Download as PDF, PPTX





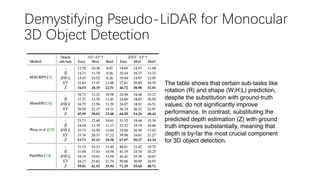
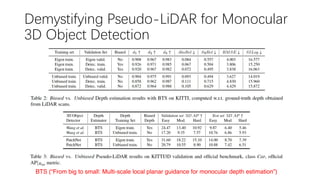

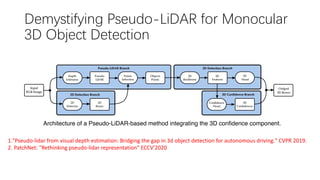
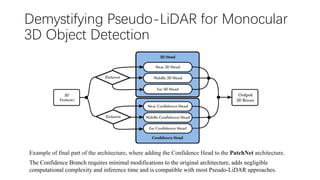



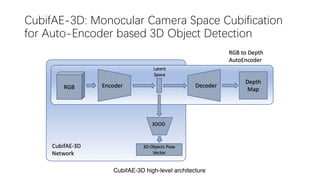




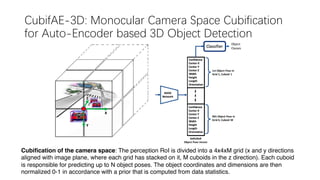





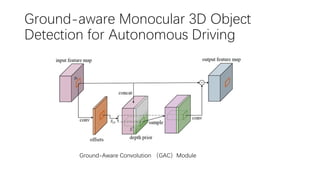
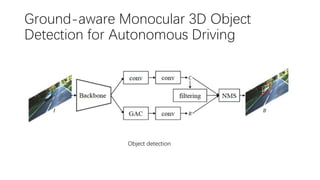
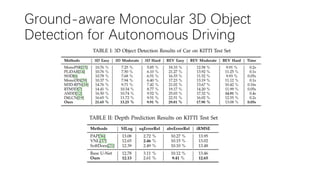



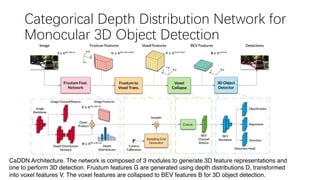

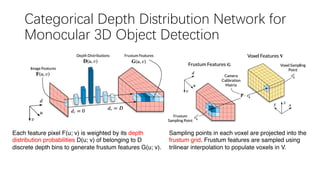


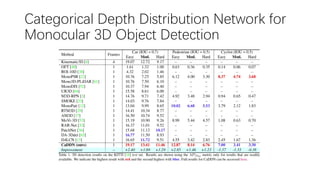
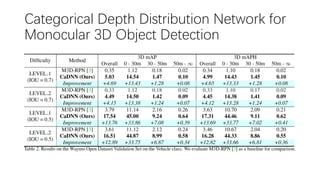
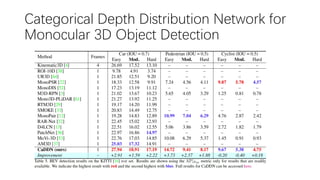



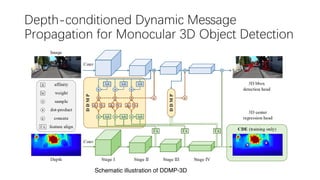
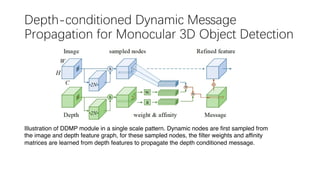

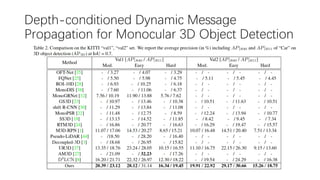






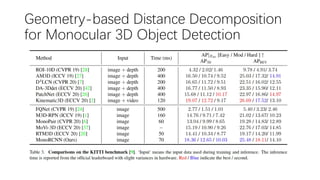



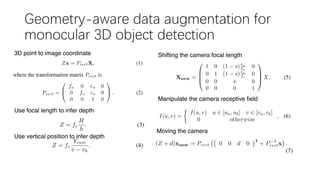
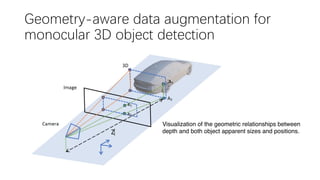

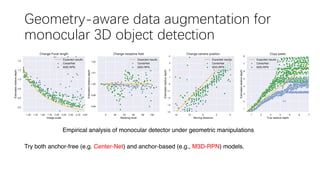

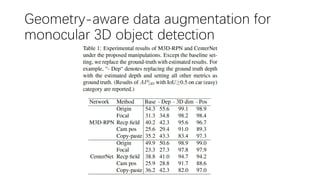
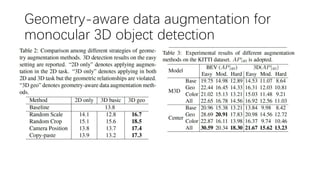
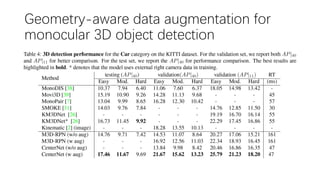

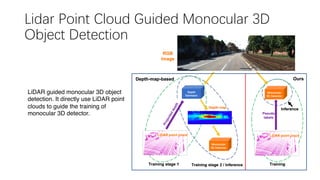


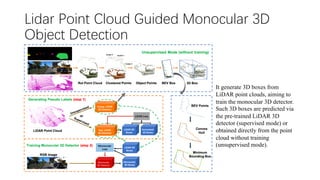



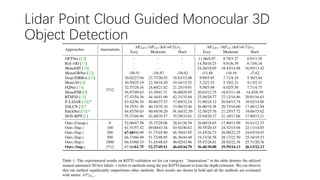
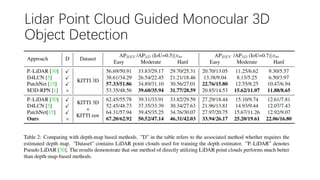



This document summarizes several methods for monocular 3D object detection from a single 2D image for autonomous driving applications. It outlines methods that use pseudo-LiDAR representations, monocular camera space cubification with an auto-encoder, utilizing ground plane priors, predicting categorical depth distributions, dynamic message propagation conditioned on depth, and utilizing geometric constraints. The methods aim to overcome challenges of monocular 3D detection by leveraging techniques such as depth estimation, 3D feature representation learning, and integrating contextual and depth cues.









































![[CVPR 2018] Utilizing unlabeled or noisy labeled data (classification, detect...](https://cdn.slidesharecdn.com/ss_thumbnails/cvpr18detectionclassification-180817015950-thumbnail.jpg?width=640&height=640&fit=bounds)













































