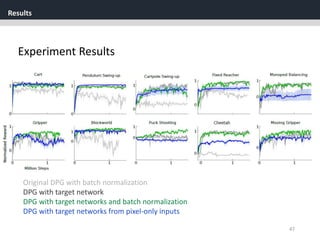
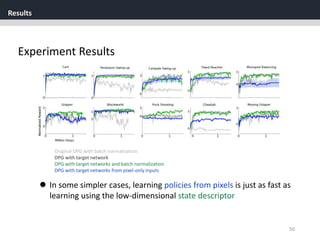
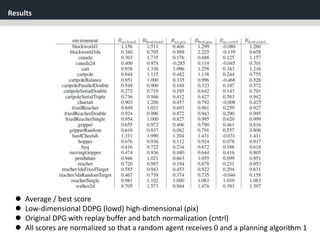
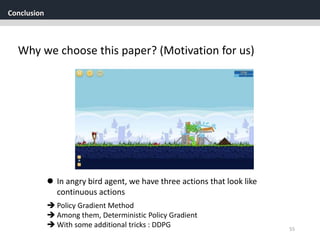
The document discusses the application of deep reinforcement learning with a focus on continuous control, specifically utilizing the Deep Deterministic Policy Gradient (DDPG) method. It addresses challenges in applying DQN to continuous action spaces and introduces techniques such as batch normalization, replay buffers, and exploration policies to improve learning stability and efficiency. Experimental results demonstrate the effectiveness of DDPG in high-dimensional state spaces, highlighting its performance improvements over traditional methods.












![Algorithm Details
23
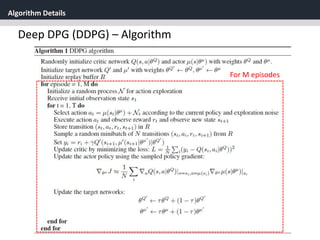
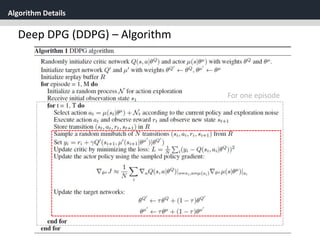
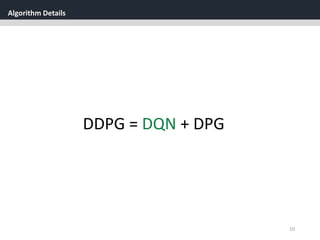
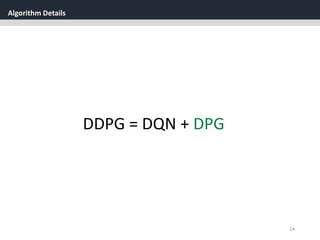
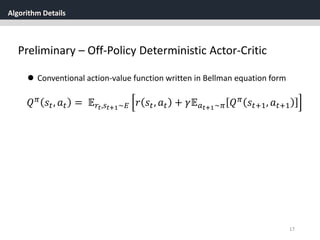
Deep DPG (DDPG)
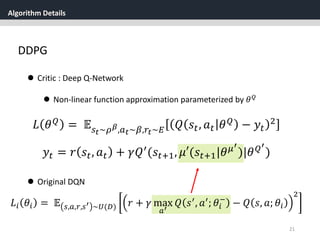
[1] Replay Buffer
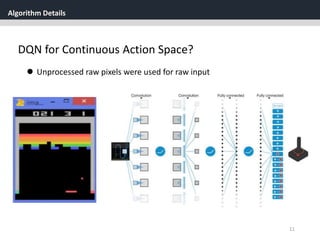
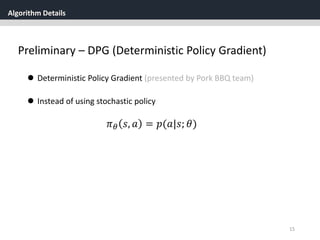
One challenge when using neural networks for reinforcement
learning is that most optimization algorithms assume that the
samples are independently and identically distributed.
When the samples are generated from exploring sequentially in
an environment this assumption no longer holds.](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-23-320.jpg)
![Algorithm Details
24
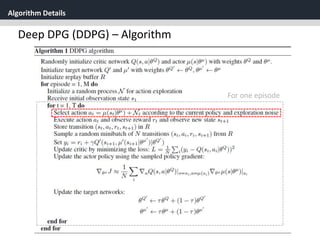
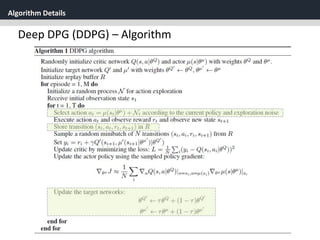
Deep DPG (DDPG)
[1] Replay Buffer
One challenge when using neural networks for reinforcement
learning is that most optimization algorithms assume that the
samples are independently and identically distributed.
When the samples are generated from exploring sequentially in
an environment this assumption no longer holds.
Use Replay Buffer
- Replay buffer is a finite sized cache ℛ
- (𝑠𝑡, 𝑎 𝑡, 𝑟𝑡, 𝑠𝑡+1) are stored in the replay buffer
- At each time step the actor and critic are updated by sampling
a mini batch uniformly from the buffer.](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-24-320.jpg)
![Algorithm Details
25
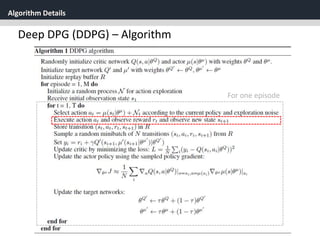
Deep DPG (DDPG)
[2] soft target updates
Directly implementing Q learning with neural networks proved to
be unstable in many environments.
Since the network being updated is also used in
calculating the target value, the Q update is prone to divergence.
𝑄(𝑠, 𝑎|𝜃 𝑄
)](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-25-320.jpg)
![Algorithm Details
26
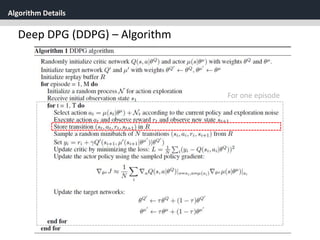
Deep DPG (DDPG)
[2] soft target updates
Directly implementing Q learning with neural networks proved to
be unstable in many environments.
Since the network being updated is also used in
calculating the target value, the Q update is prone to divergence.
𝑄(𝑠, 𝑎|𝜃 𝑄
)
Soft Target updates,
rather than directly copying the weights.](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-26-320.jpg)
![Algorithm Details
27
Deep DPG (DDPG)
[2] soft target updates
Creating a copy of the actor and critic networks respectively that
are used for calculating the target networks
𝑄′ 𝑠, 𝑎 𝜃 𝑄′
, 𝜇′(𝑠|𝜃 𝜇′
)](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-27-320.jpg)
![Algorithm Details
28
Deep DPG (DDPG)
[2] soft target updates
Creating a copy of the actor and critic networks respectively that
are used for calculating the target networks
𝑄′ 𝑠, 𝑎 𝜃 𝑄′
, 𝜇′(𝑠|𝜃 𝜇′
)
The weights of these target networks are then updated by having
them slowly track the learned networks:
𝜃′ ← 𝜏𝜃 + 1 − 𝜏 𝜃′ , 𝑤ℎ𝑒𝑟𝑒 𝜏 ≪ 1](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-28-320.jpg)
![Algorithm Details
29
Deep DPG (DDPG)
[2] soft target updates
Creating a copy of the actor and critic networks respectively that
are used for calculating the target networks
𝑄′ 𝑠, 𝑎 𝜃 𝑄′
, 𝜇′(𝑠|𝜃 𝜇′
)
The weights of these target networks are then updated by having
them slowly track the learned networks:
𝜃′ ← 𝜏𝜃 + 1 − 𝜏 𝜃′ , 𝑤ℎ𝑒𝑟𝑒 𝜏 ≪ 1
This means that the target values are constrained to change slowly, greatly
improving the stability of learning](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-29-320.jpg)
![Algorithm Details
30
Deep DPG (DDPG)
[3] batch normalization
When learning from low dimensional feature vector observations,
the different components of the observation may have different
physical units (e.g., positions vs velocities) and the range may vary
across environments](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-30-320.jpg)
![Algorithm Details
31
Deep DPG (DDPG)
[3] batch normalization
When learning from low dimensional feature vector observations,
the different components of the observation may have different
physical units (e.g., positions vs velocities) and the range may vary
across environments
Using batch normalization](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-31-320.jpg)
![Algorithm Details
32
Deep DPG (DDPG)
[3] batch normalization
When learning from low dimensional feature vector observations,
the different components of the observation may have different
physical units (e.g., positions vs velocities) and the range may vary
across environments
Batch normalization technique normalizes each dimension across
the samples in a mini batch to have unit mean and variance.
Using batch normalization
DDPG uses batch normalization on the state input and all layers of
the 𝜇 network and all layers of the Q network prior to the action
input](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-32-320.jpg)
![Algorithm Details
33
Deep DPG (DDPG)
[4] exploration in continuous action space
A major challenge of learning in continuous action spaces is
exploration](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-33-320.jpg)
![Algorithm Details
34
Deep DPG (DDPG)
[4] exploration in continuous action space
A major challenge of learning in continuous action spaces is
exploration
DDPG constructed an exploration policy 𝜇′ by adding noise
sampled from a noise process 𝒩 to the actor policy
𝜇′ 𝑠𝑡 = 𝜇 𝑠𝑡 𝜃𝑡
𝜇
+ 𝒩](https://image.slidesharecdn.com/continuouscontrolwithdeepreinforcementlearningstevejobsae-190930131810/85/DDPG-algortihm-for-angry-birds-34-320.jpg)