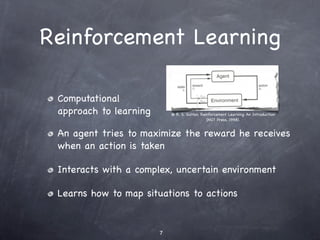
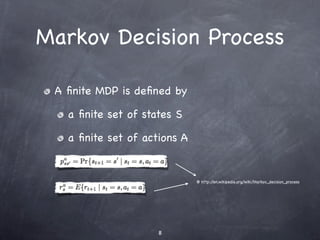
The document discusses hierarchical reinforcement learning (HRL). It provides an overview of reinforcement learning and Markov decision processes before introducing HRL. HRL can improve performance by decomposing problems into subproblems using temporal and state abstraction. Several HRL approaches are described, including options which define subpolicies and termination conditions. The document outlines future work, such as automated discovery of subgoals and state abstractions, and developing agents that can continually learn across tasks.







![Q-Learning
[Watkins, C.J.C.H.’89]
Agent with a state set S and action set A.
Performs an action a in order to change its
state.
A reward is provided by the environment.
The goal of the agent is to maximize its
total reward.
@ http://en.wikipedia.org/wiki/Q-learning
9](https://image.slidesharecdn.com/hrl-100525054951-phpapp02/85/Hierarchical-Reinforcement-Learning-9-320.jpg)




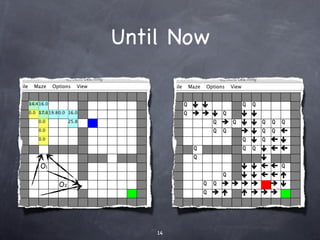
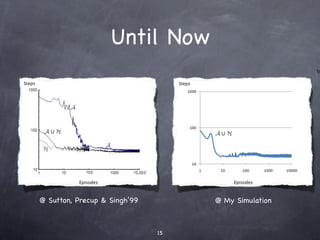
![Options
[Sutton, Precup & Singh’99]
An Option is defined by
A policy ∏: SxA ➞ [0,1]
A termination condition β: S^+ →[0,1]
And an initiation set I⊆S
Its hierarchical and used to reach sub-goals
13](https://image.slidesharecdn.com/hrl-100525054951-phpapp02/85/Hierarchical-Reinforcement-Learning-14-320.jpg)



















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









