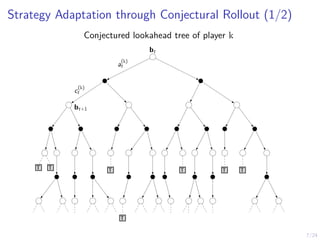
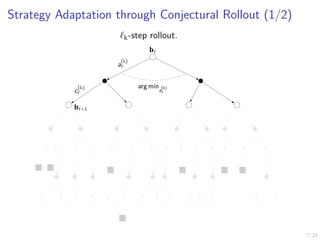
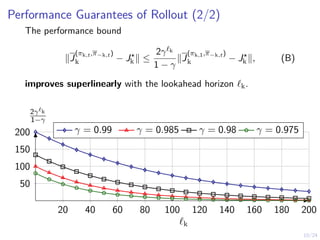
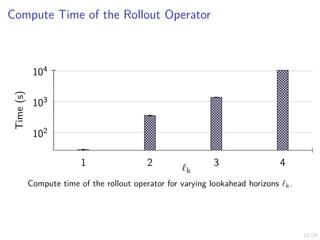
Download as PDF, PPTX








![13/24
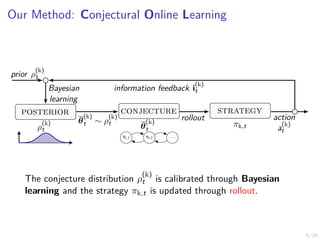
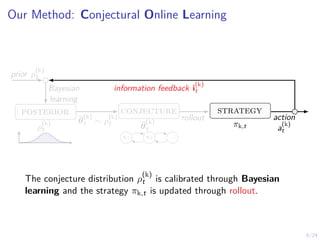
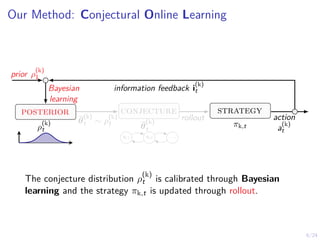
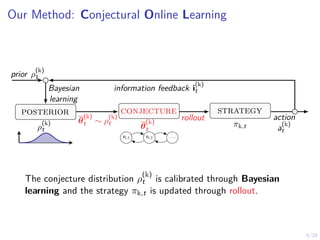
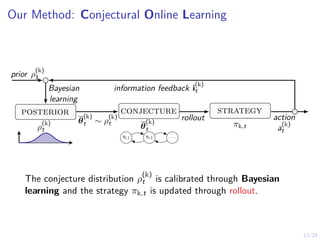
Bayesian Learning to Calibrate Conjectures
ρ
(k)
t is calibrated through Bayesian learning as
ρ
(k)
t (θ
(k)
t ) ,
P[i
(k)
t | θ
(k)
t , bt−1]ρ(k)(θ
(k)
t−1)
R
Θk
P[i
(k)
t | θ
(k)
t , bt−1]ρ
(k)
t−1(dθ
(k)
t )
,
where i
(k)
t is the information feedback at time t.
I We want to characterize limt→∞ ρ
(k)
t .
I Does the conjecture converge?
I Is the conjecture consistent asymptotically?](https://image.slidesharecdn.com/pres-240404160748-80d5a019/85/Automated-Security-Response-through-Online-Learning-with-Adaptive-Con-jectures-25-320.jpg)
![14/24
Asymptotic Analysis of Bayesian Learning
I Let ν ∈ ∆(B) be an occupancy measure over the belief space.
I We say that a conjecture θ
(k)
is consistent if it minimizes
the weighted KL-divergence:
K(θ
(k)
, ν) , Eb∼νEI(k)
"
ln
P[I(k) | θ, b]
P[I(k) | θ
(k)
, b]
!
| θ, b
#
.
I Let Θ?
k denote the set of consistent conjectures.
Remark
Due to misspecification, θ
(k)
t ∈ Θ?
k does not imply that θ
(k)
t
equals the true parameter vector θt.](https://image.slidesharecdn.com/pres-240404160748-80d5a019/85/Automated-Security-Response-through-Online-Learning-with-Adaptive-Con-jectures-26-320.jpg)
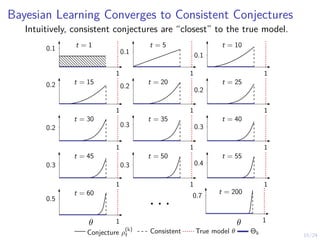

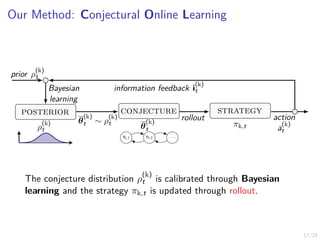
![21/24
Evaluation of col (1/3)
10 20 30 40 50 60 70
20
40
60
80
100
θt
t
10 20 30 40 50 60 70
5
10
E
θ
(D)
∼ρ
(D)
t
[K(θ
(D)
, νt)]
t
Remark
The conjectures do not converge if θt keep changing.](https://image.slidesharecdn.com/pres-240404160748-80d5a019/85/Automated-Security-Response-through-Online-Learning-with-Adaptive-Con-jectures-33-320.jpg)
![22/24
Evaluation of col (2/3)
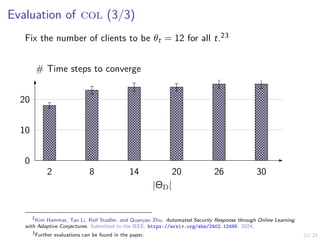
Fix the number of clients to be θt = 12 for all t.
2 4 6 8 10 12 14 16 18 20
0.5
1
ρ
(D)
t (θt = 12)
t
4 6 8 10 12 14 16 18 20
−0.05
0.05
E
θ
(D)
∼ρ
(D)
t
[K(θ
(D)
, νt)]
t](https://image.slidesharecdn.com/pres-240404160748-80d5a019/85/Automated-Security-Response-through-Online-Learning-with-Adaptive-Con-jectures-34-320.jpg)
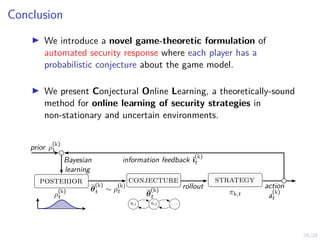

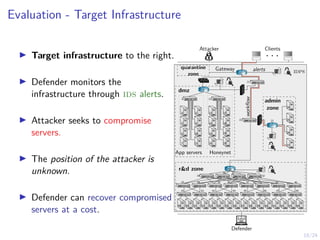
The document describes an approach called conjectural online learning for automated security response in complex IT systems. It uses Bayesian learning to continuously update conjectures about the true but unknown system model, and rollout-based strategy adaptation to update the defender's strategy based on the current conjecture. The conjectures are proven to converge asymptotically to consistent conjectures that minimize divergence from the true model. Evaluation on a target infrastructure models the evolving number of clients and correlations between observations and the true unknown model parameter.

![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)

































































