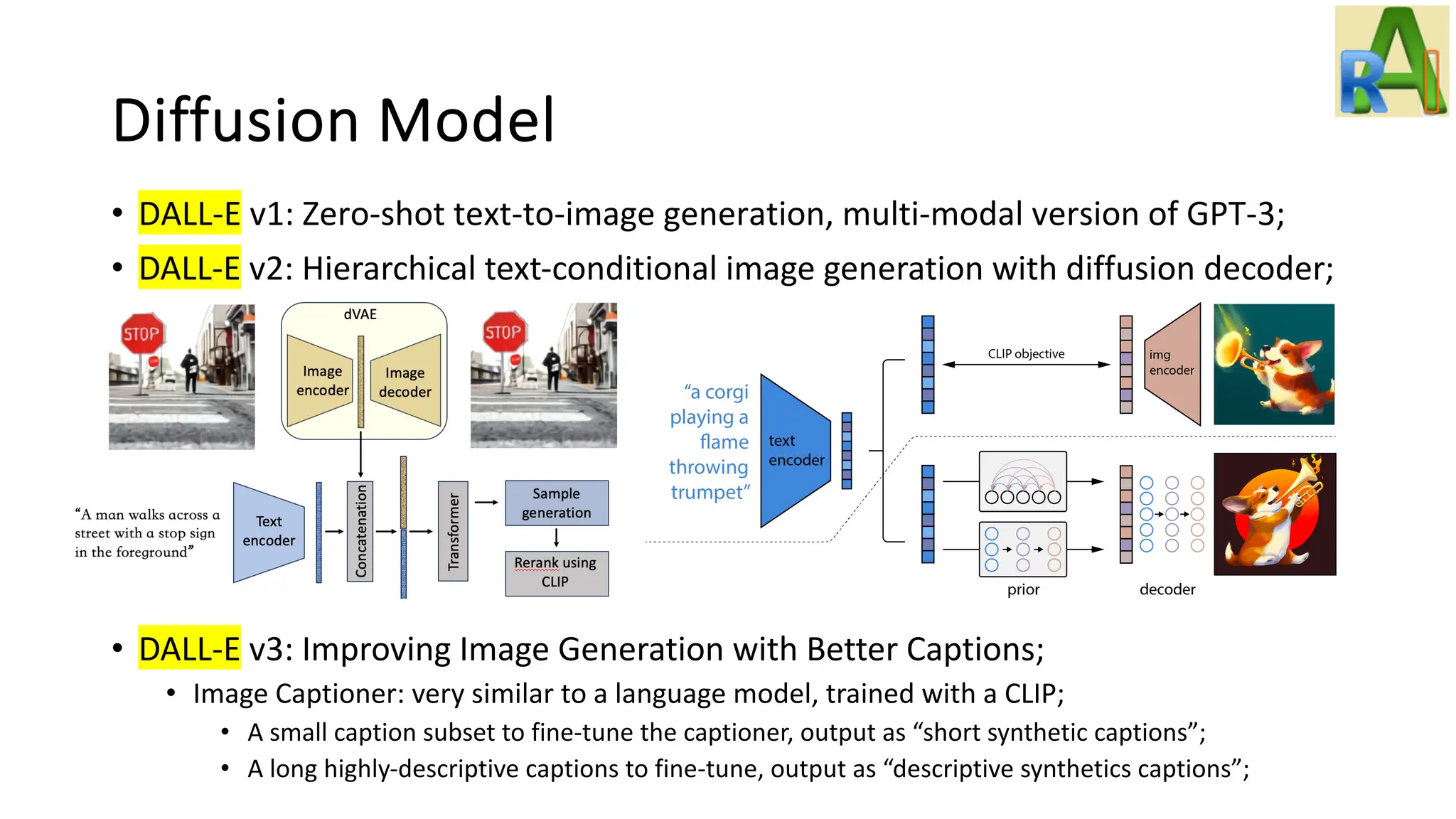
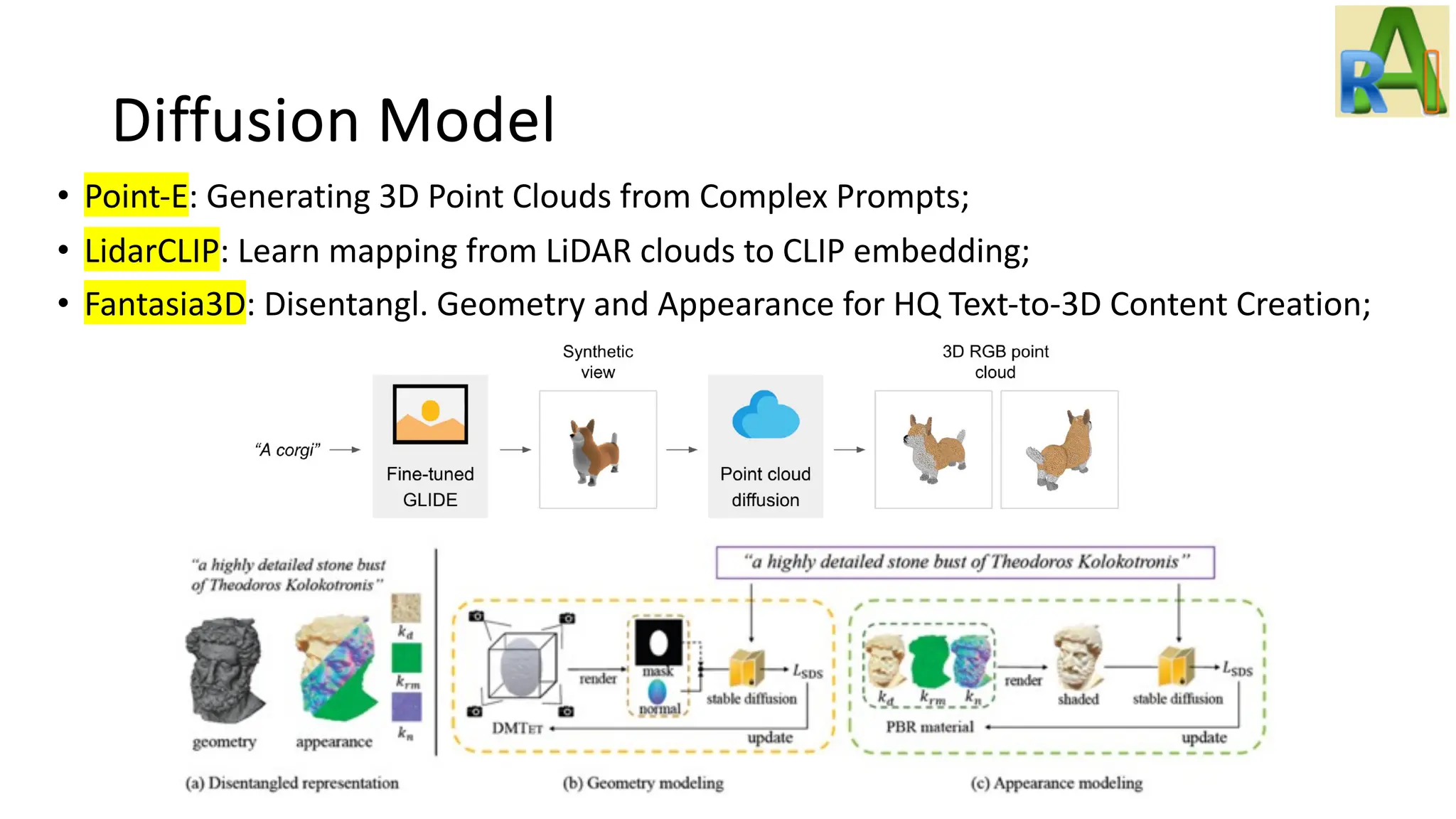
Explains the diffusion model and its applications in generating images from Gaussian noise, including details on Latent Diffusion Models and notable projects like DALL-E.
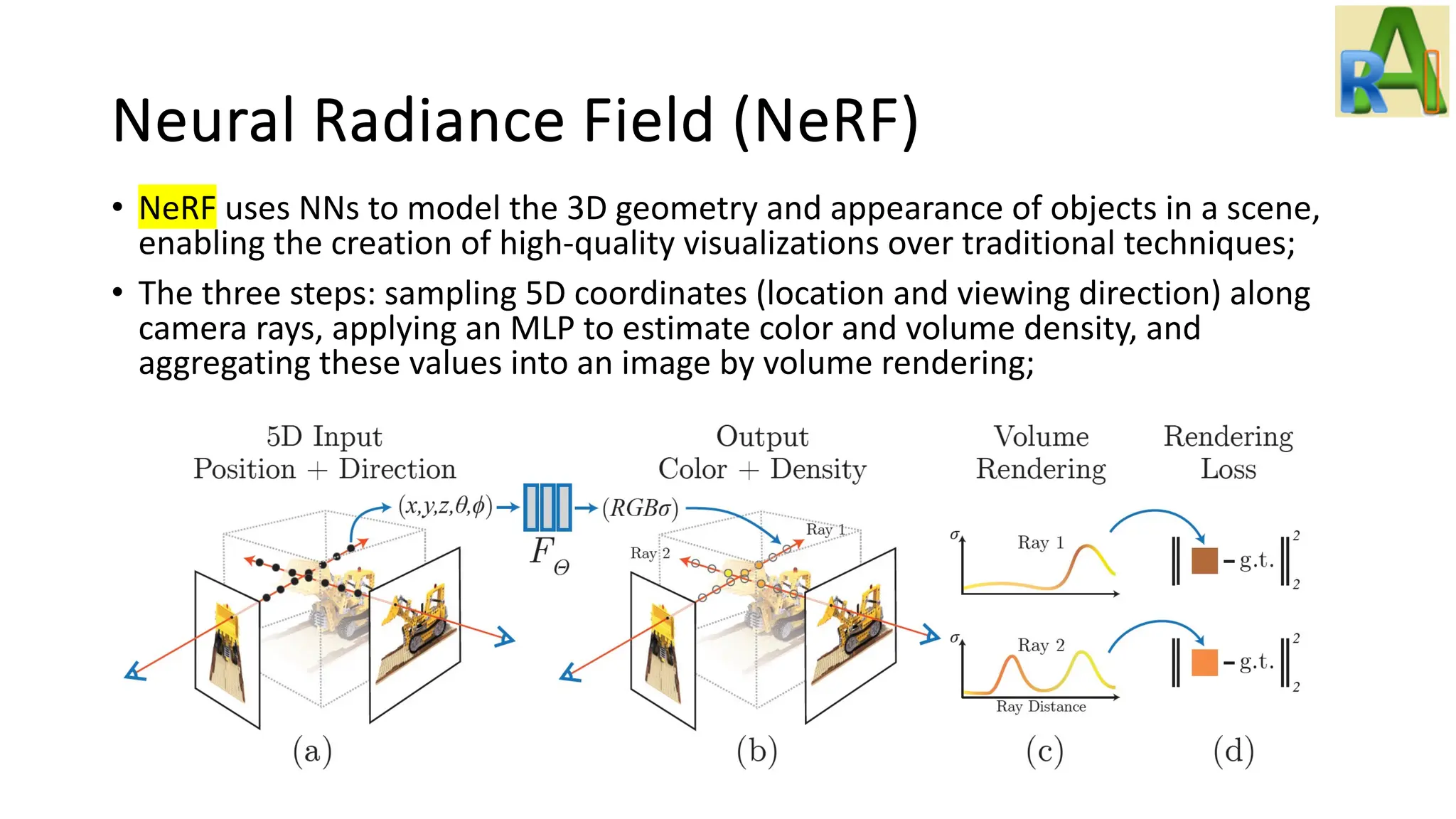
Describes NeRF and its methods for 3D object and scene generation, highlighting generalizations and accelerations in the field.
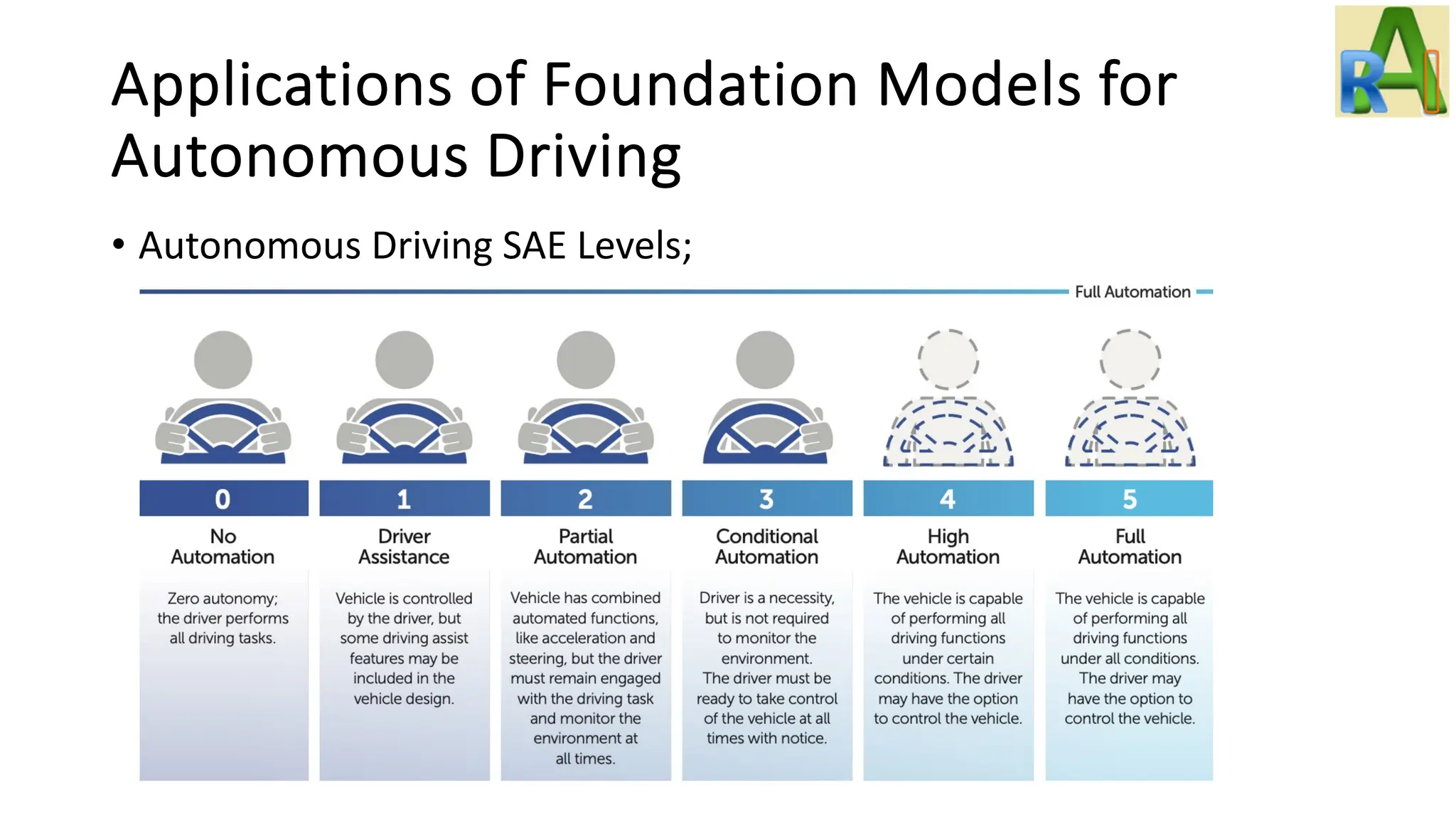
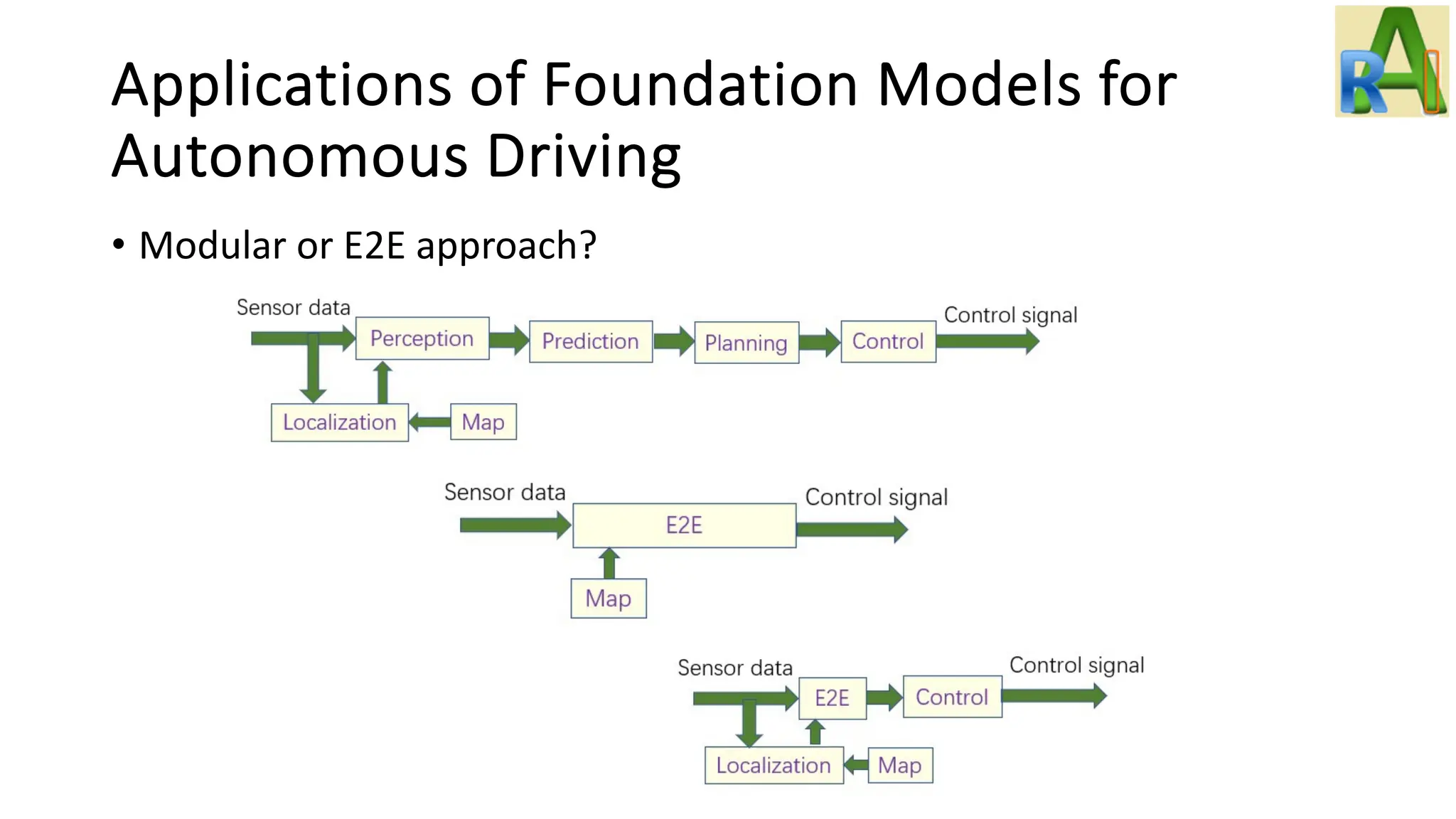
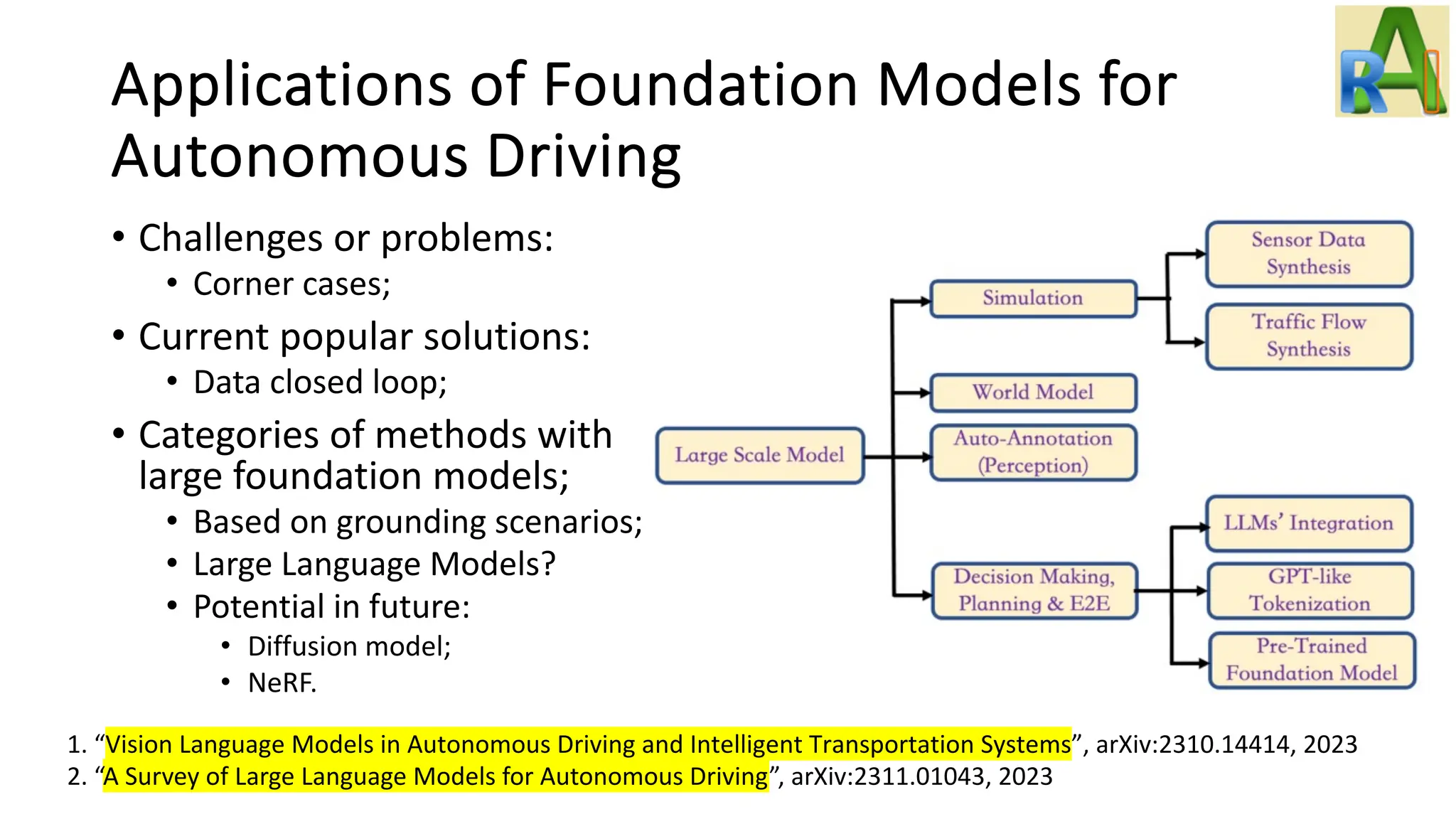
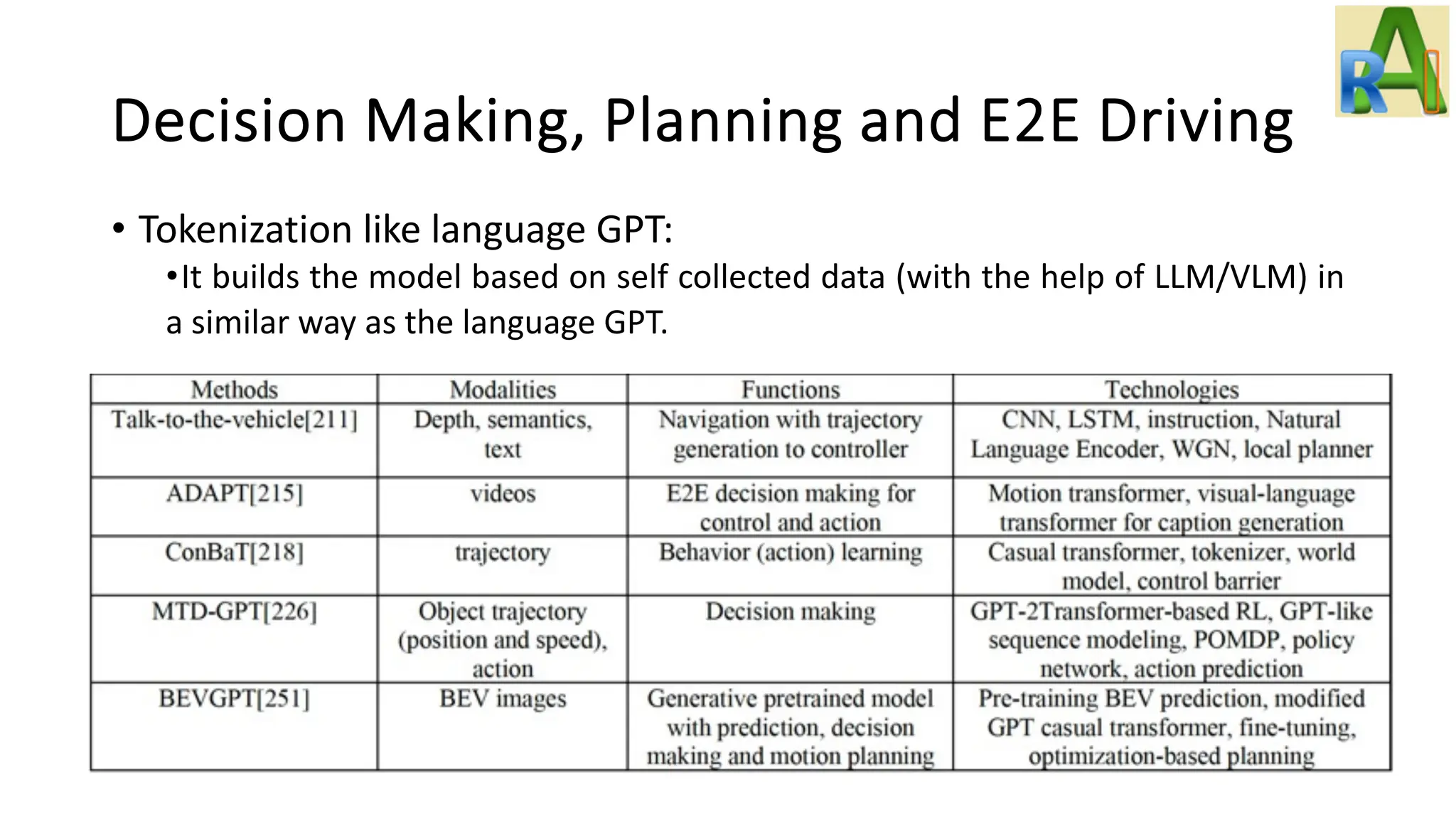
Analyzes the applications of foundation models in autonomous driving, discussing challenges, solutions with LLMs, and the potential of using diffusion models and NeRF.
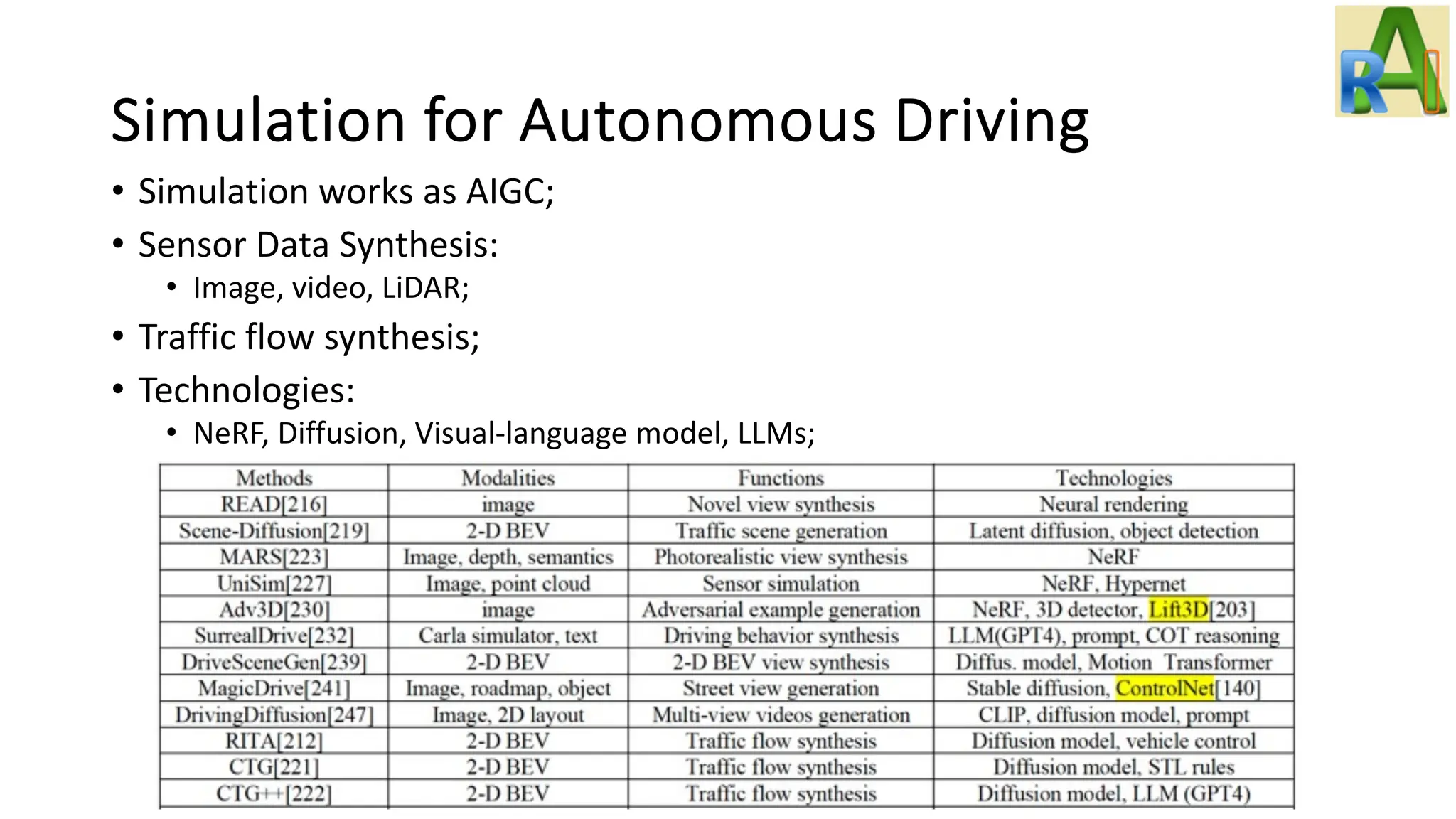
Highlights the importance of simulation using generative models for autonomous driving training, including sensor data synthesis and world modeling.
Discusses the significance of automated data labeling for efficiency in autonomous driving and the role of LLMs in open vocabulary annotation.
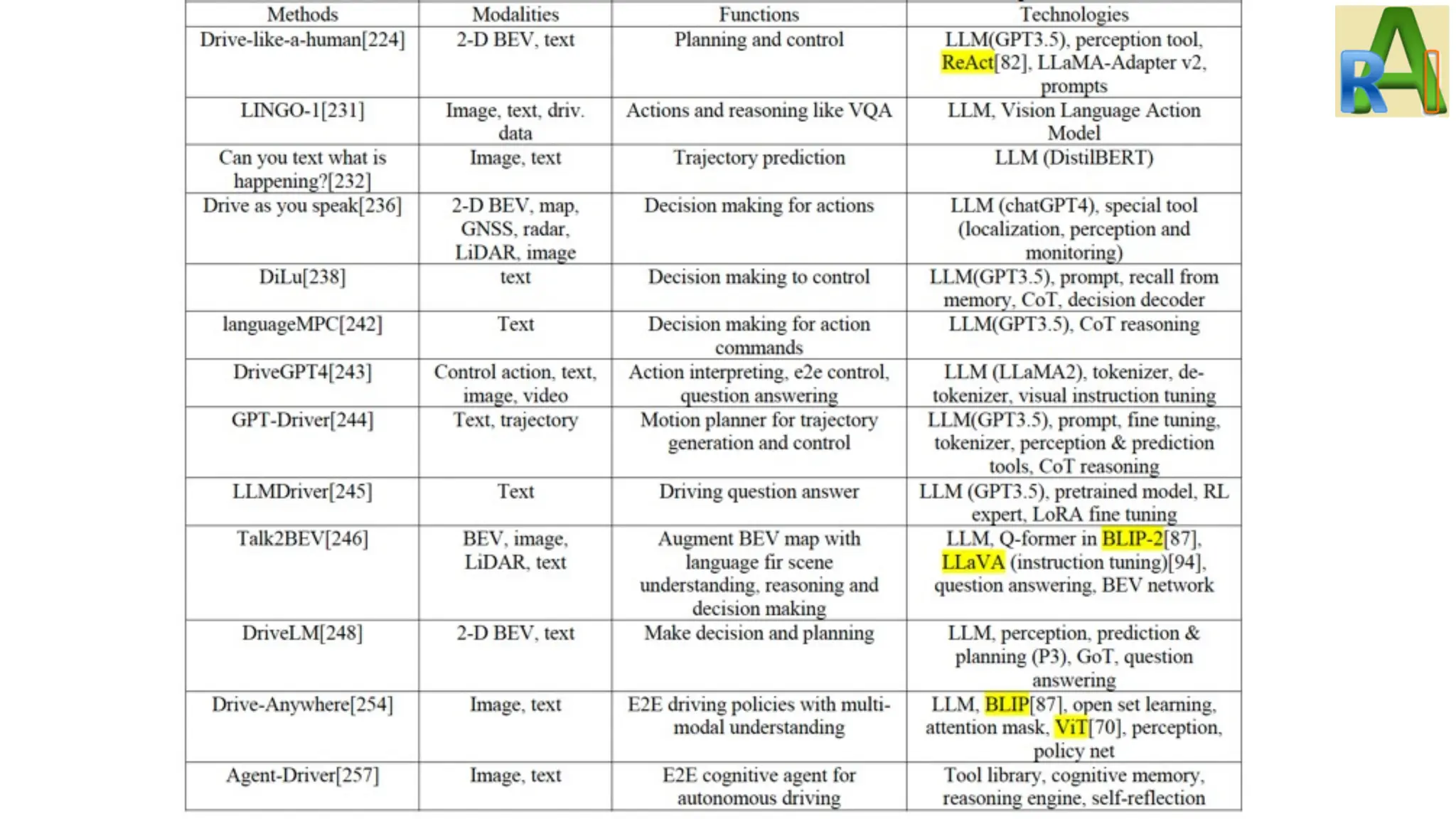
Details how LLMs integrate into decision-making modules for autonomous vehicles, emphasizing sensor data handling and model training.
Summarizes the capabilities and applications of LLMs, visual models, and the integration of AI in autonomous driving, emphasizing the future landscape.























































































