The document presents a novel approach to off-policy reinforcement learning with the introduction of a new algorithm called Retrace(λ). This algorithm achieves low variance, safety by effectively utilizing samples from any behavior policy, and efficiency by leveraging samples from near on-policy behavior. The proposed method demonstrates a convergence to the optimal action-value function without requiring the typical greedy-in-the-limit with infinite exploration assumption.



![4
• 状態
• 行動
• 状態遷移確率
• 報酬関数
• 方策
• Q 関数
• 遷移演算子
• 行動価値関数
• 学習目的:価値を最大化する方策の獲得
強化学習
エージェント
環境
状態 行動報酬
(P⇡
Q)(x, a) ,
X
x02X
X
a02A
P(x0
|x, a)⇡(a0
|x0
)Q(x0
, a0
)
Q⇡
,
X
t 0
t
(P⇡
)t
r, 2 [0, 1)
x 2 X
a 2 A
P : X ⇥ A ! Pr(X)
r : X ⇥ A ! [ RMAX, RMAX]
⇡ : X ! Pr(A)
Q : X ⇥ A ! R](https://image.slidesharecdn.com/unofficialintroductionofsafeandefficientoffpolicyreinforcementlearning-161114012920/85/safe-and-efficient-off-policy-reinforcement-learning-4-320.jpg)

![6
• 学習したい推定方策 とデータを生成した挙動方策 が
異なる
Off-policy
Convolution Convolution Fully connected Fully connected
No input
Schematic illustration of the convolutional neural network. The
he architecture are explained in the Methods. The input to the neural
onsists of an 843 843 4 image produced by the preprocessing
lowed by three convolutional layers (note: snaking blue line
symbolizes sliding of each filter across input image) and two fully connected
layers with a single output for each valid action. Each hidden layer is followed
by a rectifier nonlinearity (that is, max 0,xð Þ).
RCH LETTER
[Mnih+ 15]
regression [2]. With a function approximator, the sampled
data from the approximated model can be generated by inap-
propriate interpolation or extrapolation that improperly up-
dates the policy parameters. In addition, if we aggressively
derive the analytical gradi-
ent of the approximated
model to update the poli-
cy, the approximated gra-
dient might be far from
the true gradient of the
objective function due to
the model approximation
error. If we consider using
these function approxima-
tion methods for high-di-
mensional systems like
humanoid robots, this
problem becomes more
serious due to the difficul-
ty of approximating high-
dimensional dynamics models with a limited amount of data
sampled from real systems. On the other hand, if the environ-
ment is extremely stochastic, a limited amount of previously
acquired data might not be able to capture the real environ-
ment’s property and could lead to inappropriate policy up-
dates. However, rigid dynamics models, such as a humanoid
robot model, do not usually include large stochasticity. There-
fore, our approach is suitable for a real robot learning for high-
dimensional systems like humanoid robots.
Moreover, applying RL to actu
since it usually requires many learn
cuted in real environments, and t
limited. Previous studies used prio
signed initial trajectories to apply
proved the robot controller’s param
We applied our proposed learn
oid robot [7] (Figure 13) and show
different movement-learning task
edge for the cart-pole swing-up
nominal trajectory for the basketb
The proposed recursive use of
improve policies for real robots
other policy search algorithms, s
gression [11] or information theo
might be interesting to investiga
work as a future study.
Conclusions
In this article, we proposed reusi
es of a humanoid robot to effici
formance. We proposed recurs
PGPE method to improve the p
proach to cart-pole swing-up
tasks. In the former, we introd
task environment composed of a
tually simulated cart-pole dyna
environment, we can potentiall
different task environments. N
movements of the humanoid ro
the cart-pole swing-up. Furthe
posed method, the challenging
was successfully accomplished.
Future work will develop a m
learning [28] approach to efficien
riences acquired in different target
Acknowledgment
This work was supported by
23120004, MIC-SCOPE, ``Devel
gies for Clinical Application’’ ca
AMED, and NEDO. Part of this s
KAKENHI Grant 26730141. This
NSFC 61502339.
References
[1] A. G. Kupcsik, M. P. Deisenroth, J. Pe
cient contextual policy search for robot m
Conf. Artificial Intelligence, 2013.
[2] C. E. Rasmussen and C. K. I. William
Learning. Cambridge, MA: MIT Press, 2006
[3] C. G. Atkeson and S. Schaal, “Robot lea
14th Int. Conf. Machine Learning, 1997, pp. 12
[4] C. G. Atkeson and J. Morimoto, “Non
cies and value functions: A trajectory-base
mation Processing Systems, 2002, pp. 1643–
Efficiently reusing previous
experiences is crucial to
improve its behavioral
policies without actually
interacting with real
environments.
Figure 13. The humanoid robot CB-i [7]. (Photo courtesy of ATR.)
[Sugimoto+ 16]
O↵-Policy Actor-Critic
nd the value function
sponding TD-solution
imilar outline to the
policy policy gradient
009) and for nonlinear
analyze the dynamics
= (wt
T
vt
T
), based on
volves satisfying seven
, p. 64) to ensure con-
able equilibrium.
rmance of O↵-PAC to
s with linear memory
1) Q( ) (called Q-
edy-GQ (GQ( ) with
Behavior Greedy-GQ
Softmax-GQ O↵-PAC
Figure 1. Example of one trajectory for each algorithm
in the continuous 2D grid world environment after 5,000
milar outline to the
olicy policy gradient
09) and for nonlinear
nalyze the dynamics
= (wt
T
vt
T
), based on
olves satisfying seven
p. 64) to ensure con-
able equilibrium.
mance of O↵-PAC to
with linear memory
1) Q( ) (called Q-
dy-GQ (GQ( ) with
Softmax-GQ (GQ( )
he policy in O↵-PAC
d in section 2.3.
ntain car, a pendulum
world. These prob-
space and a continu-
Softmax-GQ O↵-PAC
Figure 1. Example of one trajectory for each algorithm
in the continuous 2D grid world environment after 5,000
learning episodes from the behavior policy. O↵-PAC is the
only algorithm that learned to reach the goal reliably.
The last problem is a continuous grid-world. The
state is a 2-dimensional position in [0, 1]2
. The ac-
tions are the pairs {(0.0, 0.0), ( .05, 0.0), (.05, 0.0),
(0.0, .05), (0.0, .05)}, representing moves in both di-
[Degris+ 12]
⇡ µ
E
µ
[·] 6= E
⇡
[·]](https://image.slidesharecdn.com/unofficialintroductionofsafeandefficientoffpolicyreinforcementlearning-161114012920/85/safe-and-efficient-off-policy-reinforcement-learning-6-320.jpg)
![7
• Forward view
– 真の収益を target に学習したい
– できない
• Backward view
– 過去に経験した状態・行動対を履歴として保持して
現在の報酬を分配
• backward view = forward view [Sutton & Barto 98]
Return Based Reinforcement Learning
tX
s=0
( )t s
I{xj, aj = x, a}
Q(xt, at) (1 ↵)Q(xt, at) + ↵
X
s t
s t
(P⇡
)s t
r
Eligibility Trace
X
t 0
t
(P⇡
)t
r
rt+1 rt+2 rt+n
(xt, at, rt)
t
n 3
2
(xt n, at n) (xt 1, at 1)](https://image.slidesharecdn.com/unofficialintroductionofsafeandefficientoffpolicyreinforcementlearning-161114012920/85/safe-and-efficient-off-policy-reinforcement-learning-7-320.jpg)
![8
• λ 収益 : n ステップ収益の指数平均
• が TD(0) と Monte Carlo 法をつなぐ
λ 収益と TD(λ)
T ⇡
=0 = T ⇡
Q
T ⇡
=1 = Q⇡
T ⇡
, (1 )
X
n 0
n
[(T ⇡
)n
Q] = Q + (I P⇡
) 1
(T ⇡
Q Q)
2 [0, 1]
X
t 0
t
(P⇡
)t
r
rt+1 rt+2 rt+n
(xt, at, rt)
t
n 3
2
(xt n, at n) (xt 1, at 1)](https://image.slidesharecdn.com/unofficialintroductionofsafeandefficientoffpolicyreinforcementlearning-161114012920/85/safe-and-efficient-off-policy-reinforcement-learning-8-320.jpg)


![11
• Importance Sampling(IS)
– 単純な重点重み
– 報酬の補正はしない
✘ の分散が大きい
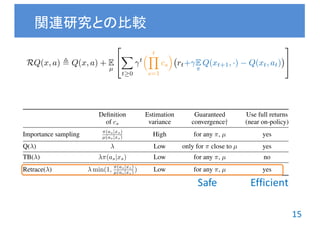
関連研究の整理 1
[Precup+ 00; 01; Geist & Scherrer 14]
cs =
⇡(as|xs)
µ(as|xs)
RQ(x, a) , Q(x, a) + E
µ
2
4
X
t 0
t
⇣ tY
s=1
cs
⌘
rt+ E
⇡
Q(xt+1, ·) Q(xt, at)
3
5
RIS
Q(x, a) , Q(x, a) + E
µ
2
4
X
t 0
t
⇣ tY
s=1
⇡(as|xs)
µ(as|xs)
⌘
rt
3
5
X
t 0
t
⇣ tY
s=1
⇡(as|xs)
µ(as|xs)
⌘
⇡ µ
a](https://image.slidesharecdn.com/unofficialintroductionofsafeandefficientoffpolicyreinforcementlearning-161114012920/85/safe-and-efficient-off-policy-reinforcement-learning-11-320.jpg)
![12
• Q(λ)
– 古典的な eligibility trace
– 推定方策で即時報酬を補正
✘ 軌跡を重み付けしないため
と が大きく異なると収束が保証されない
関連研究の整理 2
[Harutyunyan+ 16]
cs =
RQ(x, a) , Q(x, a) + E
µ
2
4
X
t 0
t
⇣ tY
s=1
cs
⌘
rt+ E
⇡
Q(xt+1, ·) Q(xt, at)
3
5
R Q(x, a) , Q(x, a) + E
µ
2
4
X
t 0
( )t
h
rt + E
⇡
Q(xt+1, ·) Q(xt, at)
i
3
5
⇡(a|x) µ(a|x)
max
x
k⇡(·|x) µ(·|x)k1
1
unsafe](https://image.slidesharecdn.com/unofficialintroductionofsafeandefficientoffpolicyreinforcementlearning-161114012920/85/safe-and-efficient-off-policy-reinforcement-learning-12-320.jpg)
![13
• Tree Backup (TB)
– 推定方策そのもので軌跡を重み付け
ü 挙動方策が非マルコフでも学習可能
✘ と が近い場合(On-Policy)
トレースの減衰が速く,収益を効率良く近似できない
関連研究の整理 3
cs = ⇡(as|xs)
[Precup+ 00]
RQ(x, a) , Q(x, a) + E
µ
2
4
X
t 0
t
⇣ tY
s=1
cs
⌘
rt+ E
⇡
Q(xt+1, ·) Q(xt, at)
3
5
R Q(x, a) , Q(x, a) + E
µ
2
4
X
t 0
( )t
⇣ tY
s=1
⇡(as|xs)
⌘ h
rt + E
⇡
Q(xt+1, ·) Q(xt, at)
i
3
5
⇡(a|x) µ(a|x)
inefficient](https://image.slidesharecdn.com/unofficialintroductionofsafeandefficientoffpolicyreinforcementlearning-161114012920/85/safe-and-efficient-off-policy-reinforcement-learning-13-320.jpg)




![19
• CNN による Q の近似
• 16スレッド並列の学習
1. θ’ ← θ
2. 各スレッドでθ’から勾配を計算
3. 全ての勾配を利用してθを更新
• Experience Replay
– 一度の更新に使うサンプル数は揃える (64)
– Retrace, TB, Q* では (連続した16の状態遷移 x 4)
実験 :: Atari 2600 + DQN
difficult and engaging for human players. We used the same network
architecture, hyperparameter values (see Extended Data Table 1) and
learningprocedurethroughout—takinghigh-dimensionaldata(210|160
colour video at 60 Hz) as input—to demonstrate that our approach
robustly learns successful policies over a variety of games based solely
onsensoryinputswithonlyveryminimalpriorknowledge(thatis,merely
the input data were visual images, and the number of actions available
in each game, but not their correspondences; see Methods). Notably,
our method was able to train large neural networks using a reinforce-
mentlearningsignalandstochasticgradientdescentinastablemanner—
illustrated by the temporal evolution of two indices of learning (the
agent’s average score-per-episode and average predicted Q-values; see
Fig. 2 and Supplementary Discussion for details).
We compared DQN with the best performing meth
reinforcement learning literature on the 49 games whe
available12,15
. In addition to the learned agents, we alsore
aprofessionalhumangamestesterplayingundercontro
and a policy that selects actions uniformly at random (E
Table 2 and Fig. 3, denoted by 100% (human) and 0% (
axis; see Methods). Our DQN method outperforms th
reinforcement learning methods on 43 of the games wit
rating any of the additional prior knowledge about Ata
used by other approaches (for example, refs 12, 15). Fur
DQN agent performed at a level that was comparable to
fessionalhumangamestesteracrossthesetof49games,a
than75%ofthe humanscore onmorethanhalfofthegam
Convolution Convolution Fully connected Fully connected
No input
Figure 1 | Schematic illustration of the convolutional neural network. The
details of the architecture are explained in the Methods. The input to the neural
network consists of an 843 843 4 image produced by the preprocessing
map w, followed by three convolutional layers (note: snaking blue line
symbolizes sliding of each filter across input image) and two f
layers with a single output for each valid action. Each hidden
by a rectifier nonlinearity (that is, max 0,xð Þ).
a b
0
200
400
600
800
1,000
1,200
1,400
1,600
1,800
2,000
2,200
Averagescoreperepisode
0
1,000
2,000
3,000
4,000
5,000
6,000
Averagescoreperepisode
RESEARCH LETTER
[Mnih+ 15]
[Mnih+ 16]
DQN
Q(xt, at; ✓) = r(xt, at) + max
a0
Q(xt+1, a0
; ✓ ) Q(xt, at; ✓)
✓ ✓ + ↵t Q(xt, at; ✓)
@Q(xt, at; ✓)
@✓
Q(xt, at; ✓) =
k 1X
s=t
s t
⇣ sY
i=t+1
ci
⌘⇥
r(xs, as) + E
⇡
Q(xs+1, ·; ✓ ) Q(xs, as; ✓)
⇤](https://image.slidesharecdn.com/unofficialintroductionofsafeandefficientoffpolicyreinforcementlearning-161114012920/85/safe-and-efficient-off-policy-reinforcement-learning-19-320.jpg)
![20
• 60 種類のゲームでのパフォーマンスを比較
• : ゲーム g におけるアルゴリズム a のスコア
実験結果
0.00.20.40.60.81.0
0.0
0.2
0.4
0.6
0.8
1.0
FractionofGames
Inter-algorithm Score
40M TRAINING FRAMES
Q*
Retrace
Tree-backup
Q-Learning
0.00.20.40.60.81.0
0.0
0.2
0.4
0.6
0.8
1.0
FractionofGames
Inter-algorithm Score
200M TRAINING FRAMES
Retrace
Tree-backup
Q-Learning
f(x) , |{g : zg,a x}|/60
zg,a 2 [0, 1]](https://image.slidesharecdn.com/unofficialintroductionofsafeandefficientoffpolicyreinforcementlearning-161114012920/85/safe-and-efficient-off-policy-reinforcement-learning-20-320.jpg)



![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)
![SSII2021 [TS2] 深層強化学習 〜 強化学習の基礎から応用まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts2-01-210607042910-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]モデルベース強化学習とEnergy Based Model](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-191129002008-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]`強化学習のための状態表現学習 -より良い「世界モデル」の獲得に向けて-](https://cdn.slidesharecdn.com/ss_thumbnails/20181026staterepresenration-181127055206-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Decision Transformer: Reinforcement Learning via Sequence Modeling](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontransformer20210709zhangxin-210709021501-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.](https://cdn.slidesharecdn.com/ss_thumbnails/20210115dlohta-210115054939-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Learning Latent Dynamics for Planning from Pixels](https://cdn.slidesharecdn.com/ss_thumbnails/taniguchi20181221-190104064850-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[DL輪読会]近年のオフライン強化学習のまとめ —Offline Reinforcement Learning: Tutorial, Review, an...](https://cdn.slidesharecdn.com/ss_thumbnails/20200626journalclubpub-200630064755-thumbnail.jpg?width=640&height=640&fit=bounds)





































