Download as PDF, PPTX












![DEEPLANES: E2E LANE POSITION ESTIMATION USING DEEP
NNS
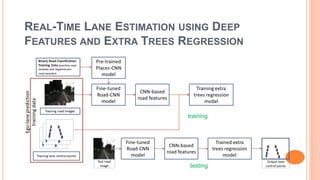
Positioning a vehicle btw lane boundaries is the core of a self-driving car.
Approach to estimate lane positions directly using a deep neural network that
operates on images from laterally-mounted down-facing cameras.
To create a diverse training set, generate semi-artificial images.
Estimate the position of a lane marker with sub-cm accuracy at 100 frames/s on
an embedded automotive platform, requiring no pre- or post-processing.
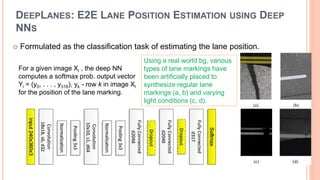
The label ti ∈ [0, . . . , 316] for
image Xi corresponds to the row
with the pixel of the lane marking
that is closest to the bottom
border of the image
two
cameras](https://image.slidesharecdn.com/lanedetection-180928030739/85/camera-based-Lane-detection-by-deep-learning-13-320.jpg)

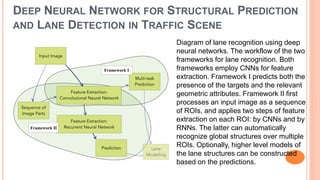
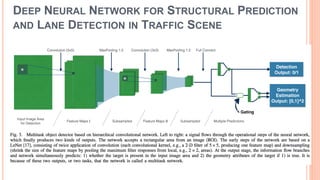
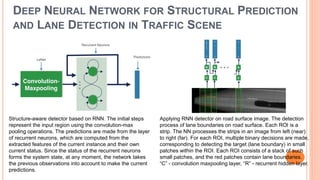
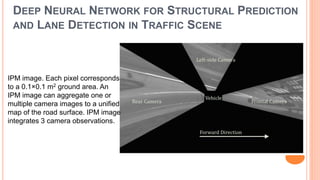





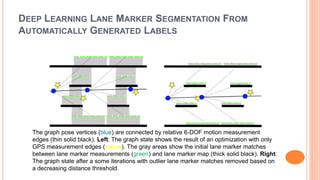




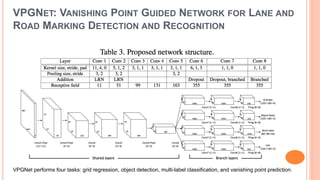

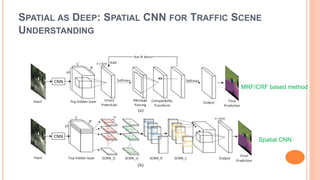
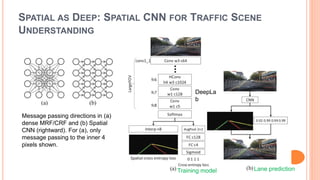
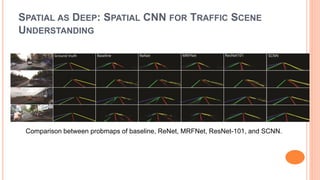

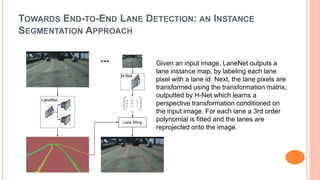





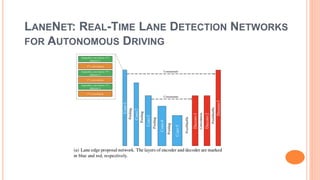
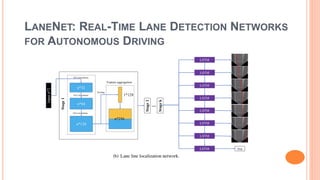





The document presents various deep learning approaches for real-time lane detection and estimation in autonomous vehicles, detailing empirical evaluations and methodologies such as dual-view convolutional networks, end-to-end lane position estimation, and instance segmentation techniques. It highlights frameworks like DeePlanes, VPGNet, and LaneNet, emphasizing their capabilities to handle diverse road conditions and improve detection accuracy without extensive manual labeling. Overall, the research illustrates advancements in utilizing deep neural networks to enhance the safety and reliability of self-driving car navigation.






















































































