Download as PDF, PPTX


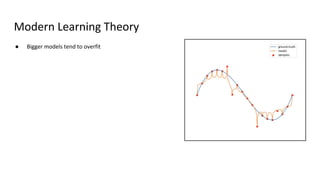
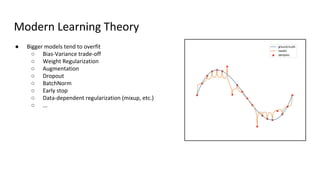




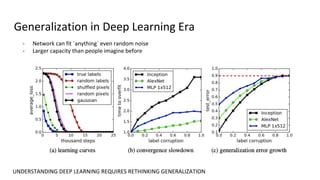

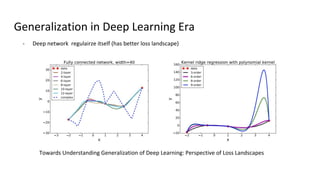
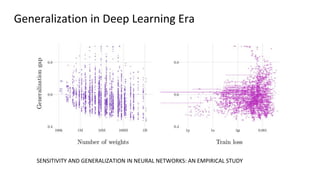
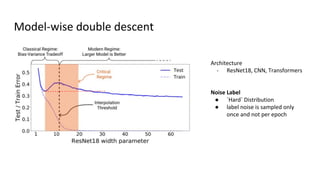
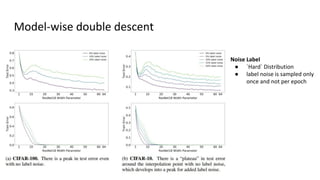
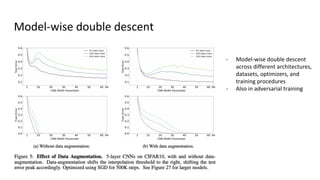
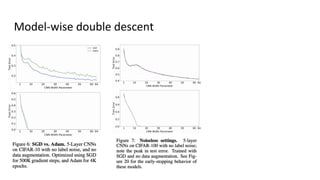
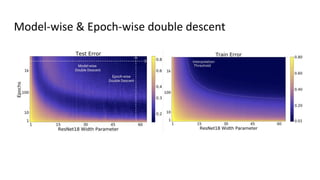
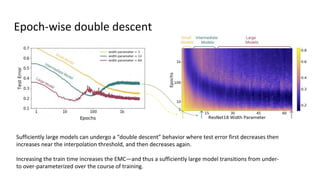

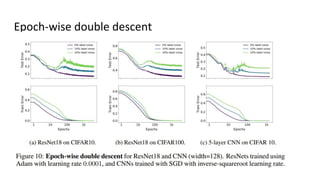
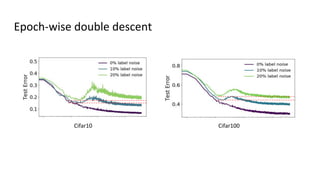
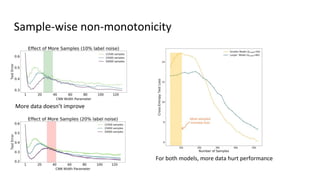
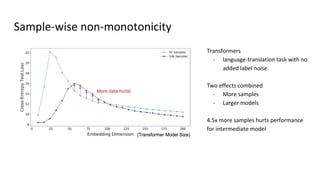
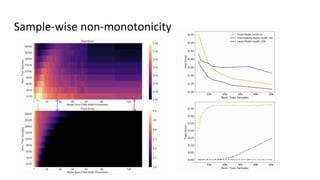


The document discusses deep double descent in modern learning theory, highlighting that larger models can overfit and may not always perform better. It describes instances where increasing training time or data can lead to worse performance, emphasizing the complexities of generalization in deep learning. Key concepts include model-wise and epoch-wise double descent, and the challenges of connecting data complexity with model complexity.























































