Download as PDF, PPTX



















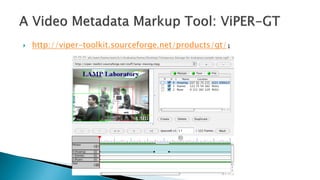




















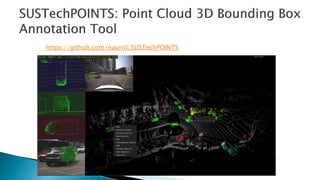









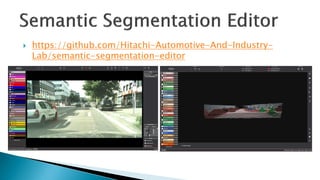





The document lists over 30 tools for annotating images, videos, and point cloud data. Many of the tools are open source and used for tasks like object detection, segmentation, and labeling. The tools cover a wide range of domains from natural images to LiDAR point clouds and include both online and desktop-based annotation solutions.



































![[NS][Lab_Seminar_240611]Graph R-CNN.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240611graphr-cnn-240704112605-f42276be-thumbnail.jpg?width=640&height=640&fit=bounds)







![[NS][Lab_Seminar_241118]Relation Matters: Foreground-aware Graph-based Relati...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241118fgrr-241118111529-1ff1aba4-thumbnail.jpg?width=640&height=640&fit=bounds)











































